在我职业生涯的初期,我在一家发布内容管理系统的公司工作。 该CMS帮助营销部门自己管理站点,而不是依靠开发人员进行任何更改。 该系统帮助客户降低了运营成本,对我而言-学习如何创建Web应用程序。
尽管产品本身具有通用性,但客户通常将其用于特定任务。 这些任务使CMS的工作量减少了,开发人员不得不寻找解决问题的方法。 在这样的环境中工作了十年之后,我学到了如何破坏生产中的Web应用程序的大量方法。 其中一些将在本文中讨论。
这些年来的经验教训之一是,各个工程师通常将自己深深地浸入他们感兴趣的领域中,并对其进行肤浅的研究。 该方案在具有良好沟通能力的工程师团队中正常工作,其中知识重叠并且填补了每个人的个人空白。 但是在经验不足的团队中或对于单个工程师而言,会发生故障。
如果您开始在这样的环境中工作,然后开始从头开始创建和部署Web应用程序,那么您将快速学习什么是“危险的表面知识”。
行业中有许多解决方案可以解决此问题:托管Web应用程序(Beanstalk,AppEngine等),容器管理(Kubernetes,ECS等)以及许多其他解决方案。 他们开箱即用,可以很好地解决问题。 但这在启动Web应用程序时是不必要的复杂性,并且通常此类解决方案“有效”。
不幸的是,他们并不总是“正当工作”。 如果有任何细微差别,那么我想进一步了解这个险恶的黑匣子。
在本文中,我们采用了一个不可靠的系统,并将其修改为合理的可靠性水平。 在每个步骤中,都会使用一个实际的问题,解决该问题会将我们带入下一个阶段。 我认为,不分析最终设计的所有部分,而是仅使用这种分阶段的方法,效率更高。 他更好地演示了何时以及以什么顺序做出某些决定。 最后,我们将从头开始为托管Web应用程序构建托管服务的基本结构,我希望我们将详细解释每个部分存在的原因。
开始
假设您的托管预算为每年500美元,那么您决定在Amazon AWS上租用一台t2.medium服务器。 在撰写本文时,这大约是每年400美元。
预先知道您将拥有一个授权系统,并且您将需要存储有关用户的信息,因此需要一个数据库。 由于预算有限,我们会将其放置在唯一的服务器上。 最后,我们得到以下基础结构:
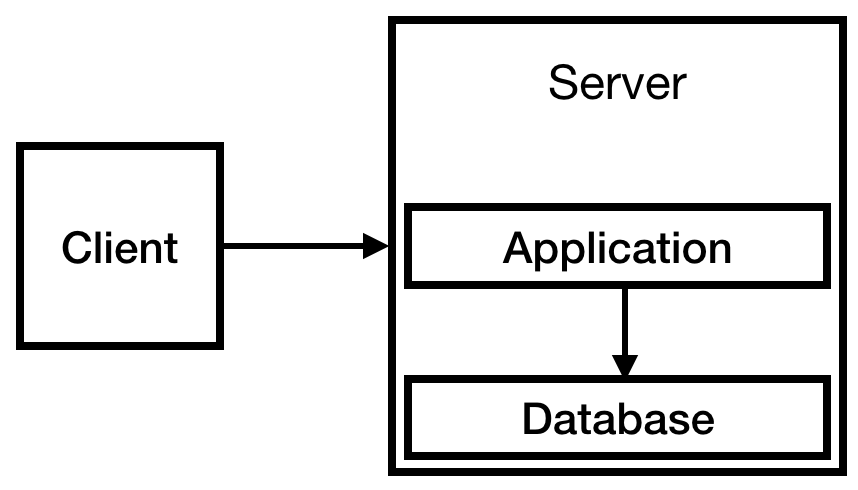 图 1个
图 1个现在就足够了。 实际上,这样的系统可以工作相当长的时间。 该服务很小,每天不到10次访问。 也许一个小的例子就足够了,但是我们对公司的发展感到乐观,因此我们谨慎地选择了t2.medium。
业务的价值在于数据库中,因此非常重要。 您需要确保如果服务器发生故障,则不会丢失数据。 您可能应该确保数据库的内容未存储在临时磁盘上。 毕竟,如果实例被删除,您将丢失数据。 这是一个非常可怕的想法。
您还应确保已备份到外部存储。 对于他们来说S3似乎是个好地方,而且相对便宜,所以让我们对其进行设置。 而且,您必须绝对检查备份是否正常运行,并定期还原备份。
现在系统看起来像这样:
 图 2
图 2您已经提高了数据库的可靠性,现在该通过在服务器上运行负载测试来准备“ habraeffect”了。 一切都很好,直到出现500个错误,然后出现404错误流,因此您正在调查发生了什么。
事实证明,您不知道会发生什么事情,因为您将日志写入了控制台并且没有将输出定向到文件。 您还会看到该过程不起作用,因此您很可能会认为这是404错误出现的原因,这可以缓解您的错误,因为您已经正确运行了本地负载测试,并且没有引起真正的Habra效应作为测试负载。
通过创建
systemd服务来解决自动重新启动的问题,启动Web服务器,这同时解决了日志记录问题。 然后运行另一个负载测试以进行验证。
再次,我们看到错误500(幸运的是,没有404)。 您检查日志。 检测到数据库连接池已满,因为已设置10个连接的较小限制。 更新限制,重新启动数据库,然后再次运行负载测试。 一切进展顺利,因此您决定在Habré上谈论您的网站。
启动日
上帝的母亲! 您的服务立即成为热门。 您已进入主页,并在前30分钟内获得了5000次观看-您会看到评论。 他们在那里写什么?
我遇到404错误,因此我不得不打开页面的缓存版本。 如果有人需要,这里是链接:...
...
什么都没有打开。 另外,我禁用了Javascript。 人们为什么认为我要加载他们的2 MB Javascript ...
...
下载主页需要4秒钟。 来自澳大利亚的Traceroute显示该服务器位于德克萨斯州的某个地方。 另外,为什么首页加载了2 MB的Javascript?
急于将Nginx配置为应用程序的反向代理服务器,并在其中配置静态404页面,还更改了部署过程以将静态文件发送到S3:这对于CloudFront CDN起作用是必需的,以减少在澳大利亚的加载时间。
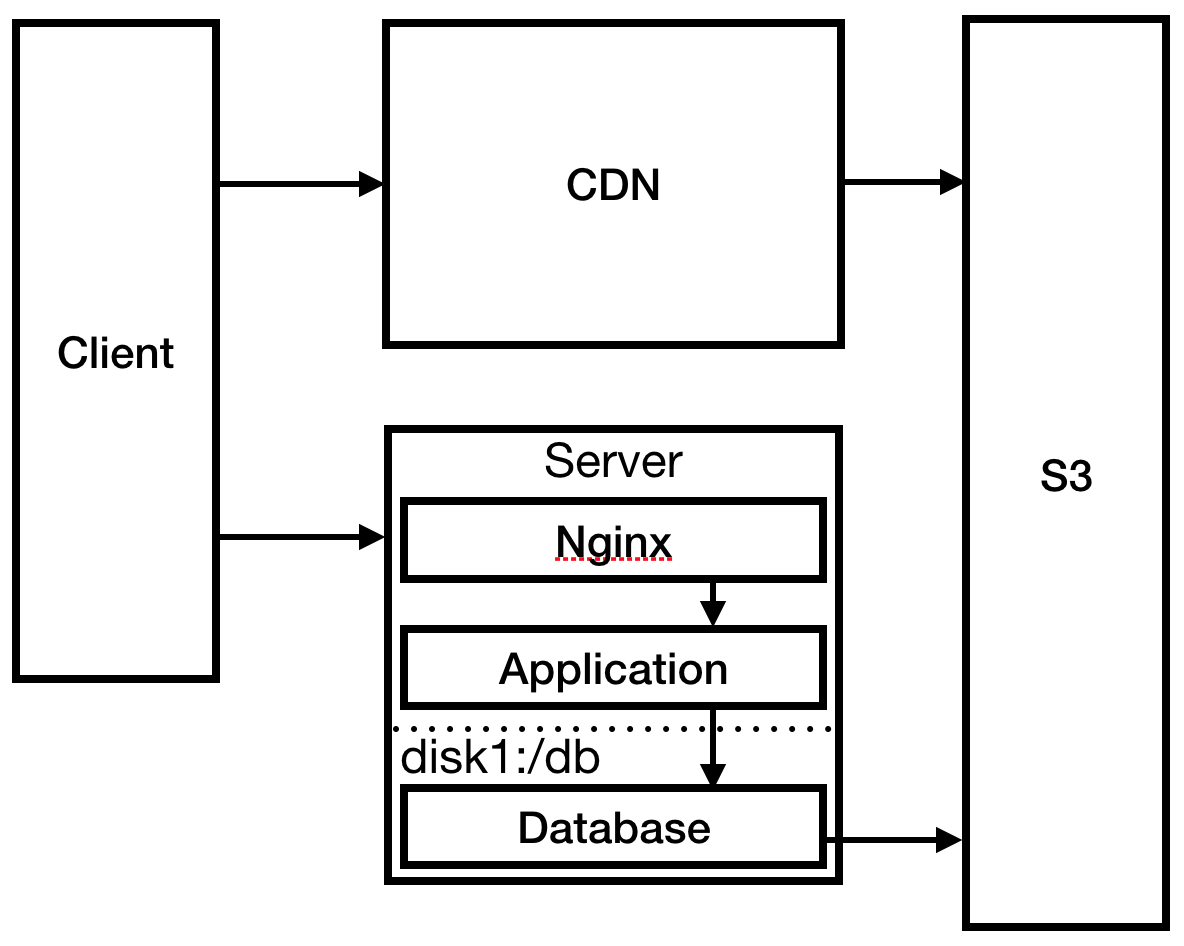 图 3
图 3您已经解决了最紧迫的问题,请转到服务器并检查日志。 您的SSH连接异常滞后。 经过研究,您发现日志文件已完全用完磁盘空间,从而导致进程崩溃并阻止其重新启动。 创建一个更大的磁盘,并将日志安装在该磁盘上。 配置
logrotate ,以使日志文件不再增长到这种大小。
性能问题
几个月过去了。 听众在增长。 该网站开始变慢。 您在CloudWatch监控中注意到,这种情况仅在UTC时间00:00到12:00之间发生。 由于开始和结束延迟时间相同,您会意识到这是由于服务器上的计划任务所致。 检查crontab并意识到一项工作计划在午夜进行:备份。 当然,备份需要十二个小时,并且会导致数据库过载,从而导致站点的速度显着下降。
您之前已阅读过有关此内容-并决定在从属数据库中运行备份。 然后记住:您没有下属数据库,因此需要创建它。 在同一服务器上运行从数据库没有多大意义,因此您决定扩展。 创建两个新服务器:一个用于主数据库,一个用于从属数据库。 更改备份以使用从属数据库。
 图 4
图 4团队成长
有一阵子,一切进展顺利。 几个月过去了。 您正在招聘开发人员。 其中一位新手介绍了一个导致生产服务器瘫痪的错误。 开发人员将责任归咎于与生产环境不同的开发环境。 他的话有些道理。 由于您是一个有良好品格的理性人,因此您将此事件视为一堂课。
现在该创建其他环境了:暂存,QA和生产。 幸运的是,从第一天开始,您就自动化了基础架构的创建,从而使一切顺利且简单。 从第一天起,您就已经建立了良好的连续交付实践,因此您可以轻松地从新分支机构组装输送机。
市场部正在推动2.0版。 您不太了解2.0的含义,但是您同意。 现在是时候为下一次流量激增做准备了。 您已经接近当前服务器的峰值,因此负载平衡的时机已到。 Amazon ELB使这变得容易。 在这段时间左右,您会注意到本文中的分层图应从上至下而不是从左至右显示各层。
 图 5
图 5有信心您将应付繁重的工作,因此再次提及您在Habré的网站。 哦,奇迹,它可以承受交通。 大获成功!
在您去检查日志之前,一切似乎都进展顺利。 测试12个服务器(每个环境中有四个服务器)花费了一个小时。 一个真正的麻烦。 幸运的是,有足够的钱购买ELK堆栈(ElasticSearch,LogStash,Kibana)。 您部署它并在所有环境中将服务器定向到那里。
 图 6
图 6现在,您可以再次转到日志,查看它们-并发现一些奇怪的东西。 它们充满了这样的条目:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
您没有使用PHP或WordPress,所以这很奇怪。 您会在数据库服务器的日志中注意到类似的可疑条目,并且想知道它们甚至如何连接到Internet。 现在是实现公共和私有子网的时候了。
 图 7
图 7再次检查日志。 黑客尝试仍然存在,但是现在它们被限制在负载均衡器上的端口80,这有点安慰,因为应用程序服务器,数据库服务器和ELK堆栈不再位于公共域中。
尽管日志是集中式的,但您仍然不愿意查找停机时间,而是手动检查日志。 通过Amazon CloudWatch,您可以在驱动器,CPU和网络利用率达到80%时设置电子邮件警报。 太好了!
操作平稳
开玩笑吧! 在软件中没有流畅的操作。 肯定会坏掉。 幸运的是,您现在拥有许多可以处理这种情况的工具。
我们创建了一个具有备份,回滚(在生产和中间阶段之间使用蓝色/绿色部署),集中式日志,监视和通知的可伸缩Web应用程序。 通常,进一步扩展取决于应用程序的特定需求。
市场上有许多托管选项可以执行大多数提到的任务。 您可以依靠Beanstalk,AppEngine,GKE,ECS等来代替自己开发,这些服务中的大多数会自动配置合理的权限,负载平衡子系统,子网等。这消除了在快速,快速地运行Web应用程序时的大部分麻烦。长期可靠的后端。
尽管如此,我发现了解这些平台各自提供的功能以及它们为什么提供此功能很有用。 这样可以轻松根据自己的需求选择平台。 通过在这样的平台上托管应用程序,您将已经知道这些模块的工作方式。 当出现问题时,了解解决问题的工具很有用。
结论
本文省略了许多细节。 它没有描述如何自动创建基础结构,如何准备和配置服务器。 它不包括创建开发环境,建立连续的交付管道以及部署和回滚。 我们没有解决网络安全性,密钥共享和最低特权原则。 他们没有谈论不变的基础架构,无状态服务器和迁移的重要性。 每个主题都需要单独的文章。
这篇文章的目的是概述生产中合理的Web应用程序的外观。 以后的文章可以在此处链接并扩展主题。
现在就这些了。
感谢您的阅读和良好的编码!
注意:请勿从本说明性文章中按实际顺序使用。 另外,所有这些事件实际上都发生在我身上,但是在不同的时间,完全不同的环境和不同的任务下发生了。