Nikolai Ryzhikov提出了他的答案版本,以回答为什么开发用户界面如此困难的问题。 在他的项目示例中,他将证明后端某些思想在前端的应用会影响开发复杂度的降低和前端的可测试性。
该材料是根据Nikolai
Ryzhikov在2018年春季
HolyJS Piter会议上的报告编写的。
目前,Nikolai Ryzhikov正在Health-IT部门工作,以创建医疗信息系统。 圣彼得堡功能程序员FPROG社区的成员。 在线Clojure社区的活跃成员,HL7 FHIR医学信息交换标准的成员。 已经编程了15年。
-我总是被这个问题折磨:为什么图形UI总是很难做到? 为什么这总是引起很多问题?
今天,我将尝试推测是否有可能有效开发用户界面。 我们可以降低其开发的复杂性吗?
什么是效率?
让我们定义什么是效率。 从开发用户界面的角度来看,效率意味着:
有一个很好的定义:
效率事半功倍
确定之后,您可以放任何东西-花费更少的时间,更少的精力。 例如,“如果编写更少的代码,则允许更少的错误”并实现相同的目标。 总的来说,我们花了很多功夫。 效率是一个很高的目标-摆脱这些损失,只做需要做的事情。
什么是复杂性?
我认为,复杂性是开发中的主要问题。
弗雷德·布鲁克斯(Fred Brooks)早在1986年就写了一篇文章,《无银弹》。 在其中,他回顾了软件。 在硬件方面,进步是突飞猛进的,而对于软件而言,一切都更加糟糕。 弗雷德·布鲁克斯(Fred Brooks)的主要问题-会有这样的技术立即使我们加速一个数量级吗? 他本人给出了一个悲观的回答,指出用软件无法实现这一点,并解释了他的立场。 我强烈建议您阅读本文。
我的一个朋友说UI编程是一个“肮脏的问题”。 您不能坐下来一次,想出正确的选择,以便永远解决问题。 此外,在过去的十年中,开发的复杂性仅在增加。
12年前...
我们12年前就开始开发医疗信息系统。 首先用闪光灯。 然后,我们研究了Gmail开始做什么。 我们喜欢它,并且希望切换到HTML的JavaScript。
实际上,那时我们远远领先于时间。 我们参加了道场比赛,实际上我们拥有与现在相同的一切。 有些组件非常擅长使用dojo小部件,有一个模块化的构建系统,并且需要构建和缩小Google Clojure编译器(那时,RequireJS和CommonJS甚至都没有气味)。
一切顺利。 我们看着Gmail受到启发,认为一切都很好。 一开始,我们只写了一个病人读卡器。 然后他们逐渐切换到医院其他工作流程的自动化。 一切变得复杂。 团队似乎是专业人士-但是每个功能都开始发出吱吱声。 这种感觉出现在12年前-至今并没有离开我。
Rails方式+ jQuery
我们进行了系统认证,因此有必要编写一个患者门户。 这种系统使患者可以去看他们的医疗数据。
然后,我们的后端是用Ruby on Rails编写的。 尽管Ruby on Rails社区不是很大,但它对行业产生了巨大影响。 来自您充满热情的小型社区,您所有的软件包管理器,GitHub,Git,自动化妆等都已来临。
我们面临的挑战的实质是我们必须在两周内实施患者门户。 我们决定尝试使用Rails方式-在服务器上完成所有操作。 如此经典的Web 2.0。 他们做到了-他们确实在两周内做到了。
我们领先于整个星球:我们进行过SPA,我们拥有REST API,但是由于某种原因,它没有效果。 有些功能本来可以成为单位,因为只有它们才能容纳所有这些复杂的组件,即后端与前端的关系。 当我们采用Rails方式时-有点不合我们的标准,这些功能突然开始铆钉。 一般的开发人员在几天内就开始推出该功能。 我们甚至开始编写简单的测试。
在此基础上,我实际上仍然受到了伤害:有人提出了问题。 当我们在后端从Java切换到Rails时,开发效率提高了大约10倍。 但是,当我们在SPA上得分时,开发效率也大大提高了。 怎么会这样
为什么Web 2.0有效?
让我们从另一个问题开始:为什么我们制作一个单页应用程序,为什么我们相信它?
他们只是告诉我们:我们需要这样做-而我们要做。 而且很少有人质疑它。 REST API和SPA架构是否正确? 它真的适合我们使用的情况吗? 我们不认为。
另一方面,有很多相反的例子。 每个人都使用GitHub。 您知道GitHub不是单页应用程序吗? GitHub是在服务器上呈现且窗口小部件很少的常规“ rail”应用程序。 有没有人从中得到过面粉? 我想有三个人。 其余的甚至没有注意到。 这丝毫不影响用户,但同时由于某种原因,我们必须为开发其他应用程序(强度,复杂性等)支付10倍的费用。 另一个例子是大本营。 Twitter曾经只是一个Rails应用程序。
实际上,有许多Rails应用程序。 这部分由天才DHH(Ruby on Rails的创建者David Heinemeier Hansson)确定。 他能够创建一个专注于业务的工具,使您可以立即进行所需的工作,而不会因技术问题而分心。
当然,当我们使用Rails方式时,会有很多黑魔法。 随着我们的逐步发展,我们从Ruby切换到Clojure,实际上保持了相同的效率,但是使所有操作都简化了一个数量级。 这真是太好了。
12年过去了
随着时间的流逝,新趋势开始出现在前端。
我们完全忽略了Backbone,因为我们之前编写的dojo应用程序比Backbone提供的功能更加复杂。
然后出现了Angular。 这是一个相当有趣的“光线”-从效率的角度来看,Angular非常好。 您选择普通的开发人员,他会铆钉该功能。 但是从简单性的角度来看,Angular带来了很多问题-它不透明,复杂,存在监视,优化等问题。
React出现了,带来了一些简单性(至少渲染的简单性,由于Virtual DOM的存在,使我们每次都好像只是简单地重画,理解和编写)。 但是说实话,就效率而言,React大大地将我们推倒了。
最糟糕的是,十二年来没有任何变化。 我们现在仍在做同样的事情。 现在该考虑了-这里有些问题。
弗雷德·布鲁克斯说,软件开发存在两个问题。 当然,他看到了复杂性中的主要问题,但是他将其分为两组:
- 任务本身带来了极大的复杂性。 它根本不能扔掉,因为它是任务的一部分。
- 随机复杂度是我们试图解决此问题的方法之一。
问题是,它们之间的平衡是什么? 这正是我们现在正在讨论的。
为什么做用户界面这么痛苦?
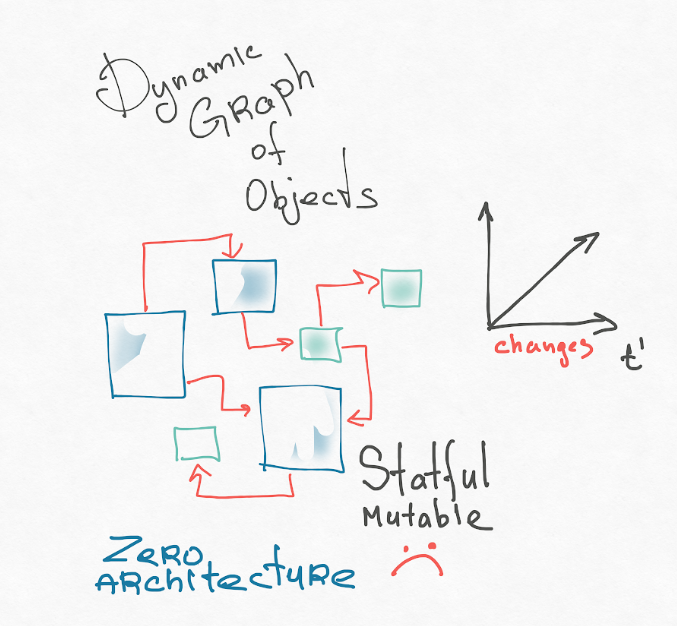
在我看来,第一个原因是我们的心理应用模型。 React组件是纯粹的OOP方法。 我们的系统是互连的可变对象的动态图。 图灵完备类型不断生成此图的节点,某些节点消失。 您是否曾经尝试过想象一下您的应用程序? 太恐怖了! 我通常会提出这样的OOP应用程序:

我建议阅读Roy Fielding(REST体系结构的作者)的论文。 他的论文题目为“建筑风格和基于网络的软件设计”。 在开始时,有一个很好的介绍,他在其中讨论了如何全面了解体系结构并介绍了概念:将系统分解为组件以及这些组件之间的关系。 它具有“零”架构,其中所有组件都可能与所有组件相关联。 这是建筑混乱。 这是我们用户界面的对象表示。
Roy Fielding建议寻找并施加一组约束,因为它是定义您的体系结构的一组约束。
可能最重要的是,限制是架构师的朋友。 寻找这些真正的限制,并从中设计一个系统。 因为自由是邪恶的。 自由意味着您可以选择一百万种选择,而不能通过一个单一的标准来确定选择是否正确。 寻找约束并在其上建立。
有一篇很棒的文章叫做OUT OF TAR PIT(“比沥青孔更容易”),其中Brooks之后的家伙决定分析到底是什么导致了应用程序的复杂性。 他们得出了令人失望的结论,即可变的,状态扩散的系统是复杂性的主要来源。 这里可以纯粹组合地进行解释-如果您有两个单元格,并且每个单元格都可以说谎(或不说谎),那么有多少种状态是可能的? -四
如果3个单元-2
3 ,如果100个单元-2
100 。 如果您展示您的应用程序并了解模糊了多少状态,您将意识到系统中存在无限数量的可能状态。 如果同时没有任何限制,那就太困难了。 而且人的大脑很虚弱,这已经被各种研究证明。 我们能够同时容纳三个要素。 有人说七点,但是即使如此,大脑还是会使用骇客。 因此,复杂性对于我们来说确实是一个问题。
我建议阅读这篇文章,得出结论:需要对这种可变状态进行某些处理。 例如,有关系数据库,您可以在那里删除整个可变状态。 其余的则以纯功能样式完成。 他们只是想到了这种功能关系编程的思想。
因此,问题来自于以下事实:
- 首先,我们没有一个好的固定用户界面模型。 组件方法将我们引向了现有的地狱。 我们没有施加任何限制,我们传播了可变状态,结果,系统的复杂性在某些时候使我们感到沮丧。
- 其次,如果我们正在编写经典的后端-前端应用程序,那么它已经是分布式系统。 分布式系统的首要原则是不要创建分布式系统(分布式对象设计的第一定律:不要分发您的对象-Martin Fowler),因为您会立即将复杂性提高一个数量级。 编写任何集成的任何人都知道,一旦您进入系统间的交互,所有项目估算都可以乘以10。但是我们只是忘了它,而是转而使用分布式系统。 当我们切换到Rails,将所有控制权返回给服务器时,这可能是主要的考虑因素。
所有这些对于人类的大脑来说都是太苛刻了。 让我们考虑一下如何解决这两个问题-体系结构中缺乏限制(可变对象的图形)以及向如此复杂的分布式系统的过渡,以至于学者们仍在困惑如何正确地进行操作(与此同时,我们注定要在最简单的业务应用程序中遭受这些折磨)?
后端如何演变?
如果我们使用与现在创建UI相同的样式来编写后端,则将出现相同的“血腥混乱”。 我们将花很多时间在上面。 所以真的曾经尝试做。 然后,他们逐渐开始施加限制。
第一个伟大的后端发明是数据库。
首先,在程序中,整个状态莫名其妙地挂在哪里,并且很难对其进行管理。 随着时间的推移,开发人员想出了一个数据库,并删除了那里的整个状态。
数据库之间的第一个有趣的区别是,数据中没有一些具有自己行为的对象,这是纯信息。 有表或其他一些数据结构(例如JSON)。 他们没有行为,这也非常重要。 因为行为是对信息的一种解释,所以可以有许多种解释。 基本事实-它们仍然是基本的。
另一个重要的一点是,在该数据库上,我们拥有一种查询语言,例如SQL。 从限制的角度来看,在大多数情况下,SQL不是图灵完备的语言,它更简单。 另一方面,它是声明性的-更具表达性,因为在SQL中您说的是“什么”,而不是“如何”。 例如,当您在SQL中组合两个标签时,SQL决定如何有效地执行此操作。 您在寻找东西时,他会为您选择一个索引。 您永远不会明确声明这一点。 如果尝试在JavaScript中进行组合,则必须为此编写一堆代码。
在这里,再次施加限制很重要,现在我们通过一种更简单,更富表现力的语言来了解这个基础。 重新分配的复杂性。
后端进入基础后,应用程序变为无状态。 这会产生有趣的效果-例如,现在,我们可能不怕更新应用程序(状态不会在内存中的应用程序层中挂起,如果应用程序重新启动,该状态将消失)。 对于应用程序层,无状态是一个很好的功能,也是一个很好的约束。 如果可以的话,戴上它。 而且,因为事实及其解释与事物无关,所以可以将新的应用程序拉到旧的基础上。
从这个角度来看,对象和类很糟糕,因为它们会粘合行为和信息。 信息更丰富;它的寿命更长。 数据库和事实可以保存在用Delphi,Perl或JavaScript编写的代码中。
当后端采用这种架构时,一切都变得更加简单。 Web 2.0的黄金时代已经到来。 可以从数据库中获取某些信息,对数据进行模板处理(纯函数),然后返回HTML-ku,该HTML-ku被发送到浏览器。
我们学习了如何在后端编写相当复杂的应用程序。 大多数应用程序都是以这种风格编写的。 但是,一旦后端迈出了一步,进入不确定性,问题又开始了。
人们开始考虑它,并提出了排除PLO和仪式的想法。
我们的系统实际上是做什么的? 他们从某个地方(从用户,另一个系统等)获取信息,然后将其放入数据库中,对其进行转换,以某种方式对其进行检查。 他们从基础上通过狡猾的查询(分析或综合查询)将其取出并返回。 仅此而已。 这一点很重要。 从这个角度来看,模拟是一个非常错误和糟糕的概念。
在我看来,通常整个OOP实际上是从UI诞生的。 人们试图模拟和模拟用户界面。 他们在监视器上看到一个特定的图形对象并思考:在我们的运行时刺激它以及它的属性等会很好。 整个故事与OOP紧密相关。 但是模拟是解决任务的最直接,最幼稚的方法。 当您离开时,有趣的事情就完成了。 从这个角度来看,将信息与行为分开,摆脱这些奇怪的对象更为重要,一切将变得更加容易:您的Web服务器接收一个HTTP字符串,返回一个HTTP响应字符串。 如果在方程式中添加一个底数,则将得到一个通常为纯的函数:服务器接受该底数和请求,返回新的底数和响应(输入的数据-剩余的数据)。
在这种简化过程中,工作人员将积聚在后端的行李又扔掉了1/3。 不需要他,这只是一种仪式。 我们仍然不是游戏开发者-我们不需要患者和医生以某种方式生活在运行时,移动和跟踪他们的坐标。 我们的信息模型是另外一回事。 我们不假装药品,销售或其他任何东西。 我们在交界处创造了一些新事物。 例如,Uber不模拟操作员和机器的行为-它引入了新的信息模型。 在我们的领域中,我们还在创造新的东西,因此您可以感受到自由。
不必尝试完全模拟-创建。
Clojure = JS--
现在该告诉您确切如何丢弃所有内容的时间了。 这里我想提一下Clojure脚本。 实际上,如果您了解JavaScript,就会知道Clojure。 在Clojure中,我们不会向JavaScript添加功能,而是将其删除。
- 我们放弃了语法-在Clojure(在Lisp中)没有语法。 用普通的语言,我们编写一些代码,然后对其进行解析并获得AST,然后对其进行编译和执行。 在Lisp中,我们立即编写了可以执行-解释或编译的AST。
- 我们抛弃了可变性。 Clojure中没有可变对象或数组。 每个操作都会生成新副本。 而且,此副本非常便宜。 巧妙地做到了便宜。 这使我们能够像在数学中一样使用价值。 我们什么都没有改变-我们正在创造新的东西。 安全,简单。
- 我们抛出类,带有原型的游戏等。 这只是不存在。
结果,我们仍然拥有我们可以操作的功能和数据结构以及原语。 这是整个Clojure。 而且,在它上面您可以执行与其他语言相同的操作,在这些语言中,有很多其他工具都不知道如何使用。
例子
我们如何通过AST到达Lisp? 这是一个经典的表达:
(1 + 2) - 3
例如,如果我们尝试以数组的形式编写其AST,其中head是节点的类型,接下来是参数,我们将得到类似的信息(我们正在尝试使用Java Script编写):
['minus', ['plus', 1, 2], 3]
现在删除多余的引号,我们可以将负号替换为
- ,将正号替换为
+ 。 扔掉Lisp中空格的逗号。 我们将获得相同的AST:
(- (+ 1 2) 3)
在Lisp中,我们所有人都是这样写的。 我们可以检查-这是一个纯数学函数(我的emacs已连接到浏览器;我将脚本放在那里,它在那里评估命令并将其发送回emacs-您会在
=>符号后面看到值):
(- (+ 1 2) 3) => 0
我们还可以声明一个函数:
(defn xplus [ab] (+ ab)) ((fn [xy] (* xy)) 1 2) => 2
或匿名函数。 也许这看起来有点吓人:
(type xplus)
她的类型是JavaScript函数:
(type xplus) => #object[Function]
我们可以通过传递参数来调用它:
(xplus 1 2)
也就是说,我们要做的就是编写AST,然后将其编译为JS或字节码,或者进行解释。
(defn mymin [ab] (if (a > b) ba))
Clojure是一种托管语言。 因此,它从父运行时获取原语,也就是说,对于Clojure Script,我们将具有JavaScript类型:
(type 1) => #object[Number]
(type "string") => #object[String]
因此,正则表达式被编写为:
(type #"^Cl.*$") => #object[RegExp]
我们拥有的功能是功能:
(type (fn [x] x)) => #object[Function]
接下来,我们需要某种复合类型。
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} (type user)
可以理解为就像在JavaScript中创建对象一样:
(def user {name: "niquola" …
在Clojure中,这称为哈希图。 这是值所在的容器。 如果使用方括号-则称为向量-这是您的数组:
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} => #'intro/user (type user)
我们使用哈希图和向量记录任何信息。
奇怪的冒号名称(
:name )是所谓的字符:创建的常量字符串,用作哈希图中的键。 在不同的语言中,它们的名称有所不同-符号或其他名称。 但这可以简单地视为常量字符串。 它们非常有效-您可以写长名称,而不必花很多资源,因为它们是相连的(即,它们不再重复)。
Clojure提供了数百种函数来处理这些通用数据结构和原语。 我们可以添加,添加新密钥。 而且,我们始终具有复制语义,即每次获得新副本时。 首先,您需要习惯它,因为您将不再能够像以前一样在变量的某个位置保存内容,然后更改此值。 您的计算应始终简单明了-所有参数都必须显式传递给函数。
这导致一件重要的事情。 在函数式语言中,函数是理想的组件,因为它在输入处显式接收所有内容。 系统中没有隐藏的链接。 您可以从一个地方获取功能,然后将其转移到另一个地方,然后在那儿使用它。
在Clojure中,即使对于复杂的复合类型,我们在价值方面也具有出色的相等性运算:
(= {:a 1} {:a 1}) => true
而且,由于可以简单地通过引用比较狡猾的不可变结构,因此此操作很便宜。 因此,即使是具有数百万个键的哈希图,我们也可以在一个操作中进行比较。
顺便说一下,React的家伙只是复制了Clojure实现并制作了不可变的JS。
Clojure也有很多操作,例如,从hashmap中的嵌套路径获取一些信息:
(get-in user [:address :city])
在hashmap的嵌套路径中放置一些内容:
(assoc-in user [:address :city] "LA") => {:name "niquola", :address {:city "LA"}, :profiles [{:type "github", :link "https://….."} {:type "twitter", :link "https://….."}], :age 37}
更新一些值:
(update-in user [:profiles 0 :link] (fn [old] (str old "+++++")))
只选择一个特定的键:
(select-keys user [:name :address])
与向量相同的东西:
(def clojurists [{:name "Rich"} {:name "Micael"}]) (first clojurists) (second clojurists) => {:name "Michael"}
基本库中有数百种操作可让您对这些数据结构进行操作。 与主机互操作。 您需要习惯一下:
(js/alert "Hello!") => nil </csource> "". location window: <source lang="clojure"> (.-location js/window)
沿着链条走到尽头:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
我可以获取JS日期并从中返回年份:
(let [d (js/Date.)] (.getFullYear d)) => 2018
Clojure的创建者Rich Hickey严重限制了我们。 我们真的什么都没有,所以我们通过通用数据结构来完成所有工作。 例如,当我们编写SQL时,通常使用数据结构来编写它。 如果仔细看,您会发现这只是一个嵌入了某些东西的哈希图。 然后有一些函数将所有这些转换为SQL字符串:
{select [:*] :from [:users] :where [:= :id "user-1"]} => {:select [:*], :from [:users], :where [:= :id "user-1"]}
我们还使用数据结构和排版数据结构编写路由:
{"users" {:get {:handler :users-list}} :get {:handler :welcome-page}}
[:div.row [:div {:on-click #(.log js/console "Hello")} "User "]]
用户界面中的数据库
因此,我们讨论了Clojure。 但是我之前提到过,数据库是后端的一大成就。 如果您现在查看前端中发生的情况,我们将看到这些家伙使用相同的模式-他们在用户界面(在单页应用程序中)中输入数据库。
数据库以elm架构,Clojure脚本化的重新框架,甚至在flux和redux中以某种受限形式引入(必须在此处设置其他插件以引发请求)。 榆木结构,重新框架和助焊剂大约在同一时间推出,并且相互借鉴。 我们写在重新框架上。 接下来,我将告诉您一些工作原理。

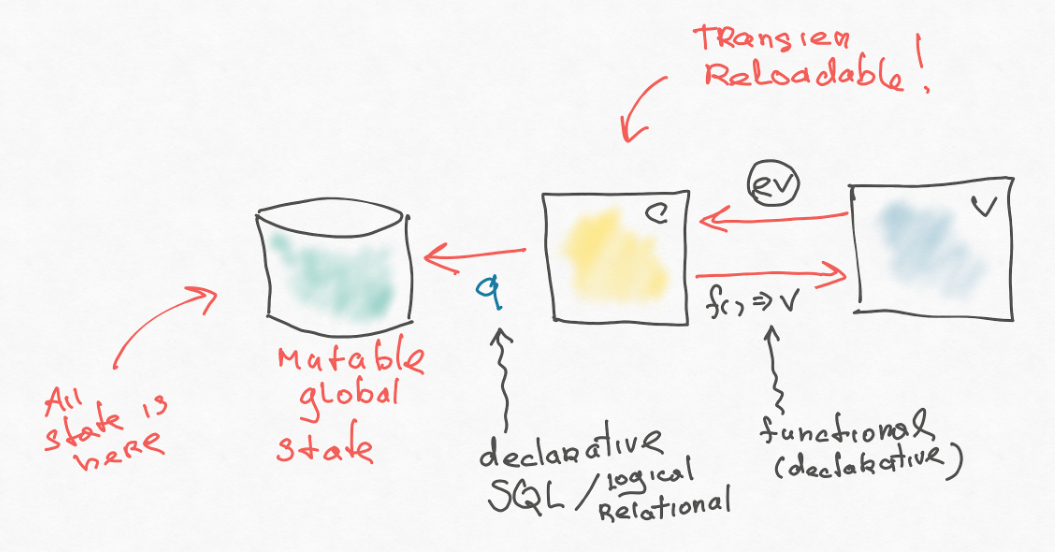
事件(有点像redux)从视图中飞出,它被某个控制器捕获。 控制器我们称为事件处理程序。 事件处理程序发出一个效果,该效果也是由数据结构解释的。
一种效果是更新数据库。 也就是说,它采用当前数据库值并返回一个新值。 我们也有订阅之类的东西-后端请求的类似物。 也就是说,这些是一些响应式查询,我们可以将其扔到该数据库中。 这些反应性的要求,我们随后就此提出意见。 在反应的情况下,我们似乎完全重绘,并且如果此请求的结果已更改-这很方便。
React只在最后出现在我们的某个地方,并且总体上来说,架构与它没有任何联系。 看起来像这样:

此处添加了缺少的内容,例如在redux-s中。
首先,我们将效果分开。 前端应用程序不是独立的。 他有一定的后端-一种“真实的来源”。 应用程序必须不断在其中写入内容,并从那里读取某些内容。 更糟糕的是,如果他有几个后端,那就去吧。 在最简单的实现中,可以直接在操作创建器中-在您的控制器中完成此操作,但这很不好。 因此,重新构造的人引入了另一种间接访问级别:某个数据结构飞出了控制器,这表明需要做什么。 这个帖子有自己的处理程序,可以完成肮脏的工作。 这是一个非常重要的介绍,我们将在后面讨论。
这也很重要(有时他们会忘记它)-一些基础事实应该成为基础。 其他所有内容都可以从数据库中删除-查询通常会执行此操作,它们会转换数据-它们不会添加新信息,但会正确构造现有信息。 我们需要这个查询。 我认为,在redux中,它现在提供了重新选择,而在重新构架中,我们将其开箱即用(内置)。
看一下我们的架构图。 我们复制了一个带有基础,控制器,视图的小型后端(Web 2.0风格)。 唯一添加的是反应性。 这与MVC非常相似,除了所有内容都集中在一个地方。 一旦每个小部件的早期MVC创建了自己的模型,但是这里的所有内容都被合并为一个基础。 原则上,您可以通过效果与控制器中的后端进行同步,可以提出更通用的外观,从而使数据库像后端的代理一样工作。 甚至还有某种通用算法:您写入本地数据库,并且该数据库与主数据库同步。
现在,在大多数情况下,基础只是某种对象,我们可以在其中使用redux编写一些内容。 但是原则上,人们可以想象它会进一步发展成为具有丰富查询语言的功能完善的数据库。 也许与某种通用同步。 例如,有一个datomic-直接在浏览器中运行的三重存储逻辑数据库。 您将其拾起并将整个状态放在那里。 Datomic具有相当丰富的查询语言,其功能可与SQL媲美,甚至可以胜出。 另一个例子是Google写的lovefield。 一切都会在那儿移动。
接下来,我将解释为什么我们需要响应式订阅。
现在,我们获得了第一个幼稚的感知-我们从后端获得了用户,将其放入数据库中,然后需要绘制它。 在渲染时,会发生很多特定的逻辑,但是我们将其与渲染和视图混合在一起。 如果我们立即开始渲染此用户,我们将获得一个棘手的大功能,它可以对虚拟DOM进行其他操作。 并且它与我们视图的逻辑模型混合在一起。
需要理解的一个非常重要的概念:由于UI的复杂性,还需要对其进行建模。 有必要将其绘制方式(从外观上看)与其逻辑模型分开。 这样逻辑模型将更加稳定。 您不能依赖于特定的框架-Angular,React或VueJS来负担它。 模型是运行时中通常的一等公民。 理想情况下,如果只是一些数据和上面的一组功能。

也就是说,从后端模型(对象),我们可以得到一个视图模型,其中可以在不使用任何渲染的情况下重新创建逻辑模型。 如果有某种菜单或类似菜单-所有这些都可以在视图模型中完成。
怎么了
为什么我们都这样做?
我仅在只有10名测试人员的情况下才能看到良好的UI测试。
通常没有UI测试。 因此,我们试图将这种逻辑从视图模型的组件中推出。 缺乏测试是一个非常糟糕的信号,表明那里出了点问题,某种程度上一切结构都很差。
为什么UI很难测试? 为什么后端人员学习了如何测试他们的代码,提供了广泛的覆盖范围,并且确实有助于使用后端代码? 用户界面为什么出错? 很可能我们在做错事。 我上面描述的所有内容实际上都使我们朝着可测试性的方向发展。
我们如何进行测试?
如果仔细观察,我们架构的一部分,包括控制器,订阅和数据库,甚至与JS都不相关。 也就是说,这是一种仅在数据结构上运行的模型:我们将它们添加到某个位置,以某种方式进行转换,取出查询。 通过效果,我们脱离了与外界的互动。 而且这是完全便携式的。 它可以用所谓的cljc编写-这是Clojure脚本和Clojure之间的一个常见子集,它们在各处的行为方式相同。 我们可以从前端切下这部分并将其放入后端所在的JVM中。 然后,我们可以在JVM中编写另一个效果,该效果直接到达终点-它无需任何http字符串转换,解析等即可拉动路由器。
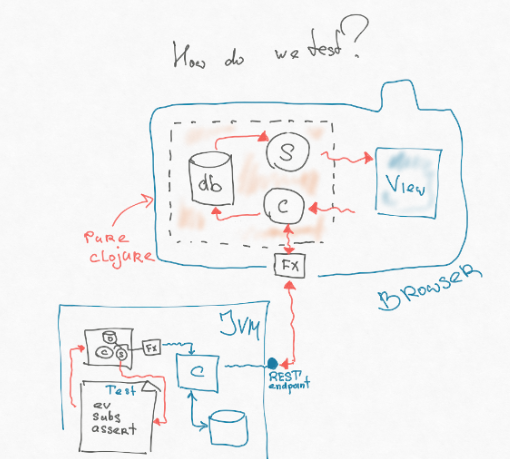
结果,我们可以编写一个非常简单的测试-与后端编写的功能相同的测试。 我们抛出一个特定事件,它会引发一个直接击中后端端点的效果。 他向我们返回了一些东西,将其放入数据库中,计算订阅,然后在订阅中包含一个逻辑视图(我们将用户界面逻辑放在最大程度)。 我们主张这种观点。
因此,我们可以在后端上测试80%的代码,而所有后端开发工具都可以使用。 使用固定装置或某些工厂,我们可以在数据库中重新创建特定情况。
例如,我们有一个新病人或未付款,等等。 我们可以经历很多可能的组合。
因此,我们可以处理第二个问题-分布式系统。 因为系统之间的契约恰好是主要的痛处,因为这是两个不同的运行时,两个不同的系统:后端更改了某些内容,并且前端发生了更改(您无法确定不会发生这种情况)。
示范
这就是实际的样子。 这是一个后端助手,他清理了基础并在其中写了一个小世界:
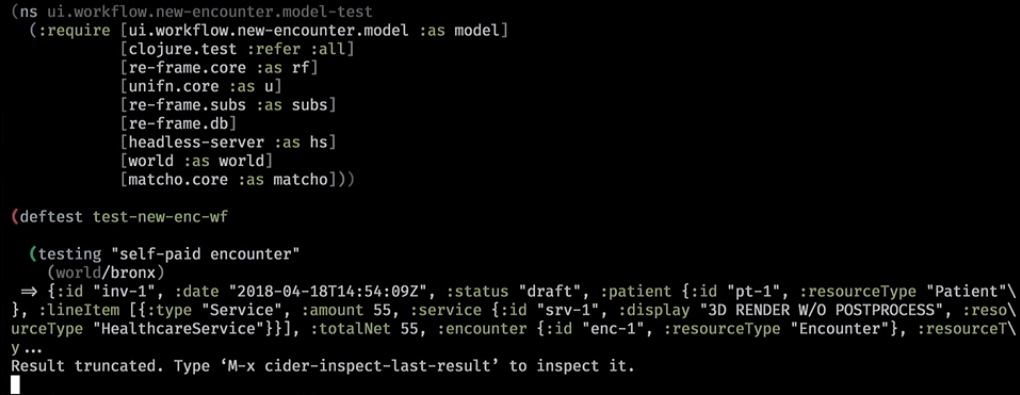
接下来,我们抛出订阅:

通常,URL完全定义了页面,并引发了一些事件-您现在位于具有一组参数的某某页面上。 在这里,我们进入了一个新的工作流程,并返回了订阅:

在幕后,他去了基地,拿了些东西,放在我们的UI基地。 对其进行订阅,并从中得出逻辑视图模型。
我们初始化了它。 这是我们的逻辑模型:

即使不查看用户界面,我们也可以猜测将根据此模型绘制的内容:将会出现一些警告,一些有关患者,相遇的信息,以及一组链接(这是导致前台的工作流小部件)在患者到达时按特定步骤进行)。
在这里,我们提出了一个更加复杂的世界。 他们进行了一些付款,并在初始化后进行了测试:
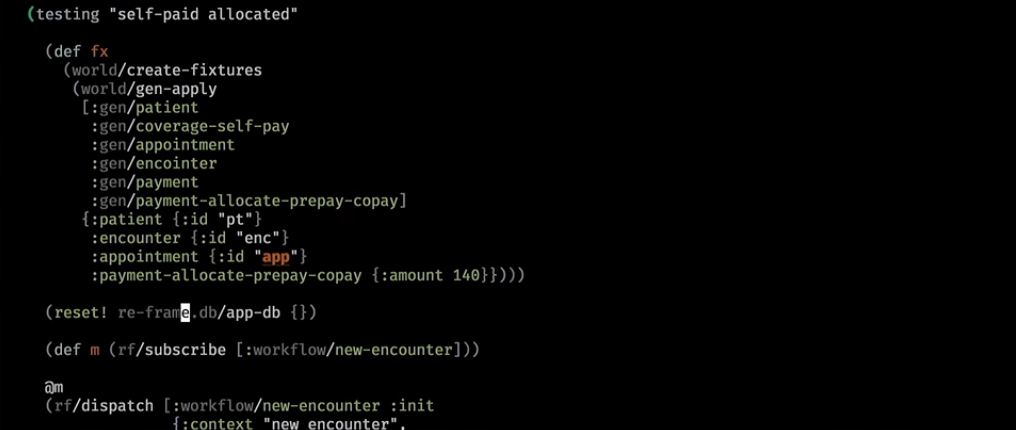
如果他已经为这次访问付费,他将在用户界面上看到以下内容:

运行测试,设置为CI。 后端和前端之间的同步将通过测试来保证,而不是诚实的。
回到后端?
我们六个月前推出了测试,我们真的很喜欢它。 逻辑模糊的问题仍然存在。 业务应用程序的行为越聪明,某些步骤所需的信息就越多。 如果您尝试从现实世界中运行某种类型的工作流,则所有内容都将具有依赖性:对于每个用户界面,您都需要从后端数据库的不同部分获取某些信息。 如果我们编写会计系统,这是不可避免的。 结果,正如我所说,所有逻辑都被抹黑了。
借助这样的测试,我们至少可以在开发时(在开发时)产生一种错觉,就像在Web 2.0的早期一样,我们在一个运行时中坐在服务器上,并且一切都舒适。
另一个疯狂的主意出现了(尚未实施)。 为什么不把这部分降低到后端呢? 为什么现在不完全摆脱分布式应用程序呢? 让此订阅和我们的视图模型在后端生成? 那里的基地可用,一切都是同步的。 一切都简单明了。
我在此看到的第一个优点是,我们将在一个地方拥有控制权。 与分布式应用程序相比,我们只是立即简化了一切。 测试变得简单,重复验证消失了。 交互式多用户系统的流行世界打开了(如果两个用户使用相同的表单,我们会告诉他们;他们可以同时编辑它)。
出现了一个有趣的功能:通过转到会话的后端和前景,我们可以了解系统中当前的人以及他在做什么。 这有点像游戏开发人员,其中的服务器按此方式工作。 那里生活在服务器上,而前端仅渲染。 结果,我们可以获得一定的瘦客户端。
另一方面,这带来了挑战。 我们将必须有一个用于这些会话的全状态服务器。 如果我们有多个应用程序服务器,则必须以某种方式适当地平衡负载或复制会话。 但是,有人怀疑这个问题少于我们得到的加分数量。
因此,我回到主要口号:可以编写许多不分布式的应用程序,以消除它们的复杂性。 如果您再次修改我们在开发中所依赖的基本假设,则可以提高效率。
如果您喜欢此报告,请注意:11月24日至25日,新的HolyJS将在莫斯科举行,那里还将有许多有趣的事情。 有关该程序的已知信息位于该站点上 ,可以在该站点上购买票。