在本文中,我想谈谈训练模型时使用数据的一些技术。 特别是,如何在盒子上进行对象分割,以及如何训练模型并获得数据集的标记,仅标记几个样本。
挑战赛
从各个阶段制作比萨饼和照片都有一定的过程(不仅包括比萨饼)。 众所周知,如果面团配方变质,则外壳上会出现白色丘疹。 专家对每个比萨饼的测试质量都有一个二进制标记。 有必要开发一种算法,可以根据照片确定测试的质量。
数据集包含从不同手机,不同条件,不同角度拍摄的照片。 披萨实例-17k。 总照片-60k。
在我看来,这项任务非常典型,非常适合展示数据处理的不同方法。 要解决此问题,您必须:
1.选择有披萨皮的照片;
2.在选定的照片上,突出显示蛋糕;
3.在选定区域训练神经网络。
筛选照片
乍看之下,似乎最简单的方法是将这项任务交给抄写员,然后在干净的数据上训练数据集。 但是,我认为我自己划出一小部分要比用划线员解释哪个角度是正确的容易。 而且,对于直角我没有严格的标准。
所以这就是我所做的:
1.标记100张边缘照片;

2.在使用权重从imagenet11k_places365从resnet-152网格全局拉出之后,计算了特征。
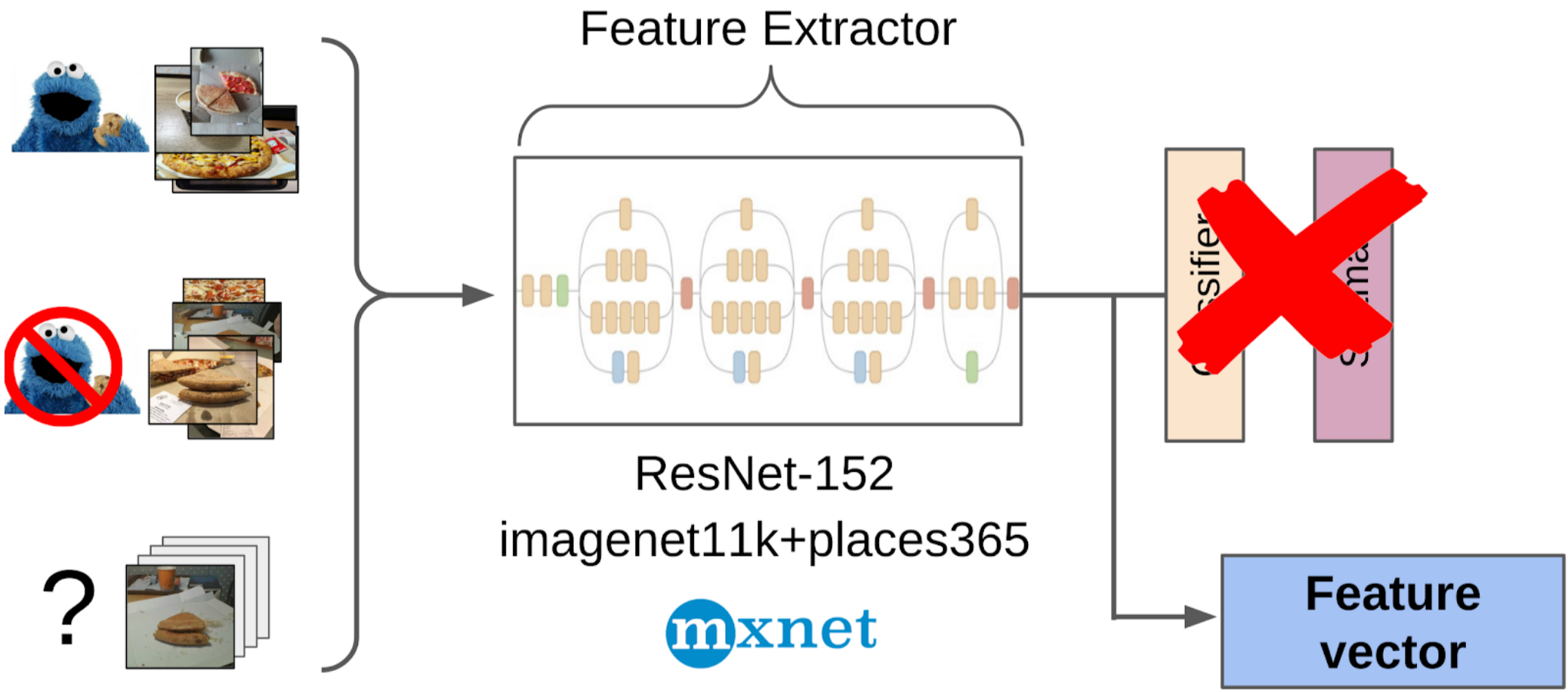
3.取得每个类别的平均特征,接收两个锚点;
4.我计算了每个锚点到其余5万张照片的所有特征之间的距离;
5.靠近一个锚点的顶部300与阳性类别相关,最接近另一锚点的顶部500与阴性相关。
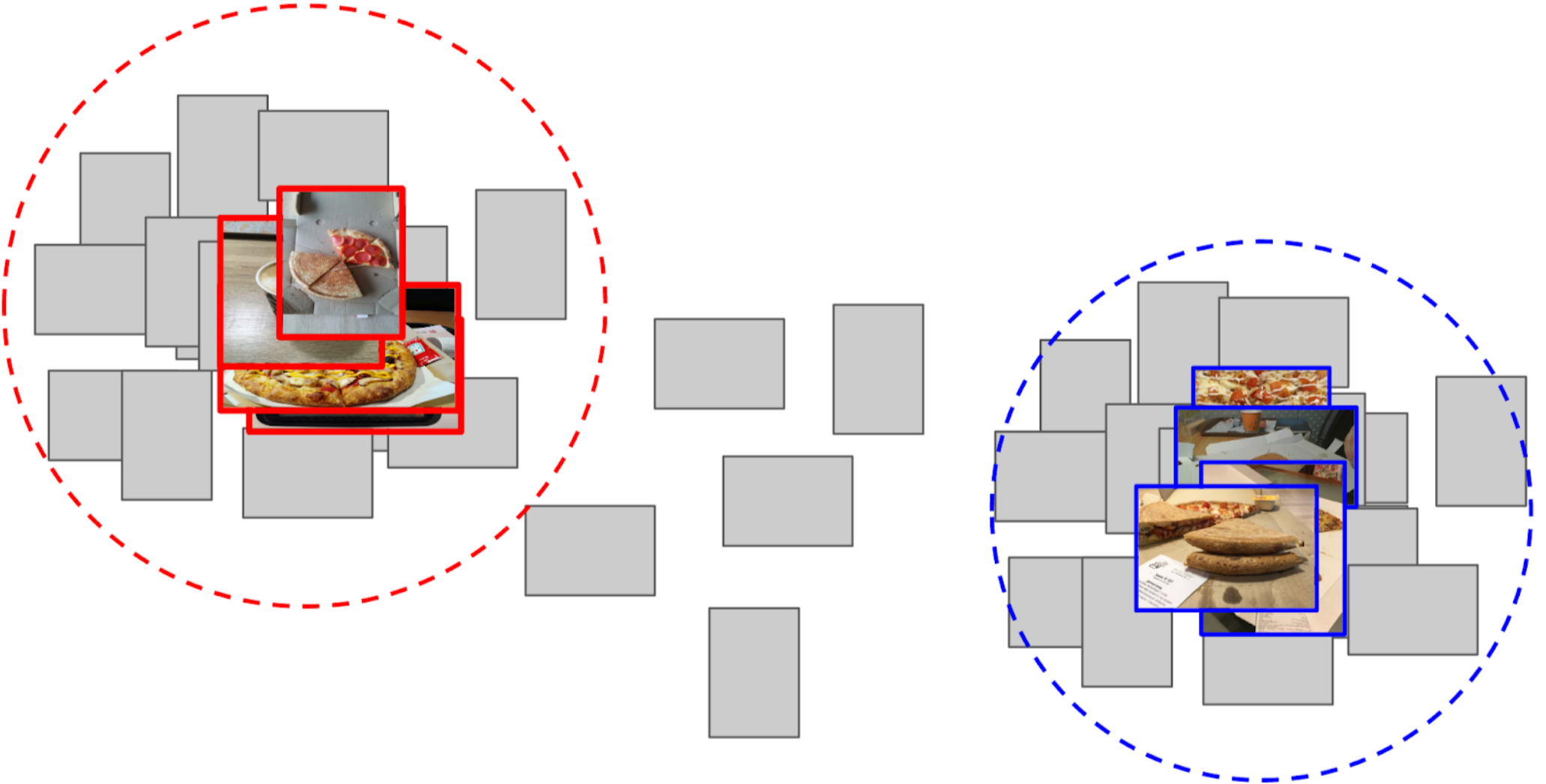
6.我对这些具有相同功能的样本进行了LightGBM培训(图片中标明了XGboost,因为它带有徽标并且更易于识别,但是LightGBM没有徽标);
7.使用该模型,我得到了整个数据集的标记。

我在kaggle比赛中使用的
基准线大致相同。
用手指解释为什么这种方法行之有效神经网络可以看作是图片的强烈非线性变换。 在分类的情况下,将图片转换为训练集中的类的概率。 这些概率实际上可以用作Light GBM的功能。 但是,这是一个很差的描述,因此对于披萨,我们可以说蛋糕的类别有条件地为0.3只猫和0.7只狗,其余为垃圾。 相反,在全局平均池化之后,可以使用较少的稀疏功能。 它们具有从训练集的样本生成特征的特性,应通过线性变换(带有Softmax的完全连接层)将特征分开。 但是,由于在imagenet火车中没有显式披萨,因此最好采用树形式的非线性变换来分隔新训练集的类。 原则上,您可以走得更远,并从神经网络的某些中间层获取功能。 它们会更好,因为它们尚未丢失对象的位置。 但是由于特征向量的大小,它们会更糟。 此外,它们的线性度不如完全连接的层前面。
有点题外话
ODS最近抱怨没有人写过他们的失败。 纠正情况。 大约一年前,我与
Eugene Nizhibitsky参加了
Kaggle海狮比赛。 任务是计算无人机图像中的海狗。 标记只是以
car体坐标的形式给出的,但是在某个时候,
弗拉基米尔·伊格洛维科夫用盒子标记了它们,并慷慨地与社区共享。 那时,我以为自己是语义分割的父亲(在
Kaggle Dstl之后 ),并决定如果我学会经典地区分猫,Unet将大大简化计数工作。
语义分割的说明语义分割实质上是图片的逐像素分类。 即,图片的每个源像素需要与一个类别相关联。 在二进制分割的情况下(在本文中为例),它将是肯定的或否定的类别。 在多类别分割的情况下,将从训练集中为每个像素分配一个类别(背景,草,猫,人等)。 在二进制分割的情况下,当时的
U-net神经网络体系结构运行良好。 该神经网络的结构类似于常规的编码器-解码器,但具有在适当的大小阶段从编码器部分到解码器的特征转发。

但是,没有任何人以香草形式使用它,但至少他们添加了Batch Norm。 好吧,通常,他们采用
胖编码器并给解码
器充气。 类似U-net的体系结构已被新型的
FPN分割网格所取代,该网格在某些任务上显示出良好的性能。 但是,类似Unet的体系结构至今仍未失去其意义。 它们作为基线很好地工作,易于训练,并且通过更改不同的编码器来改变神经科学的深度/大小非常简单。
因此,我开始教分割法,第一阶段只将拳击猫作为目标。 在训练的第一阶段之后,我对火车进行了预测,并查看了预测的外观。 借助试探法,人们可以从掩码中选择抽象的置信度,然后有条件地将预测分为两类:什么都好,哪里不好。

一切正常的预测可用于训练模型的下一次迭代。 一切都不好的预测可以在没有密封的情况下进行大面积选择,双手要戴上面具,也可以扔进火车。 因此,我和Eugene反复训练了一个模型,该模型甚至学会了为大型个体分割海狗鳍。
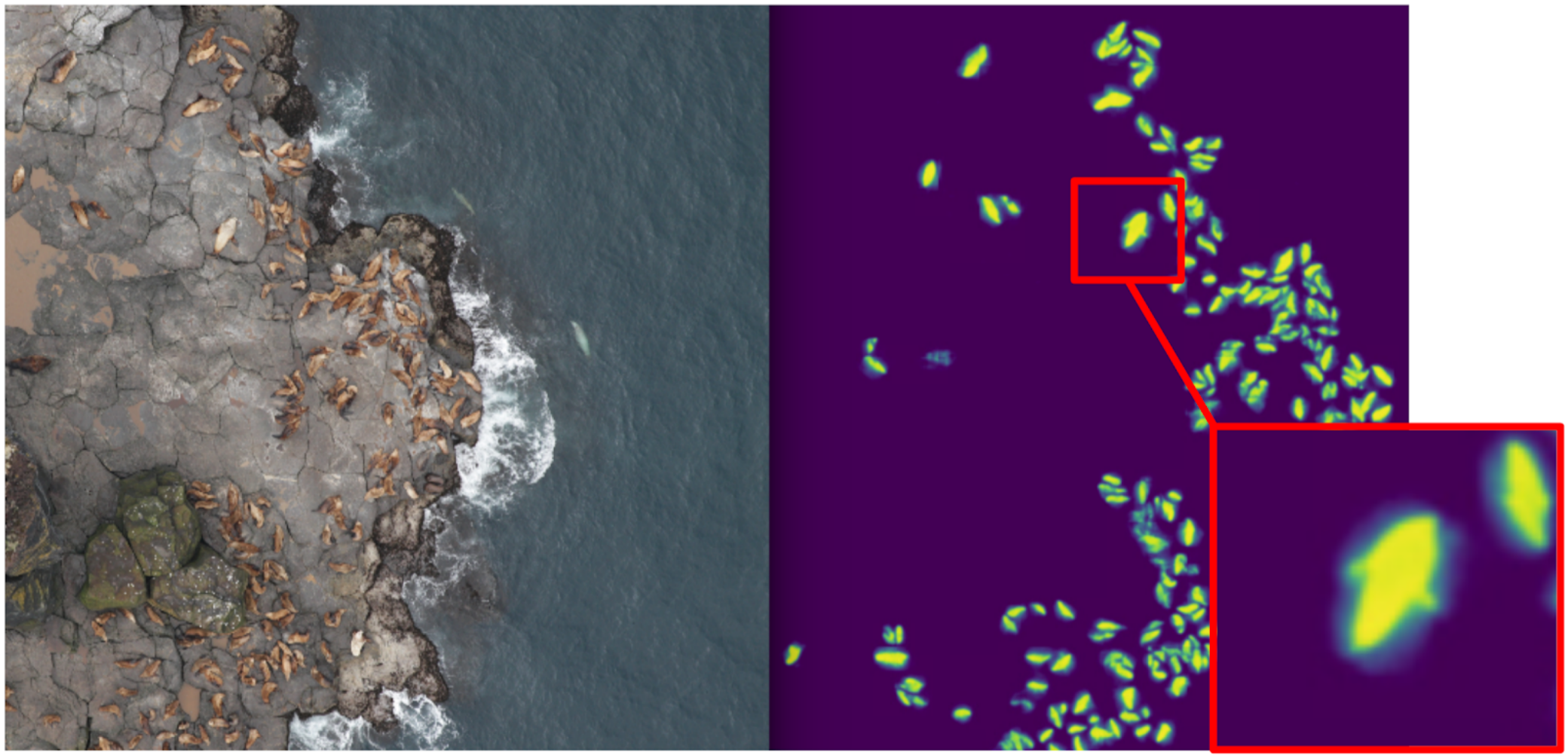
但这是一个严重的失败:我们花了很多时间来学习如何对酷猫进行细分,并且……这几乎没有帮助他们进行计算。 密封的密度(面具的单位面积上的个人数量)恒定的假设是行不通的,因为无人机以不同的高度飞行,并且图片具有不同的比例。 同时,细分仍然不能将单个人放得紧紧地挑出来-这种情况经常发生。 在DSB2018上采用
创新方法分离 Tocoder团队
的对象之前,还有一年的时间。 结果,我们在600支队伍中排名第40位,一无所获。
但是,我得出两个结论:语义分割是一种用于可视化和分析算法操作的便捷方法,并且可以通过一些努力将屏蔽从盒子中焊接出来。
但是回到比萨。 为了突出显示所选照片和过滤后的照片上的蛋糕,最正确的选择是将任务分配给划线员。 那时,我们已经为它们实现了盒子和共识算法。 因此,我仅举了几个例子,并进行了说明。 结果,我得到了500个带有精确选择的外壳区域的样品。
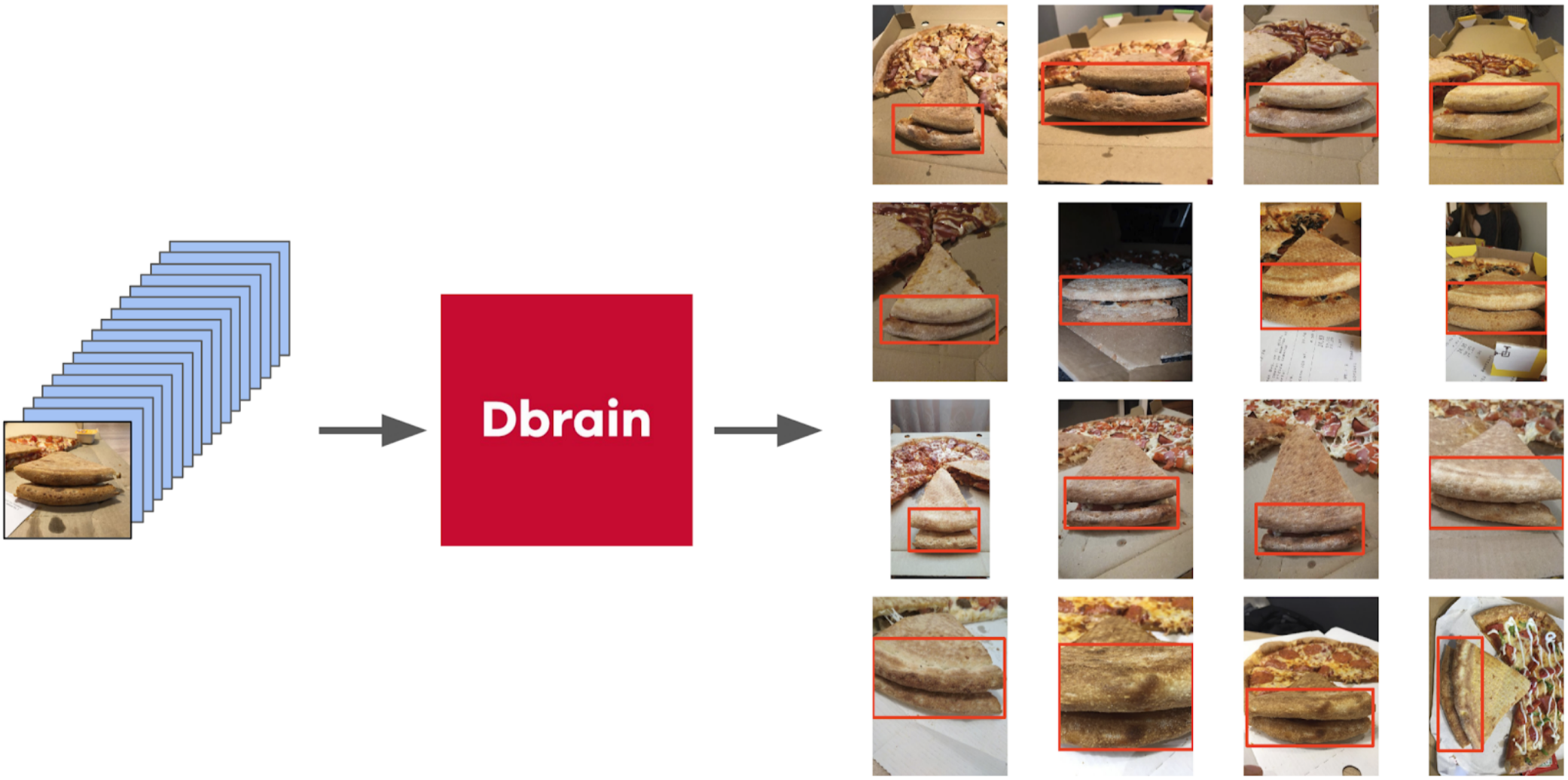
然后,我从图章中挖出我的代码,并正式采用了当前程序。 在训练的第一次迭代之后,还可以清楚地看到模型被错误的地方。 预测的置信度可以定义如下:
1-(灰色区域)/(遮罩区域)#我会保证会有一个公式
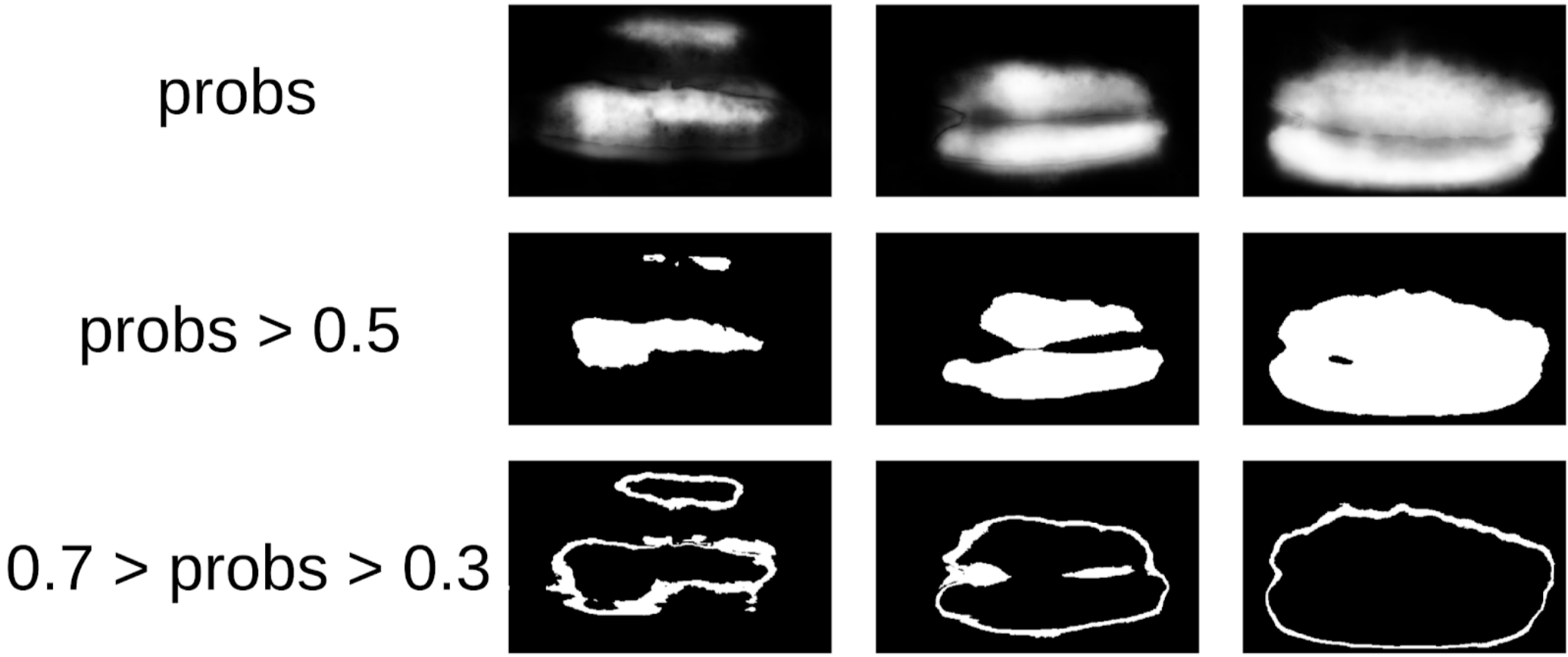
现在,为了进行下一次拉动口罩上的盒子的迭代,一个小的合奏将预测TTA火车。 在某种程度上可以认为这是WAAAAGH知识蒸馏,但是将其称为伪标记更为正确。
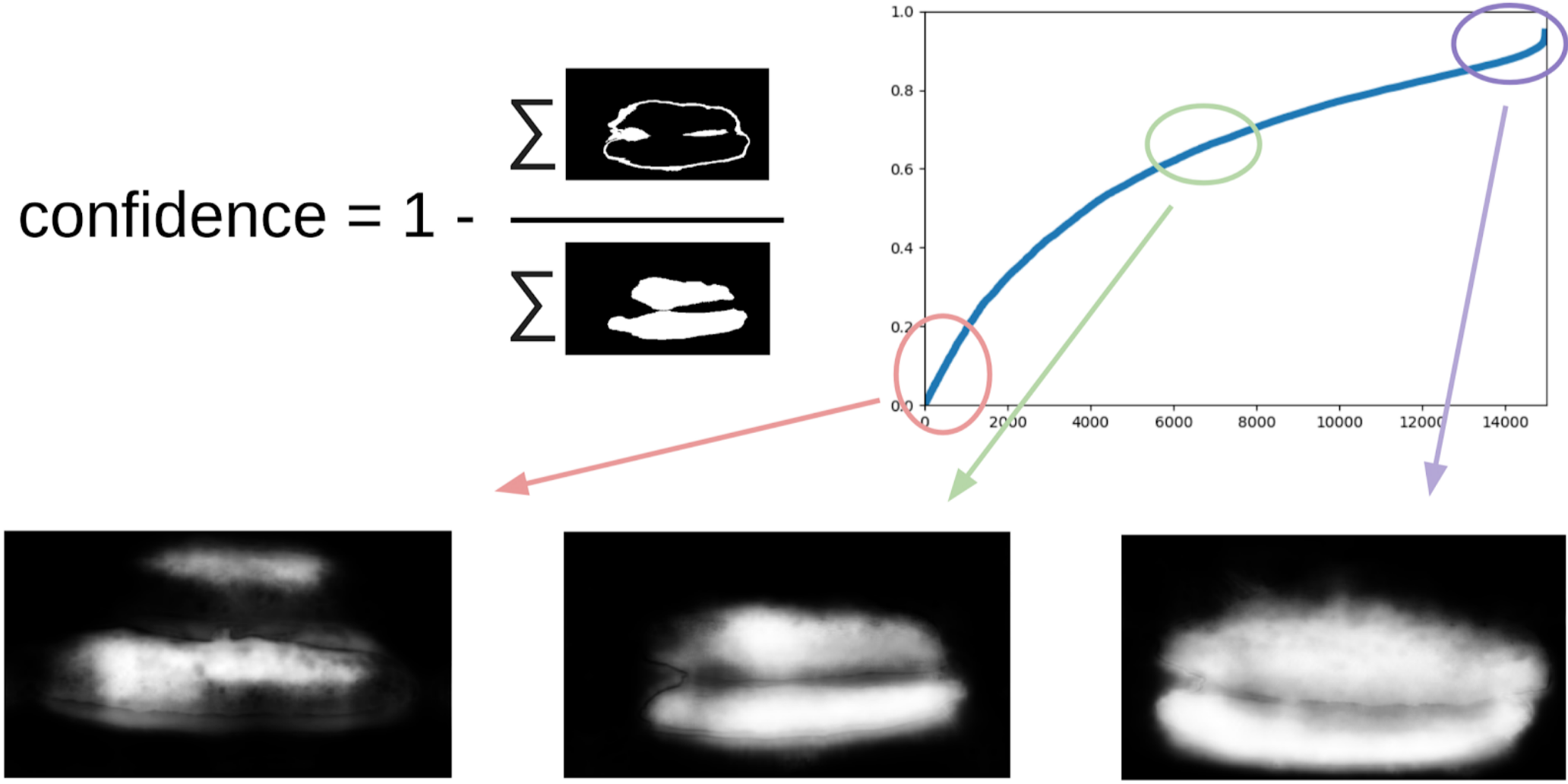
接下来,您需要用眼睛选择一定的置信度阈值,从此我们开始新的培训。 并且可以选择标记出该集合无法处理的最复杂的样本。 我认为这会很有用,并在消化午餐时在某处绘制了约20张图片。
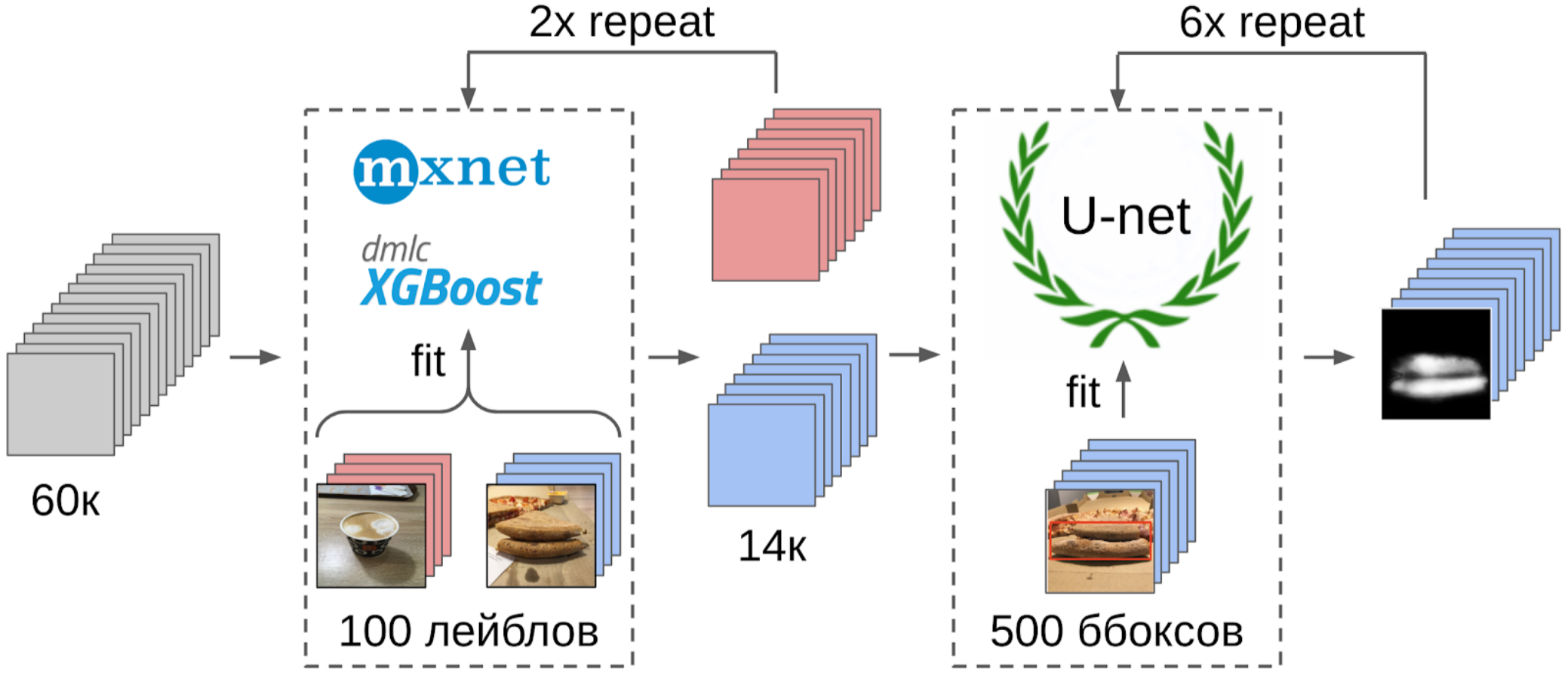
现在,计划的最后一部分是:模型训练。 为了准备样品,我提取了蛋糕的掩膜区域。 我还用膨胀使面罩膨胀了一点,然后将其应用到图片上以去除背景,因为应该没有关于测试质量的信息。 然后我刚刚从Imagenet Zoo提交了多个模型。 总共,我能够收集大约12,000个自信样本。 因此,我没有讲授整个神经网络,而只教了最后一组卷积,因此不会对模型进行重新训练。
为什么需要冻结图层这样做有两个好处:1.网络学习速度更快,因为您无需读取冻结图层的渐变。 2.网络没有经过重新训练,因为它现在具有更少的可用参数。 有人认为,在Imagenet训练期间,前几组卷积会生成非常常见的信号,例如清晰的色彩过渡和纹理,适用于摄影中非常广泛的对象。 这意味着您无法在Transer Learning期间对其进行培训。
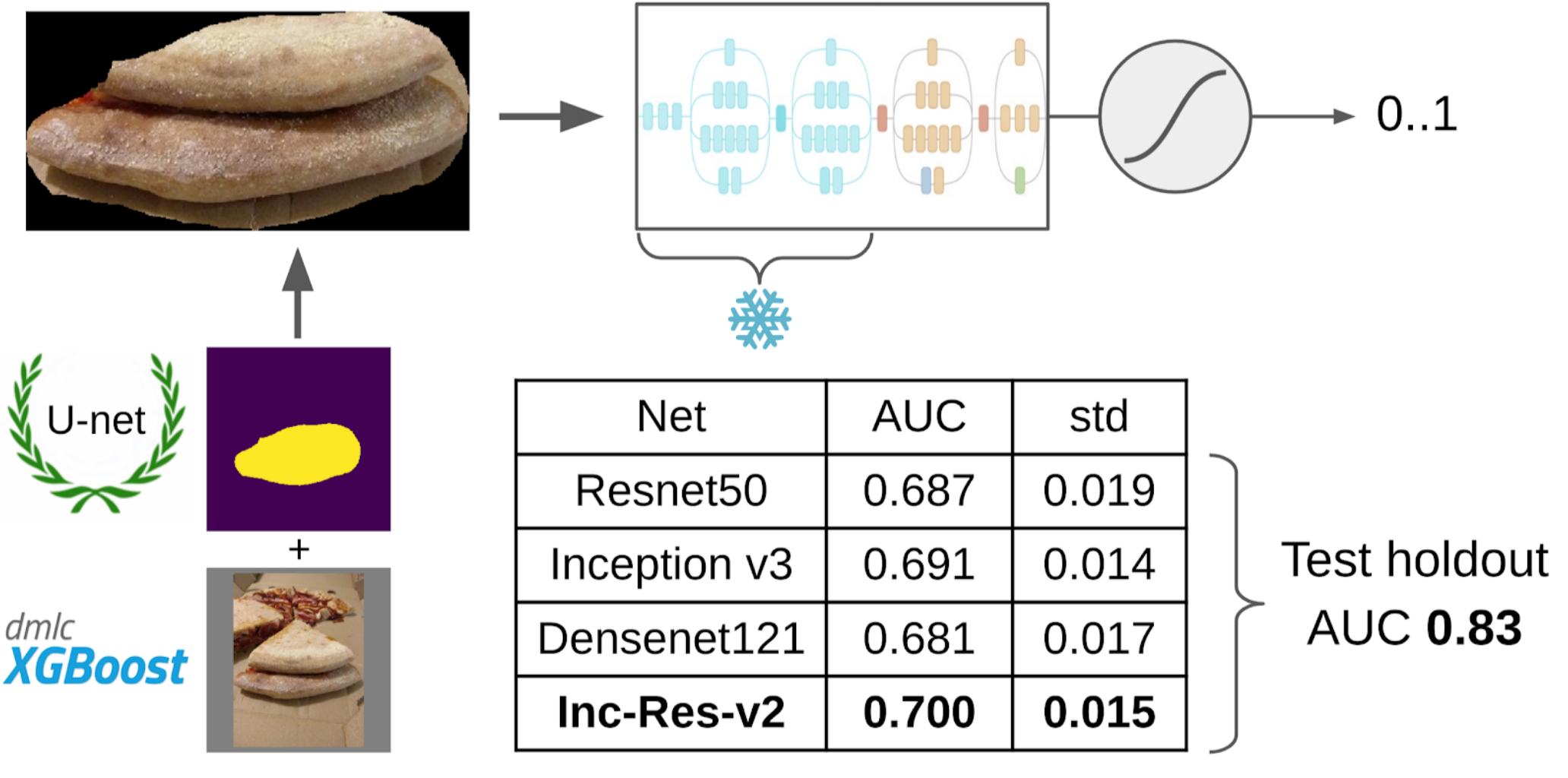
最好的单一模型是Inception-Resnet-v2,对她来说,ROC-AUC的一倍是0.700。 如果您未选择任何内容并按原样提交原始图片,则ROC-AUC为0.58。 在我开发解决方案时,下一批数据是在DODO Pizza上烹饪的,并且可以在诚实的坚持下测试整个管道。 我们检查了整个管道,得出ROC-AUC 0.83。
现在让我们看一下错误:
最高误报率

在这里可以看出,它们与蛋糕标记上的错误有关,因为明显有测试变质的迹象。
最高误报率

这里的错误与以下事实有关:选择第一个模型不是一个很好的角度,因此很难找到测试质量的关键标志。
结论
同事有时会逗我说我通过使用Unet进行细分解决了许多问题。 但是,我认为这是一种非常强大且方便的方法。 它使您可以可视化模型错误及其预测的可信度。 此外,整个支付线看起来非常简单,现在任何框架都有很多存储库。