在NVIDIA SIGGRAPH 2018上,公司首席执行官Jensen Juan正式揭幕了期待已久(并且有传言和推测)的Turing GPU架构。 下一代NVIDIA GPU(图灵)将包括许多新功能,并将于今年晚些时候问世。 尽管专业可视化(ProViz)一直是今天发布的重点,但我们希望新的架构将在其他即将推出的NVIDIA产品中使用。 今天的评论不仅仅是列出Turing的所有功能。

混合渲染和神经网络:RT和Tensor核心
那么图灵架构有什么特别之处和新之处呢? Marquee至少适用于NVIDIA ProViz社区,专为混合渲染而设计,它将光线跟踪与传统栅格化结合在一起。

重大变化:NVIDIA在Turing中包括了更多的光线追踪设备,以提供最快的硬件加速的光线追踪。 Turing架构的新功能是专用的RT Core计算单元,正如NVIDIA所称的那样,当前没有足够的信息,仅知道其功能是支持光线追踪。 这些处理器单元加快了检查射线和三角形的交集以及操纵BVH(包围体积的层次结构)的速度。
NVIDIA声称最快的Turing组件每秒可以计数100亿(Giga)射线,与未加速的Pascal相比,射线跟踪性能提高了25倍。
图灵架构包括已增强的Volta张量内核。 Tensor内核是多项NVIDIA计划的重要方面。 除了加速光线追踪之外,NVIDIA“魔术贴袋”中的一个重要工具是使用AI降噪功能来清除图像,以减少场景中所需的光线数量,这里的张量核心表现最佳。 当然,这并不是它们唯一擅长的领域-NVIDIA的所有神经网络和AI帝国都建立在它们之上。
Turing的特点是支持更广泛的精度,这意味着在对精度要求不高的工作负载中可能会大幅加速。 除精确模式Volta FP16外,图灵张量内核还支持INT8甚至INT4。 这分别比FP16快2倍和4倍。 尽管NVIDIA不想在演示中详细介绍,但我建议他们实现类似于数据打包的功能,该数据打包用于CUDA内核上的低精度操作。 尽管神经网络的准确性降低了(收益减少了-根据INT4,我们仅获得16(!)值)-某些模型确实需要这种低水平的准确性。 结果,降低精度的模式将显示出良好的吞吐量,尤其是在输出任务中,这无疑将使某些用户满意。
总的来说,回到混合渲染,有趣的是,尽管个体加速很大,但NVIDIA整体上对性能提升的承诺似乎更为适度。 尽管该公司承诺将生产效率提高到Pascal的6倍,但现在该问问要加速哪些零件以及与哪些零件进行比较了。 时间会证明一切。
同时,为了更好地利用光线跟踪之外的张量内核和狭focused的深度学习任务,NVIDIA将部署NVIDIA NGX SDK,它将神经网络集成到图像处理中。 NVIDIA期望将神经网络和张量核心用于其他图像和视频处理,包括即将推出的Deep-Anti-Aliasing(DLAA)之类的方法。
Turing SM:专用INT内核,单缓存,可变速率着色
与RT和张量内核一起,图灵流多处理器(SM)体系结构本身引入了新的技巧。 特别是,继承了最新的Volta更改之一,因此将Integer内核分配在其自己的块中,而不属于CUDA浮点内核。 优点是更快的地址生成和融合乘加(FMA)性能。
至于ALU(我仍在等待Turing的确认)-支持较低精度的更快操作(例如,快速FP16)。 在Volta中,这实现为FP16的频率是FP32的两倍,而INT8的速度是4倍。 Tensor内核已经支持此概念,因此将其转移到CUDA内核是合乎逻辑的。
快速FP16,Rapid Packed Math技术以及将多个小操作组合为一个大操作的其他方法,都是在摩尔定律变慢的时候提高GPU性能的关键组件。
仅在必要时才使用大型(精确)数据类型,可以将它们打包在一起以在同一时间段内执行更多工作。 这对于神经网络的输出以及游戏开发至关重要。 事实是,并非所有着色器程序都需要FP32精度,而降低精度可以提高性能并减少有用的内存带宽和注册表文件的使用。
Turing SM包含了NVIDIA称为“统一缓存架构”的内容。 由于我仍然期待NVIDIA提供正式的SMID图,因此尚不清楚这是否与我们在Volta看到的统一(将L1缓存与共享内存结合在一起)相同,或者NVIDIA进一步迈出了一步。 无论如何,NVIDIA都声称它现在提供的带宽是“上一代”的两倍,但尚不清楚它是指“ Pascal”还是“ Volta”(后者的可能性更大)。
最后,在图灵新闻稿中被深深隐藏,提到了可变速率阴影支持。 这是一种相对较年轻且不断发展的图形渲染技术,有关该技术的信息很少(尤其是有关NVIDIA如何实现的信息)。 但是在非常高的抽象水平上,这听起来像是“ NVIDIA的下一代技术,使您可以应用具有不同分辨率的阴影,这使开发人员可以在最需要的区域以不同的有效分辨率显示屏幕的不同区域,从而获得不同的浓度(以及渲染时间)。” 。
喂野兽:GDDR6支持
由于GPU使用的内存是由第三方公司开发的,因此没有秘密。 JEDEC及其大型3成员三星,SK Hynix和美光科技正在开发GDDR6内存,作为GDDR5和GDDR5X的后继产品。 NVIDIA已经确认Turing将支持它。 根据制造商的不同,第一代GDDR6的广告带宽为每条总线高达16 Gb / s,是最新一代NVIDIA GDDR5卡的两倍,比最新的NVIDIA GDDR5X卡快40%。
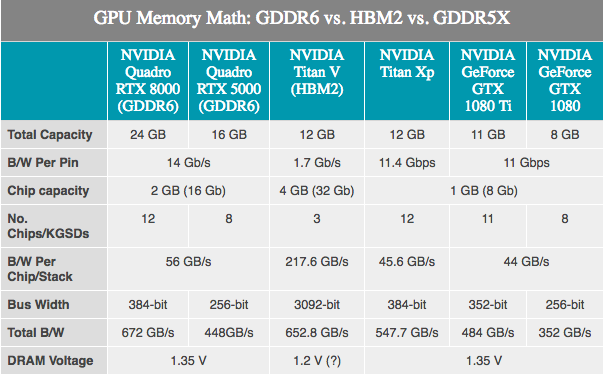
与GDDR5X相比,GDDR6看起来并不是一个重大突破,因为许多GDDR6创新已经应用于GDDR5X。 这里的基本变化包括较低的工作电压(1.35v),内部存储器现已划分:每个微电路两个存储通道。 对于标准的32位芯片-两个16位存储通道,在256位卡上总共有16个这样的通道。 尽管这反过来又说明存在大量通道,但是GPU将从创新中获得最大收益,因为从历史上看,它们是最“并行”的设备。

NVIDIA方面已经确认第一批Turing Quadro卡将使用14 Gb / s的GDDR6。 同时,NVIDIA还确认了三星内存的使用,特别是其先进的16 GB设备。 这很重要,因为这意味着典型的256位NVIDIA GPU可以配备8个标准模块,并获得16 GB的总内存容量,如果使用翻盖模式,则甚至可以达到32 GB(允许在标准256位上寻址32 GB的内存)巴士)。
各种细节:NVLink,VirtualLink和8K HEVC
在对Turing架构进行了回顾之后,NVIDIA随便确认了对某些新的外部I / O功能的支持。 NVLink支持将至少出现在几种Turing产品中。 回想一下,NVIDIA在所有三款新的Quadro卡中都使用了它。 NVIDIA提供了两种GPU配置。
重要的一点(在一部分面向游戏的读者深入阅读之前):图灵设备中存在NVLink并不意味着它将用于消费类视频卡。 也许一切都将仅限于Quadro和Tesla卡。
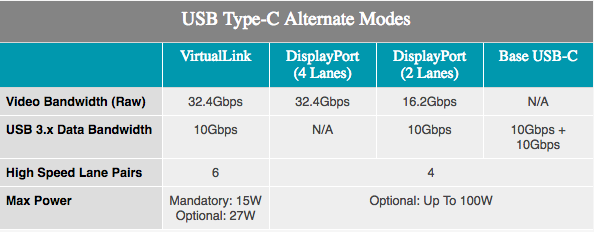
加上对VirtualLink的支持,ProViz播放器和用户将对VR有什么期望。 上个月宣布了另一种USB Type-C模式,由于一根电缆具有USB 3.1 Gen 2、4个DisplayPort HBR3频段,因此支持15 W +功率,10 Gb / s数据传输。 换句话说,这是具有附加数据和电源的DisplayPort 1.4连接。 这使视频卡可以直接控制VR耳机。 NVIDIA,AMD,Oculus,Valve和Microsoft支持该标准,因此Turing产品将成为支持该新标准的众多产品中的第一个。
尽管NVIDIA几乎没有涉及这个话题,但我们知道NINGC视频编码器单元已经在Turing中进行了更新。 最新的NVENC迭代增加了特殊的HEKC 8K编码支持。 同时,NVIDIA能够提高编码器的质量,使其视频比特率降低25%,从而达到与以前相同的质量。
绩效指标
除了公布的硬件规格外,NVIDIA还显示了Turing设备性能的多个数字。 应当指出的是,在这里我们了解得很少。 这些组件显然是基于全部或部分包含具有4608个CUDA核心和576张量核心的Turing SKU。 频率没有公开,但是,由于这些数字是针对Quadro硬件配置的,因此我们可能会看到时钟速度低于任何消费类设备。

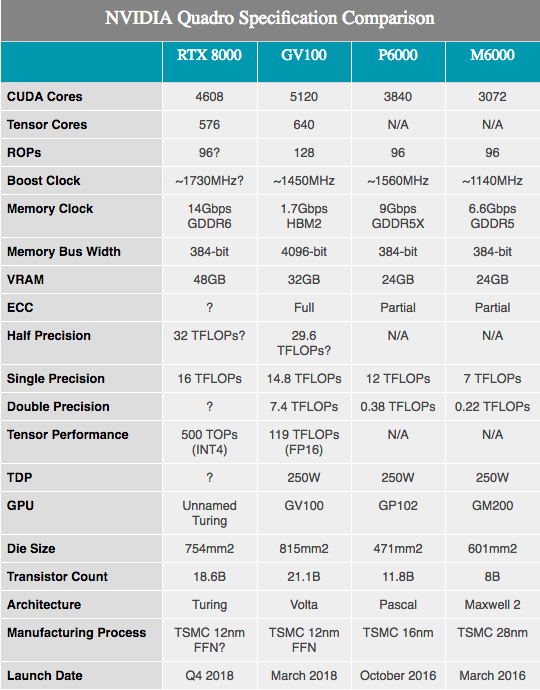
连同上述用于RT内核的10GigaRays /秒,NVIDIA张量内核的性能为每秒500万亿张量操作(500T TOP)。 作为参考,NVIDIA经常提到GV100 GPU能够提供最大120T TOP的能力,但这不是一回事。 特别是,虽然在处理FP16的操作中提到了GV100,但图灵的性能却以极低的精度INT4来引用,它的精度仅为FP16的四分之一,因此将吞吐量提高了四倍。 如果我们对精度进行归一化,那么图灵张量内核似乎并不是每个内核都具有最佳吞吐量,而是提供了比Volta更多的精度选项。 无论如何,该芯片中的576张量内核使它几乎与GV100(具有640个此类内核)相提并论。
关于CUDA内核,NVIDIA声称Turing GPU可以提供16 TFLOPS性能。 这比Tesla V100的单精度精度高15 TFLOPS,甚至比Titan V的13.8 TFLOPS还要高。如果您要寻找更便于消费者使用的信息,则比Titan Xp高32%。 在纸上进行了一些粗略的计算之后,我们可以假设GPU时钟速度约为1730 MHz,因为在SM级别上没有其他更改会改变传统ALU性能公式。
同时,NVIDIA宣布Quadro卡将配备以14 Gb / s的速度运行的GDDR6内存。 看两个分别提供48 GB和24 GB GDDR6的最佳Quadro SKU,我们几乎可以看到此Turing GPU上的384位内存总线。 谈到数字,两个高端Quadro卡的内存带宽总计为672 GB / s。
否则,随着体系结构的变化,很难进行许多有用的性能比较,尤其是与Pascal进行比较时。 从我们对Volta的了解来看,NVIDIA的整体性能得到了改善,尤其是在精心设计的计算工作负载中。 因此,与Quadro P6000相比,纸张性能提高了约33%,可能会更大。
我会提到新GPU的晶体大小。 它位于754平方毫米,不仅很大,而且很大。 与其他GPU相比,只有NVIDIA GV100大小排名第二,目前仍是NVIDIA的旗舰产品。 但是,有了186亿个晶体管,不难理解为什么最终的芯片应该这么大。 显然,NVIDIA为该GPU制定了宏伟的计划,最终它将能够证明其产品堆栈中存在两个巨大的图形处理器。
NVIDIA本身并未指出该GPU的具体型号-无论是传统的102类还是100类GPU。 我想知道我们是否会以一种或另一种形式看到针对消费类产品的这种GPU的修改? 它是如此之大,以至于NVIDIA可能希望保留其利润更高的Quadro和Tesla GPU。
如果不早于2018年第四季度发布
最后,我要说的是,随着Turing架构的发布,NVIDIA宣布首批基于Turing GPU的4张Quadro卡-Quadro RTX 8000,RTX 6000和RTX 5000将于今年第四季度开始发售。 由于此声明的本质有些颠倒-通常是NVIDIA首先发布消费类组件-我不会将相同的时间表应用于没有如此严格的验证要求的消费类卡。 如果不是更早的话,我们将在今年第四季度看到图灵设备。 那些想购买Quadro的人现在可以开始省钱:最好的新Quadro RTX 8000卡将花费您10,000美元。
最后,对于拥有NVIDIA Tesla的消费者而言,Turing的推出使Volta陷入困境。 NVIDIA没有告诉我们图灵是否最终会扩展到特斯拉的高端市场-取代GV100-还是他们最好的Volta处理器将保留其市场数百年。 但是,由于到目前为止其他Tesla卡都是基于Pascal的,因此它们是Turing在2019年排挤的首批候选人。
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,
为我们为您发明的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
VPS(KVM)E5-2650 v4(6核)10GB DDR4 240GB SSD 1Gbps至12月免费,在六个月内付款,您可以
在此处订购。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?