人们在Internet上搜索图片或视频时,通常会添加“优质”一词。 质量通常是指分辨率-用户希望图像更大,同时又要在现代计算机,智能手机或电视的屏幕上看起来不错。 但是,如果根本就没有优质的来源怎么办?
今天,我们将向哈勃的读者介绍如何借助神经网络实时提高视频的分辨率。 您还将学习解决这一问题的理论方法与实际方法有何不同。 如果您对技术细节不感兴趣,则可以安全地滚动查看该帖子-最后,您将找到我们工作的示例。

Internet上有很多质量低且分辨率低的视频内容。 可能是几十年前拍摄的电影,也可能是广播电视频道,由于各种原因,这些频道的质量都不佳。 当用户将此类视频拉伸到全屏时,图像变得模糊不清。 对于旧胶片,理想的解决方案是找到原始胶片,用现代设备扫描它并手动还原,但这并不总是可能的。 广播仍然更加复杂-需要实时处理。 在这方面,最可行的选择是使用计算机视觉技术来提高分辨率和清洁伪像。
在行业中,增加图片和视频而不损失质量的任务称为“超分辨率”。 关于该主题的文章很多,但是“战斗”应用程序的现实却变得更加复杂和有趣。 简要介绍我们自己的DeepHD技术必须解决的主要问题:
- 您需要能够还原原始视频(由于其分辨率和质量较低)所没有的细节,以“完成”它们。
- 超分辨率区域的解决方案可以还原细节,但它们不仅可以清晰,详细地显示视频中的对象,还可以使压缩伪像清晰可见,这会引起观众的不满。
- 收集训练样本存在一个问题-需要大量的配对,其中以低分辨率和高质量以及高清晰度同时显示同一视频。 实际上,通常没有质量差的内容对。
- 该解决方案应实时工作。
技术选择
近年来,神经网络的使用已在解决几乎所有的计算机视觉任务方面取得了巨大的成功,而且超分辨率的任务也不例外。 我们发现了基于GAN(生成对抗网络,生成竞争对手网络)的最有前途的解决方案。 它们使您可以获取高清的真实感图像,并通过缺少的细节来补充它们,例如在人的图像上绘制头发和睫毛。

在最简单的情况下,神经网络由两部分组成。 第一部分-生成器-拍摄输入图像并返回放大倍数。 第二部分-鉴别器-接收生成的图像和“真实”图像作为输入,并试图将其彼此区分开。
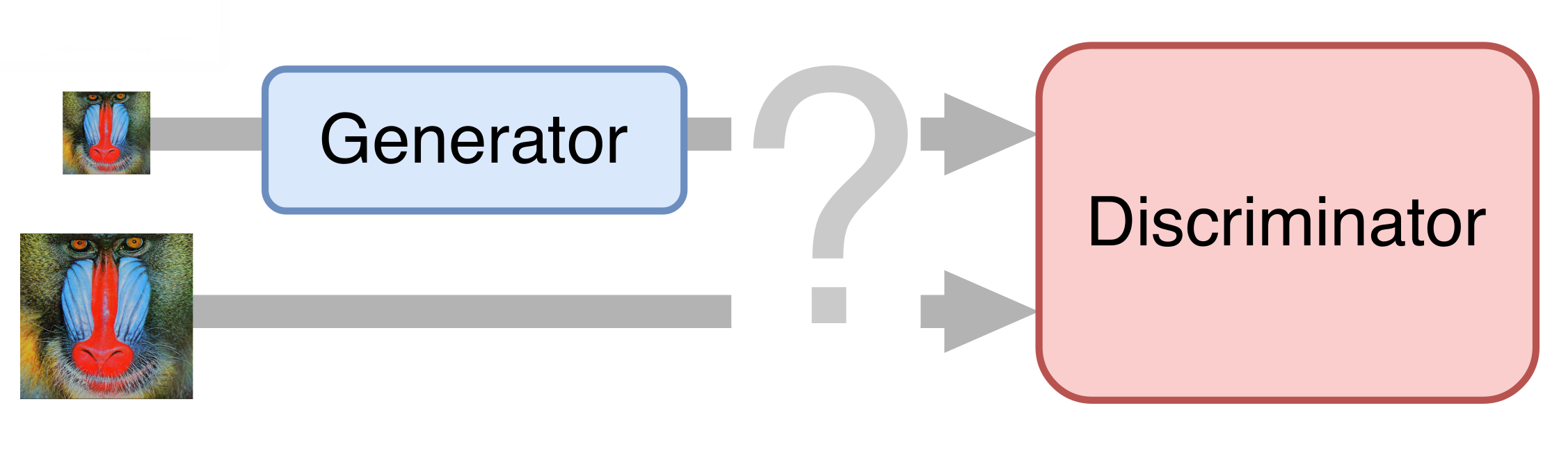
训练集准备
为了进行培训,我们收集了数十个UltraHD品质的剪辑。 首先,我们将它们降低为1080p的分辨率,从而获得参考示例。 然后,我们将这些视频减半,然后以不同的比特率压缩它们,以得到与真实视频类似的低质量内容。 我们将生成的视频分成帧并以训练神经网络的方式使用它们。
解块
当然,我们希望得到一个端到端的解决方案:训练神经网络从原始图像生成高分辨率视频和高质量图像。 但是,GAN变得非常反复无常,并不断尝试改进压缩伪像,而不是消除它们。 因此,我不得不将过程分为几个阶段。 首先是抑制视频压缩伪像,也称为解块。
一种释放方法的示例:

在此阶段,我们将生成的帧与原始帧之间的标准偏差最小化。 因此,尽管我们提高了图像的分辨率,但由于回归平均值,我们并未真正获得分辨率的提高:神经网络不知道图像中特定边界在哪个特定像素中通过,被迫对几种选择取平均值,从而得到模糊的结果。 我们在此阶段取得的主要成就是消除了视频压缩伪像,因此下一阶段的生成网络仅需要增加清晰度并添加缺少的小细节,纹理。 经过数百次实验,我们在性能和质量方面选择了最佳架构,这让人联想到
DRCN架构:
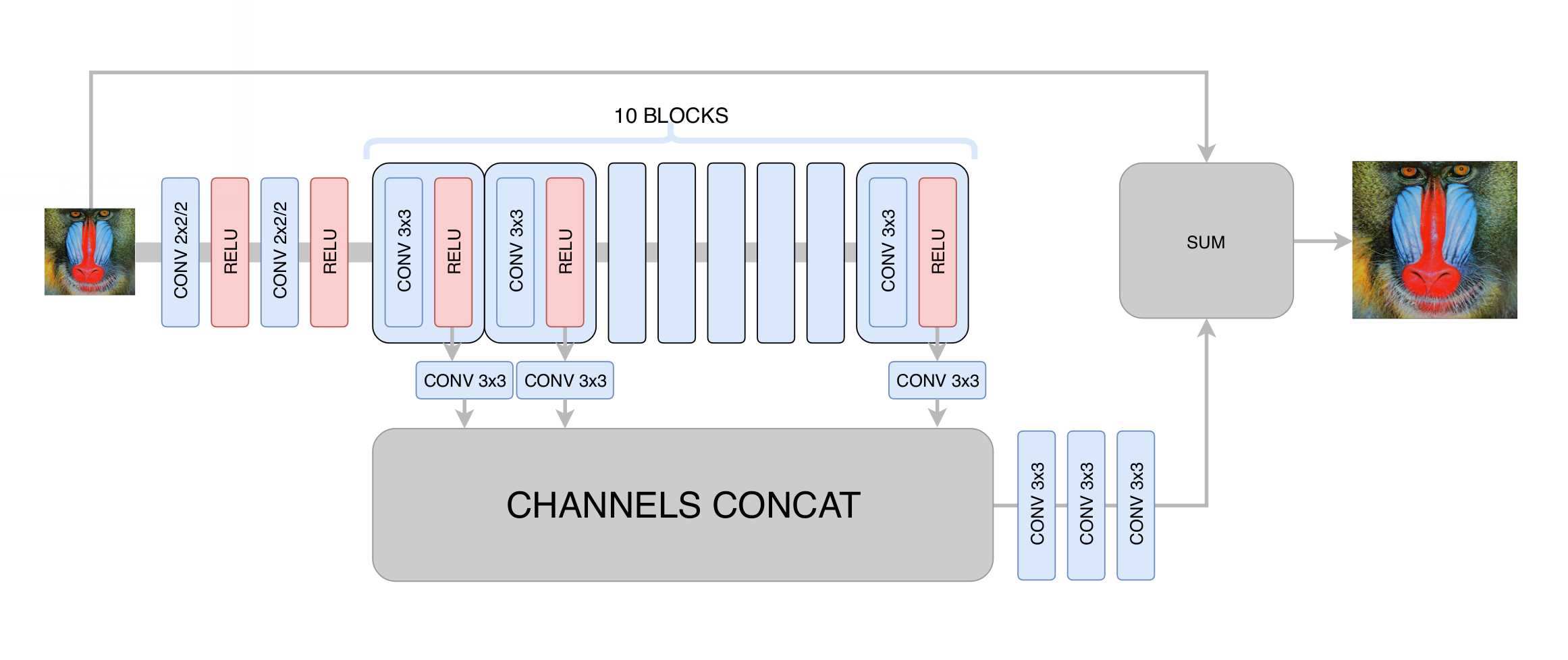
这种架构的主要思想是希望获得最深入的架构,同时又不会在训练中出现收敛问题。 一方面,每个随后的卷积层都提取输入图像中越来越复杂的特征,这使您可以确定图像中给定点处的对象类型,并恢复复杂且损坏严重的部分。 另一方面,神经网络图中任何一层到出口的距离仍然很小,这改善了神经网络的收敛性,并可以使用大量的层。
生成网络培训
我们以
SRGAN架构
为基础,以提高分辨率。 在训练竞争性网络之前,您需要预训练发电机-以与解块阶段相同的方式对其进行训练。 否则,在训练开始时,生成器将仅返回噪声,鉴别器将立即开始“获胜”-它将轻松学习将噪声与实际帧区分开,并且没有训练将起作用。

然后我们训练GAN,但有一些细微差别。 对我们而言,重要的是,生成器不仅可以创建逼真的帧,而且还可以存储其中的可用信息。 为此,我们将内容丢失功能添加到经典GAN架构中。 它代表在标准ImageNet数据集上训练的VGG19神经网络的几层。 这些层将图像转换为包含有关图像内容信息的特征图。 丢失功能使从生成的帧和原始帧获得的此类卡之间的距离最小化。 而且,当鉴别器尚未训练并提供无用的信息时,这种损失功能的存在使得有可能在训练的第一步中不破坏发生器。
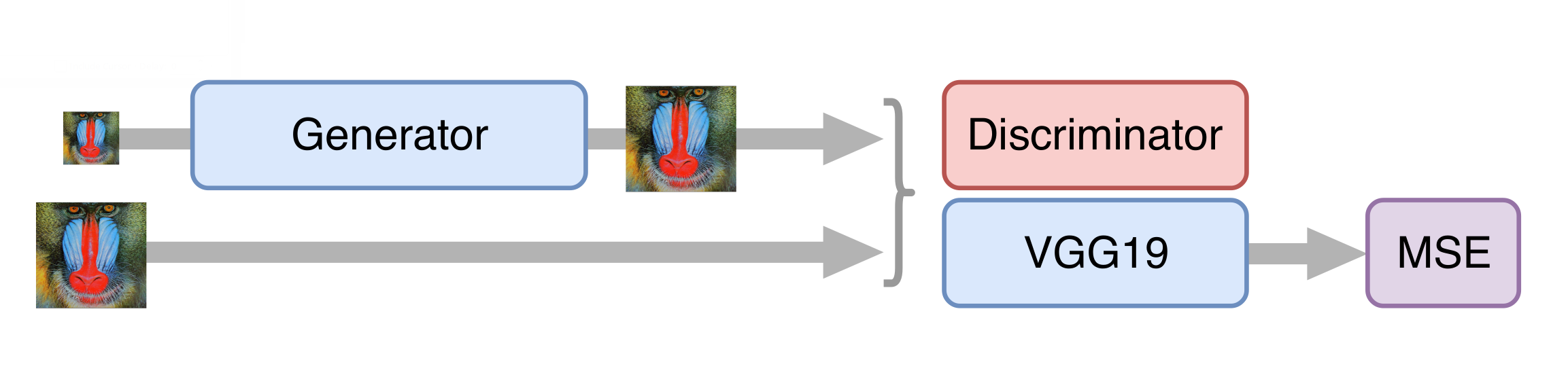
神经网络加速
一切进展顺利,经过一系列的实验,我们得到了一个很好的模型,该模型已经可以应用于老电影。 但是,处理流视频仍然太慢。 事实证明,在不显着降低最终模型质量的情况下,不可能简单地减少发电机。 然后,知识提炼方法对我们有所帮助。 此方法涉及训练较轻的模型,以便重复较重模型的结果。 我们拍摄了许多低质量的真实视频,并使用上一步获得的生成神经网络对其进行了处理,并训练了较亮的网络,以从相同的帧中获得相同的结果。 由于采用了这种技术,我们得到的网络在质量上不比原始网络差很多,但比它快十倍:要处理一个576p分辨率的电视频道,需要一张NVIDIA Tesla V100卡。
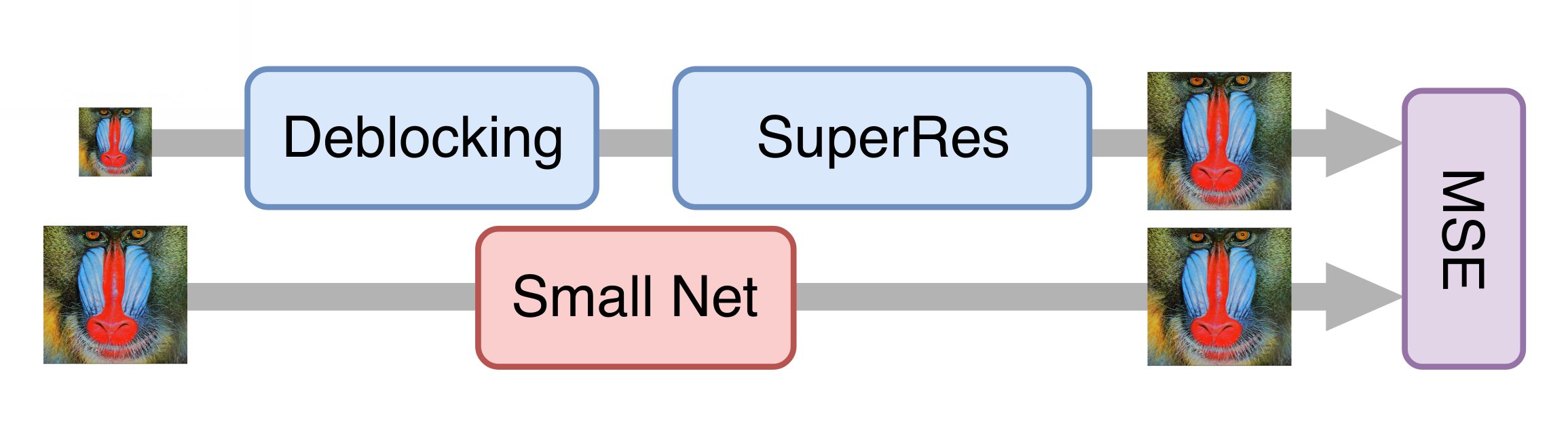
评估解决方案的质量
使用生成网络时,最困难的时刻也许是对生成模型的质量进行评估。 例如,当解决分类问题时,没有明确的误差函数。 取而代之的是,我们只知道判别器的准确性,这不能反映出我们感兴趣的生成器的质量(熟悉该领域的读者可能会建议使用
Wasserstein度量标准 ,但不幸的是,它给出了明显较差的结果)。
人们帮助我们解决了这个问题。 我们向用户显示了
Yandex.Tolok服务图像对的用户,其中一对是源图像,另一对是由神经网络处理的,或者两者都是由我们解决方案的不同版本处理的。 通过付费,用户可以从一对视频中选择更好的视频,因此即使在观看时很难看到变化,我们也具有统计学意义上的版本比较。 我们的最终模型在70%的案例中胜出,这是一个很大的数目,因为用户只需花几秒钟即可对几个视频进行评级。
有趣的结果是,DeepHD技术将576p分辨率的视频增加到720p,在60%的情况下优于相同的720p分辨率的原始视频。 处理不仅可以提高视频的分辨率,而且可以改善其视觉感知。
例子
春季,我们在KinoPoisk可以观看的几部老电影上测试了DeepHD技术:Mark Donskoy(1943)的“
Rainbow ”,Mikhail Kalatozov(1957)的“
Cranes Flying Flying ”,Joseph Kheifits(1958)的“
My Dear Man ”,“
男人的命运 ” Sergei Bondarchuk(1959),Andrei Tarkovsky(1962)的《
伊凡·童年 》,Rezo Chkheidze(1964)的《
士兵之父 》和Albert Mkrtchyan(1985)的《
我们的童年探戈 》。

如果您仔细查看细节,则处理前后版本之间的差异尤其明显:研究特写镜头中英雄的面部表情,考虑衣服的质地或织物图案。 可以弥补数字化的一些缺点:例如,消除面部的过度曝光或将更多可见的物体放置在阴影中。
后来,DeepHD技术开始用于提高Yandex.Air服务中
某些频道的广播质量。 通过
dHD标签可以轻松识别此类内容。
现在,
在Yandex上以提高的质量可以观看“雪之女王”,“不来梅镇的音乐家”,“金羚羊”和Soyuzmultfilm电影制片厂的其他热门动画片。 在视频中可以看到一些动态示例:
对于要求苛刻的观看者来说,差异将特别明显:图像变得更加清晰,树叶,雪花,丛林中夜空中的星星以及其他小细节更加清晰可见。
更多就是更多。
有用的链接
Kim Jiwon Kim,李政权,Kyoung Mu Lee用于图像超分辨率的深度递归卷积网络[
arXiv:1511.04491 ]。
克里斯蒂安·勒迪格(Christian Ledig)等。 使用生成对抗网络的逼真的单图像超分辨率[
arXiv:1609.04802 ]。
Mehdi SM Sajjadi,BernhardSchölkopf,Michael Hirsch EnhanceNet:通过自动纹理合成实现的单图像超分辨率[
arXiv:1612.07919 ]。