 神经网络评估说话者语音30秒片段的情感色彩。 作者先前的科学著作插图
神经网络评估说话者语音30秒片段的情感色彩。 作者先前的科学著作插图近年来,机器学习已越来越多地用作有用的诊断工具。 现有模型能够识别可能表示沮丧的单词和语调。 但是这些模型通常仅在患者回答医生的特定问题时才起作用:例如,有关他的心情,生活方式,病史等。也就是说,在这种情况下,神经网络的工作与与患者交谈的普通心理治疗师的工作没有什么不同。
但是对于新一代医学而言,一种能够在没有特定问题集的情况下确定
任意一组单词是否沮丧的系统要有效得多。 从理论上讲,在这种情况下,您可以实时实时监控整个人群的心理健康状况(所有语音流量),并迅速使患者住院。 自动抑郁检测模块可以在移动应用程序和游戏中实现。
该模型是由麻省理工学院的科学家开发的,
其出版物为《
麻省理工新闻》 。 该科学文章将在9月2日至6日在印度举行的
2018年Interspeech会议上发表。
“如果您想以可扩展的方式部署[检测抑郁症]模型...那么您需要减少对所使用数据的限制数量。 麻省理工学院计算机科学和人工智能实验室(CSAIL)的研究员Tuka Alhanai说,模型应该从人们之间的任何日常对话和自然互动中提取数据。
研究人员希望这种新方法将用于检测自然对话中的抑郁症迹象。 例如,基于该模型,可以开发移动应用程序,以跟踪用户的文本和语音中的精神障碍并发送警报。 这对于那些由于没有医生,咨询费用高或者仅仅因为他们不知道他有精神病而不能去医生进行初步诊断的人尤其有用。
抑郁症是一种非常危险的精神疾病,伴有自尊心的下降,对生活的兴趣和习惯性活动的减少。 在某些情况下,患有这种疾病的人可能会开始滥用酒精或其他物质。
新技术的关键创新在于它能够检测到指示抑郁的模式,然后将这些模式与新人进行比较,而无需其他信息,也就是说,无需事先对特定人进行培训。 Alkhanay解释说:“我们将其称为“无上下文”的工作,因为您不会对所寻找的问题类型和这些问题的答案类型施加任何限制。
为了训练神经网络,使用了一种称为“序列建模”的技术,该技术通常用于语音处理。 该模型从文本和声音数据序列中学习,这些文本和声音数据来自有或没有抑郁者的问题和答案。 逐渐地,她揭示出一般的模式,因为在健康和患病的人中某些单词与不同的声音相关。 另外,患有抑郁症的人可以说得慢一些,并且在单词之间使用更长的停顿时间。 在先前的研究中已经研究了这些用于精神障碍的文本和声音标识符。 最终,模型本身确定语音中是否有沮丧的迹象。
该模型在来自遇险分析采访语料库(声音,文本,视频)的142个语音片段的数据集上进行了测试。 诊断的准确性为71%(即,假阳性结果的29%),疾病检测的完整性为样本中所有患者的83%。 在大多数测试中,准确性超过了所有以前的诊断抑郁症模型的性能。 研究人员发现初步结果非常令人鼓舞。
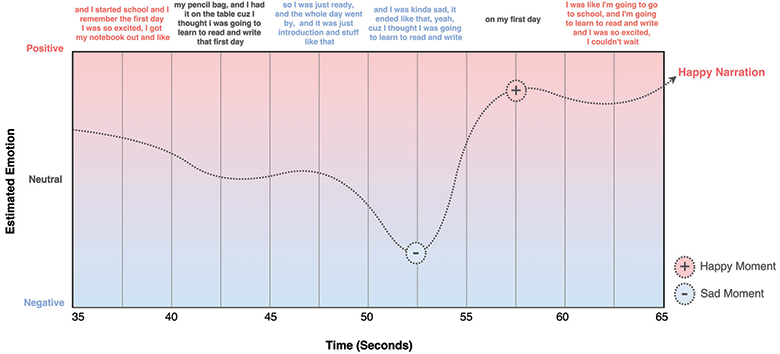
在2017年的
前一篇科学文章中 ,作者描述了一种神经网络,该神经网络通过以下标志识别说话者的情绪:
该图显示了五秒钟间隔内情感内容的分布。 负面片段是那些显示出悲伤,厌恶,愤怒,恐惧或无聊迹象的片段。 积极的细分受众群包含快乐,兴趣或热情的迹象。
除抑郁外,科学家还打算训练神经网络来识别其他精神状态,例如痴呆。