哈Ha! 今天,我想谈一谈深度学习如何帮助我们更好地理解艺术。 根据我们解决的任务,本文分为几部分:
- 从手机拍摄的照片中搜索数据库中的照片;
- 确定不在数据库中的图片的样式和风格。
所有这些都成为Arthive数据库服务及其移动应用程序的一部分。
识别绘画的任务是从数据库中来自移动应用程序的图像中找到相应的图片,为此花费了不到一秒钟的时间。 在设计前的研究阶段,完全排除了在移动设备中进行处理。 另外,事实证明,在真实拍摄条件下, 不可能保证在移动设备上执行图片与背景的分离。 因此,我们决定我们的服务将接受来自手机的整个照片作为输入,所有失真,噪声和可能的部分重叠。

我们是否可以帮助Dasha在超过200,000张图像的数据库中找到这些画作?
Arthive艺术库包含近250,000张图像,以及各种元数据。 基础不断更新-每天从数十张到数百张图像。 即使以有限的分辨率(大多数侧面不超过1400像素)抽出图像,图像占用的空间也超过80 GB。 不幸的是,数据库是“脏”的:文件损坏或太小,未对齐和未处理的图像,重复的图像。 但是,总体而言,这是好的数据。
绘画比较
让我们看看数据库中的图像如何:
基本上,数据库中的图像是对齐的,裁剪到画布的边框,保留了颜色。
以下是来自移动设备的请求:

颜色几乎总是失真的-发现复杂的照明,存在眩光,甚至发现玻璃中其他绘画的反射。 图像本身是透视变形的,可以被部分裁剪,或者相反,仅占据图片的不到一半,可以被例如人局部关闭。
为了识别图片,您需要能够将查询的图像与数据库中的图像进行比较。
为了比较容易出现透视失真和颜色失真的图像,我们使用关键点匹配。 为此,我们在图像上找到带有描述符的关键点,找到它们的对应关系,然后使用RANSAC方法单应显示相应的点。 通常以与OpenCV示例中所述相同的方式完成此操作。 如果RANSAC发现的“内在”点的数量足够大,并且发现的单应性变换看起来合理(没有很强的缩放或旋转),那么我们可以假设所需的图像是一幅并且是同一幅图像,并且透视失真。
映射关键点的示例:

当然,寻找关键点通常是一个相当缓慢的过程,但是要搜索数据库,您可以提前找到所有图片的关键点并保存其中的一些。 在我们的实验中,我们得出的结论是,不足1000点足以可靠地搜索绘画。 当使用每点64个字节(坐标+ AKAZE描述符)存储1024个点时,每个图像64 KB或每个基础大约15 GB就足够了。
在我们的案例中,按关键点比较图片大约需要15毫秒,也就是说,要完全枚举250,000张图片的数据库,大约需要1个小时。 好多
另一方面,如果我们学会从整个数据库中快速选择几个(例如100个)最有可能的候选人,我们将满足每个请求1秒的目标时间。
相似度排名
深度卷积网络已将其自身确立为搜索相似图像的好方法。 该网络用于提取特征并在其基础上计算描述符,该描述符具有以下特性:相似图像的描述符之间的距离(欧几里德,余弦或其他)比不同图像的距离小。
您可以通过以下方式训练网络:对于来自基础的图片的图像以及来自图片的失真的图像,它会生成接近的描述符,而对于不同的图片(更远的图片)。 此外,这种网络用于计算数据库中所有图像的描述符和请求中的照片描述符。 您可以快速选择最接近的图像,并根据描述符之间的距离进行排列。
训练网络以计算描述符的基本方法是使用暹罗网络。
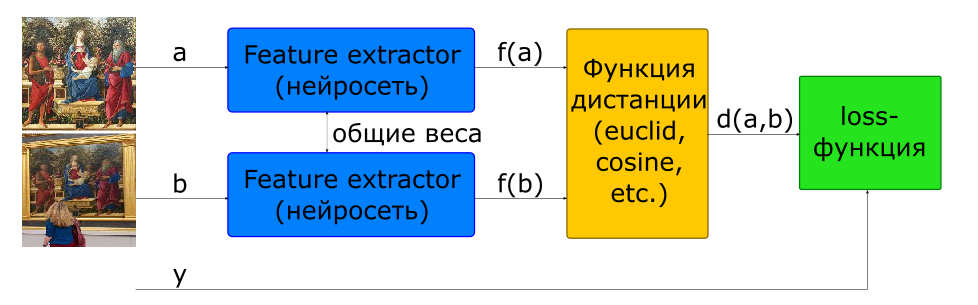
-输入图像
如果 和 -一堂课 如果不同
-图像描述符
-一对特征向量之间的距离
-目标函数
为了构建这样的体系结构,在模型中使用具有共同权重的计算描述符的网络(特征提取器)两次。 几个图像被馈送到网络输入。 特征提取器网络计算图像描述符,然后网络根据指定的度量标准计算距离(通常使用欧几里得距离或余弦距离)。 网络训练的目标功能的构建方式是,对于正数对(一张图片的图像),距离减小,而对于负数对(不同图片的图像),距离增大。 为了减少负对的影响,它们之间的距离受边距值限制。
因此,我们可以说,在学习过程中,网络试图计算具有余量半径的超球体内的相似图像的描述符,以及不同边缘的描述符,以将其推出该球体。
例如,这看起来像是在MNIST数据集上使用暹罗网络训练二维描述符。
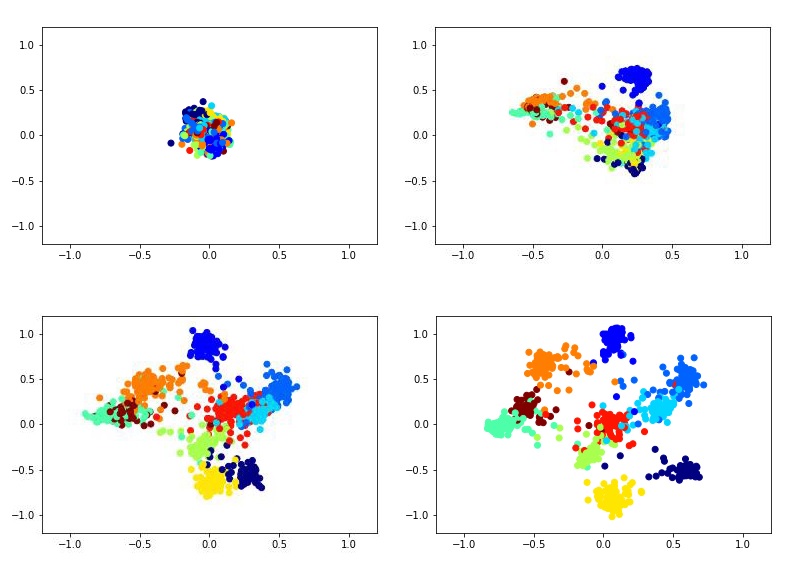
要训练暹罗网络,您需要输入成对的图片和一个标签,如果图片属于同一类,则标签等于1;如果不同,则标签等于0。 存在选择正负对的比例的问题。 当然,理想情况下,当然有必要将训练集中所有可能的成对组合提交给网络训练,但这在技术上是不可能的。 负对的数量在这种情况下大大超过正对的数量,这对学习过程也不会产生很好的影响。
通过使用三元组体系结构解决了选择训练对的比例问题的部分问题。
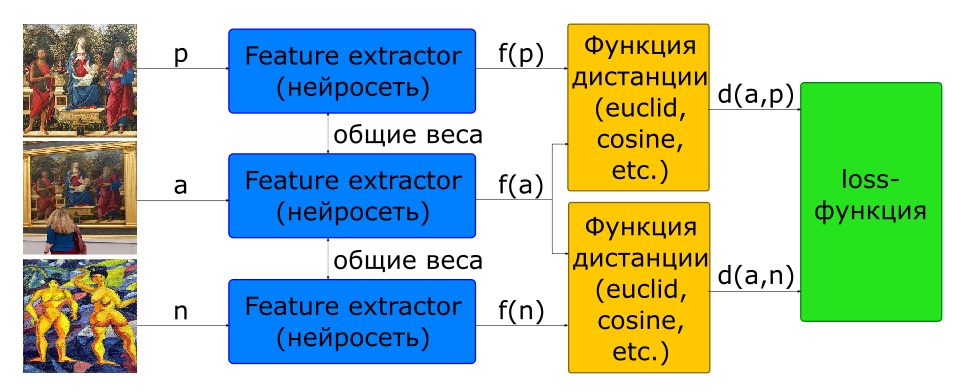
-输入图像: -一张照片, -另一个
-目标函数
在这种网络的输入端,立即形成3张图像,形成正负对。
此外,几乎所有研究人员都认为,负对的选择对于网络学习至关重要。 如果许多样本不违反边际限制,则它们的目标函数(暹罗语对,三胞胎三对)的目标函数变为0,因此,此类样本不参与网络的训练。 随着时间的流逝,学习过程的速度甚至会进一步降低,因为目标函数非零值的样本越来越少。 为了解决这个问题,否定对不是偶然选择的,而是通过搜索困难案例来选择的。 实际上,为此选择了几个否定候选,使用网络权重的最新版本(从以前的时代甚至从当前的时代)计算出每个描述符的描述符。 有了描述符,您可以在每三个中选择一个负数,以产生已知的非零损耗。
为了搜索相似的图像,特征提取器与网络分离,用于计算描述符。 对于数据库中的图像,添加描述符时会预先计算它们。 因此,查找相似图像的任务是计算查询中的图像描述符,并在数据库中搜索最接近给定度量的描述符。
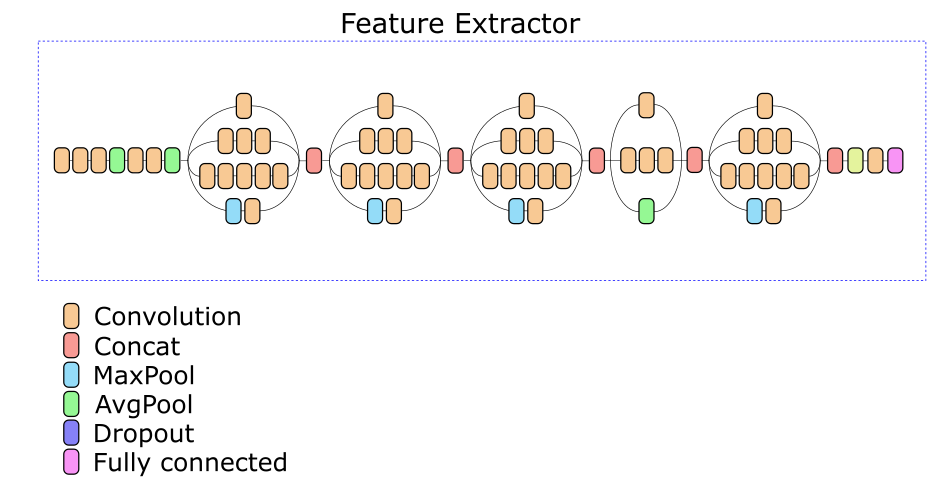
我们的网络特征提取器基于Inception v3架构。 实验选择了中间层之一,根据中间层的输出,计算出512个实数的描述符。
数据扩充
如果我们可以将每张图片放在不同的帧中,在不同的墙壁上,并且每次在不同的手机上以不同的角度拍摄图片,那就太好了。 实际上,这当然是不可能的。 因此,有必要生成训练数据。
为了生成数据,收集了大约500张在不同光照条件下具有不同背景的各种绘画的照片。 对于每张照片,选择了4个与图片画布的角相对应的点。 对于四个点,我们可以将任何图片任意地放入框架中,从而替换图片并从数据库中获取图片的几乎随机的透视失真。 通过随机裁剪,噪声和颜色失真来补充此过程,我们有机会生成完全合适的图像来模仿绘画照片。

图片与背景的分离
用于识别绘画的作品和模型的质量,以及用于对流派/风格进行分类的模型,在很大程度上取决于图片与背景的分离程度。 理想情况下,在将图片输入模型之前,需要找到其画布的4个角并以正方形显示透视图。 在实践中,事实证明很难实施一种可以保证这一点的算法。 一方面,有大量的背景,框架和对象可能掉入图片附近的框架中。 另一方面,在内部的绘画中,有相当明显的矩形轮廓(窗户,建筑立面,画中画)。 结果,通常很难说出图片的结束位置和环境的开始位置。
最后,我们基于经典的计算机视觉方法(边界检测+形态学过滤+所连组件的分析)确定了一个简单的实现,它使您可以放心地切掉单声道的背景,但又不会丢失某些图片。
工作速度
查询处理算法包括以下主要步骤:
- 准备-实际上,实现了图片的简单检测器,如果图像包含纯背景,该检测器将很好地工作;
- 使用深度网络计算图片描述符;
- 按与数据库中描述符的距离对图片进行排名;
- 在图片中搜索关键点;
- 按排名检查候选人。
我们测试了200个请求的网络速度,得出了每个阶段的以下处理时间(以秒为单位的时间):
| 舞台 | 分 | 最大值 | 平均 |
|---|
| 准备(图片搜索) | 0.008 | 0.011 | 0.016 |
| 描述符计算(GPU) | 0.082 | 0.092 | 0.088 |
| KNN(k <500,CPU,蛮力) | 0.199 | 0.820 | 0.394 |
| 关键点搜索 | 0.031 | 0.432 | 0.156 |
| 检查关键点 | 0.007 | 9.844 | 2.585 |
| 总请求时间 | 0.358 | 10.386 | 3.239 |
由于候选者的验证会立即停止,因此当找到足够有把握的图片时,我们可以假定请求的最短处理时间与在第一个候选者中找到的图片相对应。 对于根本找不到的绘画,将获得最大请求时间-检查500个候选对象后停止检查。
可以看出,大部分时间都花在了候选人的选择和验证上。 值得注意的是,这些步骤的执行非常不理想,并且具有很大的加速潜力。
重复搜寻
建立了绘画基础的完整索引后,我们用它来搜索数据库中的重复项。 在查看数据库大约3个小时后,发现在数据库中至少重复了13657张图像两次(大约三张)。
此外,发现了非常有趣的案例,这些案例不是重复的。
 一二
一二 。 看来这是同一工作的两个阶段。
 一
一 ,
二 ,
三 。 不要注意名称-所有三张图片都是不同的。
以及通过关键点进行误报识别的示例。
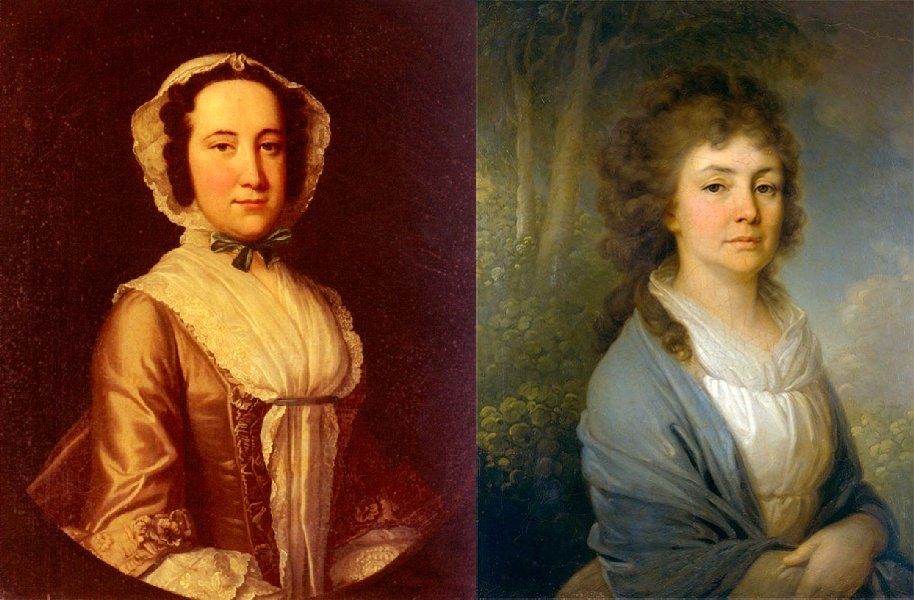 一二
一二 。
而不是结论
总的来说,我们对服务的结果感到满意。
在测试装置上,识别精度达到80%以上。 在实践中,通常会发现,如果不是第一次找到图片,那么从另一个角度拍摄就足够了,就可以找到它。 发现错误图像时几乎不会发生错误。
总之,解决方案被包装在docker容器中并提供给客户。 现在,可以使用Arthive服务在应用程序中通过照片识别绘画作品,例如Play市场上的普希金博物馆(但是,它使绘画与背景分离,要求背景变亮,有时使摄影变得困难)。