这是当前系列文章中有关如何避免为各种实体引入服务的简短说明。 晚餐时一次有趣的谈话引发了我决定写下的想法。
阿姆达尔定律
1967年,Gene Amdahl反对并行计算。 他认为生产力的增长是有限的,因为只有部分任务可以并行化。 其余“顺序部分”的大小在不同任务中有所不同,但始终存在。 这一论点被称为阿姆达尔定律。
如果根据分配给它的并行处理器数来构建任务“加速”图,您将看到以下内容:
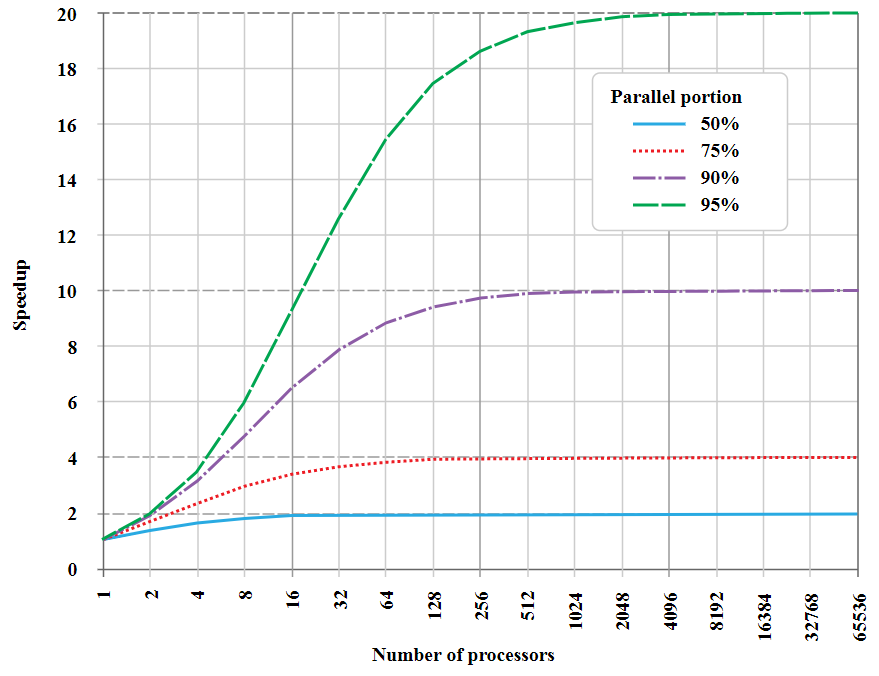 这是无法并行化的片段(“顺序部分”)的渐近图,因此最大加速度有上限
这是无法并行化的片段(“顺序部分”)的渐近图,因此最大加速度有上限从Amdal到USL
关于阿姆达尔定律的有趣之处在于,在1969年,实际上很少有多处理器系统。 该公式基于另一原理:如果任务中的顺序部分等于零,则这不是一个任务,而是多个任务。
尼尔·冈瑟(Neil Gunther)在对许多机器的性能测量结果进行观察的基础上扩展了阿姆达尔定律,并得出了通用可扩展性定律(USL)。 它使用两个参数:一个用于“竞争”(与顺序部分相似),第二个用于“不一致”(不连贯)。 不一致与恢复一致性所花费的时间有关,也就是说,这是不同处理器世界的总体视图。
在一个CPU中,由于缓存而导致协商开销。 当一个内核修改高速缓存行时,它告诉其他内核从高速缓存中检索该行。 如果每个人都需要同一行,他们会花时间从主内存中加载它。 (这是一个稍微简化的描述……但是用更精确的措词,仍然存在谈判的成本)。
由于匹配算法和保存数据序列,所有数据库节点都会产生协调成本。 在更改数据时(例如在事务数据库中)或在最终商定的存储库中读取数据时,应支付罚款。
USL效应
如果您根据处理器数量构建USL图表,则会出现一条绿线:
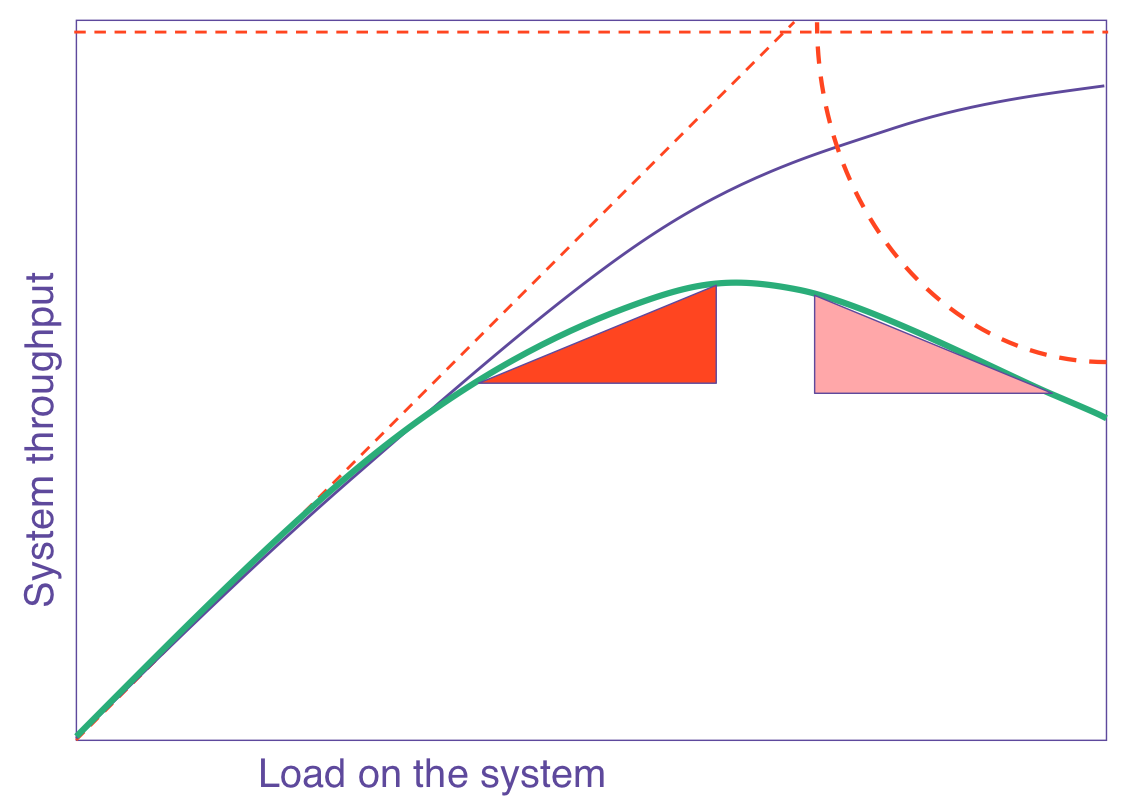 紫色线表示阿姆达尔定律将预测
紫色线表示阿姆达尔定律将预测请注意,绿线达到峰值,然后下降。 这意味着在一定数量的节点上可以发挥最大性能。
添加更多处理器-并且会降低性能 。 我在真实的压力测试中看到了这一点。
人们通常希望增加处理器数量并提高生产率。 有两种方法可以做到这一点:
- 减少顺序部分
- 减少审批成本
人类群体中的USL?
让我们尝试类比。 如果计算的“任务”是一个项目,那么我们可以将项目中的人数表示为执行工作的“处理器”的数量。
在这种情况下,顺序部分是一件只能逐步,逐步地完成的工作。 这可能是以后文章的主题,但是现在我们对顺序部分的本质不感兴趣。
我们似乎看到与和解费用有直接的类比。 无论团队成员花多少时间来恢复对世界的共同看法,都存在协调成本。
对于一个房间中的五个人来说,这些成本是最小的。 每周大约一次在黑板上用记号笔画五分钟。
对于在多个时区的大型团队,罚款可以增加并正式化。 文档和演练。 团队介绍等。
在某些体系结构中,对帐不是那么重要。 想象一下,一个由三大洲的员工组成的团队,但是每个团队都在一项服务上工作,该服务使用严格定义的格式的数据并创建严格定义的格式的数据。 他们不需要有关流程更改的一致性,但是需要有关格式更改的一致性。
有时,工具和语言可以改变对帐的成本。 支持静态类型的观点之一是,它有助于在团队中进行交互。 从本质上讲,代码中的类型是一种转换世界模型中的更改的机制。 在动态类型语言中,我们要么需要辅助构件(单元测试或聊天消息),要么需要创建边界,某些部门很少恢复与其他部门的一致性。
所有这些方法都旨在降低协调成本。 回想一下,过度缩放会导致吞吐量下降。 因此,如果您的协调成本高昂且人员过多,那么整个团队的工作速度就会变慢。 我看到了一些团队,他们似乎可以裁减一半人,工作速度快两倍。 现在,USL和对帐费用有助于了解为什么会发生这种情况-不仅仅是清除垃圾。 它是关于减少交换心理模型的开销。
在
《恐惧循环》中,我提到了一些代码库,在
这些代码库中,开发人员知道需要进行大规模更改,但担心会意外造成伤害。 这意味着过度膨胀的团队
尚未达成共识。 损失后似乎很难调和。 这意味着不可能忽略协调成本。
USL和微服务
我认为,USL解释了对微服务的兴趣。 通过将大型系统划分为彼此独立部署的越来越小的部分,可以减少工作的顺序部分。 在具有大量参与者的大型系统中,顺序部分取决于集成,测试和部署的工作量。 微服务的优势在于它们不需要集成工作,集成测试或同步部署中的延迟。
但是匹配的成本意味着您可能无法获得理想的加速度。 此处的类推也许有些紧张,但我认为可以将微服务之间的接口更改视为需要团队之间的协调。 如果这太多了,那么您将无法从微服务中获得期望的收益。
怎么办呢?
我的建议:查看所使用的体系结构,语言,工具和团队。 想想人们在改变世界的系统模型时在和解上浪费的时间。
寻找
差距 。 系统内部边界之间的差距和团队内部的分歧。
使用环境来传达更改,以便对帐过程适用于每个人,而不是每个人。
查看您团队的沟通情况。 需要多少时间和精力来确保一致性? 也许进行一些小的更改并减少对它的需要?