纽约大学医学院计划将MRI扫描加速至少10倍。 来自Facebook(FAIR)的一组人工智能研究人员将通过机器学习技术为他们提供帮助。
该项目称为
fastMRI 。 医生将为他提供1万名患者和Facebook收集的300万张大脑,膝盖和肝脏图像的数据集-他们在机器学习方面的成就训练了该算法。 根据该想法,MRI设备将仅收集部分信息,而经过训练的神经网络将填补这些空白。
研究人员计划将这些结果用于实际用途,并在一年内以免费许可证的形式发布结果。
MRI装置通过电磁辐射影响组织,并以数字数据的形式固定能量释放,然后它们从中形成图像-“二维切片”。 该过程可能持续15分钟到一个小时。 您需要收集的数据越多,所需的暴露时间就越长。
此时的一个人需要撒谎而不是移动。 对于某些患者(例如,年幼的儿童,躺卧时患有幽闭恐惧症或感到疼痛的人),这可能是个问题。
医学院的研究人员在2015年进行了首次尝试,以加快图像的获取速度。 科学家建议,仅收集一部分数据就可以减少设备中的时间,而借助神经网络算法上受过训练的AI可以填补剩余的空白。
MRI设备通常在获得结果所需的数据量方面非常灵活。 但是,在进行了首次尝试之后,研究人员得出结论,要重新创建高质量的图像,所需的数据将比他们预期的少。
困难在于,在处理照片和视频时,神经网络算法以类似的方式填补空白,根据获得的数据绘制像素,假设和偏差并不重要,至少在生死攸关的方面。 但是在MRI图像分析中,每毫米都会影响诊断。
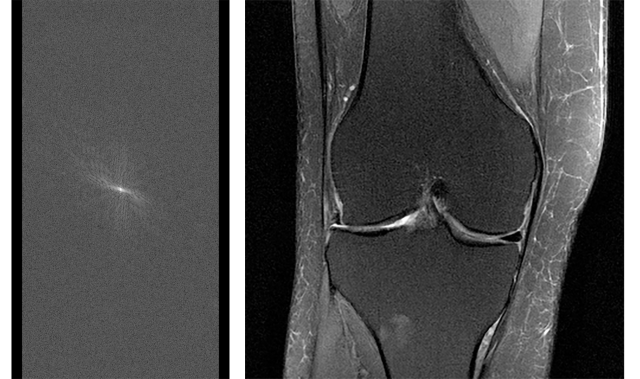 该图像的左侧是MRI收集的完整的源数据集。 右边是膝盖的镜头,可以得到其中的一个。
该图像的左侧是MRI收集的完整的源数据集。 右边是膝盖的镜头,可以得到其中的一个。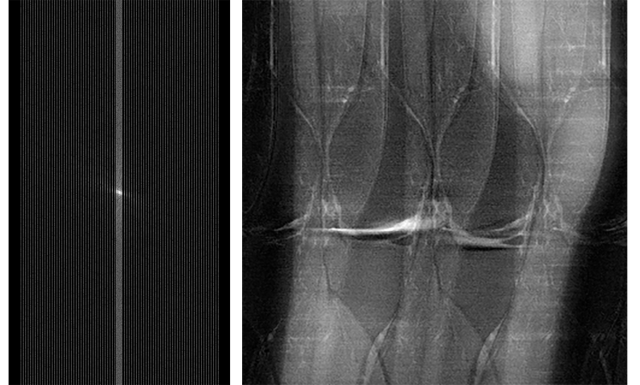 这是在此阶段使用神经网络算法获得的部分数据集和膝盖图片。
这是在此阶段使用神经网络算法获得的部分数据集和膝盖图片。除了具有重建精度的问题外,该项目还提出了一些道德问题。
Facebook工程师仅在其他领域致力于解决计算机视觉的类似问题。 他们说参与该项目是他们将技术付诸实践的好方法。 但是,最近通过获利获利的公司收集个人数据是一个特别敏感的问题。 特别是在医疗数据方面。
研究人员说,在数据集中没有关于患者的性格,姓名和医疗信息的信息,只有图像本身以及从中获得这些图像的源数据。 Facebook的代表还争辩说,该项目没有使用公司自己收集的数据。
正如Facebook的代表
告诉 VentureBeat,结果应该在一年之内。 一旦取得必要的进展,研究人员将在一般访问权限中发布训练了AI的所有模型,指标和数据集,以便其他诊所可以使用它们。