 第三代张量处理器Google Tensor Processor
第三代张量处理器Google Tensor Processor是
Google专门开发的用于执行机器学习任务的专用集成电路(
ASIC )。 他致力于多种主要Google产品,包括翻译,照片,搜索助手和Gmail。 Cloud TPU为在Google Cloud中启动尖端机器学习模型的所有开发人员和数据科学家提供了可扩展性和易用性的优势。 在Google Next '18上,我们宣布Cloud TPU v2现在可用于所有用户,包括
免费试用帐户 ,并且Cloud TPU v3可用于alpha测试。

但是很多人问-CPU,GPU和TPU有什么区别? 我们制作了一个
演示文稿和动画的
演示站点 ,可以回答这个问题。 在本文中,我将详细介绍本网站内容的某些功能。
神经网络如何工作?
在开始比较CPU,GPU和TPU之前,让我们看一下机器学习(特别是神经网络)需要什么样的计算。
想象一下,例如,我们使用一个单层神经网络来识别手写数字,如下图所示:
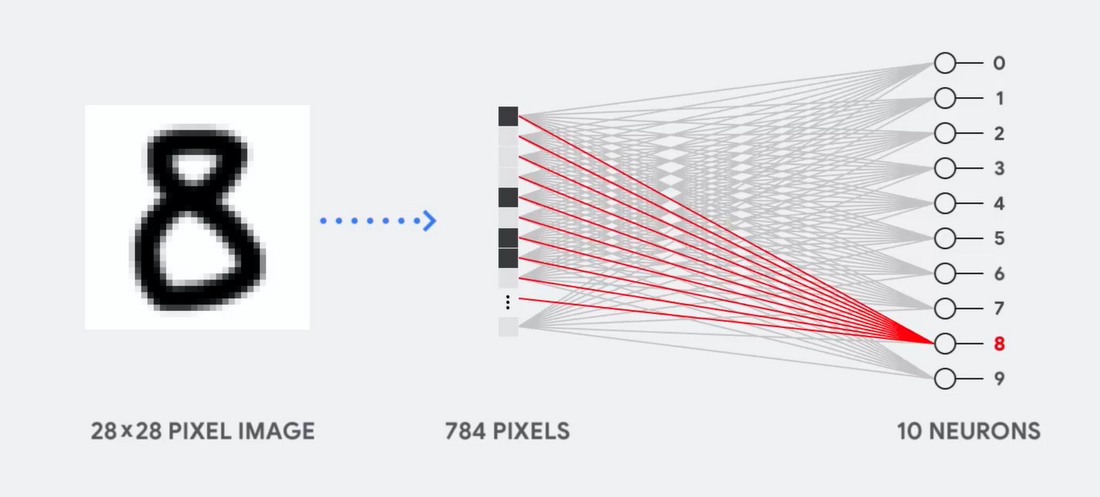
如果图片是灰度为28x28像素的网格,则可以将其转换为784个值(度量)的向量。 识别数字8的神经元将这些值乘以参数值(图中的红线)。
该参数用作过滤器,提取表示图像和形状8相似性的数据特征:

这是通过神经网络对数据分类的最简单解释。 数据与对应于它们的参数(点的颜色)相乘,以及它们的相加(右边的点之和)。 最高的结果表示输入的数据与相应参数之间的最佳匹配,这很可能是正确的答案。
简而言之,神经网络需要对数据和参数进行大量的乘法和加法运算。 我们通常以
矩阵乘法的形式组织它们,您可能在学校的代数中会遇到这种情况。 因此,问题是要尽可能快地执行大量的矩阵乘法,并花费尽可能少的能量。
CPU如何工作?
CPU如何处理此任务? CPU是基于
von Neumann架构的通用处理器。 这意味着CPU可以按以下方式使用软件和内存:
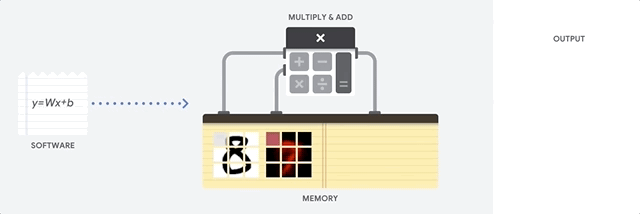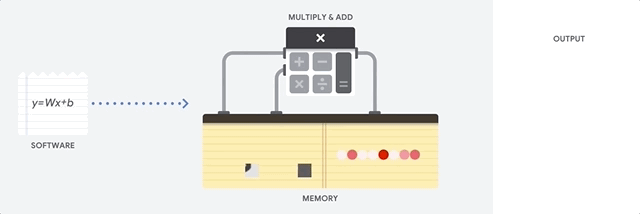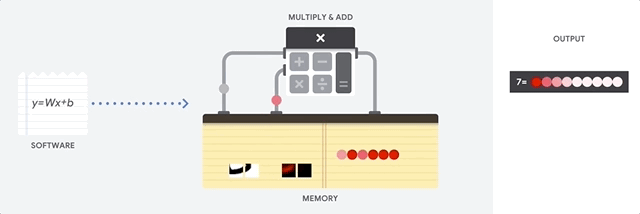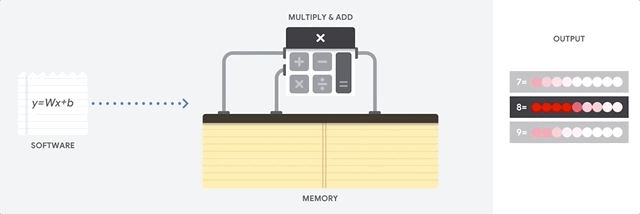
CPU的主要优点是灵活性。 借助von Neumann架构,您可以下载完全不同的软件,以实现数百万个不同的目的。 该CPU可用于文字处理,火箭发动机控制,银行交易,使用神经网络进行图像分类。
但是,由于CPU如此灵活,因此在从软件读取下一条指令之前,设备并不总是事先知道下一步的操作。 CPU需要将每个计算的结果存储在位于CPU内部的内存(所谓的寄存器或
L1缓存 )中。 对该内存的访问成为CPU架构的一个缺点,这被称为von Neumann架构瓶颈。 尽管神经网络的大量计算可以预测未来的步骤,但是每个
算术逻辑 CPU(ALU,用于存储和控制乘法器和加法器的组件)依序执行操作,每次都访问内存,这限制了整体吞吐量并消耗大量能源。
GPU的工作方式
为了与CPU相比提高吞吐量,GPU使用了一种简单的策略:为什么不将数千个ALU集成到处理器中? 现代GPU在处理器上包含大约2500-5000 ALU,这使得一次执行数千次乘法和加法成为可能。

这样的体系结构与需要大量并行化的应用程序很好地配合使用,例如神经网络中的矩阵乘法。 在典型的深度学习(GO)训练负载下,这种情况下的吞吐量与CPU相比增加了一个数量级。 因此,当今,GPU是用于GO的最流行的处理器体系结构。
但是GPU仍然是通用处理器,必须支持一百万种不同的应用程序和软件。 这使我们回到了冯·诺依曼架构瓶颈的根本问题。 对于数千个ALU,GPU中的每次计算,有必要引用寄存器或共享内存,以读取和保存中间计算结果。 由于GPU在其数千个ALU上执行更多的并行计算,因此它也成比例地在内存访问上花费了更多的精力,并占用了很大的面积。
TPU如何工作?
当我们在Google开发TPU时,我们建立了专为特定任务设计的架构。 我们没有开发通用处理器,而是开发了专门用于神经网络的矩阵处理器。 TPU将无法与文字处理器配合使用,控制火箭引擎或执行银行交易,但它可以以惊人的速度处理神经网络的大量乘法和加法运算,同时消耗更少的能量并且体积更小。
允许他执行此操作的主要步骤是从根本上消除了冯·诺伊曼(von Neumann)建筑瓶颈。 由于TPU的主要任务是矩阵处理,因此电路开发人员熟悉所有必要的计算步骤。 因此,他们能够放置数千个乘法器和加法器,并将它们物理连接起来,从而形成一个大的物理矩阵。 这称为
流水线阵列架构 。 在Cloud TPU v2的情况下,使用了两个128 x 128的流水线阵列,总共为一个处理器上的16位浮点值提供32,768个ALU。
让我们看看流水线数组如何执行神经网络的计算。 首先,TPU将内存中的参数加载到乘法器和加法器矩阵中。

然后,TPU从内存中加载数据。 每次乘法完成后,结果将传输到以下因素,同时执行加法。 因此,输出将是数据和参数的所有乘法的总和。 在体积计算和数据传输的整个过程中,完全不需要访问内存。
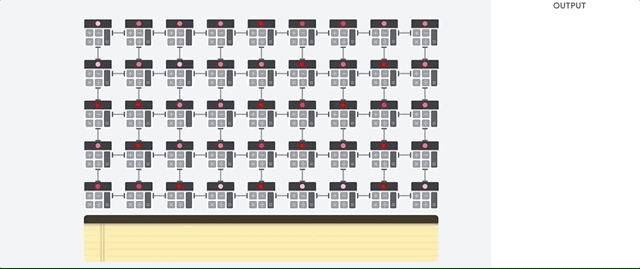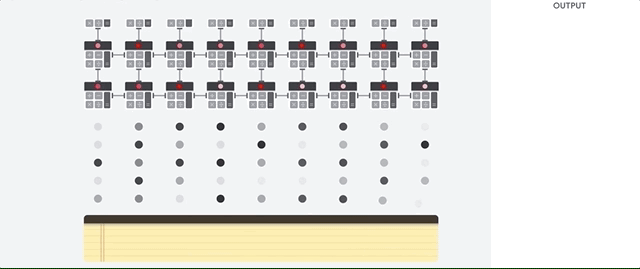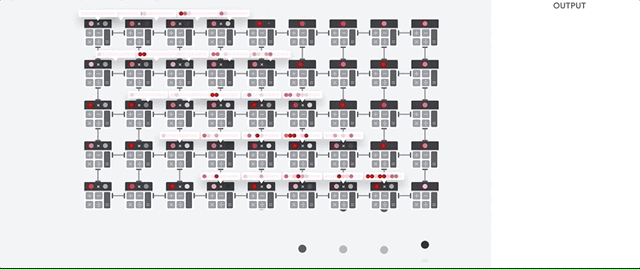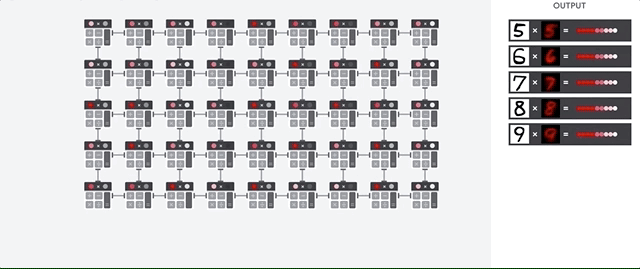
因此,在计算神经网络时,TPU表现出更高的吞吐量,消耗的能源少得多,占用的空间也少。
优势:成本降低5倍
TPU架构的好处是什么? 费用。 在撰写本文时,这是2018年8月Cloud TPU v2的成本:
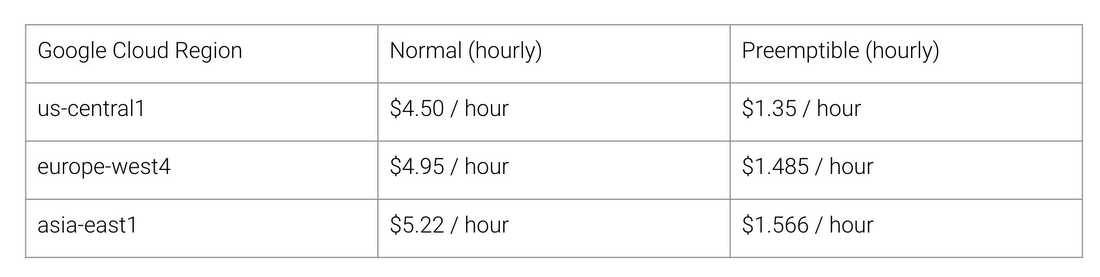
Google Cloud不同区域的正常和TPU工作成本
斯坦福大学正在分发一组
DAWNBench测试,
这些测试可衡量深度学习系统的性能。 在这里,您可以查看任务,模型和计算平台的各种组合以及相应的测试结果。
在2018年4月的竞赛结束时,使用TPU以外的架构的处理器的最低培训成本为72.40美元(用于在
现场实例上以93%的准确度对ResNet-50进行培训)。 有了Cloud TPU v2,这项培训的费用为$ 12.87。 这不到成本的1/5。 这就是专门为神经网络设计的架构的强大功能。