人们一直想教一台机器来了解一个人。 但是,直到现在,我们才更接近科幻电影的情节:我们可以要求爱丽丝调低音量,要求Google助手-订购出租车或Siri-设置警报。 在与人工智能建设有关的发展中,需要语言处理技术:在搜索引擎中,提取事实,评估文本的语调,机器翻译和对话。
我们将讨论最后两个领域:它们具有悠久的历史并对语言处理产生了重大影响。 此外,在与我们的课程《
AI Weekend》的演讲者
,计算机语言学家Anna Vlasova一起创建聊天机器人时,我们将处理处理自然语言的基本可能性。
这一切是如何开始的?
关于使用计算机处理自然语言的第一次讨论始于20世纪30年代,当时采用了Ayer的哲学推理方法-他提议通过经验检验将聪明的人与愚蠢的机器区分开。 1950年,哲学杂志《
心灵 》(
Mind)的艾伦·图灵(Alan Turing)提出了一项测试,法官必须确定与之交谈的人:人还是计算机。 使用该测试,为评估人工智能的工作设定了标准,而构建人工智能的可能性没有受到质疑。 该测试有很多局限性和缺点,但是它对聊天机器人的开发产生了重大影响。
成功应用语言处理的第一个领域是机器翻译。 1954年,乔治敦大学(Georgetown University)与IBM一起演示了一种从俄语到英语的机器翻译程序,该程序在250个单词的词典和6条语法规则的基础上工作。 该程序远非真正所谓的机器翻译,它在一次演示中翻译了49个预选的要约。 直到60年代中期,为创建功能齐全的翻译程序进行了许多尝试,但是1966年,语言自动处理咨询委员会
(ALPAC)宣布机器翻译是徒劳的方向。 国家补贴已经停止了一段时间,公众对机器翻译的兴趣下降了,但是研究并没有就此停止。

在尝试教计算机翻译文本的尝试中,科学家和整个大学都在考虑创建一个可以模仿人类语音行为的机器人。 聊天机器人的第一个成功实现是由约瑟夫·魏岑鲍姆(Joseph Weizenbaum)于1966年编写的ELIZA虚拟对话者。 Eliza模仿了心理治疗师的行为,从对话者的短语中提取了重要的词语并提出了反问题。 我们可以假设这是第一个基于规则的聊天机器人(基于规则的机器人),并且为整个此类系统奠定了基础。 诸如Cleverbot,WeChat Xiaoice,Eugene Goostman等访问者在2014年正式通过了图灵测试-甚至如果没有Eliza,Siri,Jarvis和Alexa也不会出现。
1968年,Terry Grapes在LISP中开发了SHRDLU程序。 她根据命令移动了简单的对象:圆锥体,立方体,球,并且可以支持上下文-她理解需要移动的元素(如果前面已经提到过)。 聊天机器人开发的下一步是ALICE程序,Richard Wallace为此开发了一种特殊的标记语言-AIML
(英语人工智能标记语言) 。 然后,在1995年,聊天机器人的期望被高估了:他们认为驴友会比人更聪明。 当然,聊天机器人并没有成功地变得更聪明,并且一段时间以来,聊天机器人的业务一直令人失望,并且投资者长期以来一直回避虚拟助手这一主题。
语言很重要
如今,聊天机器人仍在一套规则和行为情景的基础上工作,但是,自然语言是模糊且模棱两可的,一个思想可以有多种表达方式,因此,对话系统的商业成功取决于解决语言处理问题。 必须教会机器清楚地分类所有传入的问题,并清楚地解释它们。
所有语言的排列方式都不同,这对于解析非常重要。 从形态组成的角度来看,单词的重要元素可以按顺序连接词根,例如在突厥语中,也可以破坏词根,例如在阿拉伯语和希伯来语中。 从语法的角度来看,某些语言允许词组中单词的自由顺序,而另一些则组织得更为严格。 在经典系统中,单词顺序起着至关重要的作用。 对于现代的NLP统计方法,它不具有这样的值,因为处理不是在单词级别而是整个句子级别进行。
与多语言交流的发展有关,聊天机器人的发展还面临其他困难。 现在人们经常不使用其母语进行交流,他们错误地使用了单词。 例如,从词汇的角度来看,在“我两天前已经发货,但货物没有来”这一短语中,我们应该谈论的是诸如货物之类的实物的交付,而不是电子货币交易,这是由不说话的人用这些词来描述的。用母语。 但是在实际交流中,一个人会正确理解对话者,并且聊天机器人可能会遇到问题。 在某些主题(例如投资,银行或IT)中,人们经常切换到其他语言。 但是,聊天机器人不太可能理解危险所在,因为它很可能是用一种语言训练的。
成功案例:机器翻译
在语音助手出现和聊天机器人广泛传播之前,机器翻译是最需要的智力任务,需要处理自然语言。 关于神经网络和深度学习的讨论可以追溯到90年代,第一台Mark-1神经计算机于1958年全面问世。 但是由于计算机性能低下和缺乏足够的语言语料库,在任何地方都无法使用它们。 只有大型研究团队才能负担得起神经网络领域的研究。
20世纪中叶的机器翻译人员远非Google Translate和Yandex.Translator,但随着每一种新的翻译思想方法的出现,这种思想甚至在今天都以一种或另一种形式得到应用。
1970年基于规则的机器翻译
(RBMT)是教机器翻译的首次尝试。 翻译是在五年级的时候用字典获得的,但是以一种或另一种形式,机器翻译或聊天机器人的规则仍在使用。
1984年基于示例的机器翻译
(EBMT)甚至可以翻译彼此完全不同的语言,在这种情况下,设置任何规则都没有用。 所有现代机器翻译和聊天机器人都使用现成的示例和模式。
1990年。互联网发展时代的统计机器翻译
(英语SMT)使不仅可以使用现成的语言公司,甚至还可以使用书籍和自由翻译的文章。 更多可用数据提高了翻译质量。 统计方法现已在语言处理中得到积极使用。
NLP服务中的神经网络
随着自然语言处理的发展,经典的统计方法和许多规则解决了许多问题,但这并没有解决语言的模糊性和歧义性的问题。 如果我们在没有任何上下文的情况下说“鞠躬”,那么即使是在世的对话者也不太可能理解所讲的内容。 文本中单词的语义由相邻单词决定。 但是,如果机器只理解数字表示,该如何向机器解释呢? 从而诞生了统计文本分析方法
word2vec (英语单词到矢量) 。
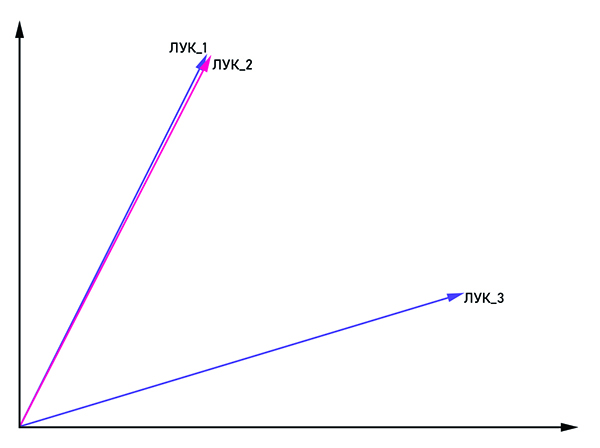 向量bow_1和bow_2是平行的,因此这是一个单词,而bow_3是同音异义词。
向量bow_1和bow_2是平行的,因此这是一个单词,而bow_3是同音异义词。这个名字的名字很明显:以带有坐标(x
1 ,x
2 ,...,x
n )的矢量形式呈现单词。 为了消除同音异义,将相同的单词与标签结合在一起:“ bow_1”,“ bow_2”,依此类推。 如果向量bow_n和bow_m平行,则可以将它们视为一个单词。 否则,这些词是同音异义词。 在输出中,每个单词在多维空间中都有其自己的矢量表示(矢量空间的维数可以从50到1000不等)。

问题仍然是用于训练条件聊天机器人的神经网络类型。 一致性在人类语音中很重要:我们根据上一句话甚至段落中提到的内容得出结论并做出决定。 递归神经网络(RNN)非常适合这些条件,但是,随着文本连接部分之间的距离增加,RNN的大小需要增加,从而导致信息处理质量下降。 该问题由LSTM网络
(英文长短期记忆)解决 。 它具有一项重要功能-电池状态,可以保持恒定,或者在必要时进行更改。 因此,链中的信息不会丢失,这对于处理自然语言至关重要。
如今,有大量用于处理自然语言的库。 如果我们谈论通常用于数据分析的Python语言,那么它们就是
NLTK和
Spacy 。 大型公司也参与开发NLP库,例如Intel的
NLP Architect或Facebook和Uber的研究人员的
PyTorch 。 尽管大型公司对语言处理的神经网络方法有极大的兴趣,但连贯的对话主要是基于经典方法建立的,而神经网络在解决语音预处理和分类问题中起着辅助作用。
NLP如何在业务中使用?
自然语言处理最明显的应用包括机器翻译,聊天机器人和语音助手-我们每天都会遇到这种情况。 大多数呼叫中心员工可以由虚拟助手代替,因为大约80%的客户对银行的请求都与相当典型的问题有关。 聊天机器人还将冷静地应对候选人的初次面试,并在“现场”会议上记录下来。 奇怪的是,法学是一个相当准确的方向,因此即使在这里聊天机器人也可以成为成功的顾问。

b2c方向并不是唯一可以使用聊天机器人的方向。 在大型公司中,员工轮换非常活跃,因此每个人都必须帮助适应新的环境。 由于新员工的问题相当典型,因此整个过程很容易实现自动化。 无需找人来解释如何为打印机加油,就任何问题与之联系。 该公司的内部聊天机器人可以很好地做到这一点。
使用NLP,您可以通过分析Internet上的评论来准确衡量用户对新产品的满意度。 如果程序将评论视为否定的,则该报告将自动发送到相关部门,那里的人们已经在与之合作。
语言处理的可能性只会扩大,并且随之扩大其应用范围。 如果您公司的呼叫中心有40个人,则值得考虑:也许最好是由一群将为您组装一个聊天机器人的程序员来代替他们?
您可以在我们的
AI Weekend课程中进一步了解语言处理的可能性,Anna Vlasova将在人工智能主题的框架中详细讨论聊天机器人。