卫星或航空图像的自动识别是获取有关地面上各种物体的位置信息的最有前途的方法。 当涉及在短时间内处理大面积的地球表面时,拒绝手动图像分割尤其重要。
最近,我有机会运用理论技能,并在机器学习领域尝试了一个真实的图像分割项目。 该项目的目标是识别林分,即高分辨率卫星图像中的树冠。 根据削减,我将分享我的经验和成果。
对于图像处理,可以给分割指定以下定义-这是特征区域在图像上的存在,这些特征区域在此特征空间中均得到了描述。
区分亮度,轮廓,纹理和语义分割。
语义(或语义)图像分割是为了突出显示图像上的区域,每个区域对应于特定的属性。 一般而言,语义分割问题很难算法化,因此,显示良好结果的卷积神经网络目前广泛用于图像分割。
问题陈述
解决了二进制分割问题-将彩色图像(高分辨率卫星图像)馈送到神经网络的输入,在该神经网络的输入上必须突出显示属于同一类的像素区域-树。
源数据
我可以使用一组多边形适合的矩形区域的卫星图像图块。 在其中,您需要寻找树木。 多边形或多多边形显示为GeoJSON文件。 在我的情况下,图块是256像素乘以256像素的png真彩色格式。 (阿拉斯语,没有IR)以/zoom/x/y.png格式对图块编号。
可以确保该集合中的所有图块均来自于每年大约同一时间(春季至秋季初,取决于特定区域的气候)和一天以与地面相似的角度拍摄的卫星图像,其中允许轻微的云层覆盖。
资料准备
由于所需多边形的面积可能小于此矩形面积,因此第一件事就是排除那些超出多边形边界的图块。 为此,编写了一个简单的脚本,该脚本从GeoJSON文件多边形中选择必要的图块。 它的工作原理如下。 首先,将多边形所有顶点的坐标
转换为图块编号并将其添加到数组中。 相对于原点也有偏移。 为了进行视觉检查,将生成一个像素等于一个图块的图像。 考虑到偏移量后,使用PIL填充图像中的多边形。 之后,将图像传输到数组,从中选择必要的图块,这些图块位于多边形内。
from PIL import Image, ImageDraw
 将多边形转换为一组图块的视觉结果
将多边形转换为一组图块的视觉结果网络模型
为了解决图像分割问题,
存在许多卷积神经网络模型。 我决定使用
U-Net ,它已经在二进制图像分割任务中证明了自己。 U-Net体系结构由所谓的收缩路径和扩展路径组成,它们通过适当的尺寸级之间的probros连接,首先降低图像的分辨率,然后增加图像的分辨率,然后将其与图像数据组合在一起并通过其他层卷积。 因此,网络充当一种过滤器。 压缩和解压缩块表示为一组特定尺寸的块。 每个块都包含基本操作:卷积,ReLu和最大池化。 在Keras,Tensorflow,Caffe和PyTorch上有U-Net模型的实现。 我用过Keras。
创建训练集
要学习此Unet模型,您需要图像。 我脑海中首先想到的是获取OpenStreetMap数据并基于它们生成用于训练的蒙版的想法。 但事实证明,我需要的多边形的精度仍有很多不足。 我还需要存在不总是映射的单棵树。 因此,我不得不放弃这项工作。 但是值得一提的是,对于其他对象,例如道路或建筑物,这种方法可能是
有效的 。

由于必须放弃基于OSM数据自动生成训练样本的想法,因此我决定手动标记一个小区域。 为此,我使用了JOSM编辑器,在其中我将可用的地形图像用作基板,并将其放置在本地服务器上。 然后出现了另一个问题-我没有找到使用常规JOSM工具打开图块网格的显示的机会。 因此,来自不同目录的同一服务器上.htaccess中的几行简单代码开始对带有grid_tile / z / x / y.png格式的任何请求发出带有像素边框的空白图块,并在JOSM中添加了这样的即兴层。 这样的自行车。
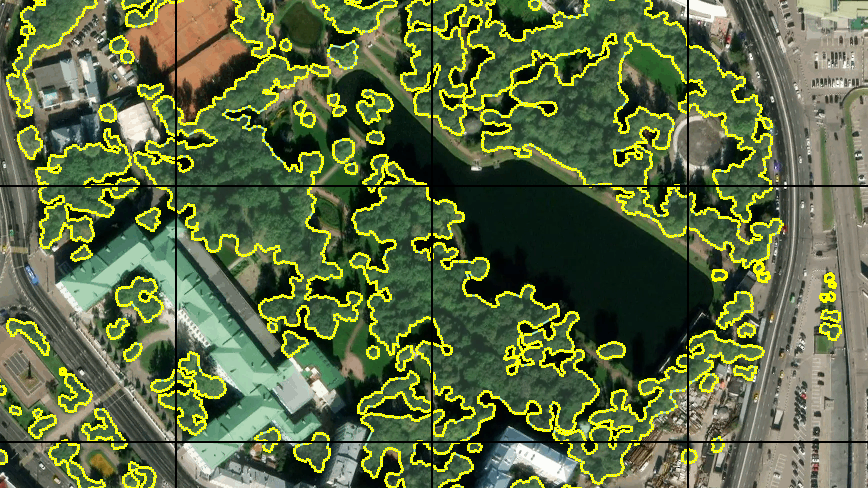
首先,我划出了大约30个磁贴。 有了图形输入板和JOSM中的“快速绘图模式”,它并不需要花费很多时间。 我知道,这样的数量不足以进行全面的培训,但我决定从此开始。 而且,对如此多的数据进行培训将足够快。
培训和第一结果
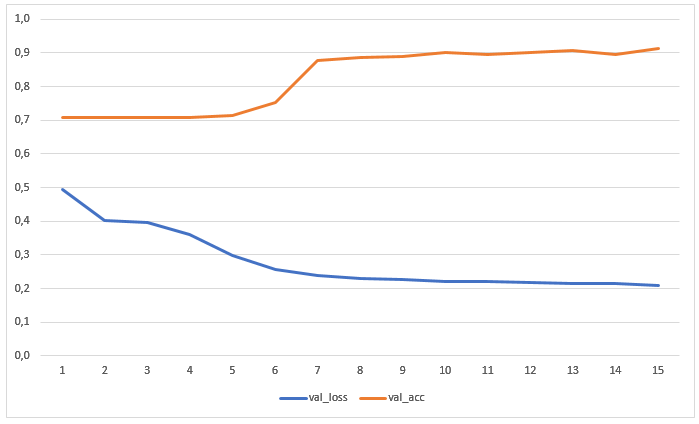
该网络已经接受了15个时代的培训,无需事先进行数据扩充。 该图显示了测试样品的损耗值和准确度:
识别出既不在训练中也不在测试样本中的图像的结果非常合理:

在对结果进行更彻底的研究后,一些问题变得很明显。 许多遗漏都在图像的阴影区域中-网络或者在树荫下找到了树木而不是在树荫下,或者恰好相反。 这是预料之中的,因为培训集中很少有这样的例子。 但是我没想到金属表面上的某些水面和深色屋顶(大概)会被识别为树木。 草坪也有误差。 决定通过添加更多具有争议部分的图像来改善样本,因此训练样本几乎翻了一番。
数据扩充
为了进一步增加数据量,我决定以任意角度旋转图像。 首先,我尝试了标准模块keras.preprocessing.image.ImageDataGenerator。 在保留比例的情况下旋转时,图像的边缘会保留空白区域,其填充由
fill_mode参数设置。 您可以通过在
cval中指定颜色来简单地用颜色填充这些区域,但是我想进行一次完整的转换,希望选择更加完整,然后我自己实现了生成器。 这样可以将大小增加十倍以上。
 fill_mode =最近
fill_mode =最近我的数据生成器将四个相邻的图块粘贴到512x512像素的单个源图块中。 考虑到旋转角度,可以随机选择旋转角度,并针对生成的图块的中心计算x和y的允许间隔,其中旋转角度不会超出原始图块。 中心坐标是根据允许的间隔随机选择的。 当然,所有这些转换都适用于平铺蒙版对。 对于各组相邻的拼贴重复所有这些操作。 从一组中,您可以获取十几个具有不同角度旋转的地形不同区域的图块。
 生成器结果示例
生成器结果示例学习更多数据
结果,训练样本的大小为1881张图像,我还增加了30个时代:
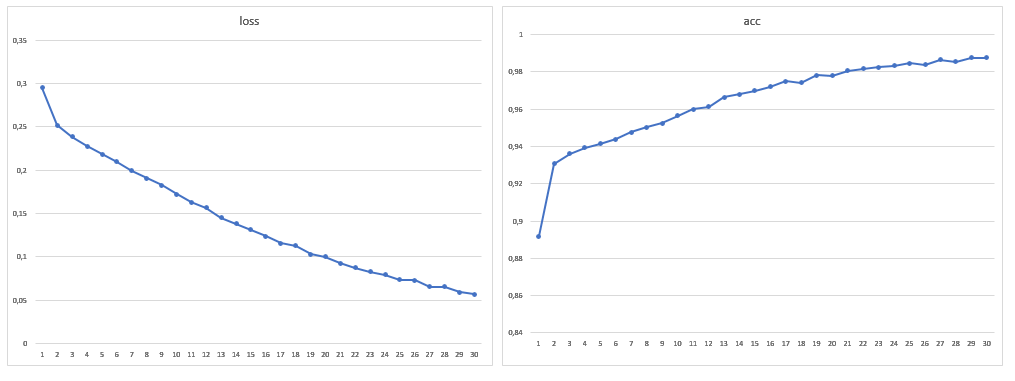
在使用新的数据量训练模型后,不再检测到屋顶和水的错误分割问题。 根本不可能消除阴影中的错误,但是它们在眼睛中的出现以及草坪的错误变得越来越少。 应当指出,一般而言,绝大多数错误是网络看到的树没有出现在树上,反之亦然。 通过使用具有大量通道的卫星图像并针对特定任务修改网络体系结构,可以提高所达到的精度。

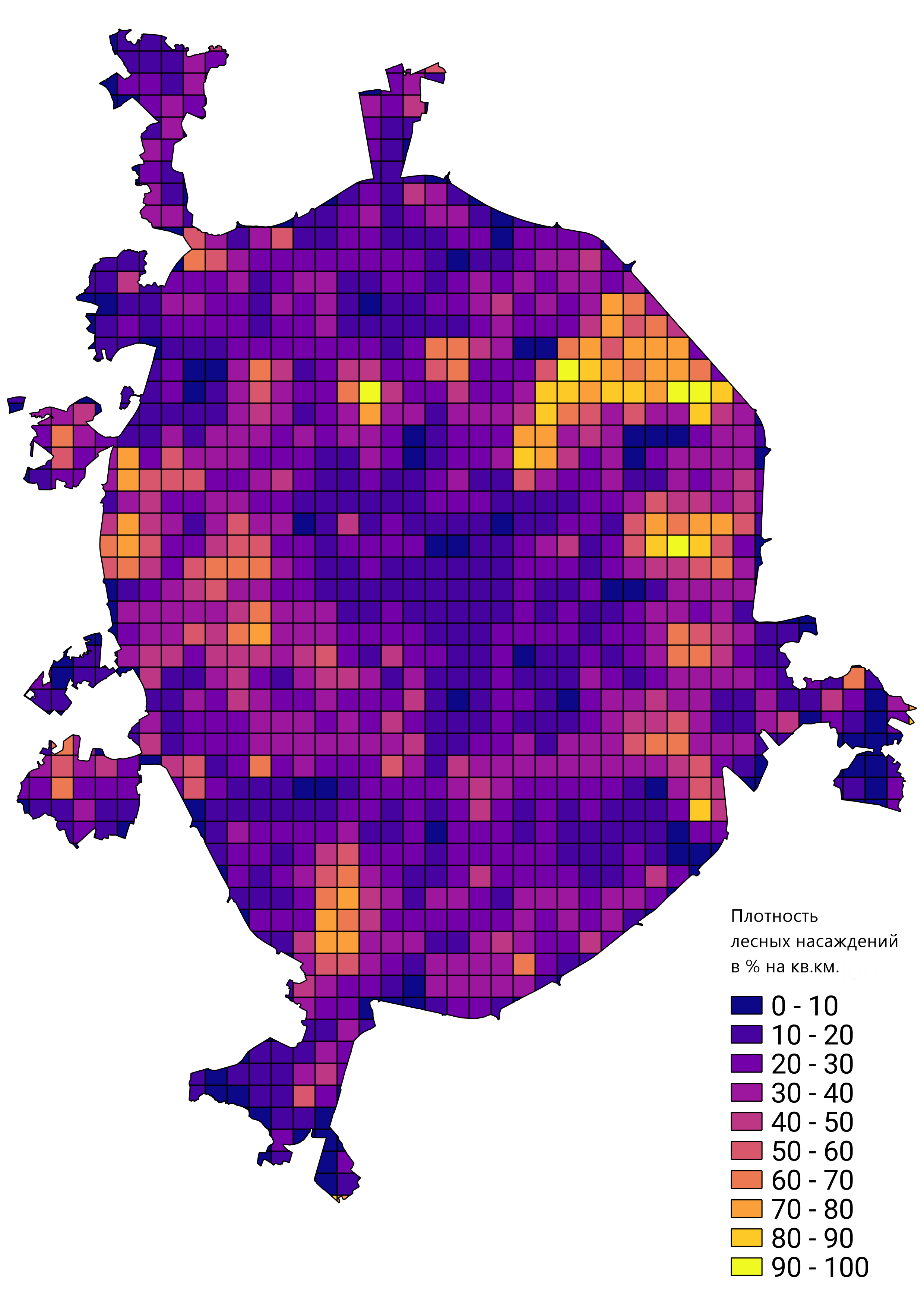
总的来说,我对所做的工作结果感到满意,并且将经过培训的网络原型用于解决实际问题。 例如,计算莫斯科的林分密度: