[翻译作者的注释]翻译是为了满足自己的需要而制作的,但是如果对某人有用,那么世界至少变得更好一点了! 原始文章-Java中HashMap的内部工作
在本文中,我们将了解HashMap集合中的get和put方法如何在内部工作。 执行什么操作。 哈希如何发生。 密钥如何检索值。 键值对如何存储?
与上一篇文章一样 ,HashMap包含一个Node数组,Node可以表示一个包含以下对象的类:
- int-哈希
- K是关键
- V是值
- 节点-下一项
现在,我们将看到它们如何工作。 首先,我们来看一下哈希过程。
散列
散列是使用hashCode()方法执行的将对象转换为整数形式的过程。 正确实现hashCode()方法以确保HashMap类的最佳性能非常重要。
在这里,我使用了自己的Key类,通过这种方式,我可以覆盖hashCode()方法来演示各种脚本。 我的钥匙班:
在这里,重写的hashCode()方法返回字符串的第一个字符的ASCII码。 因此,如果字符串的第一个字符相同,则哈希码将相同。 不要在程序中使用类似的逻辑。
此代码仅用于演示目的。 因为HashCode接受空键,所以空哈希码将始终为0。
HashCode()方法
hashCode()方法用于获取对象的哈希码。 Object类的hashCode()方法返回一个整数内存引用(标识哈希码 )。 public native hashCode()方法的签名。 这表明该方法是作为本机实现的,因为在Java中,没有方法可以获取对该对象的引用。 允许定义您自己的hashCode()方法的实现。 在HashMap类中,hashCode()方法用于计算存储区,因此计算索引。
等于()方法
equals方法用于测试两个对象是否相等。 该方法在Object类中实现。 您可以在自己的课程中覆盖它。 在HashMap类中,equals()方法用于验证键是否相等。 如果键相等,则equals()方法返回true,否则返回false。
篮子
存储桶是HashMap数组的唯一元素。 它用于存储节点(Nodes)。 两个或多个节点可以具有相同的存储桶。 在这种情况下,将使用链接列表数据结构链接节点。 铲斗的容量(容量属性)不同。 桶与容量之间的关系如下:
capacity = number of buckets * load factor
一个存储桶可以有多个节点,这取决于hashCode()方法的实现。 您的hashCode()方法实施得越好,您的存储桶将被更好地利用。
HashMap索引计算
密钥哈希码可以足够大以创建数组。 生成的哈希码可以在整数类型的范围内,如果我们创建此大小的数组,则可以轻松获得outOfMemoryException。 因此,我们生成索引以最小化数组的大小。 本质上,执行以下操作来计算索引:
index = hashCode(key) & (n-1).
其中n等于存储桶数或数组长度的值。 在我们的示例中,我将n设置为默认值16。
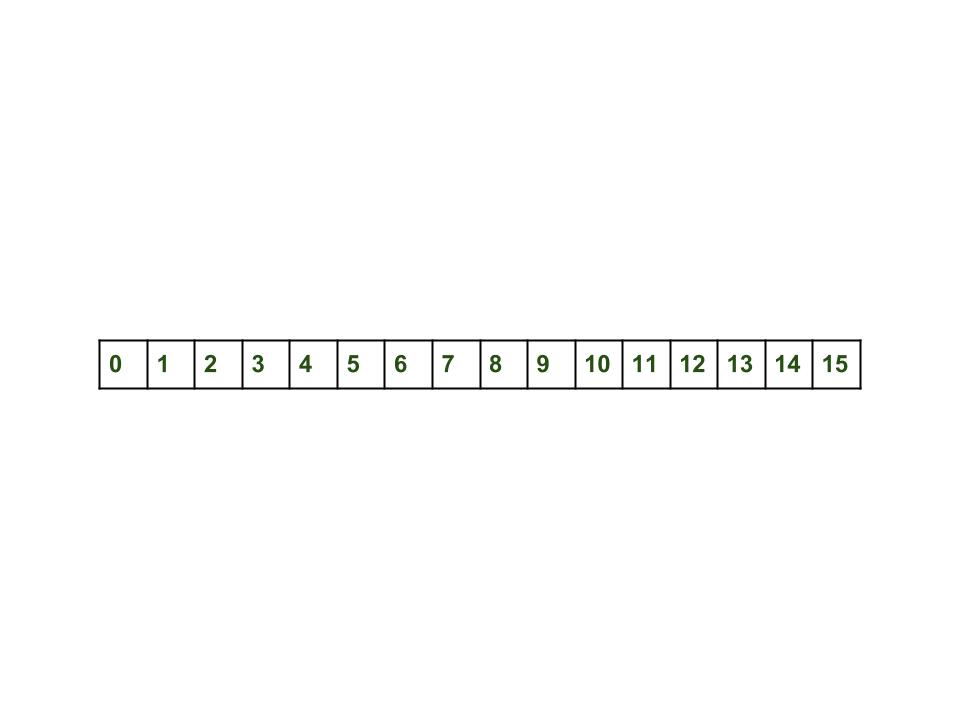
- 最初的hashMap为空:此处的hashmap大小为16:
HashMap map = new HashMap();
HashMap:
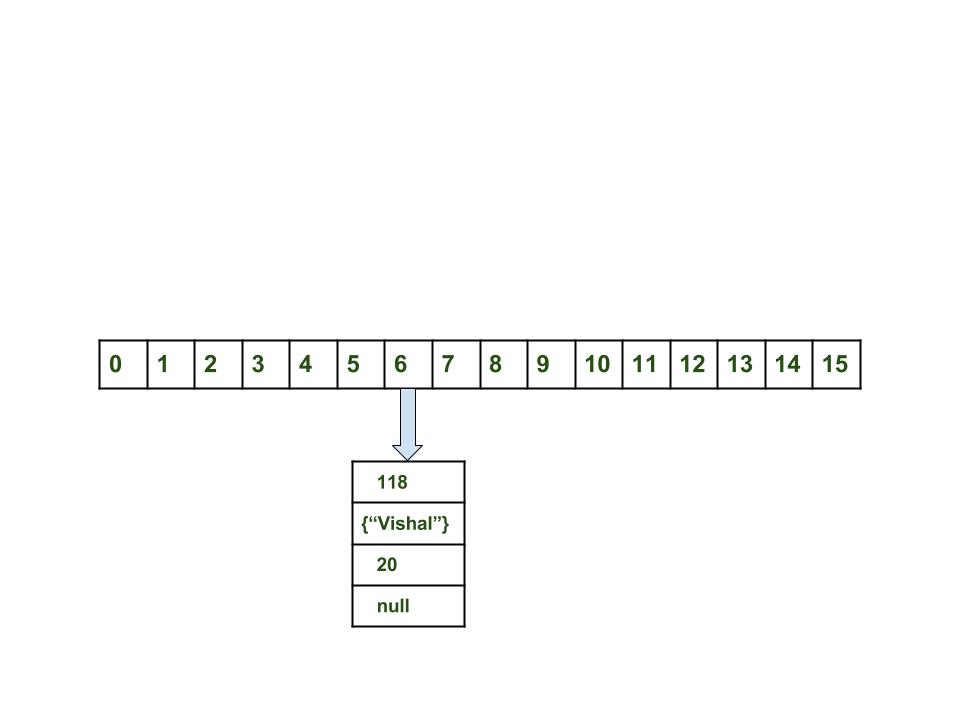
map.put(new Key("vishal"), 20);
步骤:
计算键值{“ vishal”}。 它将生成为118。
使用index方法计算索引,该index将为6。
创建一个节点对象。
{ int hash = 118
如果空间可用,则将对象放置在索引为6的位置。
HashMap现在看起来像这样:
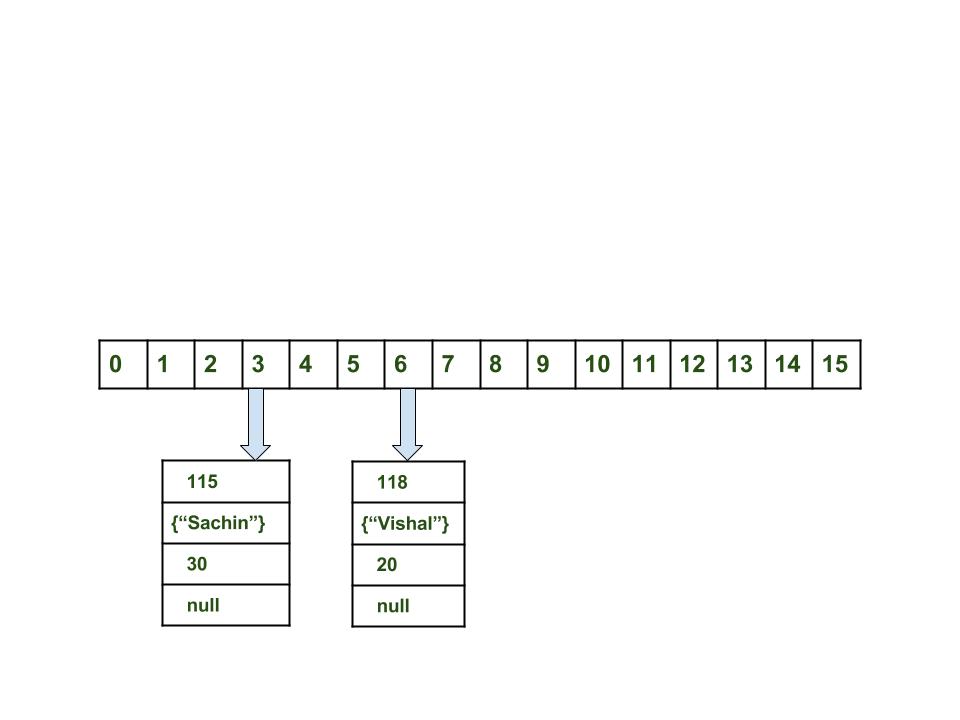
map.put(new Key("sachin"), 30);
步骤:
计算键值{“ sachin”}。 它将生成为115。
使用index方法计算索引,该index将为3。
创建一个节点对象。
{ int hash = 115 Key key = {"sachin"} Integer value = 30 Node next = null }
如果空间可用,则将对象放置在索引为3的位置。
HashMap现在看起来像这样:
map.put(new Key("vaibhav"), 40);
步骤:
计算键值{“ vaibhav”}。 它将生成为118。
使用index方法计算索引,该index将为6。
创建一个节点对象。
{ int hash = 118 Key key = {"vaibhav"} Integer value = 20 Node next = null }
如果空间可用,则将对象放置在索引为6的位置。
在这种情况下,索引为6的位置中已经存在另一个对象,这种情况称为碰撞。
在这种情况下,请使用hashCode()和equals()方法检查两个键是否相同。
如果键相同,则用新的键替换当前值。
否则,通过指定到当前对象中下一个对象的链接,使用“链接列表”数据结构链接新对象和旧对象,并将两者保存在索引6下。
HashMap现在看起来像这样:
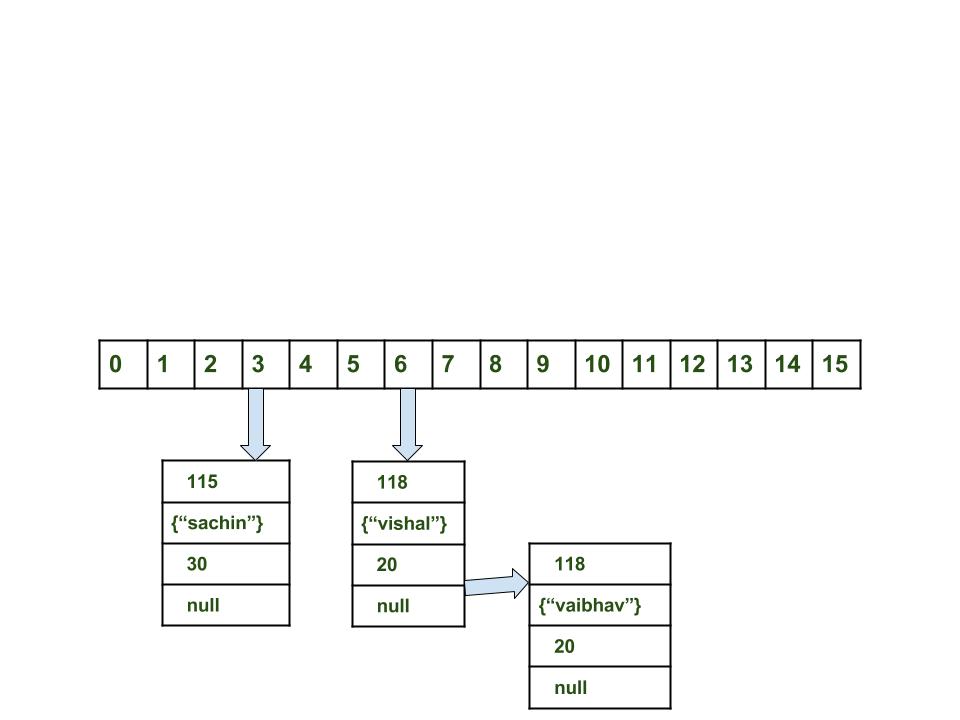
[翻译作者的注释]图像取自原始文章,最初包含错误。 对索引为6的vishal对象中下一个对象的引用不为null,它包含指向vaibhav对象的指针。
map.get(new Key("sachin"));
步骤:
计算{{sachin»}对象的哈希码。 生成为115。
使用index方法计算索引,该index将为3。
转到索引3,将第一个元素的键与现有值进行比较。 如果它们相等,则旋转该值;否则,检查下一个元素(如果存在)。
在我们的例子中,找到了元素,返回值为30。
map.get(new Key("vaibhav"));
步骤:
计算对象{“ vaibhav”}的哈希码。 它生成为118。
使用index方法计算索引,该index将为6。
转到索引6,将第一个元素的键与现有值进行比较。 如果它们相等,则旋转该值;否则,检查下一个元素(如果存在)。
在这种情况下,找不到它,并且下一个节点对象也不为空。
如果下一个节点对象为null,则返回null。
如果下一个节点对象不为空,请转到它并重复前三个步骤,直到找到该元素或下一个节点对象为空。
结论:
hashCode for key: vishal = 118 hashCode for key: sachin = 115 hashCode for key: vaibhav = 118 hashCode for key: sachin = 115 Value for key sachin: 30 hashCode for key: vaibhav = 118 Value for key vaibhav: 40
Java 8的变化
众所周知,在发生碰撞的情况下,节点对象存储在“链表”数据结构中,并且equals()方法用于比较键。 这些比较是在链表中找到正确的键的比较—线性操作,在最坏的情况下,复杂度为O(n) 。
为了解决Java 8中的此问题,在达到特定阈值后,将使用平衡树代替链接列表。 这意味着HashMap在开始时将对象保存在链接列表中,但是在哈希中的元素数量达到某个阈值之后,会发生向平衡树的过渡。 在最坏的情况下,将性能从O(n)提高到O(log n)。
重点
- 在执行重新哈希之前,get()和put()操作的复杂度几乎是恒定的。
- 在发生冲突的情况下,如果两个或更多节点对象的索引相同,则使用链接列表连接节点对象,即 到第二个节点对象的链接存储在第一个节点中,到第三个节点的链接存储在第二个中,依此类推。
- 如果给定的密钥已经存在于HashMap中,则该值将被覆盖。
- 空哈希码为0。
- 当通过键获取对象时,将在链接列表中进行转换,直到找到该对象或到下一个对象的链接为空为止。