在电影《碟中谍3》中,展示了制作著名间谍面具的过程,这使某些角色与其他角色变得难以区分。 根据情节,首先需要从多个角度拍摄英雄想要变成的人。 在2018年,一个简单的3D面部模型甚至可能不会被打印出来,但至少是以数字形式创建的-仅基于一张照片。 VisionLabs的研究人员在“数据与科学”系列的Yandex事件“
通过机器人的眼睛看世界 ”中详细描述了该过程,并详细介绍了特定的方法和公式。
-下午好。 我叫Nikolai,我在一家计算机视觉公司VisionLabs工作。 我们的主要业务是面部识别,但我们也拥有适用于增强现实和虚拟现实的技术。 特别是,我们拥有一种可以根据一张照片构建3D人脸的技术,今天我将讨论这一点。

让我们从一个故事开始。 在幻灯片上,您可以看到马云(Jack Ma)的原始照片以及根据该照片构建的3D模型,有两种变体:有和没有纹理,仅几何形状。 这是我们正在解决的任务。

我们还希望能够对此模型进行动画处理,更改注视方向,面部表情,添加面部表情等。
该应用程序在不同的领域。 最明显的是游戏,包括VR。 您也可以做虚拟试衣间-试戴眼镜,胡须和发型。 您可以进行3D打印,因为有些人对面部个性化配件感兴趣。 您还可以为机器人做鬼脸:在机器人的某些显示器上打印和显示。

首先,我将向您介绍一般如何生成3D面,然后我们将继续进行3D重建这一逆生成任务。 之后,我们将专注于动画,并继续应对这一领域中出现的挑战。

生成面孔的任务是什么? 我们想要某种方式来生成形状和表达方式不同的三维面。 这是带有示例的两行。 第一行显示不同形状的面孔,好像属于不同的人。 下面是具有不同表情的同一张脸。

解决生成问题的一种方法是变形模型。 幻灯片最左侧的面是一种平均模型,我们可以通过调整滑块对其应用变形。 这是三个滑块。 在上排中,在增加滑动器的强度的方向上有面,在下排中,在减小的方向上有面。 因此,我们将有几个可自定义的参数。 通过安装它们,您可以为人们提供不同的形状。

可变形模型的一个示例是著名的巴塞尔人脸模型,该模型是通过人脸扫描建立的。 要构建可变形模型,您首先需要带几个人,将他们带到专门的实验室中,并用专门的设备拍摄他们的脸,然后将他们转换为3D。 然后,基于此,您可以制作新面孔。

在数学上如何安排? 我们可以将人脸的三维模型想象为3n维空间中的向量。 这里n是模型中的顶点数,每个顶点对应3D中的三个坐标,因此我们得到3n坐标。

如果我们有一组扫描,则每个扫描都由这样的向量表示,并且我们有n个这样的向量的集合。
此外,我们可以根据数据库中向量的线性组合构建新面孔。 同时,我们希望这些系数有意义。 显然,它们不能完全是任意的,我将很快说明原因。 可以设置限制之一,以使所有系数都在0到1的范围内。必须这样做,因为如果系数是完全任意的,则面将变得不可信。

在这里,我想给参数一些概率意义。 也就是说,我们要查看一组参数,并了解一个人是否可能出现。 这样,我们希望低失真对应于变形的面。

这是操作方法。 我们可以将主成分方法应用于一组扫描。 在输出处,我们得到平均面S0,得到矩阵V,一组主成分,还得到沿主成分的数据变化。 然后,我们可以重新看一下面孔的生成,将面孔表示为一些平均面孔,再加上主要成分的矩阵乘以参数向量。
参数的值是我在较早的一张幻灯片中讲过的这些幻灯片的强度。 我们还可以为参数向量分配一些概率值。 特别地,我们可以同意该向量为高斯。

因此,我们得到了一种允许您生成3D面的方法,并且该生成由以下参数控制。 与上一张幻灯片一样,我们有两组参数,两个向量αid和αexp,与上一张幻灯片上的参数相同,但是αid负责人的脸部形状,而αexp负责情绪。
一个新的向量T也出现了-纹理向量。 它具有与形状矢量相同的尺寸,并且此矢量中的每个顶点都有三个RGB值。 类似地,使用参数矢量β生成纹理矢量。 在这里,参数没有被规范化,这些参数将负责照亮面部和他的位置,但是它们也存在。

这是可以使用变形模型生成的面的示例。 请注意,它们的形状,肤色不同,并且在不同的光照条件下也会绘制出来。
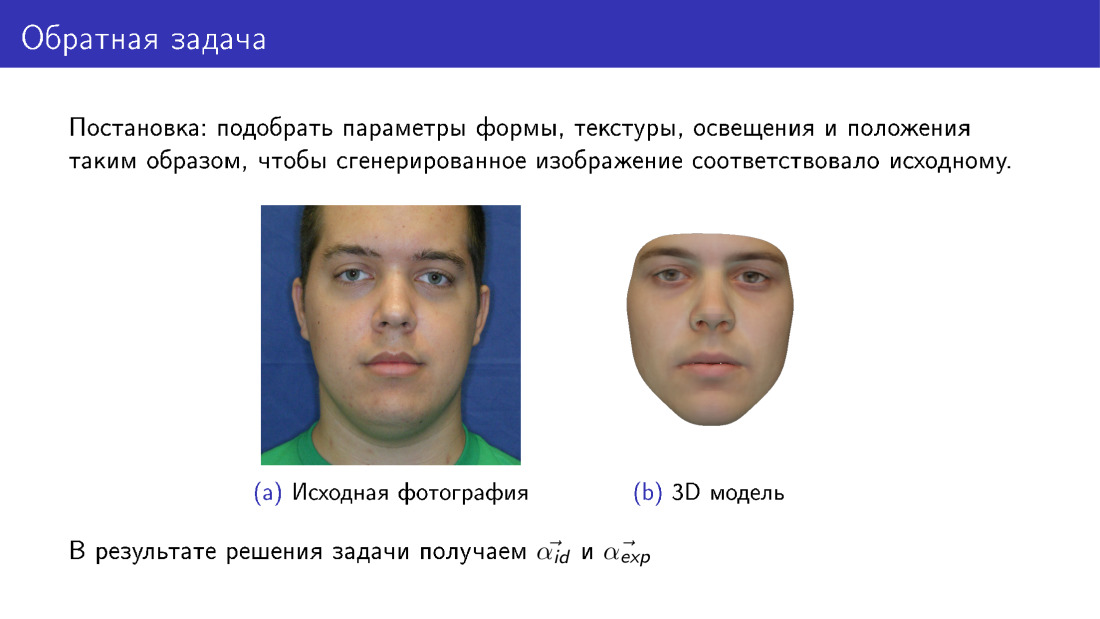
现在我们可以继续进行3D重建。 之所以称为反问题,是因为我们要为可变形模型选择这样的参数,以使我们从中绘制的面尽可能类似于原始面。 这张幻灯片与第一张幻灯片的不同之处在于,此处的面部完全是合成的。 如果在第一张幻灯片上,我们的纹理是从照片中获取的,那么此处的纹理是从可变形模型中获取的。
在输出中,我们将拥有所有参数,在幻灯片上显示了αid和αexp,并且还将具有照明,纹理参数等。

我们说过,我们要确保生成的模型看起来像照片。 使用能量函数确定这种相似性。 在这里,我们只考虑那些我们认为人脸可见的像素中图像的逐像素差异。 例如,如果旋转脸部,则会发生重叠。 例如,the骨的一部分将被鼻子覆盖。 并且可见度矩阵M应该显示出这样的重叠。
本质上,3D重建是为了最小化此能量函数。 但是为了解决此最小化问题,最好进行初始化和正则化。 出于明显的原因,正则化是必要的,因为我们说过,如果不对参数进行正则化并使其完全成为任意参数,则可能会导致变形。 需要初始化是因为任务总体上很复杂,具有局部最小值,并且您不想处理它们。

如何进行初始化? 为此,您可以使用脸部的68个关键点。 自2013-2014年以来,出现了许多算法,可以以相当不错的精度检测68个点,现在它们的精度已接近饱和。 因此,我们有一种方法可以可靠地检测到面部的68个点。
我们可以在能量函数中添加一个新术语,即我们希望模型的相同68个点的投影与面部的关键点重合。 我们在模型上标记这些点,然后以某种方式使模型变形,扭曲,投影点,并确保点的位置重合。 左照片中有紫色和黄色两种颜色的点。 该算法检测了一些点,而从模型中投影了其他点。 在模型的右边标记点,但是对于沿着脸部边缘的点,不会标记一个点,而是会标记整条线。 这样做是因为旋转面部时,这些点的标记必须更改,并且用线选择了该点。

这是我所说的术语,它是描述面部关键点和从模型投影的关键点的两个向量的坐标差异。

让我们回到正则化并从贝叶斯结论的角度考虑整个问题。 向量α等于已知图像中给定值的概率与给定α观察图像的概率乘以概率α的乘积成正比。 如果我们采用该表达式的负对数(必须将其最小化),则将看到负责正规化的术语在此处将具有具体形式。 特别是,这是第二个术语。 回顾我们之前假设向量α是高斯的假设,我们看到负责正规化的术语是参数的平方平方和,这些参数的平方被简化为沿着主成分的变化。

因此,我们可以写出包含三个项的完整能量函数。 第一项负责纹理,负责生成的图像和目标图像之间的像素差异。 第二个术语负责关键点,第三个术语负责正规化。
最小化过程中的项系数未优化,只需设置即可。
此处,能量函数表示为所有参数的函数。 αid-面部形状参数,αexp-表情参数,β-纹理参数,p-我们讨论但尚未形式化的其他参数,这些参数是位置和光照参数。
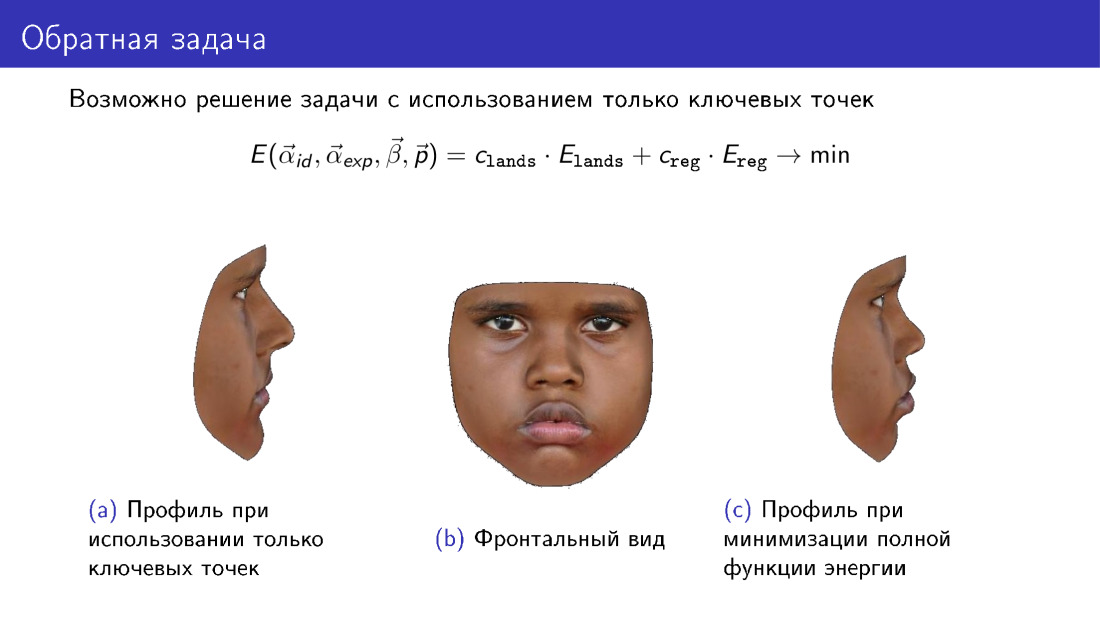
让我们详细谈一谈。 该能量函数可以简化。 从中,您可以排除负责纹理的术语,而仅使用68点传输的信息。 这将使您能够构建某种3D模型。 但是,请注意模型轮廓。 左侧是仅在关键点构建的模型。 右侧是构建时使用纹理的模型。 请注意,右侧的轮廓与中央照片更为吻合,后者代表面部的正视图。

使用现有算法构建人脸3D模型的动画效果非常简单。 回想一下,在构建3D模型时,我们获得了两个参数向量,一个负责形状,另一个负责表达式。 用户和化身的这些参数向量将始终具有自己的参数。 用户有一个形式参数矢量,化身有一个不同的形式参数。 但是,我们可以使负责表达的向量变得相同。 我们将采用负责用户面部表情的参数,并将其简单地替换为头像模型。 因此,我们将把用户的面部表情转移到化身上。
让我们谈谈这方面的两个挑战:工作速度和有限的可变形模型。

速度确实是一个问题。 使总能量函数最小化是一项计算量很大的任务。 特别是,这可能需要20到40,平均需要30秒。 这足够长了。 如果我们仅在关键点上建立三维模型,则结果会更快,但是质量会因此受到影响。

如何解决这个问题? 您可以使用更多的资源,有人可以在GPU上解决此问题。 只能使用关键点,但是质量会受到影响。 您可以使用机器学习方法。

让我们按顺序看。 这是2016年的工作,其中用户的面部表情已转移到特定视频中,您可以使用脸部控制视频。 在此,使用GPU实时执行3D模型的构建。

以下是使用机器学习的方法。 想法是,我们可以首先使用大量的人脸,使用长而精确的算法为每个人脸构建3D模型,将每个模型作为一组参数呈现,然后训练网格来预测这些参数。 特别是,在2016年的这项工作中,使用了ResNet,它将图像作为输入,并将模型参数提供给输出。

三维模型可以用另一种方式表示。 在2017年的这项工作中,不是将3D模型显示为一组参数,而是一组体素。 网络预测体素,将图片转换为三维图像。 值得注意的是,根本不需要3D模型的网络培训选项是可能的。

其工作原理如下。 这里最重要的部分是图层,该图层可以将可变形模型的参数作为输入并渲染图片。 它具有如此出色的属性,通过它您可以进行错误的反向传播。 网络接受图像作为输入,预测参数,将这些参数提供给渲染图像的层,将该图像与输入进行比较,接收错误,将错误传播回去并继续学习。 因此,网络学习预测三维模型的参数,仅将图片作为训练数据。 这是非常有趣的。

我们谈论了很多关于准确性的问题-特别是如果我们从能量函数中剔除某些术语,准确性会受到影响。 让我们形式化这意味着什么,如何评估3D人脸重建的准确性。 为此,我们需要使用专用设备获得的真相真相扫描,使用可以保证准确性的方法。 如果存在这样的基础,那么我们可以将重建的模型与地面真实性进行比较。 这很简单:我们计算从建立的模型顶点到地面真实顶点之间的平均距离,然后将其归一化为扫描的大小。 之所以必须这样做,是因为这些面孔不同,有些面孔更大,有些面孔更小,而小面孔上的误差也会更小,这仅仅是因为面孔本身更小。 因此,需要标准化。

我想谈谈我们的工作,它将在工作坊中,有ECCV。 我们做类似的事情,我们教MobileNet预测可变形模型的参数。 作为训练数据,我们使用为300W数据集中的照片构建的3D模型。 根据BU4DFE扫描评估准确性。
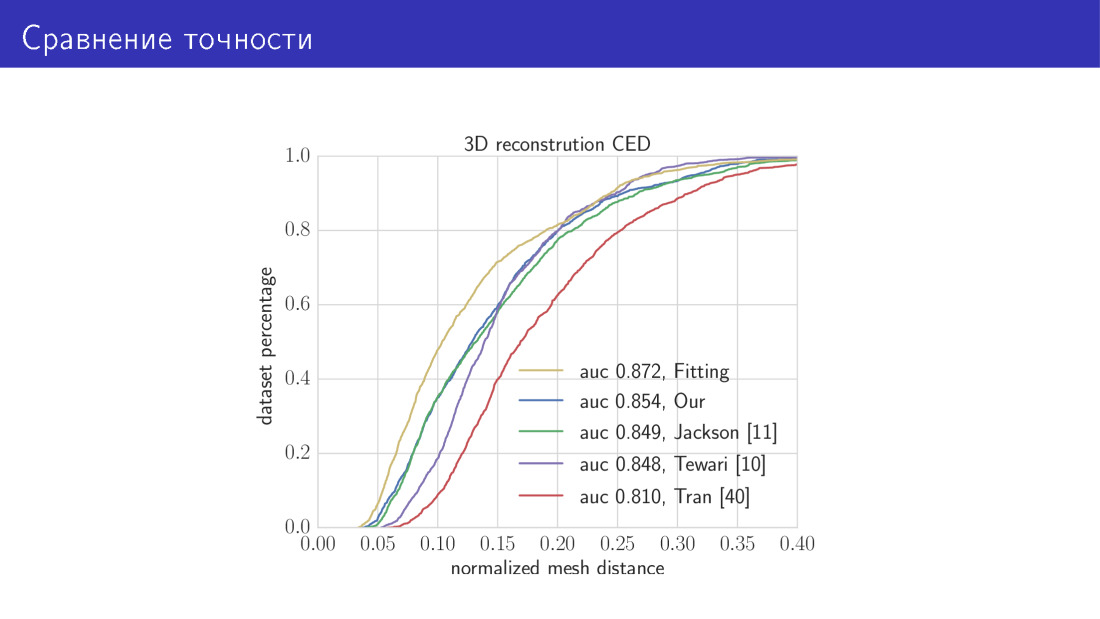
这是结果。 我们将两种算法与最新技术进行比较。 此图中的黄色曲线是一种算法,耗时30秒,其作用是使总能量函数最小。 沿着X轴的就是我们刚才所说的误差,即顶点之间的平均距离。 Y轴是误差小于X轴的图像所占的比例,在此图中,曲线越高越好。 下一条曲线是我们基于MobileNet的网络。 接下来,我们讨论了三幅作品。 参数预测网络和体素预测网络。
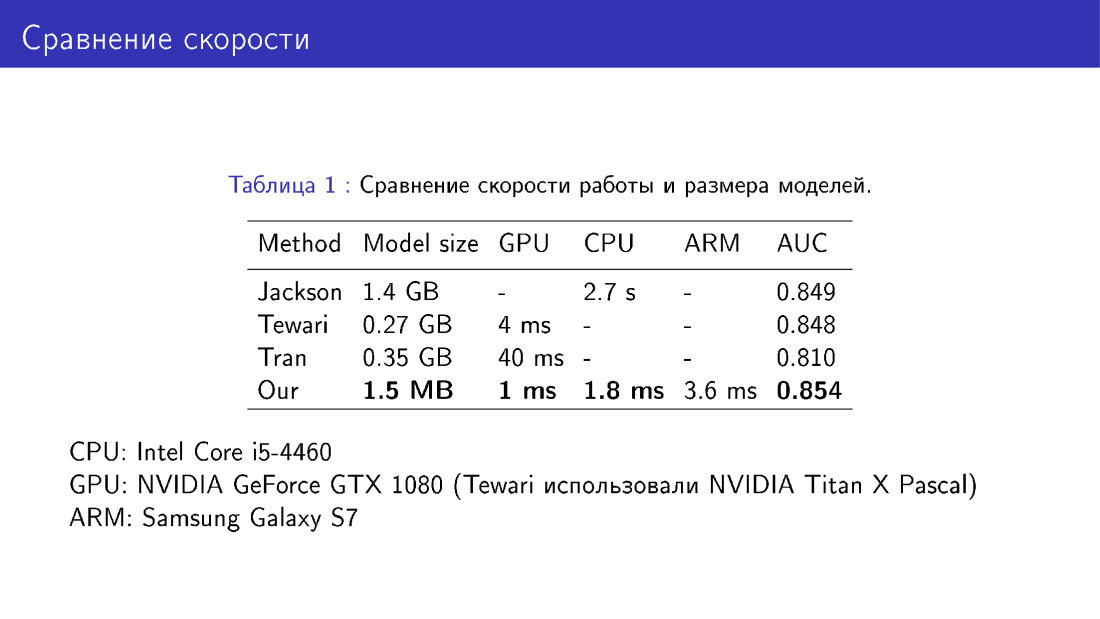
我们还在模型大小和速度方面将我们的网络与同行进行了比较。 这是一个胜利,因为我们使用MobileNet非常容易。
第二个挑战是可变形模型的局限性。

注意左脸,看一下鼻子的翅膀。 鼻子的翅膀上有阴影。 阴影的边界与照片中的鼻子的边界不一致,因此获得了缺陷。 其原因可能是,可变形模型原则上不能建立所需形状的鼻子,因为该可变形模型仅通过扫描200个面获得。 我们希望鼻子是正确的,如右图所示。 因此,我们需要以某种方式超越可变形模型的框架。

这可以使用网格的非参数变形来完成。 这是我们要解决的三个任务:修改脸部的局部(例如鼻子),然后将其嵌入到脸部的原始模型中,甚至使其他所有内容保持不变。

这可以如下进行。 让我们回到将网格指定为3n维空间中的向量的方式,然后看一下平均算子。 这是一个运算符,该运算符在S中使用标头将每个顶点替换为其邻居的平均值。 峰的邻居是通过边缘连接到峰的邻居。
我们将定义一个特定的能量函数,该函数描述顶点相对于其邻居的位置。 我们希望峰相对于其相邻峰的位置保持不变,或者至少不发生太大变化。 但是同时,我们将以某种方式修改S。此能量函数称为内部函数,因为还会有一些外部项,例如,鼻子应具有给定的形状。
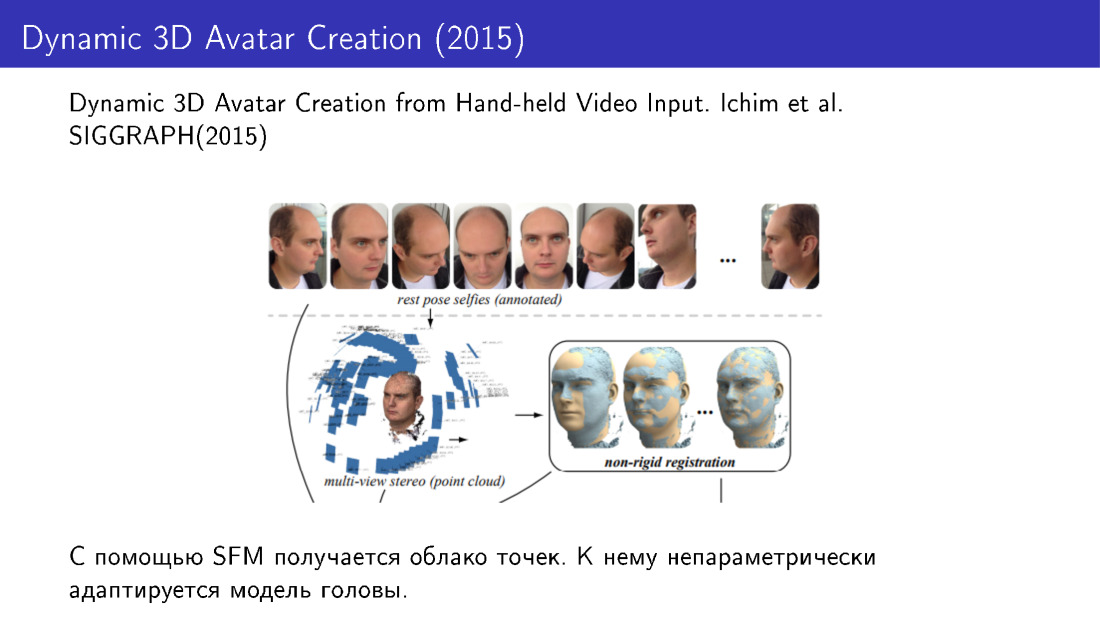
例如,在2015年的工作中使用了此类技术。 他们从几张照片中进行了3D人脸重建。 我们从手机上拍摄了几张照片,接收了点云,然后使用非参数修改将脸部模型调整为该云。
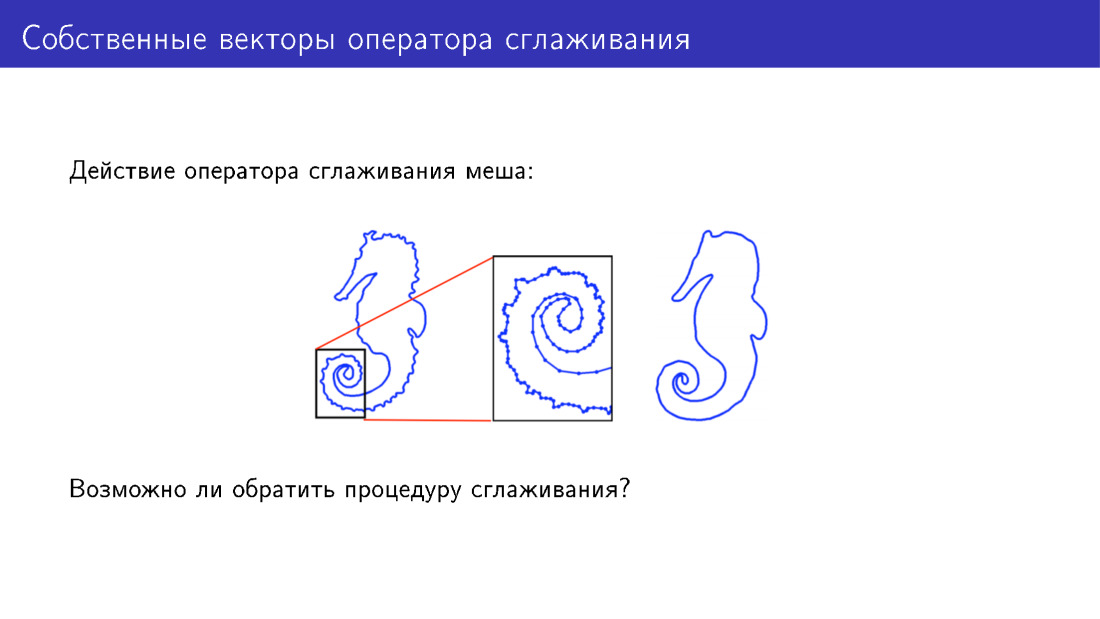
您可以通过其他方式超越可变形模型。 让我们详细介绍一下平滑运算符的作用。 在这里,为简单起见,介绍了已应用此运算符的二维网格。 左侧的模型上有许多细节;右侧的模型上,这些细节已被平滑。 但是我们可以做些什么来添加细节而不是删除它们吗?

. .
? -: - . . , 2016 . , .