早些时候,我们
谈到了最强大的日本核物理研究超级计算机。 现在,他们在日本正在制造Exaflops超级计算机Post-K-日本人将是首批推出具有这种计算能力的计算机的人之一。
调试计划于2021年进行。
上周,富士通谈到了A64FX芯片的技术特性,它将构成新的“机器”的基础。 我们将为您介绍有关该芯片及其功能的更多信息。
 /照片松井敏宏 CC /日本超级计算机K计算机
/照片松井敏宏 CC /日本超级计算机K计算机规格A64FX
预计到
2018年6月 ,Post-K的计算能力
将比现有最强大的
IBM Summit超级计算机
的性能
提高近十倍。
超级计算机具有与基于A64FX Arm的芯片相似的性能。 该芯片
包括 48个用于计算操作的内核和4个用于控制它们的内核。 它们全部平均分为四个组-核心内存组(CMG)。
每个组具有8 MB的L2缓存。 它连接到内存控制器和NoC接口(“
片上网络 ”)。 NoC将各种CMG与PCIe和Tofu控制器相连。 后者负责处理器与系统其余部分之间的通信。 豆腐控制器具有十个端口,吞吐量为12.5 GB / s。
芯片布局如下:
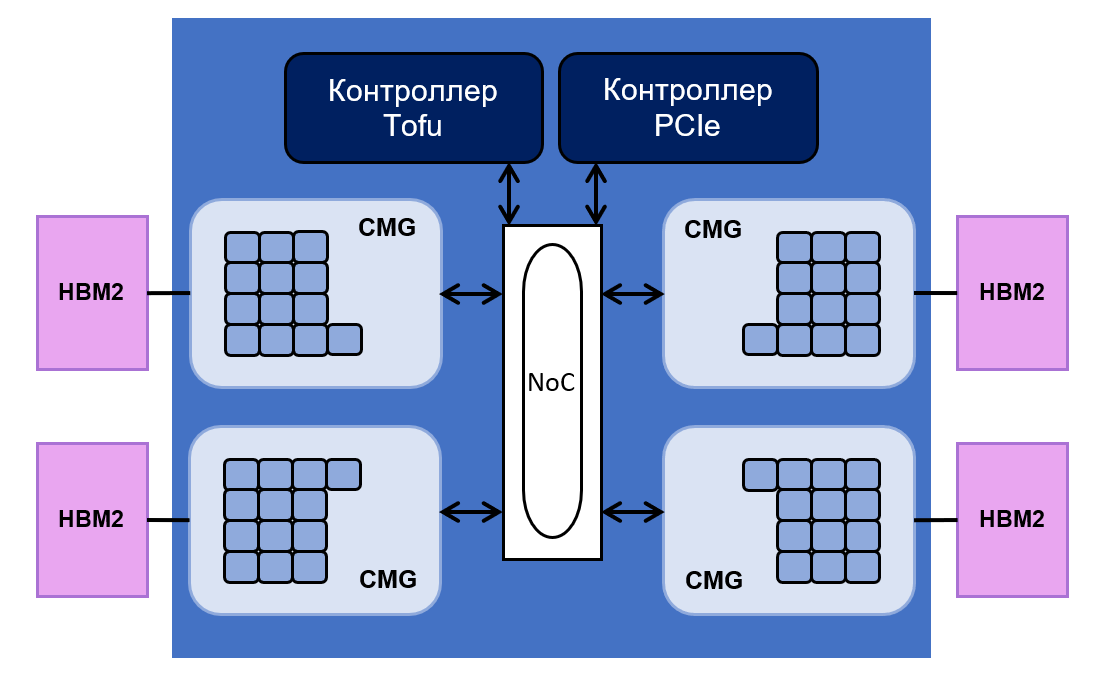
处理器的总
HBM2内存为32 GB,其吞吐量等于1024 GB / s。 富士通表示,浮点运算的处理器性能对于64位运算达到2.7 teraflop,对于32位运算达到5.4 teraflop,对于16位运算达到10.8 teraflop。
Post-K的创建由Top500资源编辑器监控,他们编辑了功能最强大的计算系统列表。 根据他们的说法,为了在一个exaflops中实现性能,超级计算机使用了37万多个A64FX处理器。
该设备将首先使用称为可伸缩矢量扩展(SVE)的矢量扩展技术。 它与其他
SIMD架构的不同之处在于,它不
限制矢量寄存器
的长度,而是为其设置有效范围。 SVE支持长度为128到2048位的向量。 因此,任何程序都可以在支持SVE的其他处理器上运行,而无需重新编译。
使用SVE(由于它是SIMD功能),处理器可以同时使用多个数据阵列执行计算。 这是NEON功能的其中一条指令的示例,该指令已在其他Arm处理器体系结构中用于矢量计算:
vadd.i32 q1, q2, q3
它将来自128位寄存器q2的四个32位整数与128位寄存器q3中的相应数字相加,并将结果数组写入q1。 在C中此操作的等效项如下所示:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
此外,SVE支持自动矢量化。 自动矢量化程序分析代码中的周期,并在可能的情况下使用矢量寄存器执行周期。 这样可以提高代码性能。
例如,C中的函数:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
它将被编译如下(对于32位Arm处理器):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
如果使用自动矢量化,则它将如下所示:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
在这里,SIMD寄存器q8和q9加载了r5和r4指向的数组中的数据。 之后,vadd指令一次添加四个32位整数值。 这增加了代码量,但是通过这种方式,每次循环迭代都会处理更多的数据。
还有谁创造exaflops超级计算机
Exaflops超级计算机不仅在日本制造。 例如,中国和美国的工作也在进行中。
在中国创建天河3(Tianhe-3)。 它的原型已经在天津国家超级计算中心
进行了测试 。 该计算机的最终版本计划于2020年完成。
 / photo O01326 CC / 天河2号超级计算机-天河3号的前身
/ photo O01326 CC / 天河2号超级计算机-天河3号的前身天合三号的核心
是中国Ph处理器。 该设备包含64个内核,
性能为512 gigaflops,内存带宽为204.8 GB / s。
还为
Sunway系列的机器创建了工作原型。 它正在济南国家超级计算机中心进行测试。 根据开发人员的说法,计算机上当前正在运行约35个应用程序-这些是生物医学模拟器,用于处理大数据的应用程序以及用于研究气候变化的程序。 预计计算机上的工作将在2021年上半年完成。
至于美国,美国人
计划在 2021年之前
制造出exaflops计算机。 该项目称为Aurora A21,
美国能源部的
阿贡国家实验室以及Intel和Cray都在研究该项目。
今年,研究人员已经为“极光早期科学计划”
选择了十个项目,他们的参与者将是第一个使用这种新型高性能系统的人。 其中包括创建大脑神经元
图谱 ,研究暗物质和开发粒子加速器模拟器的程序。
Exaflops计算机将使构建复杂的研究模型成为可能,因此许多科学项目都在等待此类机器的创建。 最雄心勃勃的项目之一是人脑计划(HBP),其目标是创建人脑的完整模型并研究神经形态计算。 据HBP的科学家称,新的exaflops系统的使用可以从它们存在的第一天就开始发现。
我们在IT-GRAD中的工作:• IaaS • PCI DSS托管 • Cloud-152
IaaS企业博客中的内容: