机器学习任务的一个重要特征是,使用不同的方法可以获得同样好的结果。 这使ML竞赛令人振奋:即使拥有明显胜于对手的其他能力,您仍然可以赢。 Tensorborne和Neurobotics团队赢得DeepHack黑客马拉松的机会几乎相等,最终获得前两名。 在
Yandex培训中,两个团队的代表发表了一份详尽的报告。 在解码中,您将找到针对新手竞争对手的解决方案和技巧的详细分析。
当然,请参加骇客马拉松假期。 当您参加每周一次的黑客马拉松并同时工作时,那就不好了。 您已经工作了一点,到了晚上7点,坐下来用Keras的TensorFlow编译Docker,以便所有这些工作都从您甚至无法访问的远程服务器上开始。 在两个晚上的某个地方,您会发现宣泄,它对您有效-没有Docker,没有一切,因为您知道这是可能的。
维塔利·达维多夫(Vitaly Davydov):
大家好! 我们本应该有两个报告,但是我们决定将它们合并成一个大报告,因为我们正在谈论DeepHack竞赛中的第一名和第二名。 我们代表两个团队。 我们的Tensorborne团队获得了第二名,而Gregory Neurobotics团队则获得了第一名。

该报告将包括三个主要部分。 在介绍中,我将讨论DeepHack的历史,它是什么,指标是什么,等等。接下来,这些人将讨论解决方案,问题,示例等。
在谈论DeepHack之前,应该指出的是,它是另一项非常大型的全球竞争ConvAI2的一小部分,该竞争于去年推出了Facebook。 今年是第二次迭代。 在某个时候,Facebook赞助了莫斯科物理技术研究所,DeepHack竞赛是在PhysTech实验室的基础上发起的。

了解有关ConvAI本身的更多信息。 他想解决什么问题? 他专门研究交互式系统。 对话系统的问题在于,没有一个评估工具(一种评估工具)来了解对话的质量。 这件事在人与人之间是非常主观的:某人可能喜欢对话,某人可能不喜欢。 ConvAI的总体全局任务是提出一个用于评估对话框的通用统一指标,该指标尚不可用。 奖金-20,000美元用于AWS Mechanical Turk。 这些不是贷给亚马逊,而是贷给Mechanical Turk,实际上是Yandex.Tolki的类似物。 这是一项众包服务,可让您对数据进行标记。
建立在ConvAI上的任务是构建一个聊天机器人,您可以与它进行某种对话。 他们选择了三个指标:困惑度,点击数1和F1。 接下来,我将显示提交时的表格。
他们试图进行评估的过程经历了三个阶段。 第一阶段是自动指标,然后是AWS Mechanical Turk评估,然后是与志愿者的实时聊天。
由于ConvAI由Facebook赞助,因此他正在积极推广自己的图书馆以创建ParlAI对话系统。 这很复杂,但是我认为所有参与者都使用了这个库。 我们已经处理了一段时间,例如,它与Python 3.6不兼容,并且存在很多问题。
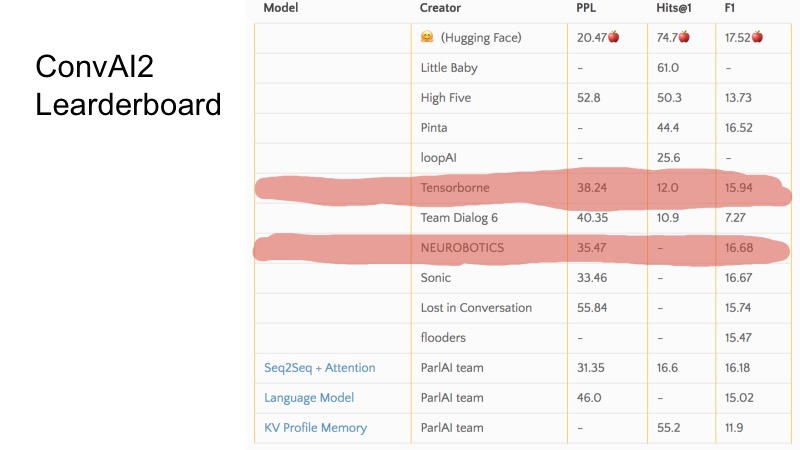
在这几行中,您可以看到我们在提交时所担任的职位。 总的来说,ConvAI的组织方式很奇怪,因为它涉及三个指标,目前尚不清楚该表的排名如何。 可以看出,对于某些指标,有些团队较高,而有些较低。 整个ConvAI的组织有点奇怪。
但是有三个基本基准。 要获得DeepHack的参赛资格,必须打破这一底线,而排名前10位的最佳队伍进入决赛。 秘密地说,我只能说有8个团队发送了决定,每个人都进入了决赛。 这不是很困难。

DeepHack的任务更加易于理解和直接。 我们不得不再次构建一个发声机器人,但是它将模仿某些给定的个性。 就是说,在入口处给机器人一个人的描述,在与他的对话中他不得不将其揭露。 该奖项非常有趣-今年秋天的NIPS之旅得到了全额赞助。
与ConvAI不同,该指标已经不同。 有两个指标,总指标在这两个指标之间加权。 第一个指标是整体质量,评估机器人的响应程度,与机器人进行交流的有趣程度,是否编写垃圾等。第二个指标是角色扮演,即0或1。这意味着机器人是否进入了对他的描述。 与漫游器通信的人看不到该描述。 评估是在Telegram中进行的,也就是说,只有一个Telegram机器人,当用户开始与他通信时,老实说,他从所有提交的内容中都找到了一个随机机器人。 显然,Yandex和MIPT在那里涌入了一些流量,据我所记得,大约有1万个对话。
我已经说过资格赛了。 决赛是全日制。 它是在莫斯科物理技术研究所工作的7天中进行的,提供了一个集群,一个地方,我们坐在那里工作。 实际上每天都在进行评估,并以此方式计算最终得分(即机器人的最终评分)。 比赛从星期一开始,第一次提交于星期二,第二天进行评估。 您在星期二发布的解决方案在星期三以1.5的权重进行了评估。 您在星期三发送的邮件-权重为1.4等

关于Facebook提供的用于训练的数据集。 它被称为Persona-Chat,是对两种个性和一组对话的描述。 这里有第一人称和第二人称的描述。 在描述对话的过程中,他们试图互相展示。 那就是已经给出的全部。 但是,与往常一样,在比赛中也不禁止使用其他第三方数据集。
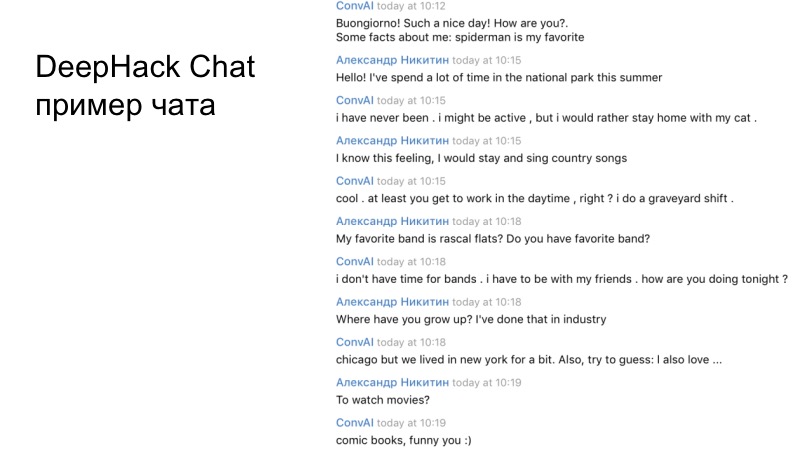
我们团队对话的一个例子。 如果您仔细阅读,很明显,最终的bot可以正常运行,并且可以正确回答。
格雷戈里将谈论第一名。
格里高里·拉什科夫(Grigory Rashkov):
-我想谈谈我们参加比赛的经验,我们的策略和决定。

首先,竞赛的特点是持续时间长,我们没有像普通黑客马拉松那样有两天,而是五天,我们可以做出很多决定。

非常主观的评估,因为评估标准的人完全不同,特别是黑客马拉松的组织者Mikhail Bubtsev说,如果他什至猜到了他在说什么配置文件,但该机器人在某个时候与他的配置文件相抵触,他回答的问题就不是这样,按他的说法,即使他知道这是关于什么的,他还是选择了不同的个人资料。
第三是缺乏验证。 参加者不能做出太大的改变,并立即收到反馈。
与所有恐怖电影一样,我们的团队从一开始就决定分手。 第一组参与基于Wasserstein GAN的主要解决方案,第二组参与bot,即基于基准的bot管理面板。 因为我们必须在第一天和第二天发送一些东西。

简要介绍一下基线:Seq2Seq加注意,它略微适合此特定任务。 到底如何 将短语发送到输入,从GloVe进行嵌入,但随后进一步考虑将每个短语作为加权嵌入的表示形式。 根据单词的倒频选择权重。 一个单词遇到的次数越少,它带来的分量就越大。

这对于反映这些特征的独特性是必要的。 一切都去了一个集合,一个矩阵,在这个集合和一个隐藏状态的基础上构建了一个掩码,然后将该掩码叠加在集合上,获得了上下文,然后通过非线性将其连接到了解码器的输入端。

对于第一天,我们还没有写出决定,我们不得不发送一些东西,因此我们根据基准编写了一个代理,但是将任务设置为以某种方式从众多代理中脱颖而出。 为此,我们使用了简单的启发式方法,我们的机器人是第一个开始对话的人,他在这句话中使用了微笑。 而且有效。
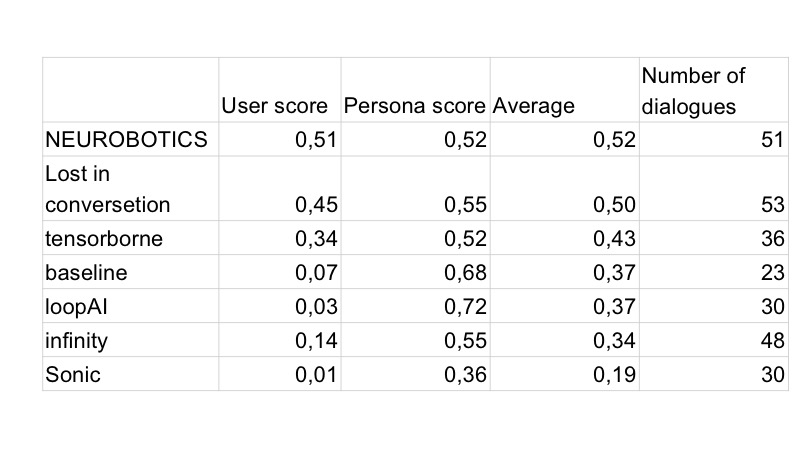
自然地,第二天,所有机器人都首先被制造出来,并且都有表情符号。 第二天,维拉巴乔居民继续与GAN合作,维拉里博居民尝试了其他启发式方法。
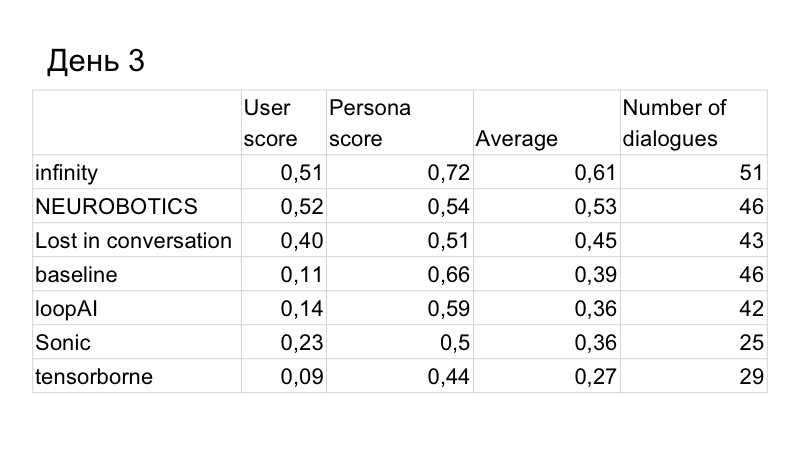
结果,对话质量的得分略有提高,但我们被这个人超越了。 这些是第三天的结果,只剩两天了。 我们了解到,我们没有足够的时间来编写GAN并对其进行正常测试,因为它已经研究了很长时间,非常辛苦,因此我们必须选择许多超参数。 因此,我们决定切换到基线,因为它运行良好。

我们的任务是改善对用户个人资料的识别。 我们提出了这样一种启发。 怎么了 用户愉快地与机器人聊天,询问他从事什么样的工作,爱好,驾驶哪种汽车,因此机器人的回答都很好,因为机器人通常反应良好。 结果,在对话结束时,用户看到了两个与对话中的内容无关的配置文件,仅仅是因为在那里显示了其他内容,而不是用户要求的内容。 因此,我们认为有必要以某种方式从配置文件中提供信息。
如何以最合乎逻辑的方式做到这一点? 如果一个人有任何利益,他可能会谈论它们,寻找共同的利益。 因此,我们决定该漫游器会在某些时候根据其个人资料提出问题。 产生了一个有趣的效果,即仅根据G的语言规则编写的生成器使用了配置文件中的一些事实A,因此,将G(A)输入到对话中,所有这些都发送到了bot的内存中,并且下次模型生成信息时,从简介和对话开始,也就是说,更有可能说出与简介相关的内容。
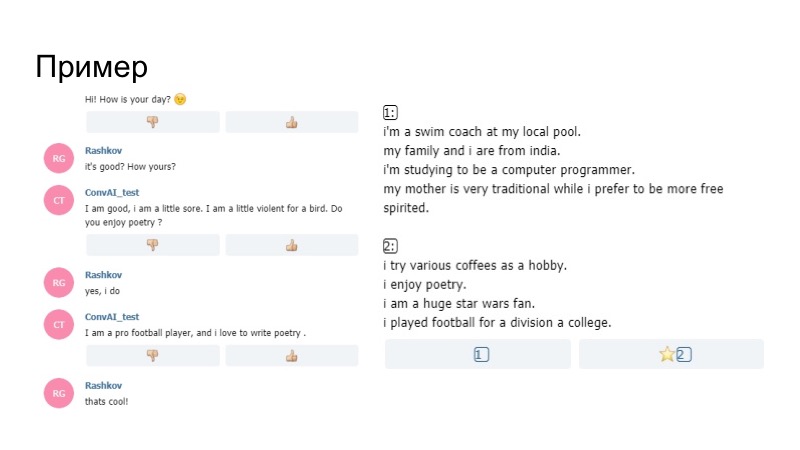
在现实中看起来像什么? 简介中的漫游器说他对诗歌很满意,然后在谈话中他问我是否喜欢诗歌。 我说是的,在他的模型上,而不是我们根据规则构建的生成器上,我说他喜欢写诗。 因此,该机器人专注于其配置文件,并且可以正常工作。

我们再次回到了第一名。 最后一天仍然存在。 我们注意到,尽管如此,我们作为对话正在失败。

我们利用了更多的解决方案。 首先,他们使用释义,分析了其他人说的话,因为组织者布置了该数据库,并注意到许多人与该机器人进行通信并不完全正确。
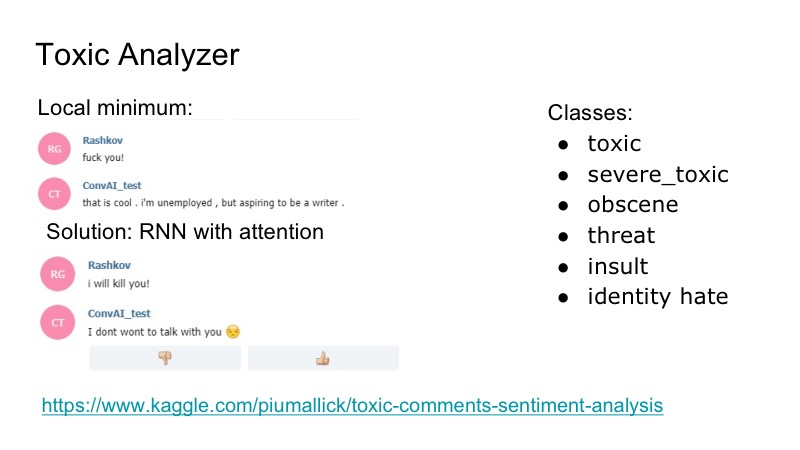
该机器人在本地有一个有趣的最低要求:他对任何侮辱的反应都很好,他对此表示同意,并且为了解决此问题,我们决定使用Kaggle竞争产品进行有毒评论分析器,我们编写了一个非常简单的分类器,也引起了RNN的注意。 在该数据集中,存在以下重叠的类:侮辱,威胁...我们决定不单独研究模型,由谁发言,因为遇到了这样的问题,但这种问题并不常见。 因此,我们只是写了一些笑话,该僵尸程序回答了,每个人都很高兴。

此外,我们使用释义来丰富我们的机器人的语音。 这也不是很困难,我们用同义词替换了短语中的单词,查看了短语中生成的n-gram,这样它们与最初的n-gram并没有太大的区别,然后我们选择了最适合出现概率最大的短语的组合。
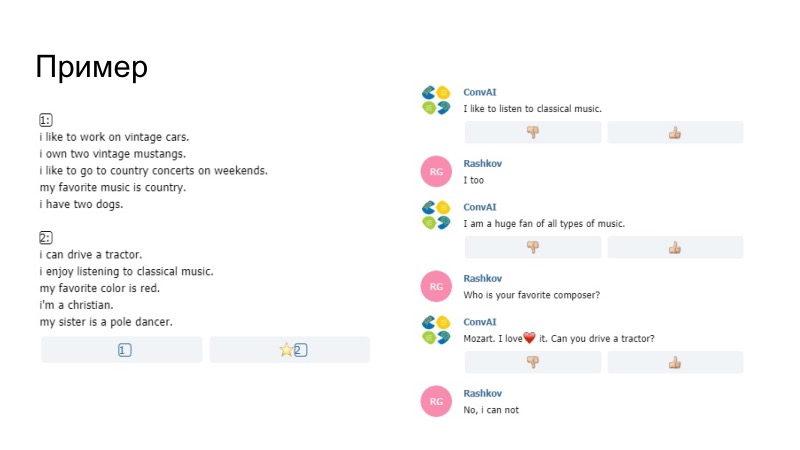
作为发生情况的一个例子,该机器人在这里说喜欢听音乐,在个人资料中说喜欢,已经被我们喜欢取代了。 我们不确定是由模型本身还是由Paraphraser生成的,但是事情已经过去了。 另一个说法是不可能仅从概要文件发送数据。 比较五角星。 如果五角星形图与您的评论和个人资料相符,则仅此短语未通过,组织者对其进行了整理。 此外,除其他外,我们添加了一个笑脸字典。

第二个例子,我们充满了微笑。 然后是启发式,当机器人对您的行为做出反应时,您很久没有写了。 Paraphraser也在这里工作,并取得了不错的成绩。

对话的质量是最好的,扮演角色的质量也是。
我们试图使模型生成一组选项,然后将它们与配置文件进行比较。 但是在我看来,在这种情况下,机器人的运行情况更糟,我们无法进行验证,只能进行两三个对话的主观评估。 因此,他们决定不放置此类内容,因为该配置文件已广为人知。
然后,我们编写了反问题的解决方案,即第二个模型,该模型从对话框中选择了所需的轮廓。 我们计划最初将其用于培训,以便从中读取损失函数并将其进一步分布到网格中。 但这可能会使说话者本身恶化,因此他们决定不这样说。 我们还考虑将这种东西用于机器人的行为,但我们没有时间测试所有东西,因此决定拒绝该东西。 此外,我们决定根据该短语的情感色彩来放置表情符号,编写了一个模型,但没有找到合适的数据集,所使用的表情符号与此差不多。

我们的团队
即使您希望的主模型无法编写它或导致不良结果,也不要立即放弃,您仍然需要尝试一些简单的事情,这很自然。 第二件事,有时候值得一看,您的模型缺少什么,思考一下特定的任务,分解它们并解决特定的问题领域,这就是我们所做的。 谢谢您的关注。
谢尔盖·科列斯尼科夫(Sergey Kolesnikov):
-我叫Sergey Kolesnikov,我代表Tensorborne的决定。

我们想出了一个漂亮的名字,参加了比赛,然后想出了很多不同的作品来发表两篇文章,但没有赢得黑客马拉松。 因此,它将被称为:“如何不赢得黑客马拉松,但仍然发表该死的两篇文章。” 院长先生
我们参加比赛的特点超出了我们的动机。 由于评估是每天进行的,因此包装也必须每天制造,最终的奖励是按照折扣法确定的,就像我们在RL中一样。 所有这些都变成了这样一个事实,我们每天必须至少发送一些内容才能正常工作,并且我们至少得到某种分数。 结果,它确实变成了您想要的-您不想要,但是您必须划船。
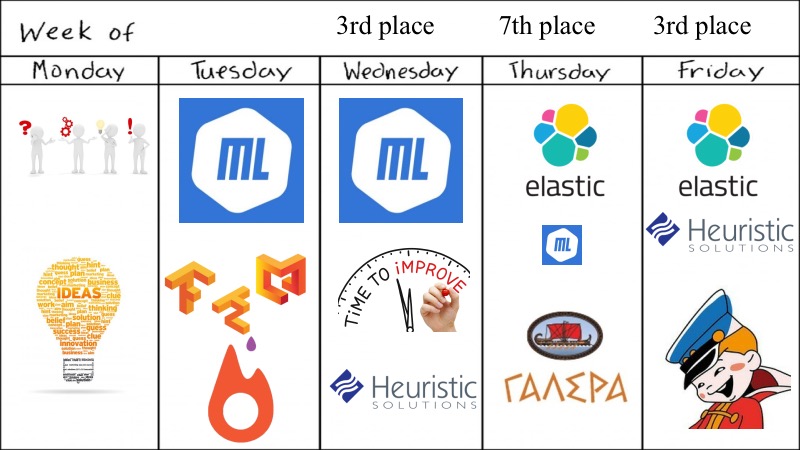
我们有什么? 预览整周。
尽管黑客马拉松说他是每周一次,但一切都在四天内决定,这似乎不足以完成ConvAI的任务。
最初,我们有五个人,都是Fiztekh左右的优秀大学毕业生,所以星期一我们来了,提出了很多建议,可以尝试的想法以及可以尝试的深度学习模型。 没错,我们没有试验GAN,因为我们已经对它们进行了文本试验,但是这没有用,所以我们采取了一些简单的方法,此外,竞赛非常相似,并且有预训练模型。 在星期二,我们甚至能够进行深度学习,ML尽可能在我们的身边,我们推出了具有GPU支持的出色docker,以及Tensorflow和Keras的其他功能,为此我们需要单独授予勋章,因为这并不那么琐碎如我所愿。
根据星期二的结果,它们是有希望的,因此我们决定通过小的启发式算法等对ML进行稍微改进,但以第七名失败。 但是由于我们的队友,有人找到了ElasticSearch并进行了尝试。 有一个非常尴尬的时刻,ElasticSearch可以正常工作,而DL模型和ML等健壮性稍差一些。 比赛快结束了。 正如前一位发言者所指出的那样,我们决定沿可行的方向划桨。 我们选择了ElasticSearch,采用小的启发式方法,认为足够好,而且确实足够好,因为我们获得了第二名。
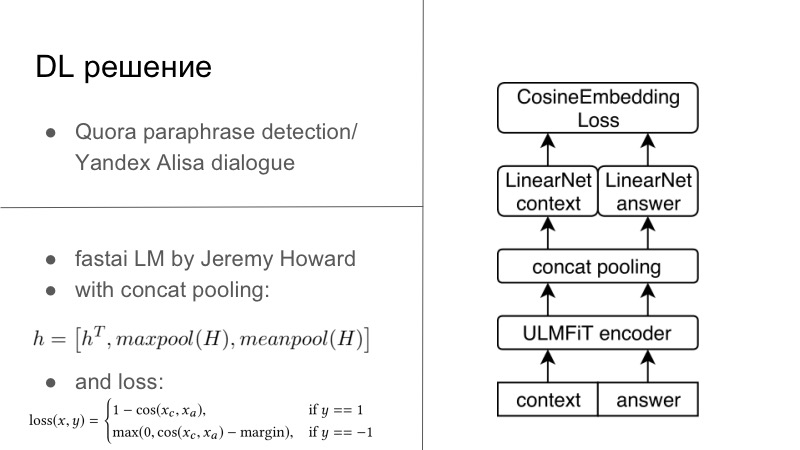
更多细节。 实际上,有几种DL解决方案。 第一个DL解决方案非常简单。 谁记得,在去年或去年的前一年,举行了Quora复述检测竞赛,而今年Yandex为Alice举办了一场竞赛,以建立对话等等。 您可能会注意到那里的任务非常接近。 首先,有必要说出这两个短语是否是释义,第二,有必要继续对话。 我们认为,由于我们正在开发对话系统,所以我们也要继续进行良好的对话。 而且效果很好,与Quora的对话非常个人化。
基本上,所有这些看起来都像我们有一些编码器,通常我们都在常规RNN上进行训练,最好是在注意和其他方面进行LSTM训练。 然后,我们通常使用下面幻灯片中显示的Cosaine嵌入损失,或使用Tripler Loss类型的另一种嵌入损失,或者嵌入其他解释或对特定对话的响应的其他东西,而不是解释延迟,等等。 这是第一个解决方案,它在Keras的Tensorflow上,已经准备好,我们尝试过,而且还不错。
另一种解决方案是在一天晚上的两次黑客马拉松中诞生的。 有一个很棒的人杰里米·霍华德(Jeremy Howard),他为每个人推广DL和ML,他有两门很棒的课程,向您介绍本课程以及更多,他为此课程撰写了FastAI。 所有这些都在PyTorch上起作用,并且在许多方面甚至重写了PyTorch,这是此lib的缺点之一。 但是从好处来看,杰里米与NLP毫无关系,今年3月,他们与另一名学生发表了一篇文章,他们在LSTM上训练了有关出色的FastAI的所有最佳实践的LSTM,他在课程中推广了许多技巧,并实际上获得了SOTA。为了一切。
由于我只是PyTorch的小传教士,所以我仍然能够从FastAI根除此模型,将其塞入PyTorch框架中,甚至可以对其进行培训,甚至可以为该任务训练整个过程。 基本上,我们具有一定的对话上下文,实际上,即使我们有几个句子,您也可以将其简单地连接为一个大句子。 answer, . FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! . pre-trained-. , , .
当然,请参加骇客马拉松假期。当您参加每周一次的黑客马拉松并同时工作时,那就不好了。您已经工作了一点,到了晚上7点,坐下来用Keras的TensorFlow编译Docker,以便所有这些工作都从您甚至无法访问的远程服务器上开始。在两个晚上的某个地方,您会发现宣泄,它对您有效-没有Docker,就没有一切,因为您知道这是可能的。看来,如果您参加大型比赛,那么分配的时间要比一周内不能入睡的时间多一些。去赢吧。谢谢你