在芯片级别引入AI可以使您在本地处理更多数据,因为设备数量的增加不再带来相同的效果
芯片制造商正在研究可以显着增加每瓦特和周期处理的数据量的新架构。 这是近几十年来芯片架构最大的革命之一。
所有主要的芯片和系统制造商都在改变发展方向。 他们进入了架构竞赛,在一切方面都发生了范式转换:从读写方法到内存,再到处理过程,最终是芯片上各种元素的布局。 尽管小型化仍在继续,但是没有人押注于扩展以应对来自传感器的数据的爆炸性增长并增加机器之间的通信量。
新架构的变化包括:
- 根据应用的不同,有时会在1个时钟周期内处理精度更高或某些操作优先级的数据的新方法。
- 新的内存体系结构改变了我们存储,读取,写入和访问数据的方式。
- 遍布系统的更专业的处理模块靠近内存。 根据数据类型和应用程序选择加速器,而不是中央处理器。
- 在AI领域,正在进行以模板形式组合各种类型的数据的工作,这有效地增加了数据的密度,同时最大程度地减少了不同类型之间的差异。
- 现在,机箱中的布局是体系结构的主要组成部分,越来越多的注意力集中在更改这些设计的简便性上。
Rambus杰出工程师Stephen Wu表示:“有几种趋势会影响技术进步。” -在数据中心,您可以充分利用硬件和软件。 从这个角度来看,数据中心所有者正在关注经济。 引入新的东西是昂贵的。 但是瓶颈正在改变,因此引入了专用芯片来提高计算效率。 而且,如果减少往返I / O和内存的数据流,则会产生很大的影响。”
这些变化在计算基础架构的边缘(即在终端传感器之间)更为明显。 制造商突然意识到,数以百计的设备会生成太多数据:这样的数据量无法发送到云中进行处理。 但是,在边缘处理所有这些数据会带来其他问题:它需要在不显着增加功耗的情况下大幅提高性能。
特斯拉Nvidia首席平台架构师罗伯特·奥伯(Robert Ober)说:“出现了一种降低精度的新趋势。” -这些不只是计算周期。 这是在内存中使用16位指令格式的更加密集的数据打包。”
Aubert相信,由于在可预见的将来进行了一系列架构优化,因此每两年即可使处理速度加倍。 他说:“我们将看到生产率显着提高。” -为此,您需要做三件事。 首先是计算。 第二个是记忆。 第三个区域是主机带宽和I / O带宽。 要优化存储和网络堆栈,需要做很多工作。”
已经在执行某些操作。 在2018年Hot Chips会议上的演讲中,三星奥斯汀研究中心的首席架构师Jeff Rupley指出了M3处理器的几项重大架构更改。 一个包含每拍更多的指令-在最后一个M2芯片中包含六个而不是四个。 此外,实现了神经网络的分支预测,并且指令队列增加了一倍。
这种变化将创新点从直接的微电路制造转移到一方面的体系结构和设计,再转移到生产链另一侧的元件布局。 尽管创新将继续在技术过程中继续进行,但仅以此为代价,很难在每种新芯片模型中将生产率和功耗提高15%至20%,这还不足以应对数据量的快速增长。
Xilinx总裁兼首席执行官Victor Pan在Hot Chips会议上的演讲中说:“变化正在以指数级的速度进行,每年将产生10 ZB(10
21字节)的数据,并且其中大多数是非结构化的。”
记忆的新方法
处理大量数据需要重新考虑系统中的每个组件,从数据处理方法到存储方法。
eSilicon EMEA高级创新总监Carlos Machin说:“已经进行了很多尝试来创建新的存储器架构。 -问题是您需要读取所有行并在每行中选择一位。 一种选择是创建一个可以从左到右以及从上到下读取的内存。 您甚至可以走得更远,并将计算添加到内存中。”
这些更改包括更改读取内存的方法,处理元件的位置和类型,以及引入AI来优先确定整个系统中数据的存储,处理和移动。
“如果数据稀疏,我们一次只能从该数组中读取一个字节,或者也许从同一字节路径中读取八个连续的字节,而又不浪费精力在我们不感兴趣的其他字节或字节路径上,那该怎么办? ? “ Aks Mark Greenberg,Cadence产品营销总监。” -将来有可能。 例如,如果您查看HBM2的体系结构,则将堆栈组织为16个虚拟通道(每个通道分别为64位),并且只需要获取4个连续的64位字即可访问任何虚拟通道。 因此,可以创建宽度为1024位的数据数组,水平写入,但一次垂直读取四个64位字。”
内存是冯·诺依曼(von Neumann)体系结构的主要组成部分之一,但现在它也已成为实验的主要领域之一。 AMD客户产品首席架构师Dan Bouvier说:“主要的敌人是虚拟内存系统,在虚拟内存系统中,数据以更不自然的方式进行移动。” -这是广播节目。 我们在图形领域已经习惯了这一点。 但是,如果我们解决了DRAM存储库中的冲突,我们将获得更高效的流传输。 然后,单独的GPU可以在90%的效率范围内使用DRAM,这非常好。 但是,如果您设置流媒体而不会中断,则CPU和APU的效率范围也将从80%降至85%。”
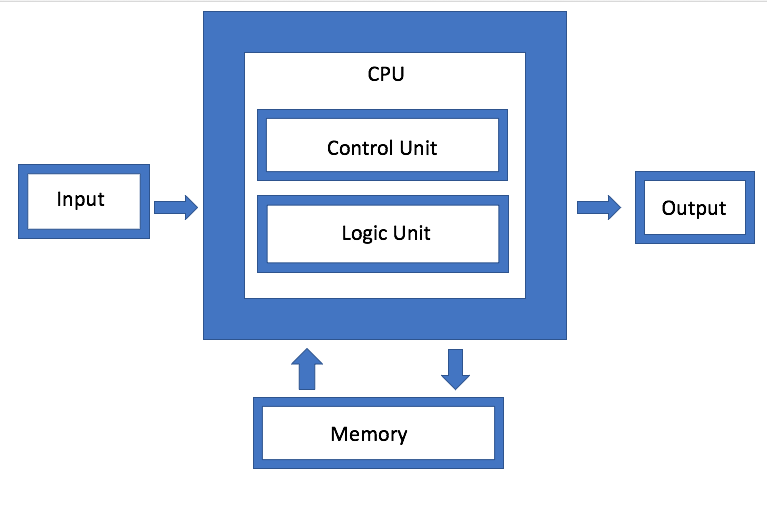 图 1.建筑学冯·诺依曼。 资料来源:半导体工程
图 1.建筑学冯·诺依曼。 资料来源:半导体工程IBM正在开发另一种类型的内存体系结构,它实质上是磁盘聚合的升级版本。 目标是,系统可以使用连接器任意使用任何可用的内存,而不是使用单个驱动器,IBM硬件架构师Jeff Stucheli将其称为“瑞士军刀”来连接元素。 该方法的优点是它允许您混合和匹配不同类型的数据。
“处理器正在成为高性能信号接口的中心,” Stucelli说。 “如果更改微体系结构,则内核在每个周期以相同的频率执行更多的操作。”
连接性和吞吐量应确保处理大量增加的生成数据。 Rambus的Wu表示:“主要的瓶颈现在位于数据移动位置。” “该行业在提高计算速度方面做得很好。” 但是,如果您希望使用数据或专用数据模板,则需要更快地运行内存。 因此,如果您查看DRAM和NVM,性能取决于流量模式。 如果数据正在流式传输,则内存将提供非常好的性能。 但是,如果数据随机丢失,则效率会降低。 而且无论您做什么,随着音量的增加,您仍然必须更快地做到这一点。”
更多的计算,更少的流量。
由于边缘设备以不同的频率和速度生成了几种不同类型的数据,这使问题更加复杂。 为了使这些数据在不同的处理模块之间自由移动,管理必须比过去更加高效。
“有四种主要配置:多对多,内存子系统,低功耗IO,网格和环形拓扑,” Arteris IP董事长兼首席执行官Charlie Janak说。 -您可以将所有四个放置在一个芯片上,这与关键的IoT芯片相同。 或者,您可以添加高通量HBM子系统。 但是复杂性是巨大的,因为其中一些工作负载是非常特定的,并且该芯片具有多个不同的工作任务。 如果您查看其中的某些微芯片,它们将获得大量数据。 这是在汽车雷达和激光雷达等系统中。 没有一些高级互连,它们就不可能存在。”
任务是如何最大程度地减少数据移动,但同时又在需要时最大化数据流-并以某种方式在本地处理和集中式处理之间找到平衡,而不必增加能耗。
“一方面,这是带宽问题,” NetSpeed Systems产品营销经理Rajesh Ramanujam说。 -您希望尽可能减少流量,因此将数据传输到处理器附近。 但是,如果仍然需要移动数据,则建议尽可能压缩它们。 但是,它本身不存在任何东西。 一切都需要从系统级别进行计划。 在每个步骤中,必须考虑几个相互依赖的轴。 它们确定您是以传统的读写方式使用内存还是使用新技术。 在某些情况下,您可能需要更改存储数据本身的方式。 如果需要更高的性能,这通常意味着增加芯片面积,从而影响散热。 现在,考虑到功能安全性,不允许数据过载。”
因此,各种数据处理模块都非常重视边缘和通道带宽上的数据处理。 但是,随着您开发不同的架构,实现数据处理的方式和位置也将大为不同。
例如,Marvell推出了具有内置AI的SSD控制器,以处理边缘上的繁重计算负载。 AI引擎可用于SSD驱动器内部的分析。
“您可以将模型直接加载到硬件中,并在SSD控制器上进行硬件处理,” Marvell的首席工程师Ned Varnitsa说。 -今天,它使服务器在云中(主机)。 但是,如果每个磁盘将数据发送到云,这将创建大量的网络流量。 最好在边缘进行处理,并且主机仅发出命令,而这只是元数据。 您拥有的驱动器越多,处理能力就越大。 这是减少流量带来的巨大好处。”
这种方法特别有趣,因为它可以根据应用程序适应不同的数据。 因此,主机可以生成任务并将其发送到存储设备进行处理,然后仅将元数据或计算结果发送回去。 在另一种情况下,存储设备可以存储数据,对其进行预处理并生成元数据,标签和索引,然后由主机根据需要进行检索以进行进一步分析。
这是可能的选择之一。 还有其他 三星的Rupli强调了处理和合并可以解码两条指令并将它们组合为一个操作的习惯用法的重要性。
人工智能处理控制和优化
在所有优化级别,都使用人工智能-这是芯片体系结构中真正的新元素之一。 代替允许操作系统和中间件管理功能,此监视功能分布在整个芯片上,芯片之间以及系统级别。 在某些情况下,会引入硬件神经网络。
eSilicon营销副总裁Mike Gianfanya说:“重点并不是将更多的元素组合在一起,而是改变传统的体系结构。” -借助AI和机器学习,您可以在系统中分布元素,从而通过预测获得更有效的处理。 或者,您可以使用在系统或模块中独立运行的单独芯片。”
ARM已经开发了第一款机器学习芯片,该芯片计划于今年晚些时候在多个市场发布。 “这是一种新型的处理器,” ARM荣誉工程师Ian Bratt说。 -它包括一个基本模块-它是计算引擎,以及MAC引擎,具有控制模块的DMA引擎和广播网络。 总共有16个使用7 nm处理技术制造的计算核心,它们以1 GHz的频率产生4 TeraOps。”
由于ARM与合作伙伴生态系统一起工作,因此其芯片比正在开发的其他AI / ML芯片更具通用性和可定制性。 它不是整体结构,而是按功能将处理分开,因此每个计算模块都在单独的特征图上工作。 布拉特确定了四个关键要素:静态计划,有效折叠,缩小机制以及针对未来设计变更的程序化适应。
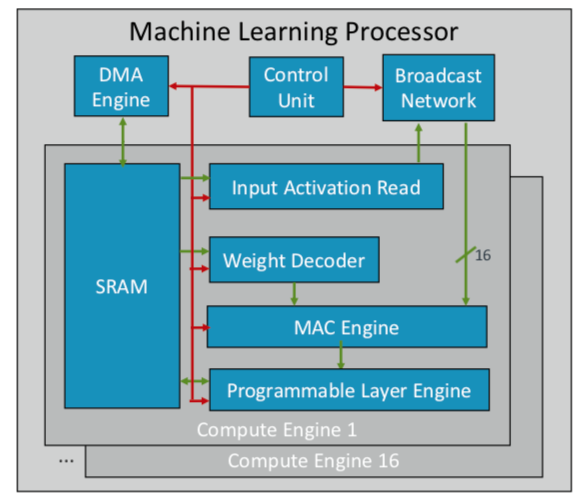 图 2. ARM处理器ML体系结构。 资料来源:ARM /热门芯片
图 2. ARM处理器ML体系结构。 资料来源:ARM /热门芯片同时,Nvidia选择了另一种策略:在GPU旁边创建专用的深度学习引擎,以优化图像和视频处理。
结论
使用这些方法中的一些或全部,芯片制造商期望每两年将性能提高一倍,以跟上爆炸性的数据增长,同时保持在严格的能源预算范围内。 但这不仅仅是更多的计算。 这是芯片和系统设计平台的一种变化,当不断增长的数据量而不是硬件和软件的限制成为主要因素时。
Synopsys董事长兼首席执行官Aart de Gues说:“当计算机出现在公司中时,我们周围的世界似乎在加速发展。” -他们在有成堆的书的纸上会计。 分类帐已经变成一堆打孔卡,用于打印和计算。 发生了巨大的变化,我们再次看到了。 随着简单计算计算机的问世,操作的算法没有改变:您可以跟踪每个步骤。 但是现在正在发生其他事情,有可能导致新的加速。 就像在农田上浇水并仅在温度达到所需水平的某一天才施用某种肥料。 机器学习的这种使用是过去不明显的优化。”
在评估中他并不孤单。 西门子业务部Mentor总裁兼首席执行官Wally Raines说:“将采用新的体系结构。” -他们将被设计。 机器学习将在很多或大多数情况下使用,因为您的大脑会从自己的经验中学习。 我拜访了20家或更多开发某种类型的专业AI处理器的公司,每个公司都有自己的小众市场。 但是您将越来越多地看到它们在特定应用中的应用,它们将补充传统的von Neumann体系结构。 神经形态计算将成为主流。 这是计算效率和降低成本的重要一步。 移动设备和传感器将开始执行服务器今天要做的工作。”