大家好
我们刚刚翻译了布伦丹·伯恩斯(Brendan Burns)的一本有趣的书,其中谈到了分布式系统的设计模式

此外,“
Mastering Kubernetes ”(第二版)一书的翻译已经全面展开,作者的有关Docker的书即将在9月出版,并且还会有单独的帖子。
我们相信,这条路的下一站是一本有关普罗米修斯的书,因此今天,请您注意比约恩·温泽尔(BjörnWenzel)撰写的关于普罗米修斯与Kubernetes之间紧密互动的短文的翻译。 请记住参加调查。
监视Kubernetes集群是一项非常重要的工作。 群集中包含大量信息,可让您回答以下类别的问题:现在有多少可用的内存和磁盘空间,cpu的使用率如何? 哪个容器消耗多少资源? 这也包括有关集群中运行的应用程序状态的问题。
用于此类工作的工具之一就是Prometheus。 它由Cloud Native Computing Foundation支持,最初是由SoundCloud开发的Prometheus。 从概念上讲,普罗米修斯很简单:
建筑学
Prometheus服务器可以在Kubernetes集群中工作,并通过特殊文件接收配置。 特别是,此配置包含有关在指定时间间隔后从何处收集数据的终端的信息。 然后,Prometheus服务器以特殊格式从这些终端请求度量(它们通常在
/metrics可用)并将它们存储在时间序列数据库中。 以下是一个简短的示例:一个小的配置文件,它从在每个节点上部署为代理的
node_exporter模块请求度量:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
首先,我们定义作业名称
job_name ,此名称可用于在Prometheus中请求度量,然后是
scrape_interval数据
scrape_interval和一组运行
node_exporter的服务器。 现在,Prometheus将每15秒向服务器询问到当前指标的
path /metrics 。 看起来像这样:
首先,给出度量的名称,然后给出签名(括号中的信息),最后给出度量的值。 最有趣的是这些指标的搜索功能。 为此,Prometheus具有非常强大的
查询语言 。
上面已经描述了Prometheus的主要思想是:Prometheus以给定的时间间隔轮询端口以获取度量并将其存储在时间序列数据库中。 如果Prometheus无法删除指标本身,则还有另一种功能称为pushgateway。 Pushgateway网关接受外部作业发送的指标,Prometheus以指定的时间间隔从此网关收集信息。
Prometheus体系结构的另一个可选组件是
alertmanager 。
alertmanager组件允许
alertmanager设置限制,如果超出限制,则可以通过电子邮件,空闲时间或opsgenie发送通知。
此外,Prometheus服务器包含许多
集成功能 ,例如,它可以在Amazon API上请求ec2实例或从Kubernetes请求Pod,节点和服务。 它还具有许多
导出器 ,例如上述的
node_exporter 。 这样的导出器可以在例如安装了MySQL之类的应用程序的节点上工作,并以给定的时间间隔轮询该应用程序以获取指标并在终端/指标上提供它们,而Prometheus服务器可以从那里收集这些指标。
另外,编写自己的导出器并不困难-例如,对于提供度量标准(例如jvm信息)的应用程序。 例如,有一个由Prometheus开发的
库 ,用于导出此类指标。 该库可以与Spring结合使用,并且还允许您定义自己的指标。 这是来自
client_java页面的示例:
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
这是一个描述方法持续时间的度量,其他度量现在可以通过终端提供或通过推送网关推送。
Kubernetes集群中的用法
如前所述,在Kubernetes集群中使用Prometheus时,集成了从炉膛,节点和服务中删除信息的功能。 最有趣的是,Kubernetes是专门设计用于Prometheus的。 例如,
kubelet和
kube-apiserver在Prometheus中提供
kube-apiserver度量,因此监视非常简单。
在此示例中,对于初学者,我使用官方头盔图表。
对于我自己,我稍微更改了默认头盔图的配置。 首先,我需要在Prometheus安装中激活
rbac ,否则Prometheus无法从
kube-apiserver收集信息。 因此,我编写了自己的values.yaml文件,该文件描述了舵图应如何显示。
我做了最简单的更改:
alertmanager.enabled: false ,即取消了在集群中部署alertmanager(我不打算使用alertmanager,我认为使用Grafana来配置警报会更容易)kubeStateMetrics.enabled: false我认为这些指标仅返回有关炉膛最大数量的一些信息。 首次启动系统时,此信息对我并不重要server.persistentVolume.enabled: false直到默认情况下配置了永久卷为止- 我在Prometheus中更改了信息收集的配置,就像在github上的pull请求中所做的那样。 事实是,在Kubernetes v1.7中,cAdvisor指标在另一个端口上工作。
之后,您可以使用helm启动Prometheus:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yaml因此,我们安装了Prometheus服务器,并在每个节点上-将其安装在node_exporter下。 现在,您可以转到Prometheus Web GUI并查看一些信息:
kubectl port-forward <prometheus-server-pod> 9090以下屏幕快照显示了Prometheus出于什么目的收集信息(状态/目标),以及最后一次对信息进行多次射击的时间:
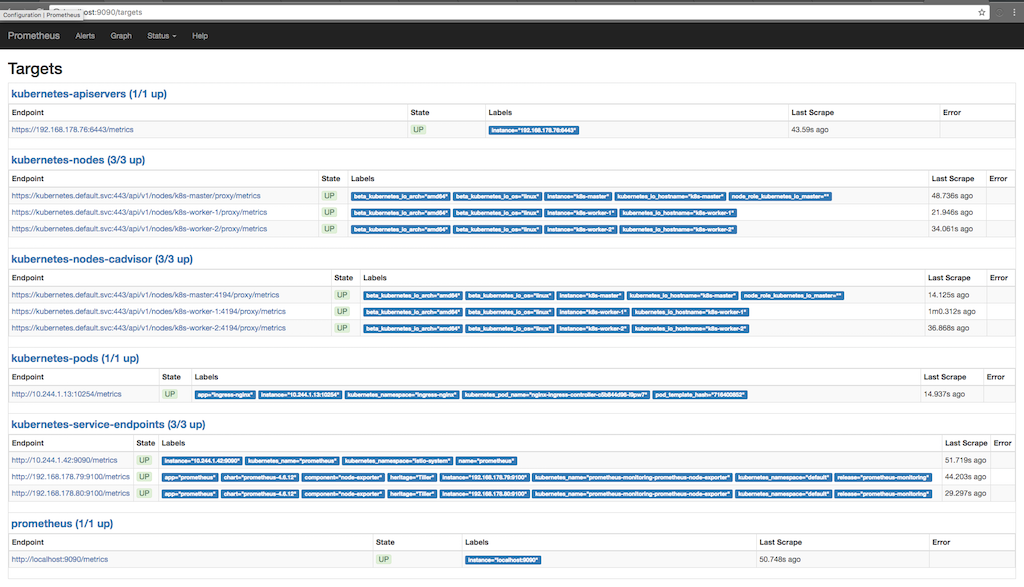
在这里,您可以看到Prometheus如何从apiserver,节点,在节点上运行的cadvisor和kubernetes服务端点上请求指标。 您可以通过转到Graph并编写查询以查看我们感兴趣的信息来详细查看指标:

例如,在这里,我们在挂载点“ /”看到可用存储空间。 在图的底部,添加了由Prometheus添加或在node_exporter上已经可用的签名。 我们使用这些签名仅请求安装点“ /”。
带注释的自定义指标
如第一个屏幕截图中已显示的那样,派生了Prometheus所请求指标的目标,在集群中还有一个用于炉床的指标。 Prometheus的一个不错的功能之一就是能够从整个壁炉中获取信息。 如果炉膛中的容器提供了Prometheus指标,那么我们可以使用Prometheus自动收集这些指标。 我们唯一需要注意的是为安装提供两个注释。 在我的情况下,
nginx-ingress-controller开箱即用:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
在这里,我们看到部署模板带有两个Prometheus注释。 第一个描述Prometheus应该通过其请求度量的端口,第二个描述了激活数据收集功能。 现在,Prometheus请求
Kubernetes Api-Server注释的
Kubernetes Api-Server pod收集信息,并尝试从终端/指标收集信息。
联合工作
我们有一个项目,其中以联合模式使用Prometheus。 这个想法是这样的:我们仅收集只能从群集内部访问的信息(或者更容易从群集内部收集此信息),启用联合模式并使用安装在群集外部的第二个Prometheus获取此信息。 因此,可以一次从多个Kubernetes集群收集信息,还可以捕获无法从该集群内部访问或与该集群不相关的其他组件。 另外,没有必要将收集的数据长时间存储在集群中,如果集群出了问题,我们可以从集群外部收集一些信息,例如node_exporter。