
在
上一篇关于国家风险管理的文章中,我们介绍了以下基础知识:为什么国家当局应该管理风险,在哪里寻找风险以及评估的方法是什么。 今天,我们将讨论风险分析过程:如何确定其发生原因并确定违规者。
风险评估
要评估风险(即使在静态但动态的方法框架内),您也需要找出其原因,发生条件,并确定主要特征:实施的可能性和潜在损害。
以海关清关为例:在将任何产品进口到该国时,除了各种不同的信息(成本,重量,包装,发件人,收件人等)外,必须根据特殊分类器在申报中做出声明-外国经济活动(FEA)的商品名称。 然后,该代码将根据海关关税(TN FEA +费率)确定关税。
关税是一个复杂的分类:乍一看,某些商品可以归为不同税率的不同代码。 例如,您只能通过研究其图纸来处理复杂的采矿设备。 因此,进口商倾向于声明错误的代码(但与真相类似),以减少预算支出。
因此,我们
确定了风险 -在报关单中声明不可靠的产品代码,以低估海关付款。 原因是分类器中存在具有不同税率的“边界”职位。
很难发现这种风险发生的条件,即在实践中何时何物发生。 为此,您需要进行
风险分析 :研究对控制对象的观察历史,找出何时和谁声明了错误的产品代码,并确定这些情况的一些一般特征。 这样就可以为未来的风险管理制定
规则 :我们将哪些对象归因于风险以及要进行哪些审计。
获得这些规则的最简单方法是信任员工的专业判断。
专家规则
这种识别风险的规则是主题专家。 他们以工作经验为指导,或总结每天遇到违规者的同事的观点。 结果是“ if ... then ...”形式的简单判断。
在这种情况下,风险的发生概率和威胁造成的潜在损害是通过“肉眼”或粗略估算确定的。
专家规则的优点是易于人为汇编和解释。 缺点是,许多人,既是违反者又是可观的经济活动主体,可能同时落入该规则之下。 因此,控制的有效性将很低。 同时,一些违规者将经过,专家无法检测并考虑到其模式。
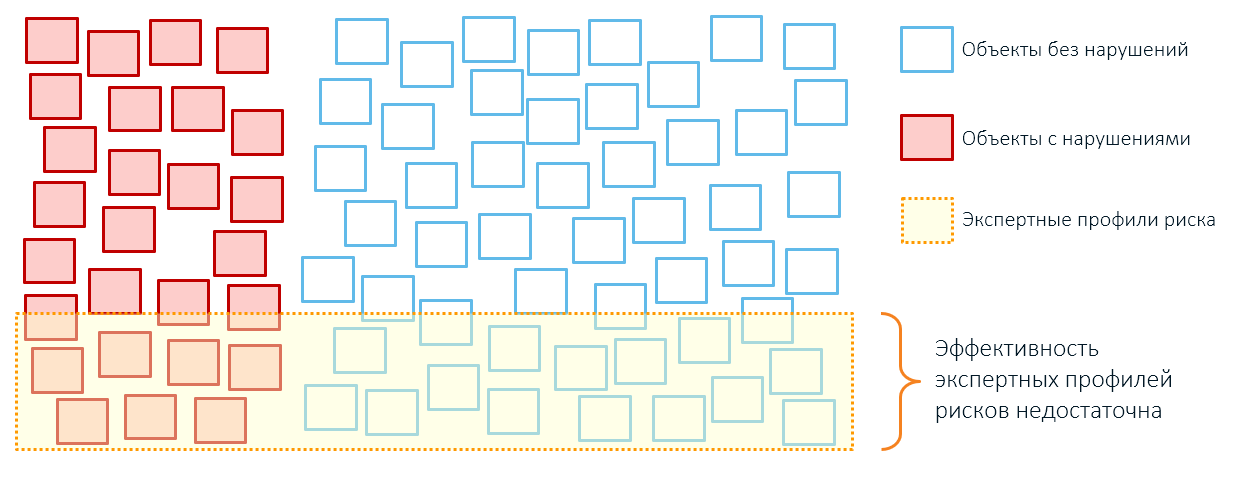
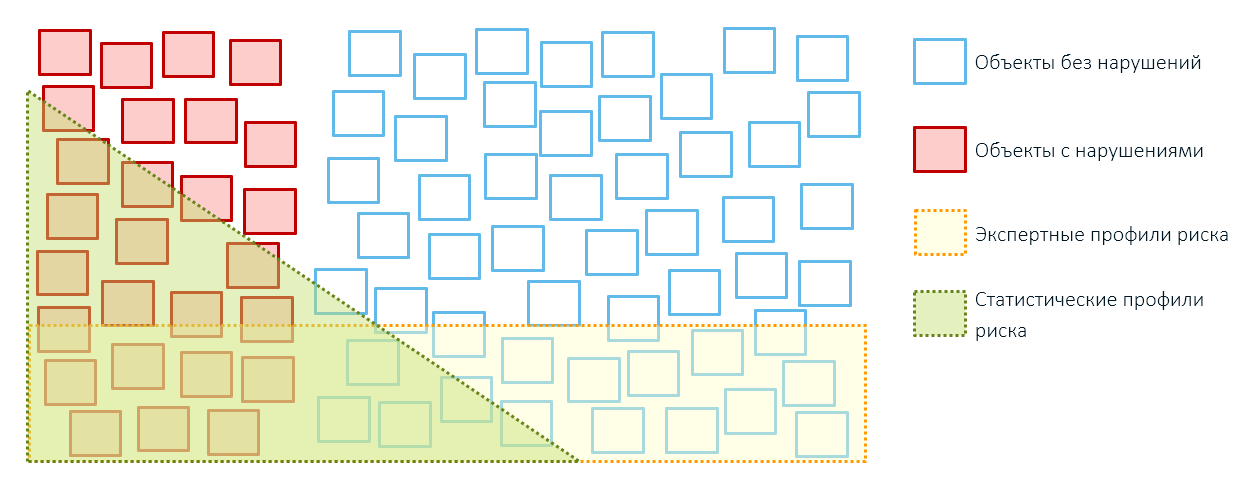
例如,海关管制的一条专家规则告诉我们,所有批次的苹果的价值低于特定阈值都与风险传递有关:

当我们执行控制时,我们会发现不规则的货物(红色)和正常交付的货物(绿色),其低廉的成本可以通过个人折扣,发件人与库存积压或企业的经济模式来解释。
超出此条件值阈值(红线)的所有内容都将失去控制(灰色圆圈)。 但是,如果我们也对它们进行检查,我们将发现真正合法的交付和实际价值甚至高于声明中声明的交付(带有红色虚线轮廓的灰色圆圈)并且没有全额支付关税的交付。
因此,专家规则的应用通常会导致过多地覆盖控制对象和降低性能(还记得我们第一篇文章中的方框吗?):
不应责怪专家:人类意识只能在人类可以操作的物体上进行(一次有趣的文章发表在哈勃(Habr)上,作者建议将其数量限制为七个)。 因此,大笔画而不是确切的细节:假设发生火灾的风险仅取决于建筑物的建造年份,位置区域和居民类别。 所有这些特征曾经被“扮演”过:一所老房子里起火了,一间房间在功能失调的地方着火了。 因此,专家预计这种类型的物体将对未来造成威胁。
但并不是所有这些“危险”建筑物都将被烧毁,即使它们属于专家统治之下:许多古老的木制房屋屹立不动。 一些功能失调的房屋多年来一直没有着火站立。 只是专家无法考虑到危险物体的某些微妙的个性特征。
这是机器学习发挥作用的地方,可帮助创建
统计风险概况 。 它们是在我们将数据分析技术应用于违规历史和有关受控对象的信息时形成的。
统计风险概况
在这种情况下,我们解决了二进制分类问题:一种专门的分析算法可以自己确定对象的哪些特征,从而可以将它们归因于“坏”或“好”。 如果一切操作正确,最后我们将获得相当准确的风险评估:详细的条件,自动计算的概率以及潜在的损害(通过专家方法也可以“专家”方式确定)。 这些特征定义了“风险概况”-什么,在哪里,何时以及如何令人恐惧。
统计风险概况以不同的方式创建。 它可以基于决策树或随机森林。 您可以应用具有大量隐藏层的棘手神经网络。
但是,SAS认为,出于状态控制的目的,最好基于解释算法(例如
回归或
决策树)创建统计风险概况。 实践表明,即使国家机构是对机器的准确但难以理解的预测,但如果它不能解释为什么这个受人尊敬的人被标记为坏蛋,国家机构就很难确定自己的方向。
国家机构需要准确地了解哪些因素表明存在威胁,以及哪些违规者具有相同的特征,因为存在批准管理决策的程序(特定情况为风险状况)。 官员应了解自己到底是要“投入战斗”的原因,因为他对风险简介的结果负责。
任何验证均应说明理由,并且该说明应以文字表达。 否则,您必须在检察官面前脸红一些,并说明事实证明,该国家机构是根据deus ex machina的神秘指示“捏造”国内业务的。
因此,统计风险概况也看起来像是可以阅读和理解的规则。 只有描述可能违反者的特征列表比专家简介更大,更复杂:
 *配置文件参数值已更改且与实际值不对应
*配置文件参数值已更改且与实际值不对应一组
风险指标 (条件)可能看起来有些奇怪。 但这不是“伟大的法宝”-仅仅借助机器学习技术和我们所拥有的有限信息,我们就描述了导致破坏的人类行为的某种隐藏模式。
税收控制方面也是如此-违规者可以从一定数量的特定交易范围,申报截止日期,公司员工人数,帐户数量以及另外30种不同的参数(与总纳税人的数量相区别)中共同描述低估了增值税的不法企业家。
一个人将无法比较所有这些特征,他将管理三个或五个,这更容易理解。 而且程序可以。 根据需要详细。 建立模型时,该算法会自动迭代大量数据,并找出违法者的共同点-即使这是对黄网中的红色领带的热爱。
这与罪犯个人特征的描述相似:鼻子,耳朵的形状,眉毛的弯曲,衬衫的颜色和脚的长度。 我们不知道他的脸,身高和体重,但是我们有他的一千个特征,包括左手小指骨上的头发长度。 这些参数中的每一个都不会单独给出犯罪意图-您不需要仅将一个人的耳廓弯曲半径戴上手铐。 但是,这些特征的全部集合共同构成了入侵者的相当准确的描述:
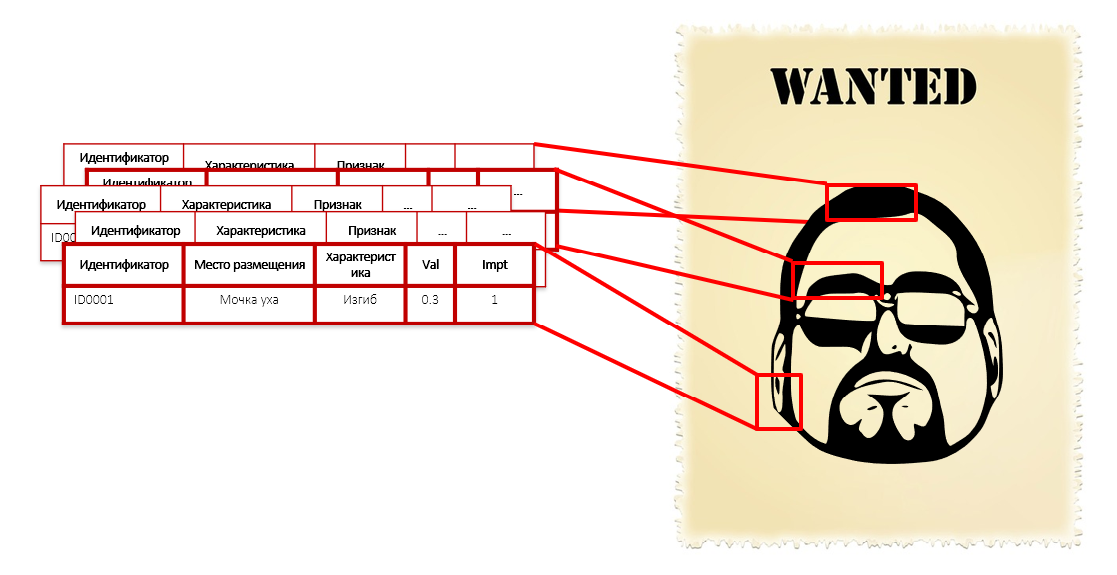
当我们根据对隐藏模式的分析从将专家规则应用到统计分析时,我们摆脱了故意无效的检查。 持续控制的巨大领域缩小了对属于
不正当行为模式的对象的影响。
从上面的海关示例中召回苹果。 通过将检查的历史记录提交到统计模型的入口,我们获得了一个风险简介,其中考虑了进口商-违规者的行为特征,无论他们申报商品的价格如何:
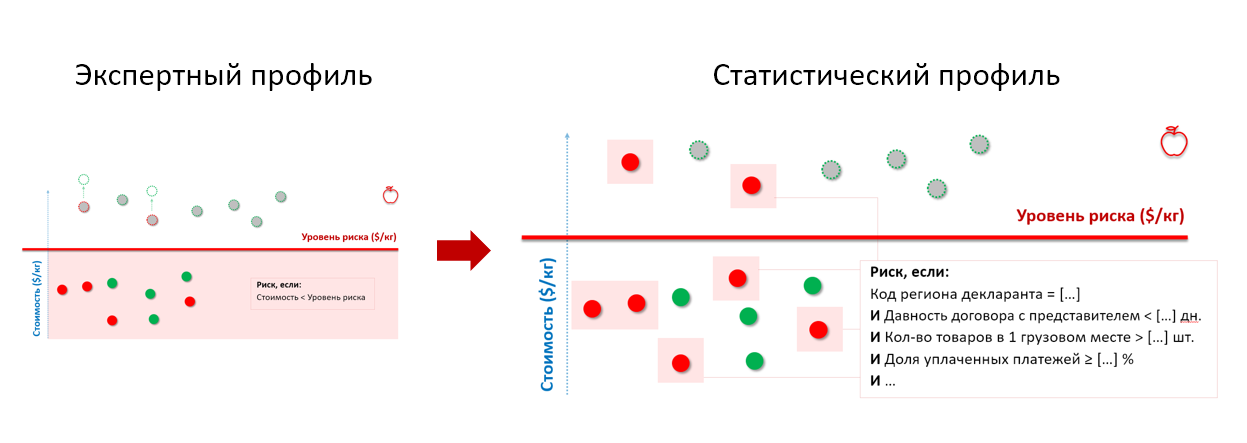 *一组风险简介参数已更改,与实际参数不符
*一组风险简介参数已更改,与实际参数不符这就是使用“决策树”类算法构建统计风险概况的方式-它的每个级别越来越多地将一组测试实体分为“好”和“坏”,并显示出分离的特征最重要(在SAS Visual Statistics屏幕快照中):
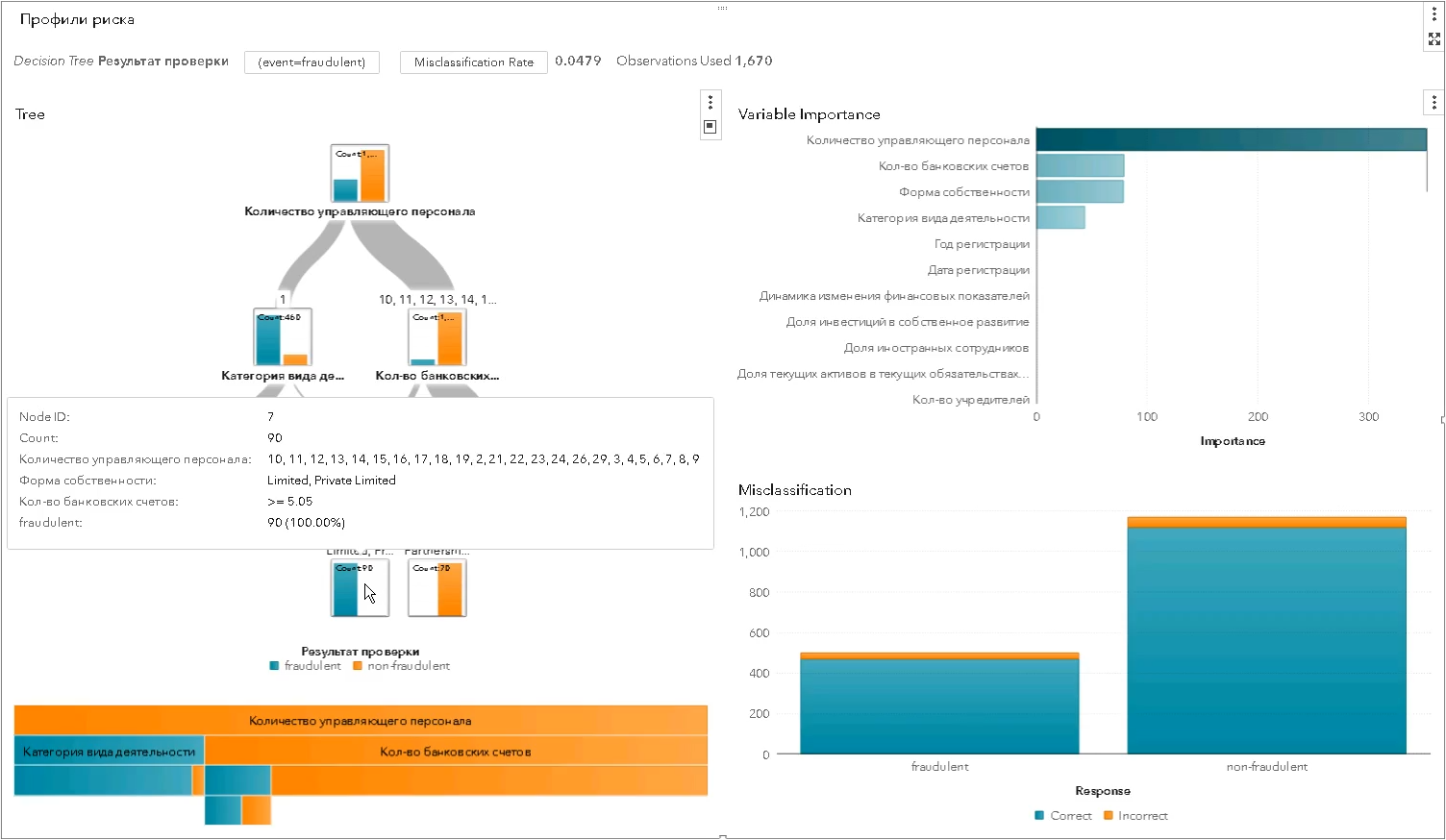
统计资料比专家资料要好-更准确,更具选择性和公正性。 它们通过减少空闲的“锻炼”数量来帮助提高检查的有效性:
统计配置文件的缺点是它们受过去识别违规情况的经验的指导。 以知名的方案。
如果在海关管制史上,在进口货物时出现轻描淡写的情况,该算法将发现违规者的迹象并形成统计风险概况。 如果我们正在寻找某种尚未引起国家机构注意的新违规行为,并且我们不知道其特征,那么我们就必须“通过接触”采取行动-通过反复试验。
未知搜寻
您可以通过几种方式感受未知。
首先是
随机抽样 。 我们(在力所能及的范围内)采用任意对象-产品,企业,建筑物或公民-并仔细考虑。 这种方法是相当公正的,但不是很有效-一个受人尊敬的主题同样可以落入“汇报”。 国家机构的实力和预算资金将白费。
二是
识别异常 。 在这种情况下,将使用一个对象进行验证,将其参数与其余参数区分开。 当我们分析异常事件时,不仅随机地“戳”一堆对象,发现违规的可能性也更高。
例如,进行环境监督时,发现工厂意外消耗大量电力:
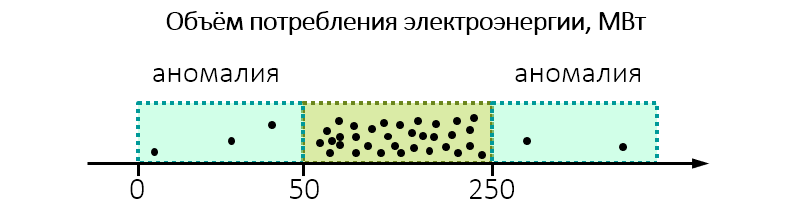
也许值得仔细研究一下,并检查工厂是否没有超过允许的排入水中或向空气排放。
或者海关货物的重量与包装的重量比例不寻常:
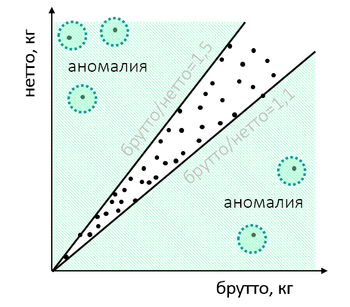
经过检查,结果可能是进口商为了弥补某些违规行为而“举足轻重”:低估了成本,因此想收紧其中一个测试值或以其他为幌子发行一些商品。 如果挖掘得当,“自然”体重特征与虚拟特征不同。
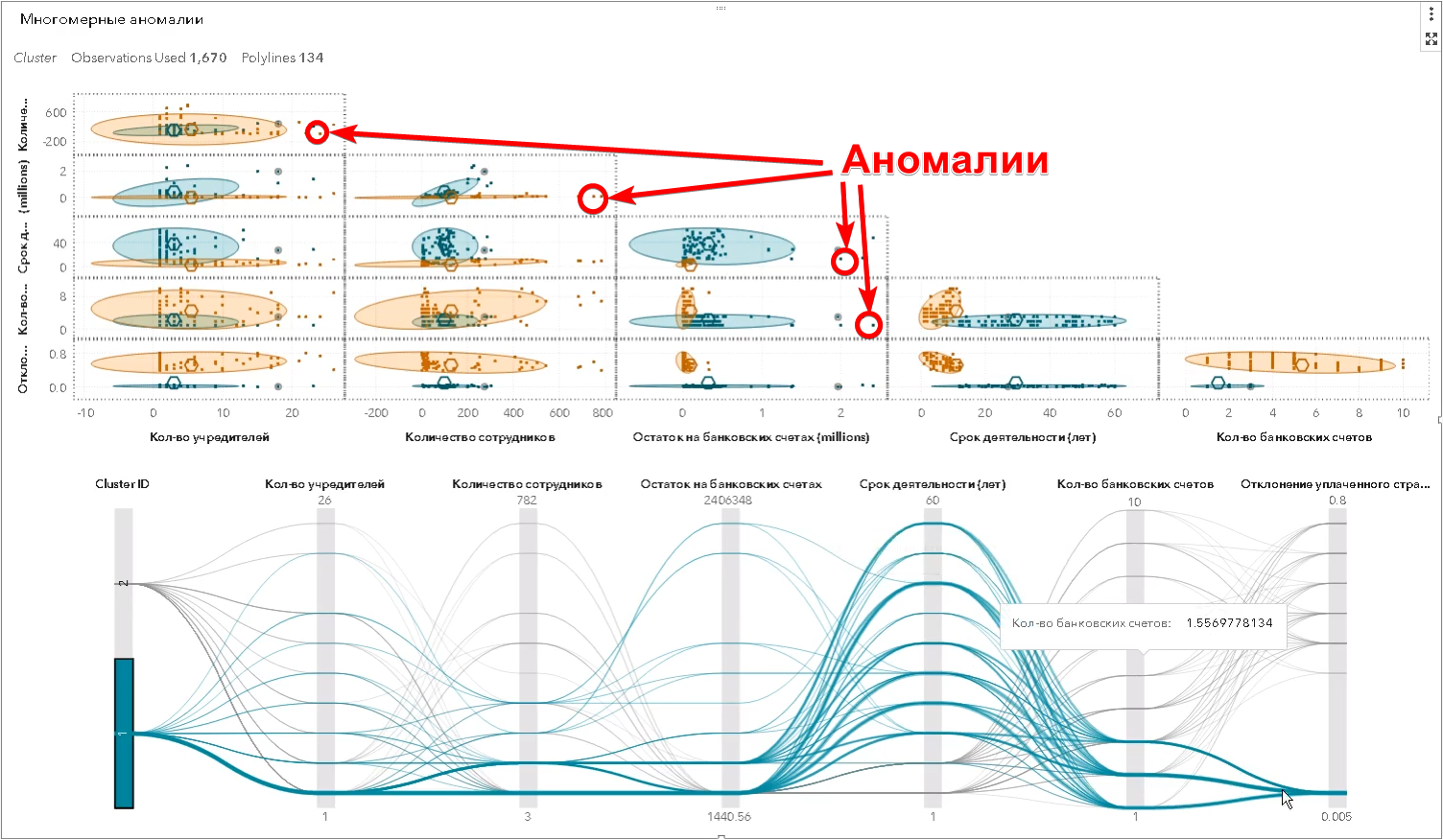
但是,这些是人们能够看到的最简单的示例。 实际上,对异常的搜索发生在属性的多维空间中-可能有数百个属性。 该算法完成了人类无法做的事情-它可以同时找到在许多符号上与其他对象明显不同的对象,并确定所谓的多维离群值(在SAS Visual Statistics的屏幕快照中):
此外,除了人类可以理解的范围之外,使用图表(在SAS Social Network Analysis的屏幕快照中)将不同的公司之间存在多种法律关系可视化:
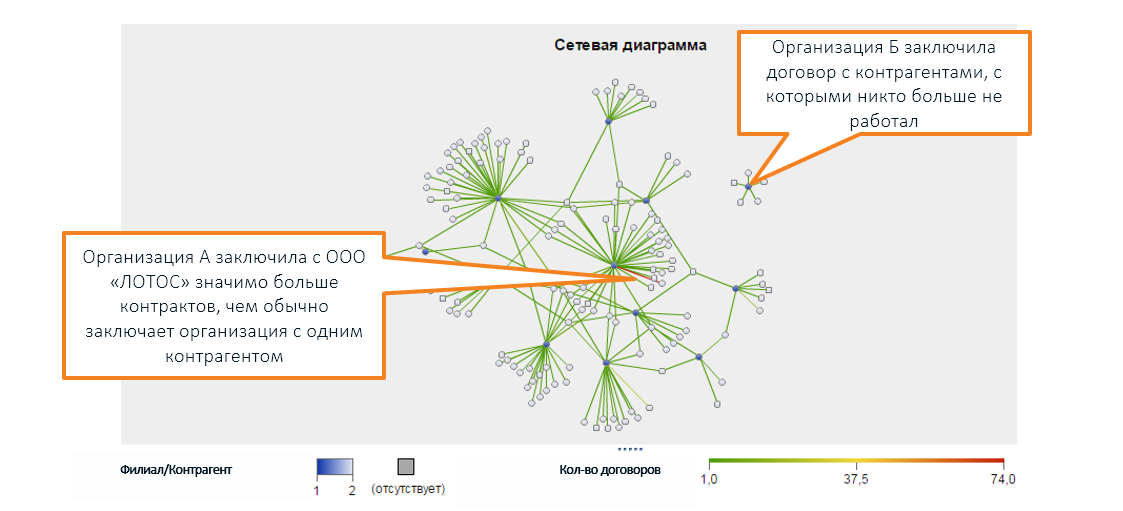 *组织名称是发明的,与真实公司的巧合是随机的
*组织名称是发明的,与真实公司的巧合是随机的异常的特征不一定表示存在问题。 该检查可能未显示任何内容:是的,这些指标很奇怪,但是没有违反。
异常不是危险,而只是“一些异常”。 需要异常特征来提供新的“原始材料”以用于构建专家或统计特征,因为异常验证的结果包括在受控对象的观察历史中。
混合方式
通过将识别风险的所有三种方法结合起来,可以达到国家机构(不仅限于其中)的控制和监督活动的最佳效果:专家规则,基于机器学习技术的统计风险概况和异常状况。 同时,最好使用专家规则来减少对象的覆盖范围,而仅将它们留给有针对性的行政影响(例如,实施制裁-我们阻止来自这些国家/地区的商品):
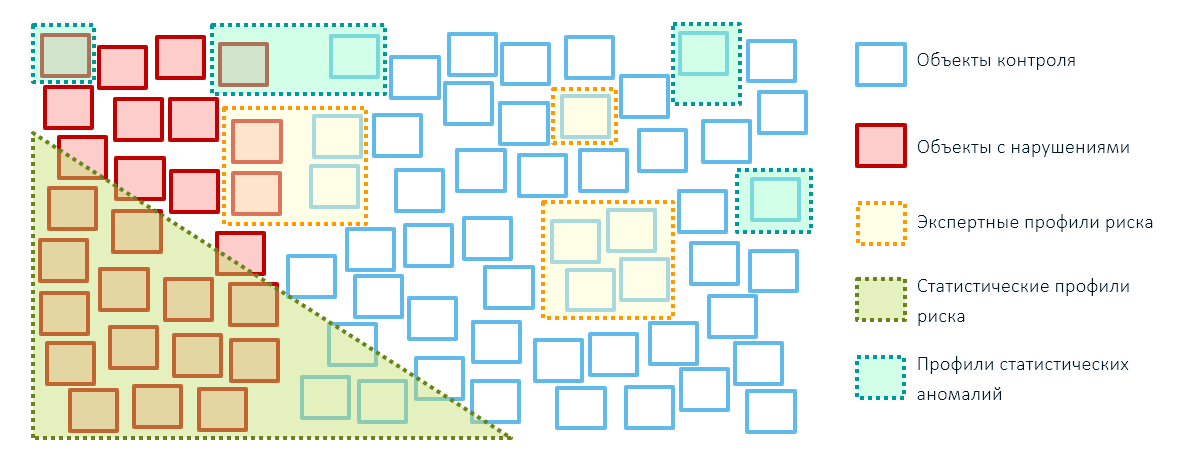
在建立风险管理系统的最初阶段,您不能没有专家规则,因为创建分析模型需要先例基础。 要创建它,有必要根据专家的风险状况进行检查,然后再进入数学模型。
SAS相信,国家控制和监督活动的未来是基于一种混合方法,该方法将结合国家机构的经验和其雇员的专业知识与现代机器学习技术。 在这种情况下,我们将所有三个模块的结果简化为一个综合风险评估:
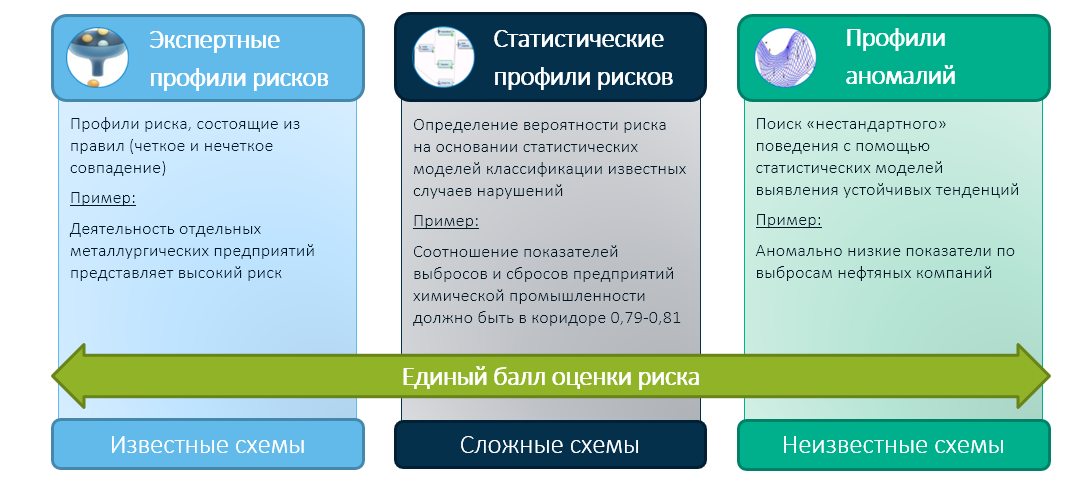
集成评估(例如基于专家决策矩阵)已经确定了控制机构的选择-检查谁和信任谁。
在下一篇文章中,我们将分析使已识别威胁最小化的方法,并思考为什么反馈和动态风险重新评估如此重要。