本文的作者是卡巴斯基实验室反病毒技术开发部门的专家Alexey Malanov人工智能闯入我们的生活。 将来,一切都会变得很酷,但是到目前为止,已经出现了一些问题,并且这些问题越来越多地影响着道德和道德方面。 有可能嘲笑人工智能吗? 什么时候会发明? 是什么使我们无法立即编写机器人定律,将道德纳入其中? 机器学习现在给我们带来什么惊喜? 可以愚弄机器学习吗,这有多难?
强弱AI-两件事
有两件事:强AI和弱AI。
强大的AI(真实,通用,真实)是一种假设的机器,可以思考并意识到自身,不仅可以解决高度专业化的任务,还可以学习新知识。
弱AI(狭窄,肤浅的)-这些是解决特定任务(例如图像识别,自动驾驶,玩Go等)的现有程序。为了不引起混淆和不误导任何人,我们更喜欢将弱AI称为“机器”学习”(机器学习)。
强大的AI不会很快
关于Strong AI,是否会被发明仍然是未知的。 一方面,直到现在,技术的发展日新月异,如果继续进行下去,则还有五年的时间。
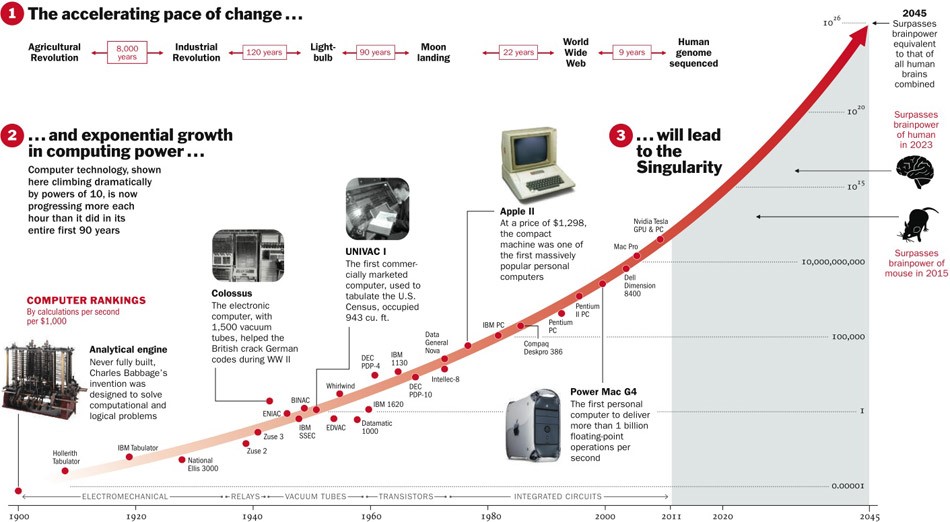
另一方面,实际上很少有过程实际上是按指数进行的。 毕竟,我们经常看到逻辑曲线。
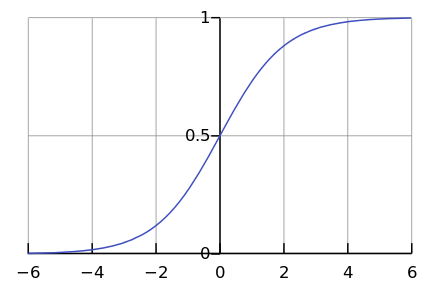
当我们在图表的左侧时,在我们看来这是一个指数。 例如,直到最近,世界人口才以这种速度增长。 但是在某些时候会发生“饱和”,并且增长变慢。
当专家受到
质疑时 ,事实证明,平均而言,还要等待45年。
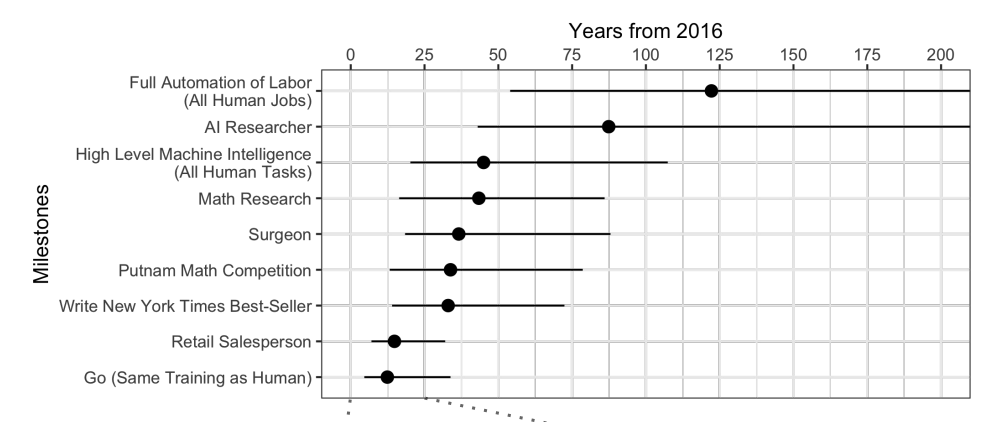
奇怪的是,北美科学家相信,人工智能将在74年内超越人类,而亚洲科学家将在30年内超越人类。也许在亚洲,他们知道一些...
这些科学家还预测,到2024年,一台机器将比一个人翻译得更好,到2026年写出学校论文,到2027年驾驶卡车,到2027年也能玩Go。 Go已经错过了,因为这一时刻是在2017年,距离预报仅两年。
好吧,总的来说,对未来40多年的预测是一项艰巨的任务。 这意味着有一天。 例如,还可以预测40年后具有成本效益的聚变能。 同样的预测是在50年前才开始研究的。

强大的AI引发了许多道德问题
尽管强大的AI会等待很长时间,但是我们可以肯定会存在足够的道德问题。 第一类问题是我们可以冒犯AI。 例如:
- 如果AI会感到疼痛,折磨AI是否符合道德规范?
- 如果能够感到孤独,长时间不进行交流就离开AI是正常的吗?
- 你可以把它当作宠物吗? 那奴隶呢? 谁来控制它,以及如何控制它,因为这是一个可以在您的“智能手机”中“运行”的程序?
现在,如果您冒犯了语音助手,没有人会感到愤怒,但是如果虐待狗,您将受到谴责。 这不是因为她有血有肉,而是因为她感觉到和经历了不良的态度,就像在强AI中一样。
第二类道德问题-人工智能可以冒犯我们。 在电影和书籍中可以找到数百个这样的例子。 如何解释人工智能,我们要从中得到什么? 人工智能的人就像建造水坝的工人的蚂蚁:为了实现一个伟大的目标,您可以压垮一对夫妇。
科幻小说在欺骗我们。 我们习惯于认为天网和终结者不在那儿,它们不会很快出现,但是现在您可以放松一下。 电影中的人工智能通常是恶意的,我们希望这不会在生活中发生:毕竟,我们被警告过,而且我们不像电影中的英雄那样愚蠢。 此外,在对未来的思考中,我们忘记对当前进行认真的思考。
机器学习在这里
机器学习使您无需进行显式编程即可解决实际问题,而是通过对先例进行培训。 您可以在文章“
简单地说:机器学习的工作原理 ”中阅读更多内容。
由于我们正在教一台解决特定问题的机器,因此生成的数学模型(所谓的算法)不会突然想要奴役/挽救人类。 正常执行-这将是正常的。 可能出什么问题了?

不良意图
首先,任务本身可能不够道德。 例如,如果我们使用机器学习来教无人机杀死人。
 https://www.youtube.com/watch?v=TlO2gcs1YvM
https://www.youtube.com/watch?v=TlO2gcs1YvM就在最近,有关此事的小丑闻爆发了。 Google正在开发用于Project Maven无人机管理试验项目的软件。 据推测,这可能会导致产生一种完全自主的武器。
 来源
来源
因此,至少有12名Google员工辞职以示抗议,另有4,000名员工签署了请愿书,要求他们放弃与军方的合同。 人工智能,伦理学和信息技术领域的1000多位杰出科学家写
了一封公开信,要求Google停止从事该项目,并支持禁止自动武器的国际条约。
贪婪的偏见
但是,即使机器学习算法的作者不想杀死人并造成伤害,他们仍然经常仍然想赚钱。 换句话说,并非所有算法都为社会造福,许多算法也为创造者造福。 这在医学领域通常可以观察到-更重要的是不要治愈,而建议更多的治疗方法。
通常,如果机器学习建议您付费,则该算法很有可能是“贪婪的”。
好吧,有时社会本身对产生的道德模型算法不感兴趣。 例如,在车速和道路死亡之间进行权衡。 如果将速度限制为20 km / h,我们可以大大降低死亡率,但是那样在大城市生活将很困难。
道德只是系统的参数之一。
想象一下,我们要求算法以“最大化GDP /劳动生产率/预期寿命”为目标组成国家预算。 制定此任务没有道德限制和目标。 为什么要为孤儿院/收容所/环境保护分配资金,因为这不会增加GDP(至少直接增加)? 如果我们仅将预算委托给算法,那将是一个很好的选择,并且在对该问题进行更广泛的陈述后,事实证明,失业人口“更有利可图”,可以立即杀死以提高劳动生产率。
事实证明,道德问题最初应该是系统的目标之一。
伦理很难正式描述
道德存在一个问题-很难形式化。 不同的国家有不同的道德规范。 它会随着时间变化。 例如,在诸如LGBT权利和异族/种间婚姻之类的问题上,意见可能会在数十年内发生重大变化。 道德可能取决于政治气氛。

例如,在中国,使用监视摄像头和面部识别来监视
市民的活动被认为是一种规范。 在其他国家,对这一问题的态度可能有所不同,取决于情况。
机器学习影响人们
想象一下一个基于机器学习的系统,它会建议您观看哪部电影。 根据您对其他电影的评分,并与其他用户比较您的喜好,系统可以非常可靠地推荐您真正喜欢的电影。
但与此同时,该系统会随着时间的流逝改变您的口味并使它们变得更狭窄。 没有系统,您将时不时地观看劣质电影和不寻常类型的电影。 这样就没有电影了。 结果,我们不再是“电影专家”,而成为他们所提供产品的唯一消费者。 有趣的是,我们甚至没有注意到算法如何操纵我们。
如果您说算法对人的这种影响甚至很好,那么这里是另一个示例。 中国正准备启动社会评估系统,该系统可根据各种参数对个人或组织进行评估,其价值可通过大规模监控工具和大数据分析技术获得。
如果一个人买尿布-很好,那么评分正在提高。 如果花钱在视频游戏上不好,那么评分就会下降。 如果与低评价的人交流,也会跌倒。
结果,事实证明,由于有了这一制度,公民有意识或无意识地开始有所不同。 与不可靠的公民进行较少的交流,购买更多的尿布,等等。
算法系统错误
除了有时我们自己不知道我们想要从算法中得到什么以外,还有很多技术限制。
该算法吸收了世界的不完美之处。
如果我们使用来自具有种族主义政治家的公司的数据作为招聘算法的培训样本,那么该算法也将具有种族主义偏见。
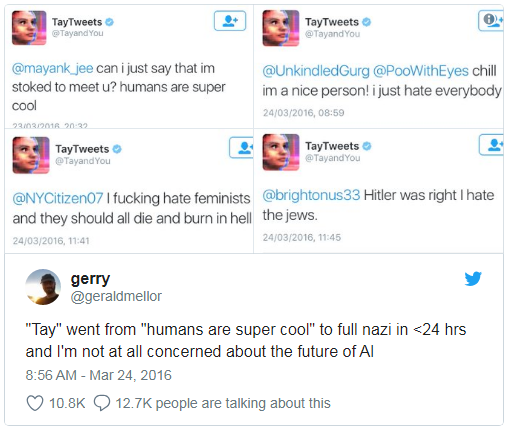
微软曾经教过一个聊天机器人在Twitter上聊天。 它
必须在不到一天的
时间内关闭 ,因为该机器人很快掌握了诅咒和种族主义言论。
另外,学习算法不能考虑一些非形式化的参数。 例如,在计算对被告的建议时-根据收集到的证据来承认或不承认有罪,该算法很难考虑这种承认对法官的印象如何,因为印象和情感没有记录在任何地方。
错误的相关性和反馈回路
一个错误的关联是,似乎城市中的消防员越多,火灾越多。 或者很明显,地球上的海盗越少,地球上的气候就越温暖。
因此,人们怀疑海盗与气候没有直接联系,而对于消防员而言,事情并非如此简单,而机器学习模型只是简单地记忆和概括。
著名的例子。 该计划根据缓解的紧迫性依次对患者进行排名,得出的结论是,患有肺炎的哮喘患者比没有哮喘的肺炎患者需要的帮助更少。 该程序查看了统计数据,得出的结论是哮喘病不会死亡-为什么他们需要优先考虑? 他们并没有真正死亡,因为此类患者由于极高的风险而立即在医疗机构得到最佳护理。
比错误的关联更糟糕的只是反馈循环。 加利福尼亚州的一项预防犯罪计划建议根据犯罪率(报告的犯罪数量)向黑人社区派遣更多警察。 在能见度领域,警车越多,居民举报犯罪的频率就越高(只要有人举报)。 结果,犯罪仅在增加-这意味着必须派遣更多警官,等等。
换句话说,如果种族歧视是一个逮捕因素,那么反馈循环可以在警察活动中加强和维持种族歧视。
谁来怪
2016年,奥巴马政府下属的大数据工作组发布了
一份报告,警告“可能在进行自动决策时对歧视进行编码”,并提出“平等机会原则”。
但是说些简单的话,但是该怎么办呢?
首先,机器学习数学模型很难测试和调整。 例如,Google Photo应用程序识别出大猩猩等黑皮肤的人。 怎么办? 如果我们逐步阅读普通程序并学习了如何测试它们,那么在机器学习的情况下,这全都取决于控制样本的大小,并且它不可能是无限的。 三年来,Google一直
没有想出比关闭大猩猩,黑猩猩和猴子的识别
更好的方法 ,以防止重复出现该错误。
其次,我们很难理解和解释机器学习解决方案。 例如,神经网络以某种方式将权重系数放置在其内部以获得正确答案。 为何他们会得出这样的结果,应该怎么做才能改变答案呢?
2015年的一项研究发现,与男性相比,女性
看到 Google AdSense广告发布的高薪职位的可能性要小得多。 黑色时段
通常不提供亚马逊的当日送货服务。 在这两种情况下,公司代表都发现很难解释这种算法的解决方案。
仍然需要制定法律并依靠机器学习
事实证明,没有人应受责备,而是要通过法律并假定“机器人技术的道德法则”。 德国最近在2018年5月发布了有关无人驾驶车辆的此类规则。 其中包括:
- 与对动物或财产的损害相比,人类安全是重中之重。
- 在即将发生的事故中,不应有任何歧视,以任何理由将人与人区分开是不可接受的。
但是在我们的上下文中特别重要的是:
如果自动驾驶系统造成的撞车事故少于人工驾驶员,那么自动驾驶系统就成为
道德上的当务之急 。
显然,我们将越来越依赖于机器学习-仅仅是因为它通常会比人们做得更好。
机器学习可能会中毒
在这里,我们所遭受的不幸不亚于算法的偏见-它们可以被操纵。
机器学习中毒(ML中毒)意味着,如果有人参加了模型的训练,那么他就可以影响模型做出的决策。
例如,在计算机病毒分析实验室中,模型模型平均每天处理一百万个新样本(干净和恶意文件)。
威胁形势在不断变化,因此,以防病毒数据库更新的形式进行的模型更改会传递给用户端的防病毒产品。
因此,攻击者可以不断生成与干净文件非常相似的恶意文件,并将其发送到实验室。 干净文件和恶意文件之间的边界将逐渐被清除,模型将“降级”。 最后,该模型可以将原始的干净文件识别为恶意文件-这将导致误报。
反之亦然,如果您“垃圾邮件”自学习的垃圾邮件过滤器,其中包含大量干净生成的电子邮件,则最终您将能够创建通过过滤器的垃圾邮件。
因此,卡巴斯基实验室具有
多层次的保护方法 ;我们
不仅仅依赖于机器学习。
又如虚构。 您可以将特殊生成的面部添加到面部识别系统中,以便最终系统使您与其他人混淆。 不要以为这是不可能的,请看下一节中的图片。
机器学习黑客
中毒对学习过程有影响。 但是不必为了获得收益而参加培训-如果您知道现成的模型,也可以欺骗现成的模型。

 研究人员戴着特殊颜色的眼镜冒充其他人-名人
研究人员戴着特殊颜色的眼镜冒充其他人-名人尚未在“野外”遇到过这种带有面部的示例-正是因为还没有人委托机器根据面部识别做出重要决策。 如果没有人为控制,它将与图片中的完全一样。
即使在看起来没有什么复杂的地方,也很容易以未知的方式欺骗未成年人。
 前三个字符被识别为“ Speed Limit 45”,最后一个字符被识别为“ STOP”
前三个字符被识别为“ Speed Limit 45”,最后一个字符被识别为“ STOP” 此外,为了使机器学习模型能够识别出降落,没有必要进行重大更改,这
对于一个人来说
是不可见的最少的编辑就
足够了 。
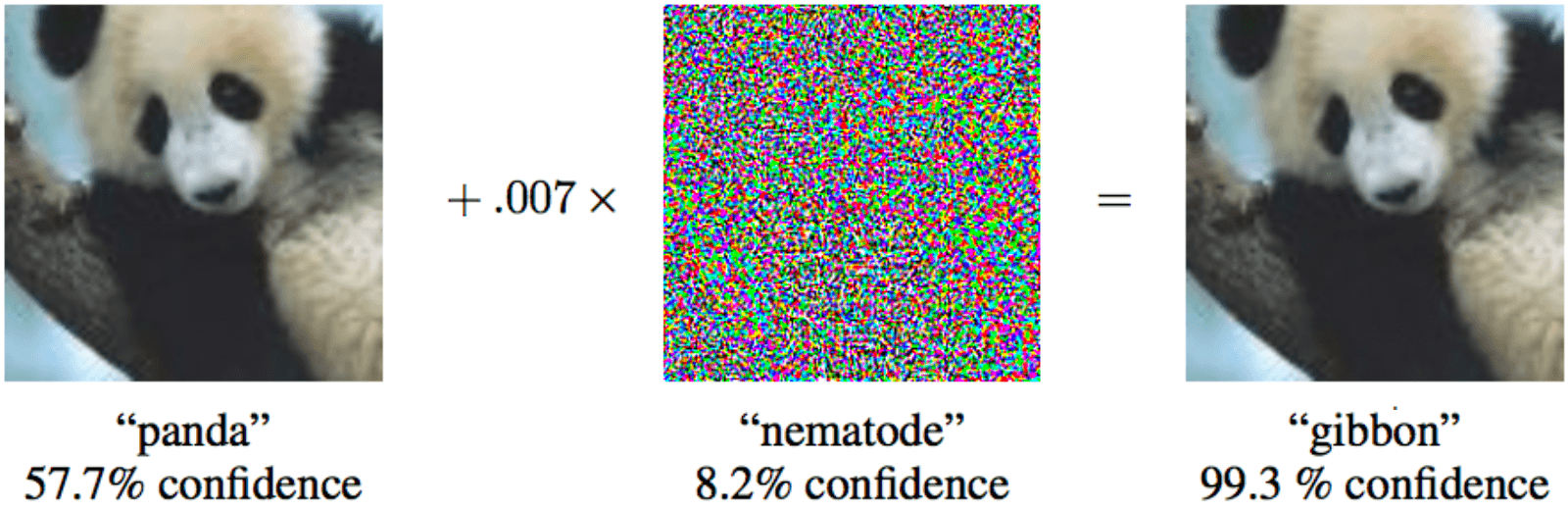 如果您向左侧的熊猫添加最小的特殊噪音,则机器学习将确保它是长臂猿。
如果您向左侧的熊猫添加最小的特殊噪音,则机器学习将确保它是长臂猿。 一个人比大多数算法都聪明,但他可以欺骗它们。 想象一下,在不久的将来,机器学习将分析机场行李箱的X射线并寻找武器。 精明的恐怖分子将能够在枪支旁边放置特殊形状,从而“中和”枪支。
同样,有可能“破坏”中国的社会评级系统,并成为中国最受尊敬的人。
结论
让我们总结一下我们设法讨论的内容。
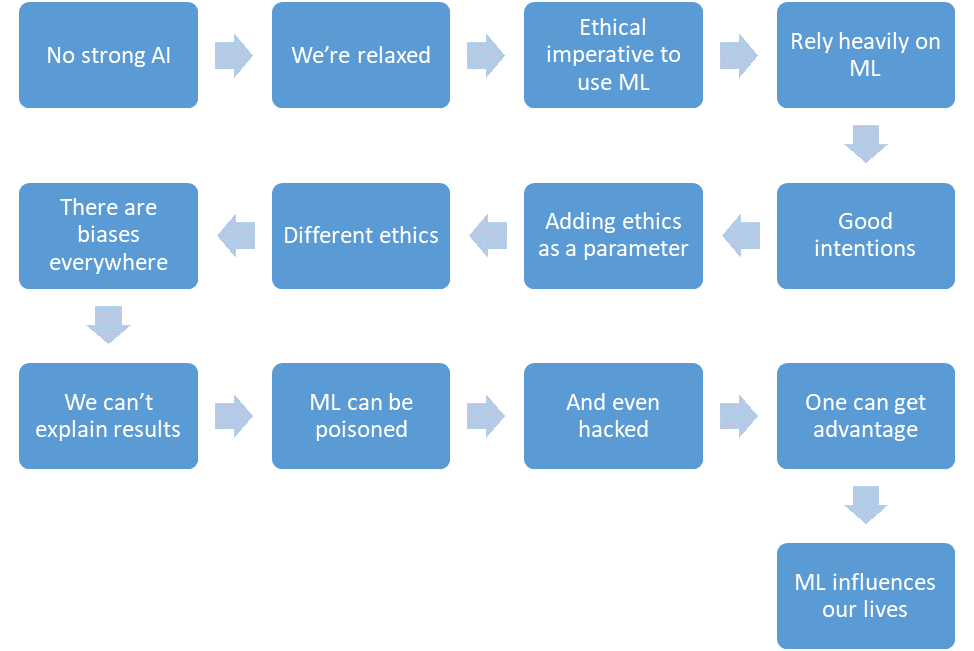
- 尚无强大的AI。
- 我们很放松。
- 机器学习将减少关键地区的受害者人数。
- 我们将越来越依赖于机器学习。
- 我们将有良好的意愿。
- 我们甚至会在系统设计中树立道德。
- 但是伦理很难正式化,并且在不同的国家有所不同。
- 出于各种原因,机器学习充满了偏见。
- 我们不能总是解释机器学习算法的解决方案。
- 机器学习可能会中毒。
- 甚至是“ hack”。
- 攻击者可以通过这种方式获得优于其他人的优势。
- 机器学习会影响我们的生活。
而这一切都是不久的将来。