周围世界的空间充满了各个事件及其链接-这些事件反映在媒体上,在社交网络上的博客作者和普通民众中,也是如此。 仅当我们对同一问题收集不同的观点时,才能获得具有一定程度客观性的周围现实图景。 事件的分类程序是“收集”所收集信息的工具:事件描述的版本。 接下来,通过搜索工具,建议和事件时间序列的直观表示,向用户提供有关事件信息的访问权限。
今天,我们将以代号“ Varya”谈论我们的系统,更确切地说是其软件核心,以表彰主要开发人员。
我们尚未提及启动公司的名称,应Habrahabr主管部门的要求,现在我们已提交了一个申请来分配启动状态。 但是,我们现在可以告诉您有关功能和我们的想法。 我们的系统确保事件信息与用户和有效的数据管理的相关性-在系统中,每个用户自己确定要观看和阅读的内容,控制搜索和推荐。
我们的项目是一个由8人组成的团队的初创公司,他们具有在技术和算法上复杂的系统,编程,营销和管理方面的设计能力。
团队在一起每天都在进行项目工作-已经实施了用于分类,搜索和呈现信息的算法。 与针对用户的推荐相关的算法的实现仍然遥遥领先:基于事件,人员之间的关系以及对用户活动和兴趣的分析。
我们要解决什么任务,为什么要讨论呢? 我们帮助人们获得有关任何规模的事件的详细信息,无论它们发生在何处以及何时发生。
该项目为用户提供了一个在志趣相投的圈子中讨论事件的平台,使您可以分享评论或自己所发生事件的版本。 社交媒体平台是为那些想要了解“高于平均水平”并对过去,现在和未来的主要事件有个人见解的人创建的。
用户自己可以在媒体空间中找到并创建有用的内容,并监视其可靠性。 我们对他们生活中的事件记忆深刻。
现在该项目处于MVP阶段,我们正在测试有关分类程序功能和工作的假设,以便确定进一步开发的正确方向。 在本文中,我们将讨论解决任务并共享最佳实践的技术。
机器单词处理的任务由搜索引擎解决:Yandex,Google,Bing等。 用于处理信息流并隔离其中的事件的理想系统如下所示。
为该系统构建了类似于Yandex和Google的基础架构,实时扫描整个Internet进行更新,然后在信息流中分配事件内核,围绕这些事件内核形成其版本和相关内容的聚集。 该服务的软件实现基于深度学习神经网络和/或基于Yandex库CatBoost的解决方案。
很酷 但是,我们还没有这么大量的数据,也没有相应的计算资源来进行同化。
按主题分类是一项流行的任务,有许多解决方案可用于解决该问题:朴素的贝叶斯分类器,潜在的狄利克雷位置,决策树和神经网络的提升。 可能在机器学习的所有问题中,当使用所描述的算法时,都会出现两个问题:
首先,从哪里获取大量数据?
其次,如何廉价而愤怒地放置它们?
我们为基于事件的系统选择了哪种方法?
我们的产品适用于事件。 活动与常规文章有所不同。
为了克服“冷启动”,我们决定使用两个WikiMedia项目:Wikipedia和Wikinews。 一篇Wikipedia文章可以描述几个事件(例如,Sun Microsystems的发展历史,Mayakovsky的传记或伟大卫国战争的进程)。
事件信息的其他来源是RSS feed。 新闻以不同的方式发生:大型分析文章包含多个事件,例如Wikipedia文本,而来自各种来源的简短信息性消息则表示同一事件。
因此,文章和事件形成了多对多关系。 但是在MVP阶段,我们假设一件文章是一件事件。
查看Google或Yandex的界面,您可能会认为搜索引擎仅查找关键字。 这仅适用于非常简单的在线零售商。 大多数搜索引擎都是多条件的,我们项目的引擎也不例外。 此外,在用户界面中不会显示在搜索过程中考虑的所有参数。 我们的项目具有用户选择的参数列表,例如:
主题和关键字-
“什么?” ; 位置-
“在哪里?” ; 日期-
“何时?” ;
那些编写搜索引擎的人都知道,仅关键字一个字就会引起很多问题。 好吧,其余选项也不是那么简单。
事件的主题是一件非常困难的事情。 人脑的设计使其喜欢对所有事物进行分类,而现实世界对此表示强烈反对。 传入的文章希望形成自己的主题组,而它们根本不是我们和我们的热情用户分发给他们的主题。
现在,我们有15个主要的事件主题,并且此列表已进行了多次修订,并且至少会有所增加。
位置和日期安排得更正式一些,但是这里有一些陷阱。
因此,我们有一套正式的标准和原始数据,我们需要将其映射到这些标准。 这就是我们的工作方式。
蜘蛛网
蜘蛛程序的任务是折叠进入的物品,以便可以对其进行快速搜索。 为此,蜘蛛程序必须能够将主题,位置和日期归因于文章以及排名所需的其他一些参数。 我们的输入蜘蛛会接收由搜寻器构建的文章的文本模型。 文本模型是文章各部分及其对应文本的列表。 例如,几乎每篇文章都至少具有标题和正文。 实际上,她仍然具有第一段,该文本引用其来源的一组类别以及一个信息框字段的列表(对于Wikipedia以及具有此类元数据标签的源)。 还有一个出版日期。 为了在搜索引擎中排名,对于我们来说重要的是要知道例如是否在标题中或文本末尾的某处找到了日期。 文本模型用于构建主题模型,位置模型和日期模型,然后将结果添加到索引。 可以单独撰写有关每种模型的文章,因此在这里我们仅简要概述这些方法。
主题
确定文档的主题是一项常见的任务。 主题可以由文档作者手动分配,也可以自动确定。 当然,我们有新闻来源和Wikipedia归因于我们文档的主题,但是这些主题与事件无关。 您是否经常在新闻源中找到“假日”主题? 相反,您将满足“社会”的主题。 我们在最早的版本中也有此版本。 我们无法确定应该与之相关的内容,因此被迫将其删除。 此外,所有资源都有自己的一套主题。
我们要管理在界面中显示给用户的主题列表,因此对我们而言,确定文档主题的任务是模糊分类的任务。 分类任务需要带有标签的示例,即我们希望的主题已归属到的文档列表。 我们的列表与所有类似的主题列表相似,但是与它们不符,因此我们没有带标签的样本。 您也可以手动或自动获取它,但是如果我们的主题列表发生了变化(并且将会改变!),则不能选择手动获取。
如果没有标记的样本,则可以使用潜在的Dirichlet放置和其他主题建模算法,但是,得到的结果将是结果,而不是您想要的。
在这里,我们必须提到另外一点:我们的文章来自不同的来源。 所有主题模型都是在使用的词汇上以一种或另一种方式构建的。 对于新闻和维基百科,它是不同的,甚至是筛选过的高频。
因此,我们面临两项任务:
1.提出一种以半自动模式快速布置文档的方法。
2.基于这些文档,为我们的主题建立一个可扩展的模型。
为了解决这些问题,我们创建了一个混合算法,其中包含图中所示的自动和手动阶段。
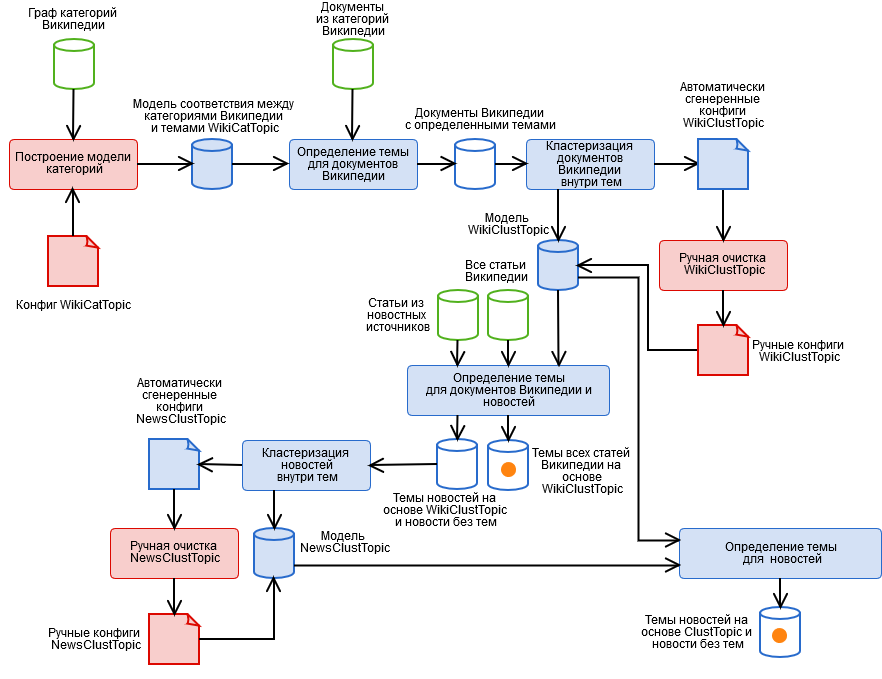
- 手动Wikipedia类别标记,并获取WikiCatTopic类别主题模型。 在此阶段,将构建一个配置,该配置将Wikipedia的WT类别的子图分配给我们的每个T主题。 维基百科是伪本体论。 这意味着,如果某物属于“科学”类别,那么它可能根本就与科学无关,例如,从无害的子类别“信息技术”中,您实际上可以进入任何Wikipedia文章。 需要单独的文章介绍如何使用它。
- 基于WikiCatTopic自动检测Wikipedia文档的主题。 如果文档属于图表CT的类别之一,则为该文档分配主题T。 请注意,此方法仅适用于Wikipedia文章。 要将主题的定义概括为任意文本,可以构建每个主题的词袋,并考虑到主题的余弦距离(我们尝试过,没有什么好处),但是这里必须考虑三件事。
- 此类主题包含非常多样的文章,因此该主题在单词空间中的形象将不会连贯,这意味着这种模型在确定主题方面的``信心''非常低(毕竟,该文章与一小部分文章相似,但与其余文章相似)。
- 任意文本,主要是新闻,其词法构成与维基百科不同;这也没有添加“确定性”模型。 此外,某些主题不能建立在Wikipedia上。
- 第一阶段是一项非常艰苦的工作,每个人都懒得去做。
- 使用k-means方法基于段落2的结果在主题内对文档进行聚类,并获得WikiClustTopic主题的聚类模型。 这是一个相当简单的举动,使我们能够从很大程度上解决第2段中的三个问题中的两个。对于聚类,我们建立词袋,并且将属于主题的定义为与其聚类的余弦距离的最大值。 我们的集群和Wikipedia文档之间的对应关系的配置文件中描述了该模型。
- 手动清理WikiClustTopic模型,启用-禁用-传输群集。 在这里,当发现完全不正确的簇时,我们还返回到阶段1。
- 自动检测Wikipedia文档和新闻的WikiClustTopic主题。
- 根据段落5的结果,使用k-means方法对新闻内的新闻进行聚类,以及未接收到新闻的新闻,并获得NewsClustTopic主题的聚类模型。 现在,我们有了一个主题模型,其中考虑了新闻的细节(以及有关爬虫工作质量的宝贵信息)。
- 手动清洁NewsClustTopic模型。
- 根据集成模型ClustTopic = WikiClustTopic + NewsClustTopic重新映射新闻主题。 基于此模型,确定新文档的主题。
地点
自动位置确定是搜索命名实体的任务的一种特殊情况。 这些位置的特征如下:
- 所有位置列表都不相同,因此不太适合。 我们构建了自己的混合系统,不仅考虑了层次结构(俄罗斯包括新西伯利亚地区),还考虑了基于以下因素的历史名称更改(例如,RSFSR成为俄罗斯):地名,Wikidata和其他开源。 但是,我们仍然必须使用Google Maps编写geotag转换器:)
- 有些位置包含几个词,例如Nizhny Novgorod,您需要能够收集它们。
- 位置与其他词语相似,尤其是那些以其名字命名的人的名字:基洛夫,朱可夫,弗拉基米尔。 这是同义的。 为了解决这个问题,我们在Wikipedia文章中收集了描述定居点的统计数据,在其中找到了地点名称,还尝试使用Open Corpora词典构建此类同音异义词的列表。
- 人类并没有极大地限制想象力,许多地方都被命名为相同的地方。 我们最喜欢的例子:位于哈萨克斯坦和新西伯利亚附近的俄罗斯的Karasuk。 这是位置类别中的同音异义词。 考虑到在此位置还找到其他位置,以及它们是同音异义词之一是父级还是子级,我们将对其进行解决。 这种启发式方法不是通用的,但效果很好。
日期
日期-与主题和位置相比,形式的体现。 我们使用正则表达式为它们创建了一个可扩展的解析器,不仅可以解析年月日,还可以解析各种更有趣的事物,例如“ 1941年冬末”,“十九世纪90年代”和“上个月”。 ”,同时考虑到文档的时代和基准日期,并尝试恢复丢失的年份。 关于日期,您需要知道并非所有日期都很好。 例如,关于第二次世界大战之文章的结尾可能是四十年后纪念馆的开幕,为了处理此类案件,您需要将文章划分为事件,但我们尚未这样做。 因此,我们仅考虑最重要的日期:从标题和第一段开始。
搜索引擎
搜索引擎是一个小发明,首先,它按需搜索文档,其次,以与查询相关的降序排列它们,也就是按降低的相关性排列。 为了计算相关性,我们使用许多参数,而不仅仅是琐碎的事情:
文档所属主题的程度。
位置文档的所有权程度(找到所选位置的次数以及在文档的哪个部分中找到)。
文档与日期匹配的程度(考虑到请求与文档日期之间的时间间隔的相交天数,以及相交处减去联合的天数)。
文件的长度。 长篇文章应该更高。
图片的存在。 每个人都喜欢图片,应该还有更多!
维基百科文章的类型。 我们可以将带有事件描述的文章分开,它们应该在示例中“弹出”。
文章来源。 新闻和自定义文章应高于Wikipedia。
作为搜索引擎,我们使用Apache Lucene。
履带式
搜寻器的任务是为蜘蛛收集物品。 就我们而言,这里还包括文本的主要清理以及文档文本模型的构建。 搜寻器值得另外发表一篇文章。
PS:我们欢迎您提供任何反馈意见,我们邀请您测试我们的项目-接收链接,写个人信息(我们无法在此处发布)。 将您的评论保留在文章下方,或者如果您要获得我们的服务,则可以通过反馈表在此处。