
不幸的是,在Internet上,关于实际应用程序的迁移以及Percona XtraDB群集(以下称为PXC)的生产操作的信息不足。 我将尝试纠正这种情况,并讲述我的经历。 将没有分步安装说明,并且不应将本文视为文档外的替代品,而应将其作为建议的集合。
问题
我在
Ultimate-guitar.com担任系统管理员。 由于我们提供Web服务,因此我们自然会有后端和数据库,这是该服务的核心。 服务正常运行时间直接取决于数据库性能。
Percona MySQL 5.7被用作数据库。 保留是使用主复制方案master实现的。 从站用于读取一些数据。
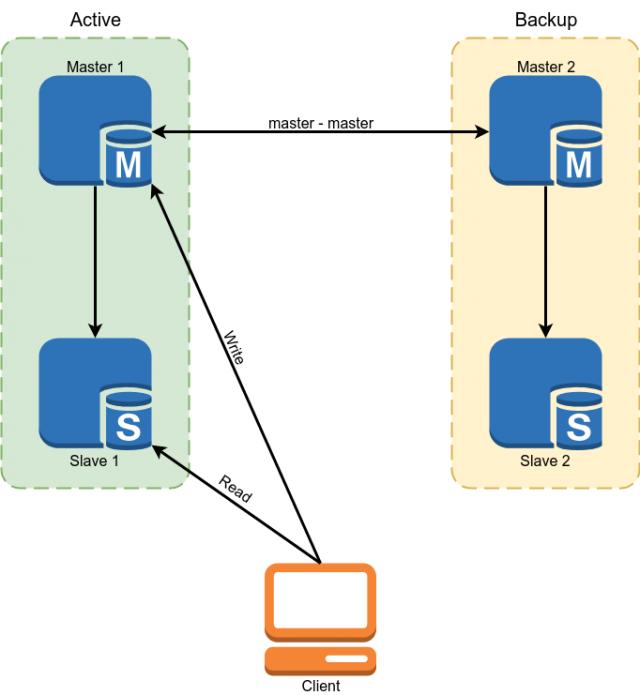
但是此方案不适合我们,但具有以下缺点:
- 由于在MySQL复制中,异步从站可能会无限期滞后。 必须从主机读取所有关键数据。
- 从上一段可以看出开发的复杂性。 开发人员不仅可以向数据库发出请求,还必须考虑是否在每种情况下都准备好从属服务器的积压工作,如果没有,则从向导中读取数据。
- 发生事故时进行手动切换。 由于MySQL体系结构没有针对脑裂的内置保护,因此实现自动切换存在问题。 我们将不得不为自己编写一个具有选择主控器复杂逻辑的仲裁器。 当向两个母版写信时,冲突可能同时发生,从而破坏了母版复制并导致经典的裂脑。
一些干燥的数字,以便您了解我们的工作方式:
数据库大小:300 GB
QPS:〜10k
RW比率:96/4%
主服务器配置:
CPU:2个E5-2620 v3
内存:128 Gb
固态硬盘:英特尔Optane 905p 960 Gb
网络:1 Gbps
我们有一个经典的OLTP负载,需要大量阅读,这需要非常快速地完成,并且需要少量的编写。 由于Redis和Memcached中积极使用了缓存,因此数据库的负载很小。
决策选择
正如您可能从标题中猜到的那样,我们选择了PXC,但在这里我将解释为什么选择它。
我们有4个选择:
- 变更DBMS
- MySQL组复制
- 在主复制主机上使用脚本自己拧紧必要的功能。
- MySQL Galera集群(或其分支,例如PXC)
几乎没有考虑过更改数据库的选项,因为 该应用程序很大,在许多地方,它都与mysql功能或语法联系在一起,例如,迁移到PostgreSQL将花费大量时间和资源。
第二个选项是MySQL组复制。 毫无疑问,它是在MySQL的Vanilla分支中开发的,这意味着它将来会变得广泛并且拥有大量的活动用户。
但是他有一些缺点。 首先,它对应用程序和数据库架构施加了更多限制,这意味着迁移将更加困难。 其次,组复制解决了容错和脑裂的问题,但是集群中的复制仍然是异步的。
我们也不喜欢太多自行车的第三种选择,在以这种方式解决问题时,我们不可避免地要实现这一选择。
Galera允许完全解决MySQL故障转移问题,并部分解决与从站上数据相关的问题。 部分原因是维护了复制异步。 在本地节点上提交事务后,更改将异步推送到其余节点,但是群集确保节点不会滞后太多,如果节点开始滞后,则会人为地减慢工作速度。 群集可确保在提交事务后,即使在尚未复制更改的节点上,也没有人可以提交冲突的更改。
迁移后,数据库操作方案应如下所示:
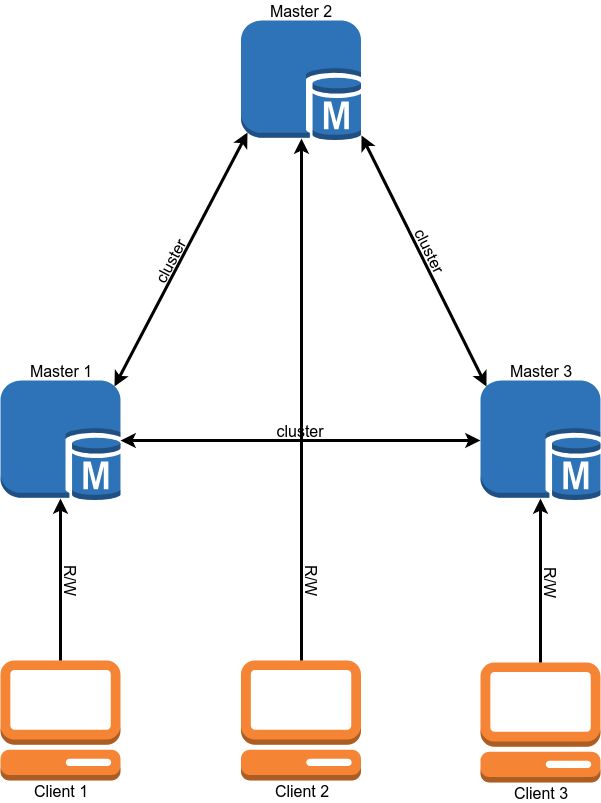
迁移
为什么选择解决方案后迁移第二个项目? 这很简单-集群包含应用程序和数据库必须遵循的许多要求,并且我们需要在迁移之前满足它们。
- 所有表的InnoDB引擎。 不支持MyISAM,内存和其他后端。 它很简单地解决了-我们将所有表都转换为InnoDB。
- ROW格式的Binlog。 群集不需要二进制日志即可工作,并且如果不需要经典从属,可以将其关闭,但是二进制日志格式应为ROW。
- 所有表必须具有主键/外键。 这是从不同节点正确并发写入同一表所必需的。 对于那些不包含唯一键的表,可以使用复合主键或自动递增。
- 请勿对事务使用“ LOCK TABLES”,“ GET_LOCK()/ RELEASE_LOCK()”,“ FLUSH TABLES {{table}} WITH READ LOCK”或隔离级别“ SERIALIZABLE”。
- 不要使用“ CREATE TABLE ... AS SELECT”查询 ,因为 他们结合了模式和数据更改。 它很容易分为两个查询,第一个查询创建一个表,第二个查询填充数据。
- 不要使用“ DISCARD TABLESPACE”和“ IMPORT TABLESPACE” ,因为 他们没有被复制
- 将选项“ innodb_autoinc_lock_mode”设置为“ 2”。 使用STATEMENT复制时,此选项可能会破坏数据,但是由于群集中仅允许ROW复制,因此不会有问题。
- 作为“ log_output”,仅支持“ FILE”。 如果表中有日志条目,则必须将其删除。
- 不支持XA事务。 如果使用了它们,则必须在没有它们的情况下重写代码。
我应该注意,如果您设置变量'pxc_strict_mode = PERMISSIVE',几乎所有这些限制都可以删除,但是如果您的数据对您很重要,那么最好不要这样做。 如果设置了“ pxc_strict_mode = ENFORCING”,则MySQL将不允许您执行上述操作或阻止节点启动。
在满足了数据库的所有要求并在开发环境中全面测试了我们的应用程序的运行之后,我们可以进入下一个阶段。
群集部署和配置
我们在数据库服务器上运行着几个数据库,其他数据库不需要迁移到集群。 但是带有MySQL群集的软件包可以代替经典的mysql。 对于此问题,我们有几种解决方案:
- 使用虚拟化并在VM中启动群集。 我们之所以不喜欢此选项,是因为其开销很大(与其余部分相比),并且需要维修另一个实体
- 构建您的软件包版本,这会将mysql放在非标准位置。 因此,在一台服务器上可以有多个版本的mysql。 如果您有许多服务器,那么这是一个不错的选择,但是需要定期更新软件包的持续支持会花费大量时间。
- 使用Docker。
我们选择了Docker,但在最小选项中使用了它。 对于数据存储,使用本地卷。 “ --net host”操作模式用于减少网络延迟和CPU负载。
我们还必须构建我们自己的Docker映像版本。 原因是Percona的标准映像在启动时不支持还原位置。 这意味着,每次重新启动实例时,它不会执行快速的IST同步(仅上载必要的更改),而是执行缓慢的SST,从而完全重新加载数据库。
另一个问题是群集大小。 在群集中,每个节点都存储整个数据集。 因此,阅读随着簇大小的增加而完美地缩放。 与记录相反,情况相反-提交时,将验证每个事务在所有节点上是否没有冲突。 自然,节点越多,提交将花费的时间越多。
在这里,我们还有几种选择:
- 2个节点+仲裁器。 2个节点+仲裁器。 测试的好选择。 在部署第二个节点期间,主节点不应记录。
- 3个节点。 经典版本。 速度与可靠性之间的平衡。 请注意,在此配置中,一个节点必须扩展整个负载,因为 在添加第三个节点时,第二个将是施主。
- 4个以上的节点。 对于偶数个节点,有必要添加一个仲裁器以避免裂脑。 一个非常适合大量阅读的选项。 群集的可靠性也在增长。
到目前为止,我们已经选择了具有3个节点的选项。
集群配置几乎完全复制了独立的MySQL配置,并且仅在几个选项上有所不同:
“ Wsrep_sst_method = xtrabackup-v2”此选项设置复制节点的方法。 其他选项是mysqldump和rsync,但它们在复制期间会阻塞节点。 我认为没有理由使用non-xtrabackup-v2复制方法。
“ Gcache”是集群binlog的类似物。 它是固定大小的循环缓冲区(在文件中),所有更改都写入其中。 如果关闭群集节点之一,然后再将其重新打开,它将尝试从Gcache读取丢失的更改(IST同步)。 如果它没有节点所需的更改,则将需要完全重新加载节点(SST同步)。 gcache的大小设置如下:wsrep_provider_options ='gcache.size = 20G;'。
wsrep_slave_threads与集群中的经典复制不同,可以将多个“写集”并行应用于同一数据库。 此选项指示应用更改的工作人员数量。 最好不要保留默认值1,因为 在工作者应用大写集的过程中,其余的将在队列中等待,并且节点复制将开始滞后。 有人建议将此参数设置为2 * CPU THREADS,但是我认为您需要查看您具有的并发写入操作的数量。
我们将值定为64。在较低的值上,集群有时无法在负载突发期间(例如,启动重冠时)无法应用队列中的所有写集。
wsrep_max_ws_size集群中单个事务
的大小限制为2 GB。 但是,大笔交易与PXC概念不太吻合。 最好完成100个20 MB的事务,而不是每2 GB 1个事务。 因此,我们首先将群集中的事务大小限制为100 MB,然后将限制减小为50 MB。
如果启用了严格模式,则可以将变量“
binlog_row_image ”设置为“ minimal”。 这将使binlog中条目的大小减少数倍(Percona测试中为10倍)。 这样可以节省磁盘空间,并允许不符合“ binlog_row_image = full”限制的事务。
SST的限制。 对于用于填充节点的Xtrabackup,您可以设置网络使用,线程数和压缩方法的限制。 这是必要的,以便在节点被填充时,施主服务器不会开始变慢。 为此,将“ sst”部分添加到my.cnf文件中:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
我们将复制速度限制为80 Mb / s。 我们使用Pigz进行压缩,这是gzip的多线程版本。
GTID如果您使用经典从站,则建议在集群上启用GTID。 这将允许您将从站连接到群集的任何节点,而无需重新加载从站。
另外,我想谈谈2个集群机制,它们的含义和配置。
流量控制
流控制是一种管理集群中的写负载的方法。 它不允许节点在复制中滞后太多。 这样,实现了“几乎同步”的复制。 操作机制非常简单-接收队列长度达到设置值后,它将向其他节点发送消息“流控制暂停”,该消息告诉其他节点暂停提交新事务,直到滞后节点完成耙入队列。
由此得出以下几点:
- 群集中的记录将以最慢的节点速度进行。 (但是可以收紧。)
- 如果在提交事务时有很多冲突,则可以更积极地配置Flow Control,这将减少它们的数量。
- 群集中节点的最大延迟是一个常数,但不是时间,而是队列中的事务数。 滞后时间取决于平均事务大小和wsrep_slave_threads的数量。
您可以按以下方式查看流控制设置:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
首先,我们对wsrep_flow_control_interval_high参数感兴趣。 它控制队列的长度,然后打开FC暂停。 该参数由以下公式计算:gcs.fc_limit *√N(其中N =群集中的节点数。)。
第二个参数是wsrep_flow_control_interval_low。 它负责队列长度的值,到达该值时将关闭FC。 由以下公式计算:wsrep_flow_control_interval_high * gcs.fc_factor。 默认情况下,gcs.fc_factor = 1。
因此,通过更改队列的长度,我们可以控制复制延迟。 减少队列的长度将增加群集花费在FC暂停上的时间,但会减少节点的延迟。
您可以设置会话变量“
wsrep_sync_wait = 7”。 这将强制PXC仅在应用当前队列中的所有写集之后执行读或写请求。 自然,这将增加请求的延迟。 延迟的增加与队列的长度成正比。
还希望将最大交易规模减小到最小,以使长交易不会意外漏掉。
EVS或自动逐出
此机制使您可以丢弃不稳定(例如,数据包丢失或长时间延迟)或响应缓慢的节点。 多亏了它,与一个节点的通信问题将不会放置整个群集,而是让该节点被禁用并继续以正常模式工作。 当群集通过WAN或不受您控制的网络部分运行时,此机制特别有用。 默认情况下,EVS是关闭的。
要启用它,请将选项“ evs.version = 1;”添加到
wsrep_provider_options参数中 和“ evs.auto_evict = 5;” (节点关闭之后的操作次数。值为0会禁用EVS。)还有几个参数可让您微调EVS:
- evs.delayed_margin节点响应所花费的时间。 默认情况下为1秒,但是在本地网络上工作时,可以将其降低到0.05-0.1秒或更短。
- evs.inactive_check_period检查周期。 预设0.5秒
实际上,在触发EVS之前出现问题时,节点可以工作的时间是evs.inactive_check_period * evs.auto_evict。 您还可以设置“ evs.inactive_timeout”,并且默认情况下15秒将立即丢弃不响应的节点。
一个重要的细微差别是,该机制本身在恢复通信时不会将节点返回。 必须手动重新启动。
我们在家里设置了EVS,但我们没有机会在战斗中对其进行测试。
负载均衡
为了使客户端平均使用每个节点的资源并仅在活动集群节点上执行请求,我们需要一个负载平衡器。 Percona提供2种解决方案:
最初,我们想使用ProxySQL,但是在进行基准测试后,即使使用fast_forward模式,延迟也会使Haproxy损失约15-20%(查询重写,路由和许多其他ProxySQL函数在该模式下不起作用,请求按原样被代理) 。
Haproxy更快,但是Percona脚本有一些缺点。
首先,它是用bash编写的,这对其自定义没有帮助。 更严重的问题是它不缓存MySQL检查的结果。 因此,如果我们有100个客户端,每个客户端每1秒钟检查一次节点状态,则脚本将每10毫秒向MySQL发出一次请求。 如果由于某种原因MySQL开始运行缓慢,那么验证脚本将开始创建大量进程,这肯定不会改善这种情况。
决定编写
一种解决方案 ,其中MySQL状态检查和Haproxy响应彼此不相关。 该脚本会定期检查后台节点的状态,并缓存结果。 Web服务器为Haproxy提供缓存的结果。
Haproxy配置示例listen db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
本示例显示单个向导配置。 其余的群集服务器充当从属服务器。
监控方式
为了监视集群状态,我们使用了Prometheus + mysqld_exporter和Grafana来可视化数据。 因为 mysqld_exporter收集了很多指标来自己创建仪表板,这非常繁琐。 您可以
从Percona获取现成的
仪表板,并为自己定制它们。
我们还使用Zabbix收集基本的集群指标和警报。
您要监视的主要群集指标:
- wsrep_cluster_status必须在所有节点上都设置为Primary。 如果值为“ non-Primary”,则此节点已失去与群集仲裁的联系。
- wsrep_cluster_size集群中的节点数。 这也包括“丢失”的节点,这些节点必须在群集中,但由于某些原因不可用。 轻轻关闭节点时,此变量的值减小。
- wsrep_local_state指示节点是否是集群的活动成员并且准备就绪。
- wsrep_evs_state如果已启用“自动逐出”(默认为关闭), 则为重要参数。 此变量表示EVS认为此节点运行状况良好。
- wsrep_evs_evict_list EVS从集群抛出的节点列表。 在正常情况下,列表应该为空。
- wsrep_evs_delayed除去EVS的候选对象的列表。 还必须为空。
关键绩效指标:
- wsrep_evs_repl_latency显示(最小/平均/最大/高级偏差/数据包大小)集群内的通信延迟。 即,它测量网络延迟。 值增加可能表示网络或群集节点过载。 即使关闭EVS,也会记录此指标。
- wsrep_flow_control_paused_ns自节点启动以来在流控制暂停中花费的时间(以ns为单位)。 理想情况下,它应该为0。此参数的增长表明集群性能存在问题或缺少“ wsrep_slave_threads”。 您可以通过参数“ wsrep_flow_control_sent ”确定哪个节点变慢。
- wsrep_flow_control_paused自上次执行“ FLUSH STATUS”以来的时间百分比,该节点花费在Flow控制上暂停。 与先前的变量一样,它应趋于零。
- wsrep_flow_control_status指示流控制当前是否正在运行。 在FC暂停启动节点上,此变量的值为ON。
- wsrep_local_recv_queue_avg平均接收队列长度。 此参数的增加表明节点性能存在问题。
- wsrep_local_send_queue_avg发送队列的平均长度。 此参数的增加表示网络性能问题。
这些参数的值没有通用的建议。 显然,它们应该趋于零,但是在实际负载下,情况极有可能并非如此,您必须自己确定群集正常状态的边界通过的位置。
后备
集群备份实际上与独立的mysql没有什么不同。 对于生产用途,我们有几种选择。
- 使用xtrabackup从“增益”节点之一中删除备份。 最简单的选择,但是在备份群集期间,性能将被浪费。
- 使用经典从属服务器并从副本进行备份。
具有独立备份和使用xtrabackup创建的群集版本的备份可相互移植。 也就是说,可以将从群集中获取的备份部署到独立的mysql,反之亦然。 自然,MySQL的主要版本应该匹配,最好是次要版本。 使用mysqldump进行的备份自然也可以移植。
唯一的警告是,在部署备份之后,必须运行mysql_upgrade脚本,该脚本将检查并更正某些系统表的结构。
资料迁移
现在我们已经弄清了配置,监视和其他内容,我们可以开始迁移到产品了。
我们的方案中的数据迁移非常简单,但是有点麻烦;)。
图例-主机1和主机2通过主机复制主机连接。 记录仅转到主服务器1。主服务器3是一台干净的服务器。
我们的迁移计划(在该计划中,为简单起见,我将省略与从属服务器的操作,而只谈论主服务器)。
尝试1
- 使用xtrabackup从主机1删除数据库备份。
- 将备份复制到主服务器3,然后以单节点模式运行群集。
- 在主机3和主机1之间设置主机复制。
- 将读写切换到主机3.检查应用程序。
- 在主服务器2上,关闭复制并启动群集MySQL。 我们正在等待他从主服务器3复制数据库。在复制过程中,我们有一个群集,其中一个节点处于“捐赠者”状态,而另一个节点仍未工作。 在复制期间,我们得到了一堆锁,最后两个节点都因错误而掉线(由于死锁而无法创建新节点)。 这个小实验耗费了我们四分钟的停机时间。
- 将读写切换回主机1。
由于在数据库上的开发环境中测试电路时,实际上没有写流量,并且在负载下重复同一电路时,出现了问题,因此迁移不起作用。
为了避免这些问题,我们对迁移方案进行了些微更改,然后第二次成功重试;)。
尝试2
- 我们重新启动母版3,以便它可以在单节点模式下再次运行。
- 我们再次在master 2上引发集群MySQL。 目前,来自复制的流量仅流向群集,因此锁没有重复出现的问题,并且第二个节点已成功添加到群集。
- 再次,将读写切换到主机3。我们检查应用程序的操作。
- 禁用与master 1的master复制。在master 1上打开集群mysql,并等待其启动。 为了避免踩到相同的耙子,重要的是应用程序不要写入Donor节点(有关详细信息,请参阅负载平衡部分)。 启动第三个节点后,我们将具有三个节点的功能齐全的集群。
- 您可以从群集的一个节点上删除备份,并创建所需的经典从站数量。
第二种方案与第一种方案的区别在于,仅在提升集群中的第二个节点之后,我们才将流量切换到集群。
这个过程大约花了我们6个小时。
多主机
迁移之后,我们的集群以单主机模式工作,也就是说,整个记录进入了其中一台服务器,而其余的仅读取了数据。
将生产切换到多主模式后,我们遇到了一个问题-发生事务冲突的频率比我们预期的要高。 这对于修改许多记录的查询尤其不利,例如,更新表中所有记录的值。 那些在群集上的同一节点上依次成功执行的事务将并行执行,较长的事务将收到死锁错误。 在进行了几次尝试以解决应用程序级别的问题之后,我不会再拖延了,我们放弃了多主设备的想法。
其他细微差别
- 群集可以是从属。 使用此功能时,建议将除从站选项“ skip_slave_start = 1”之外的所有节点添加到配置中。 否则,每个新节点都将从主服务器开始复制,这将导致复制错误或副本上的数据损坏。
- 正如我所说的捐助者,一个节点不能正确地为客户服务。 必须记住,在一个由三个节点组成的群集中,可能会出现以下情况:一个节点已流出,第二个节点是捐助方,仅剩下一个节点可用于客户服务。
结论
经过迁移和一些操作时间后,我们得出以下结论。
- Galera集群可以正常工作并且非常稳定(至少只要没有异常的节点掉落或异常行为即可)。 在容错方面,我们得到了我们想要的。
- Percona的多主报表主要是市场营销。 是的,可以在此模式下使用集群,但这将需要对该使用模型的应用程序进行深度改动。
- 没有同步复制,但是现在我们控制(在事务中)节点的最大延迟。 再加上最大事务大小为50 MB的限制,我们可以相当准确地预测节点的最大延迟时间。 开发人员编写代码变得更加容易。
- 在监视中,我们观察到复制队列增长的短期峰值。 原因是在我们的1 Gbit / s网络中。 可以在这样的网络上运行群集,但是在负载突发期间会出现问题。 现在我们计划将网络升级到10 Gbit / s。
我们总共收到了三个“愿望清单”,大约一个半。 最重要的要求是容错能力。
对于那些感兴趣的人,我们的PXC配置文件:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
来源和有用的链接
→
我们的Docker映像→
Percona XtraDB Cluster 5.7文档→
监视群集状态-Galera群集文档→
Galera状态变量-Galera群集文档