作为产品支持的一部分,我们不断为用户提供服务。 这是一个标准过程。 与任何过程一样,需要定期对其进行严格的评估和改进。
我们知道一些系统的问题将很容易解决,并且在可能的情况下也不会吸引其他资源:
- 分发应用程序时出错:我们得到了“异形”,其他团队有时得到了“我们的”。
- 很难评估应用程序的“复杂性”。 如果应用程序很复杂,则可以将其传递给强大的分析人员,并且只需简单的应用程序,初学者就可以应对。
解决这些问题中的任何一个都将积极影响处理应用程序的速度。
机器学习的应用程序,用于对应用程序内容的分析,似乎是改善调度过程的真正机会。
在我们的情况下,可以通过以下分类问题来表述该问题:
- 确保将请求正确分配给:
- 配置单元(应用程序中的5个或“其他”中的一个)
- 服务类别(事件,信息请求,服务请求)
- 估计关闭请求的预期时间(作为“复杂性”的高级指示)。
什么以及我们将如何工作
为了创建算法,我们将使用“标准集”:带有scikit-learn库的Python。
对于实际应用,将实现两种方案:
培训内容:
- 从应用程序跟踪器获取“培训”数据
- 运行用于训练模型的算法,保存模型
用法:
- 从应用程序跟踪器接收数据进行分类
- 模型加载,应用分类,保存结果
- 根据分类更新跟踪器中的应用程序
与管道相关的所有内容(与跟踪器的交互)都可以在任何地方实现。 在这种情况下,尽管可以在python中继续,但仍编写了powershell脚本。
机器学习算法将以.csv文件的形式接收分类/训练数据。 处理的结果也将输出到.csv文件。
输入数据
为了使算法尽可能独立于服务团队的意见,我们将仅考虑从应用程序创建者收到的数据作为模型的输入参数:
- 简短说明/标题(文字)
- 问题的详细描述(如果有)(文本)。 这是应用程序通信流中的第一条消息。
- 客户名称(员工,类别)
- 根据要求包括在监视列表中的其他员工的名称(员工列表)
- 申请备案时间(日期/时间)。
训练数据集
为了训练算法,使用了过去3年的未接电话数据-约3500条记录。
另外,为了教会分类器识别“其他”配置单元,将由其他部门处理的针对其他配置单元的封闭应用程序添加到了训练集中。 附加记录总计-约17,000。
对于所有此类其他请求,配置单元将设置为“其他”
预处理
文字内容
文本预处理非常简单:
- 我们将所有内容翻译成小写
- 仅保留数字和字母-用空格替换其余部分
通知列表(监视列表)
该列表可以以字符串形式进行分析,其中名称以姓,名的形式显示,并用分号分隔。 为了进行分析,我们将其转换为字符串列表。
通过合并列表,我们可以基于训练集的所有应用获得一组唯一的名称。 此一般列表将构成名称的向量。
申请处理期限
就我们的目的(优先级管理,发布计划)而言,将服务的持续时间将应用程序归为特定类别就足够了。 它还允许您使用少量类将任务从回归转移到分类。
文字内容
- 合并“标题”和“问题描述”。
- 传递给TfidfVectoriser形成单词向量
要求者姓名
由于期望创建应用程序的人将成为进一步分类的重要属性-我们将使用DictionaryVectorisor将其分别转换为一种编码
通知列表中包含的人员名称
监视列表应用程序中包含的人员列表将根据之前准备的所有名称转换为向量:如果该人员在列表中,则相应的组件将设置为1,否则设置为0。一个应用程序可以在监视列表中包含多个人员-分别是多个组件将具有单个值。
建立日期
创建日期将以一组数字属性的形式显示-年,月,月中的某天,星期几。
这是在以下假设下完成的:
- 应用程序处理速度随时间而变化
- 处理速度受季节因素影响
- 星期几(尤其是周末申请)可以帮助识别配置单位和服务类别
训练模式
分类算法
对于所有三个分类任务,使用逻辑回归。 它支持多类分类(在“一对多”模型中),学习速度很快。
为了训练定义服务类别和处理应用程序持续时间的模型,我们将仅使用明显属于我们的配置单元的应用程序。
学习成果
定义配置单位
在将应用程序分配给配置单元时,该模型演示了高度的完整性和准确性指标。 另外,当应用程序引用外部配置单元时,该模型很好地定义了事件。
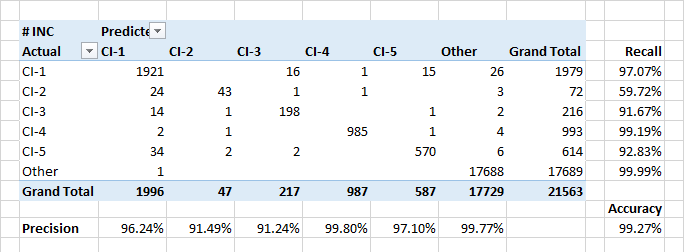
CI-2类的相对较低的完整性部分是由于数据中的实际分类错误。 此外,CI-2还提供了针对其他CI执行的“技术”应用程序。 因此,就描述和所涉及的用户而言,此类应用程序可能类似于其他类别的应用程序。
将应用程序分类为CI-?的最重要属性。 警报表中应包含应用程序客户和人员的名称。 但是有些关键字的重要性排在前30位。 应用程序的创建日期无关紧要。
应用类别定义
事实证明,按类别进行分类的质量要低一些。
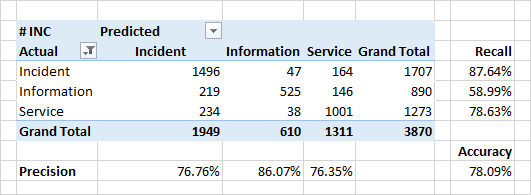
源数据中的预测类别和类别不匹配的一个非常严重的原因是源数据中的实际错误。 由于多种组织原因,分类可能不正确。 例如,可以将应用程序标记为“信息”(“这不是错误-这是功能”)或“服务”(“是的,它已损坏,但我们只是重新启动它”),而不是“事件”(系统缺陷,系统意外行为)。一切都会好的“)。
识别此类不一致是分类器的任务之一。
在类别的情况下,分类的重要属性是来自应用程序内容的单词。 对于事件,这些词是“错误”,“修复”,“何时”。 还有一些词表示系统的某些模块-这些模块使用户可以直接使用它们并观察直接或间接错误的出现。
有趣的是,对于定义为“服务”的应用程序,高位词还定义了系统的某些模块。 一个思考,检查并最终修复它们的机会。
确定申请的处理时间
最薄弱的是预测申请处理的持续时间。
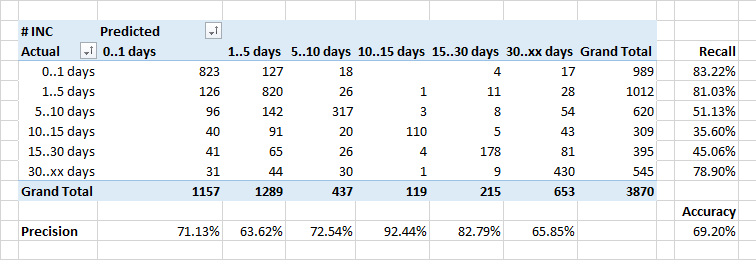
通常,在一定时间内关闭的应用程序数量的依存关系在理想情况下应该看起来像指数的倒数。 但是考虑到某些事件需要在系统中进行更正,并且这是作为常规版本的一部分完成的,因此,某些应用程序的执行时间会人为地增加。
因此,分类器也许将某些“长”应用程序分类为“更快”-他不知道计划发布的时间,并且认为需要更快地关闭应用程序。
这也是思考的好理由...
模型的实现
该模型以封装所有使用的所有标准scikit-learn类的类的形式实现-缩放,矢量化,分类器和有效设置。
基于辅助对象,模型的准备,训练和后续使用作为类方法实现。
通过对象实现,您可以方便地生成使用其他分类器类和/或预测原始数据集其他属性值的模型的派生版本。 所有这些都是通过覆盖虚拟方法来完成的。
但是,所有数据准备程序可能对所有选项仍然通用。
另外,以对象形式实现模型使得通过序列化/反序列化自然解决使用会话之间训练模型的中间存储问题。
为了序列化模型,使用了标准的Python机制pickle / unpickle。
由于它允许您将多个对象序列化到同一文件中,因此这将有助于一致地保存常规处理流程中包括的多个模型的恢复。
结论
所得的模型即使相对简单,也可以得出非常有趣的结果:
- 按类别在分类中确定系统的“遗漏”
- 很明显,系统的哪些部分与问题相关(显然-不是没有原因的)
- 申请处理时间显然取决于需要单独改善的外部因素。
我们尚未根据收到的“提示”重建内部流程。 但是即使是这个小实验,也可以评估机器学习方法的功能。 而且,还引起了团队在分析自己的过程及其改进方面的额外兴趣。