在本文中,我们将讨论如何以及为什么开发
交互系统 (一种在客户端应用程序和1C:企业服务器之间传输信息的机制),从设置任务到对体系结构和实现细节进行思考。
交互系统(以下称为CB)是具有保证传递的分布式容错消息传递系统。 SV被设计为具有高可伸缩性的高负载服务,既可以作为在线服务(由1C提供),也可以作为可以在其服务器容量上部署的流通产品来使用。
CB使用
Hazelcast分布式存储和
Elasticsearch搜索引擎。 我们还将讨论Java以及如何水平扩展PostgreSQL。

问题陈述
为了清楚说明为什么要创建交互系统,我将向您介绍1C中业务应用程序的开发工作方式。
首先,为那些还不知道我们在做什么的人提供一些关于我们的信息:)我们正在创建1C:企业技术平台。 该平台包括用于开发业务应用程序和运行时的工具,该工具允许业务应用程序在跨平台环境中工作。
客户-服务器开发范例
在“ 1C:企业”上创建的业务应用程序在三级
客户端-服务器体系结构“ DBMS-应用程序服务器-客户端”中运行。 可以在应用程序服务器或客户端上执行以
嵌入式语言1C编写的应用程序代码。 应用程序对象(目录,文档等)的所有工作以及对数据库的读取和写入仅在服务器上执行。 表单和命令界面的功能也在服务器上实现。 客户接收,打开并显示表格,与用户“通信”(警告,问题...),表格中的小计算需要快速反应(例如,将价格乘以金额),使用本地文件,使用设备。
在应用程序代码中,过程和函数的标题必须明确指示执行代码的位置-使用指令&在客户端上/在服务器上(英语版本的&AtClient /&AtServer)。 现在,使用1C的开发人员将纠正我,说实际上还有
更多的指令,但是对我们而言,这现在不是必需的。
可以从客户端代码调用服务器代码,但是不能从服务器代码调用客户端代码。 这是我们出于多种原因做出的基本限制。 特别是,由于必须编写服务器代码以使其均等地执行,所以无论从客户端还是从服务器调用它,无论在何处调用它。 而且,如果从另一个服务器代码中调用服务器代码,则客户端本身将不存在。 并且由于在执行服务器代码期间,导致其原因的客户端可以关闭,退出应用程序,并且服务器将没有人要调用。
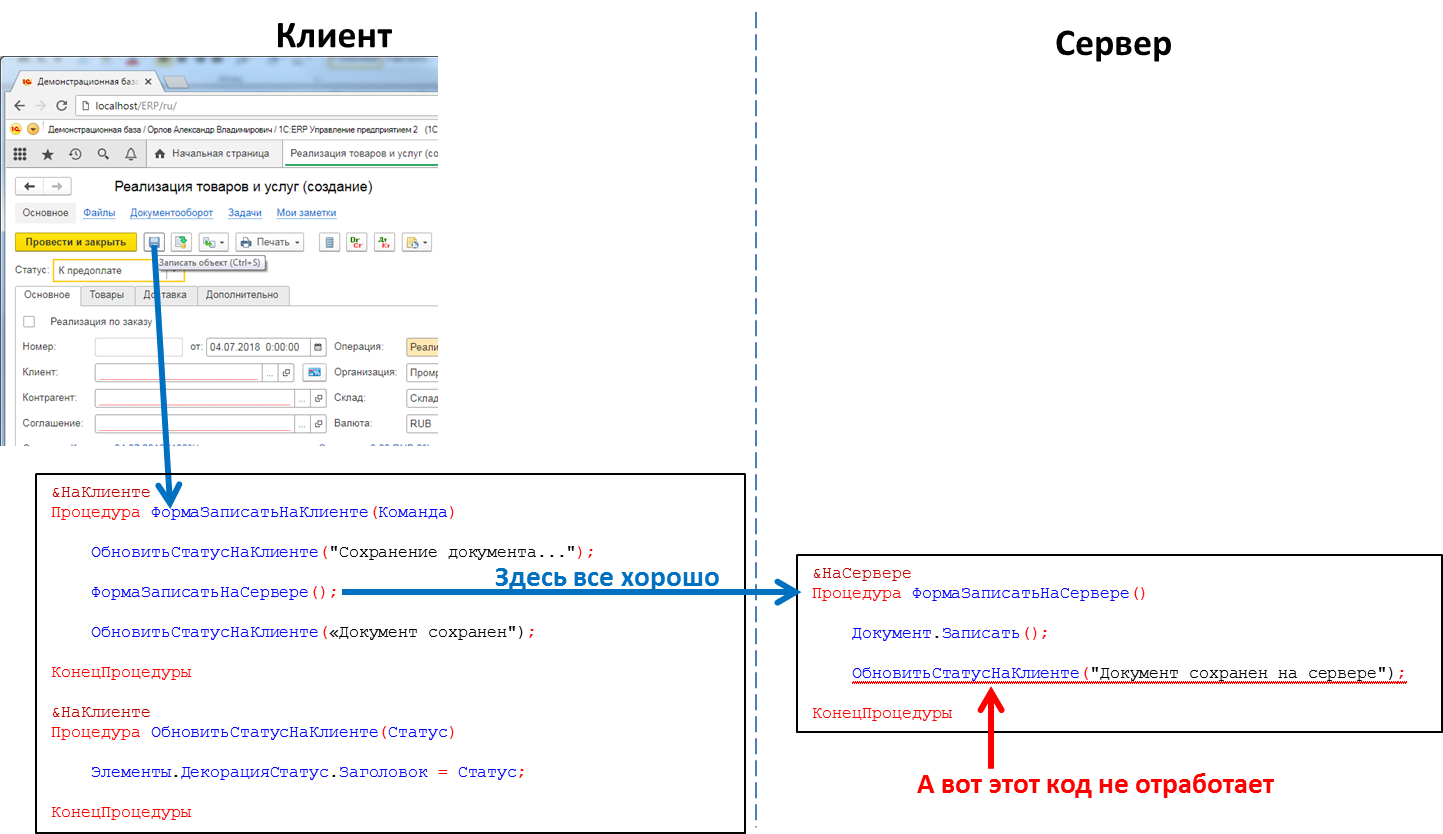 处理按钮单击的代码:可以从客户端调用服务器过程,而不能从服务器调用客户端过程
处理按钮单击的代码:可以从客户端调用服务器过程,而不能从服务器调用客户端过程这意味着如果我们要从服务器向客户端应用程序传输某些消息,例如,“长期播放”报告的形成已经结束并且可以查看该报告,则没有这种方法。 我们必须从技巧到技巧,例如从客户端代码中定期轮询服务器。 但是这种方法给系统加载了不必要的调用,并且确实看起来不太优雅。
并且还需要,例如,当
SIP电话到达时,将其通知客户端应用程序,以便它通过呼叫方的号码在交易对手数据库中找到它,并显示有关呼叫交易对手的用户信息。 或者,例如,在仓库中收到订单后,将其通知客户的客户应用程序。 通常,在许多情况下,这种机制将很有用。
实际分期
创建一个消息传递引擎。 快速,可靠,有保证的传递以及能够灵活搜索消息的能力。 基于该机制,实现在1C应用程序内部工作的Messenger(消息,视频通话)。
设计一个水平可扩展的系统。 应该通过增加节点数来关闭增加的负载。
实作
我们决定不将SV的服务器部分直接嵌入1C:Enterprise平台中,而是将其实现为单独的产品,可以从1C应用程序代码中调用其API。 这样做是出于多种原因,其主要原因是-我想使在不同的1C应用程序之间(例如,在贸易和会计办公室之间)交换消息成为可能。 不同的1C应用程序可以在1C的不同版本上运行:企业平台,不同的服务器等。 在这种情况下,将CB作为位于1C安装“侧面”的单独产品来实施是最佳解决方案。
因此,我们决定将CB作为单独的产品。 对于小型公司,我们建议使用我们在云中安装的CB服务器(wss://1cdialog.com),以避免与在本地安装和配置服务器相关的开销。 但是,大型客户可能会发现在自己的设施中安装自己的CB服务器是合适的。 我们在基于
1cFresh的基于云的SaaS产品中使用了类似的方法-该产品作为流通产品发布,供客户安装,也已部署在我们的云
https://1cfresh.com/中 。
应用程式
为了实现负载平衡和容错,我们将不部署一个Java应用程序,而是部署多个Java应用程序。 如果您需要在节点之间传输消息,请在Hazelcast中使用发布/订阅。
客户端与服务器的通信-通过websocket。 非常适合实时系统。
分布式缓存
在Redis,Hazelcast和Ehcache之间选择。 在院子里2015 Redis刚刚启动了一个新集群(太新了,太可怕了),其中有一个Sentinel带有很多限制。 Ehcache不知道如何组装到群集中(此功能稍后出现)。 我们决定尝试使用Hazelcast 3.4。
Hazelcast开箱即用地访问群集。 在单节点模式下,它不是很有用,只能用作缓存-它不知道如何将数据转储到磁盘,它丢失了一个节点-丢失了数据。 我们部署了多个Hazelcast,在它们之间备份关键数据。 缓存不是备份-这不是一个遗憾。
对于我们来说,Hazelcast是:
- 用户会话的存储库。 每次访问数据库都要花费很长时间,因此我们将所有会话都放在Hazelcast中。
- 快取。 寻找使用者个人资料-检入快取。 编写了一条新消息-将其放入缓存中。
- 通信应用程序实例的主题。 Noda生成一个事件,并将其放在Hazelcast主题中。 订阅此主题的其他应用程序节点接收并处理事件。
- 集群锁。 例如,我们在唯一键(1C数据库框架内的讨论单)上创建一个讨论:
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
检查没有频道。 他们拿起锁,再次检查,创建。 如果您在使用锁后未对其进行检查,那么此时可能还会有另一个线程被检查,并且现在将尝试创建相同的讨论-但它已经存在。 无法通过同步的或通常的Java Lock进行锁定。 通过基地-缓慢,而基地是可惜的,通过Hazelcast-您所需要的。
选择一个DBMS
我们在与PostgreSQL合作以及与该DBMS开发人员合作方面拥有丰富而成功的经验。
PostgreSQL对于集群来说并不容易-它具有
XL ,
XC和
Citus ,但是通常来说,它们不是noSQL,它们可以直接使用。 NoSQL不被视为主要的存储库,我们选择了以前从未使用过的Hazelcast就足够了。
由于您需要扩展关系数据库,因此意味着
分片 。 如您所知,在分片时,我们将数据库分为几个独立的部分,以便它们中的每一个都可以移动到单独的服务器上。
分片的第一个版本意味着能够将应用程序的每个表以不同的比例分配到不同的服务器。 服务器A上有很多消息-请让我们将此表的一部分转移到服务器B。这样的解决方案只是对过早的优化大喊大叫,因此我们决定将自己限制为多租户方法。
您可以在
Citus Data网站上
阅读有关多租户的信息。
在SV中,存在应用程序和订户的概念。 应用程序是业务应用程序(例如ERP或Accounting)及其用户和业务数据的特定安装。 订户是代表其应用程序在CB服务器中注册的组织或个人。 订户可以注册多个应用程序,并且这些应用程序可以彼此交换消息。 订户也成为我们系统中的租户。 多个订户的消息可以位于一个物理库中; 如果我们看到某个订户开始产生大量流量-我们会将其带到单独的物理基础(甚至是单独的数据库服务器)。
我们有一个主数据库,其中存储了有关所有订户数据库的位置信息的路由表。
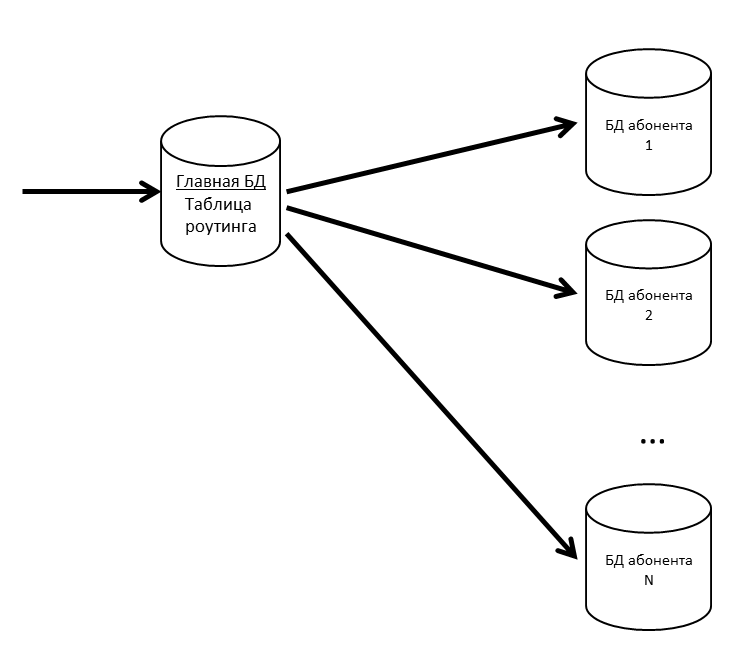
为了避免主数据库成为瓶颈,我们将路由表(以及其他经常请求的数据)保留在缓存中。
如果订户数据库开始变慢,我们将其切入内部分区。 在其他项目上,我们使用pg_pathman对大型表进行分区。
由于丢失用户消息很不好,因此我们支持带有副本的数据库。 同步副本和异步副本的组合使您在丢失主数据库的情况下很安全。 仅在主数据库及其同步副本同时发生故障的情况下,才会发生消息丢失。
如果同步副本丢失,则异步副本将变为同步。
如果主数据库丢失,则同步副本成为主数据库,异步副本成为同步副本。
Elasticsearch搜索
由于CB也是一个使者,因此您需要通过不正确的匹配快速,方便,灵活地进行搜索,同时考虑形态。 我们决定不重新发明轮子,而是使用基于
Lucene库的免费Elasticsearch搜索引擎。 我们还将Elasticsearch部署在集群(主-数据-数据)中,以消除应用程序节点出现故障时的问题。
在github上,我们找到了Elasticsearch
的俄语形态插件并使用了它。 在Elasticsearch索引中,我们存储单词(由插件定义)和N-gram的词根。 当用户输入要搜索的文本时,我们在N-gram中寻找键入的文本。 当存储在索引中时,单词“文本”将分为以下N个语法:
[那些,技术,tex,文本,文本,ek,eks,ekst,eksts,ks,kst,kst,kst,st,st,你],
并且还将保存单词“ text”的词根。 这种方法使您可以在单词的开头,中间和结尾进行搜索。
整体图片
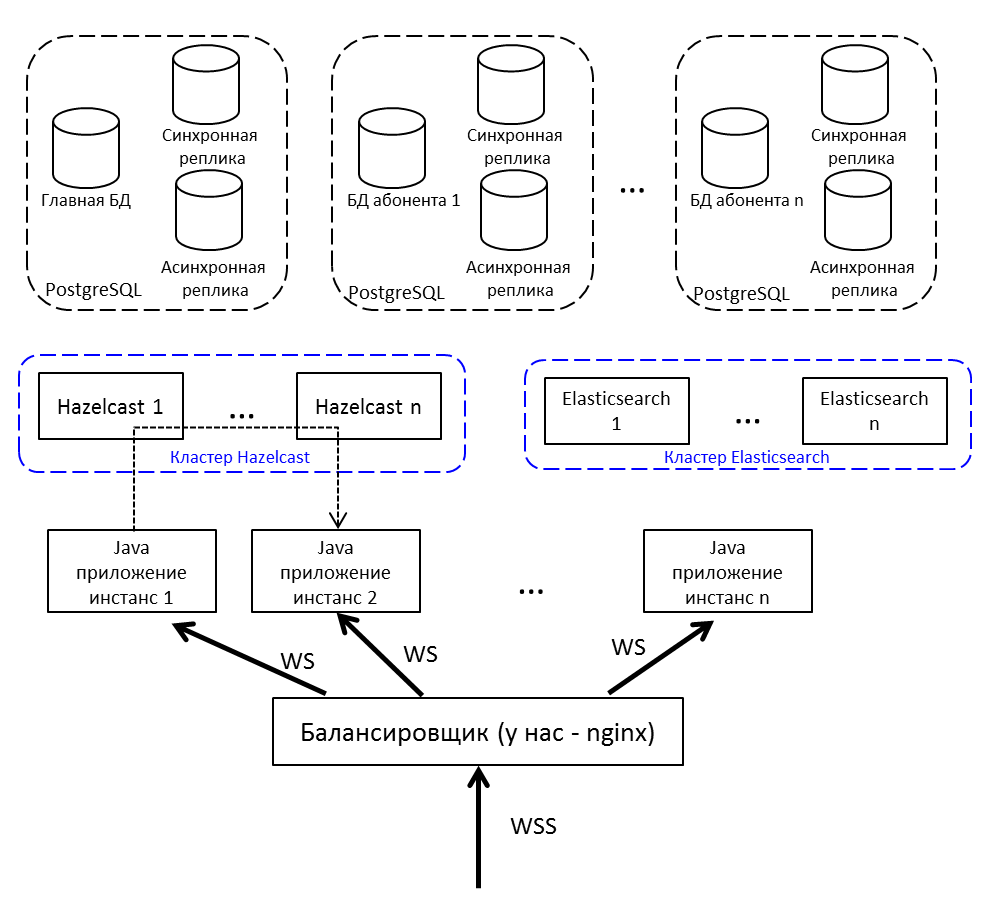
从文章开头重复图片,但有以下解释:
- 互联网平衡器; 我们有nginx,可以是任何一个。
- Java应用程序的实例通过Hazelcast相互通信。
- 对于使用Web套接字的工作,我们使用Netty 。
- 用Java 8编写的Java应用程序由OSGi捆绑软件组成。 计划-迁移到Java 10并过渡到模块。
开发与测试
在开发和测试CB的过程中,我们遇到了我们使用的产品的许多有趣功能。
负载测试和内存泄漏
每个CB版本的发布都是压力测试。 在以下情况下成功:
- 测试进行了几天,没有拒绝服务
- 关键操作的响应时间未超过舒适的阈值
- 与前一版本相比性能下降不超过10%
我们用数据填充测试库-为此,我们从生产服务器上获取有关最活跃订户的信息,将其数量乘以5(消息,讨论,用户的数量),然后进行测试。
我们以三种配置对交互系统进行负载测试:
- 压力测试
- 仅连接
- 订户注册
在压力测试期间,我们启动了数百个线程,它们不间断地加载系统:编写消息,创建讨论,获取消息列表。 我们模拟普通用户的行为(获取我的未读消息列表,写信给某人)和软件解决方案(传输具有不同配置的程序包,处理通知)。
例如,这是压力测试的一部分:
- 用户登录。
- 请求未读的讨论
- 50%的机会阅读消息
- 以50%的概率写消息
- 下一个用户:
- 以20%的概率创建了一个新的讨论。
- 随机选择他的任何讨论
- 进去
- 请求消息,用户个人资料
- 从此讨论中创建五个发给随机用户的消息。
- 讨论之外
- 重复20次
- 注销,返回脚本的开头
- 聊天机器人进入系统(从应用解决方案的代码模拟消息的交换)
- 以50%的概率创建一个新的数据交换渠道(特别讨论)
- 以50%的概率将消息写入任何现有渠道
出现“仅连接”情况是有原因的。 有一种情况:用户已连接系统,但尚未参与其中。 每个用户在早上09:00开启计算机,建立与服务器的连接,并且保持沉默。 这些家伙很危险,他们很多-从软件包中仅获得PING / PONG,但他们保持与服务器的连接(他们无法保持连接-但突然收到一条新消息)。 当大量此类用户在半小时内尝试登录系统时,该测试会重现这种情况。 它看起来像一个压力测试,但它恰好侧重于这第一个入口-这样就不会出现故障(一个人没有使用该系统,但它已经崩溃了-很难提出更糟糕的事情)。
订户注册方案起源于第一次启动。 我们进行了压力测试,并确定该系统不会因此而减慢速度。 但是用户去了,注册在超时后开始下降。 注册时,我们使用
/ dev / random ,它与系统的熵有关。 请求新的SecureRandom时,服务器无法累积足够的熵并冻结数十秒钟。 解决这种情况的方法有很多,例如:切换到不太安全的/ dev / urandom,放置一个特殊的生成熵的板,预先生成随机数并存储在池中。 我们暂时通过一个池解决了问题,但是从那时起,我们一直在运行单独的测试以注册新订户。
作为负载生成器,我们使用
JMeter 。 他不知道如何使用Web套接字;需要一个插件。 “ jmeter websocket”的搜索结果中第一个是
BlazeMeter的文章 ,其中推荐
Maciej Zaleski的
插件 。
我们决定和他一起开始。
在开始进行严格测试之后,我们几乎立即发现JMeter中出现了内存泄漏。
该插件是一个独立的大故事,它拥有176个星,在github上有132个分支。 自2015年以来,作者本人就一直没有承诺(我们在2015年采用它,然后就没有引起怀疑),关于内存泄漏的github问题,7个未关闭的请求请求。
如果您决定使用此插件进行负载测试,请注意以下讨论:
- 在多线程环境中,使用了通常的LinkedList,因此,他们在运行时收到了NPE 。 可以通过切换到ConcurrentLinkedDeque或通过同步块来解决。 他们为自己选择了第一个选项( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 )。
- 内存泄漏,断开连接不会删除连接信息( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 )。
- 在流模式下(当Web套接字在示例末尾没有关闭,但在计划中进一步使用时),响应模式( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 )不起作用。
这是github上的那些之一。 我们做了什么:
- 他们带了叉子Elyran Kogan (@elyrank)-问题1和3已修复
- 解决问题2
- 码头从9.2.14更新到9.3.12
- 将SimpleDateFormat包装在ThreadLocal中; SimpleDateFormat不是线程安全的,这导致运行时NPE
- 消除了另一个内存泄漏(断开连接后错误地关闭了连接)
然而它流了!
记忆开始不是一天,而是两天。 绝对没有时间了,他们决定运行更少的线程,而是运行四个代理。 至少一个星期就足够了。
两天过去了...
现在,记忆开始在Hazelcast耗尽。 从日志中可以明显看出,经过几天的测试,Hazelcast开始抱怨内存不足,一段时间后,群集崩溃了,节点继续单独死亡。 我们将JVisualVM连接到hazelcast,并看到了“上升锯”-他经常打电话给GC,但无法清除他的记忆。
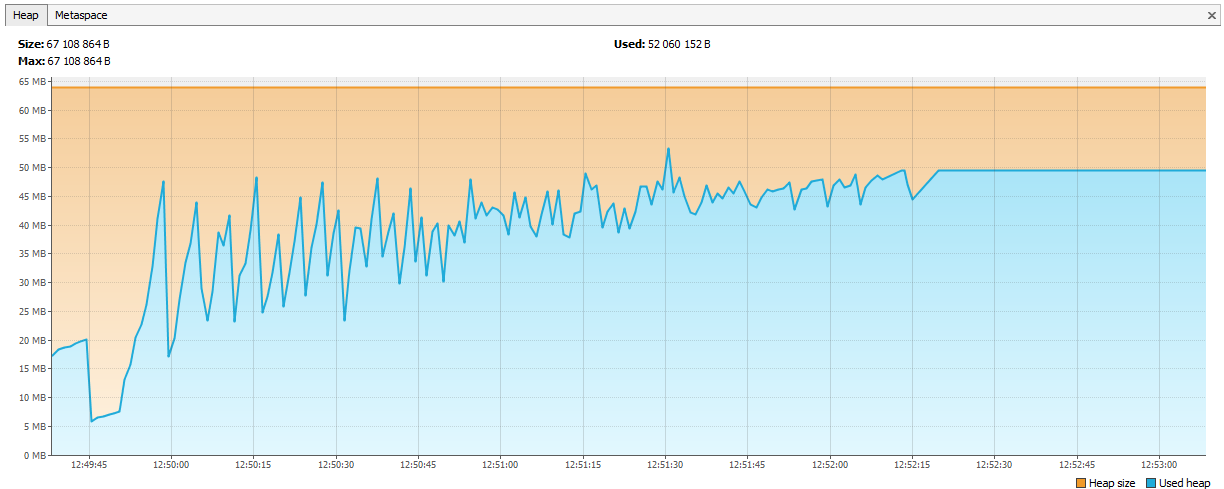
事实证明,在hazelcast 3.4中,删除map / multiMap(map.destroy())时,内存并未完全释放:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888现在,该错误已在3.5中修复,但这是一个问题。 我们使用动态名称创建了新的multiMap,并根据逻辑将其删除。 代码看起来像这样:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
致电:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
为每个订阅创建了multiMap,并在不需要时将其删除。 我们决定先启动Map <String,Set>,键将是订阅的名称,值将是会话标识符(如果需要,您可以从中获取用户ID)。
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
图表拉直。
我们从压力测试中学到了什么
- JSR223需要以常规方式编写并启用编译缓存-这要快得多。 友情链接
- Jmeter-Plugins图表比标准图表更易于理解。 友情链接
关于我们对Hazelcast的体验
Hazelcast对我们来说是一个新产品,我们从3.4.1版本开始使用它,现在我们的生产服务器具有3.9.2版本(在撰写本文时,Hazelcast的最新版本是3.10)。
ID生成
我们从整数标识符开始。 假设我们需要一个新的Long作为新实体。 序列不适合数据库,表参与分片-事实证明,在DB1中有一个消息ID = 1,在DB2中有消息ID = 1,无论是在Hazelcast中,您都不能将这样的ID放在Elasticsearch中,但是最糟糕的是如果要减少数据从两个数据库合并为一个数据库(例如,确定一个数据库足以满足这些订户)。 您可以在Hazelcast中创建多个AtomicLong,并将计数器保持在该位置,然后获取新ID的性能为增量和获取加上在Hazelcast中进行请求的时间。 但是有关Hazelcast的还有一些更理想的选择-FlakeIdGenerator。 每个客户在联系时都会获得一个ID范围,例如,第一个从1到10,000,第二个从10,001到20,000,依此类推。 现在,客户端可以独立发布新的标识符,直到发布给它的范围结束为止。 它可以快速运行,但是当您重新启动应用程序(和Hazelcast客户端)时,新的序列开始-因此出现了缺口等。 另外,开发人员还不太清楚为什么ID是整数,但是它们的区别却很大。 我们都权衡了一下,切换到UUID。
顺便说一下,对于那些想要像Twitter的人,这里有一个Snowcast库-这是在Hazelcast之上的Snowflake实现。 您可以在这里看到它:
github.com/noctarius/snowcastgithub.com/twitter/snowflake但是我们还没有达到她的手。
TransactionalMap.replace
另一个惊喜:TransactionalMap.replace无法正常工作。 这是一个测试:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
我必须使用getForUpdate编写替换:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
不仅测试常规数据结构,还测试其事务版本。 IMap可以正常工作,但是TransactionalMap消失了。
附加新的JAR,无需停机
首先,我们决定在Hazelcast中记录我们课程的对象。 例如,我们有一个Application类,我们想保存并读取它。 保存:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
我们读到:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
一切正常。 然后,我们决定在Hazelcast中建立索引以进行搜索:
map.addIndex("subscriberId", false);
并且在编写新实体时,他们开始收到ClassNotFoundException。 Hazelcast试图对索引进行补充,但对我们的课程一无所知,希望它与该课程一起使用JAR。 我们这样做了,一切正常,但是出现了一个新问题:如何在不完全停止集群的情况下更新JAR? Hazelcast在按Pod方式升级期间不会使用新的JAR。 此刻,我们决定不用索引就可以很好地生活。 毕竟,如果您将Hazelcast用作键值存储,一切都会正常吗? 不完全是 同样,这里是IMap和TransactionalMap的不同行为。 如果IMap无关紧要,则TransactionalMap会引发错误。
地图 我们写了5000个对象,然后阅读。 一切都在期待之中。
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
而且在交易中不起作用,我们得到了ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
在3.8中,出现了“用户类部署”机制。 您可以分配一个主节点并在其上更新JAR文件。
现在,我们已经完全改变了方法:我们将其序列化为JSON并将其保存在Hazelcast中。 Hazelcast不需要知道我们的类的结构,但是我们可以在不停机的情况下进行更新。 域对象的版本控制由应用程序控制。 可以同时启动该应用程序的不同版本,并且新应用程序可能会使用新字段写入对象,但是旧版本不知道这些字段。 同时,新应用程序将读取旧应用程序记录的对象,其中没有新字段。 我们在应用程序内部处理此类情况,但为简单起见,我们不更改或删除字段,我们仅通过添加新字段来扩展类。
我们如何提供高性能
到Hazelcast进行四次旅行-好,两次到数据库-不好
转到缓存中获取数据总是比在数据库中存储更好,但是您不想存储无人认领的记录。 关于缓存内容的决定,我们推迟到开发的最后阶段。 对新功能进行编码后,我们打开PostgreSQL记录所有查询(log_min_duration_statement设置为0)并运行负载测试20分钟,使用收集到的日志,诸如pgFouine和pgBadger之类的实用程序可以构建分析报告。 在报告中,我们主要查找慢速和频繁查询。 对于慢速查询,我们建立执行计划(EXPLAIN)并评估是否可以加速这种查询。 对相同输入数据的频繁请求得到了很好的缓存。 我们尝试使请求保持“扁平”状态,每个请求一张表。
运作方式
SV作为一项在线服务于2017年春季推出,并于2017年11月发布了单独的SV产品(当时处于Beta状态)。
在运行了一年多的时间里,CB在线服务的运行并未出现严重问题。 我们通过
Zabbix监控在线服务,从
Bamboo收集和部署。
CB服务器分发工具包以本地软件包的形式提供:RPM,DEB,MSI。 对于Windows Plus,我们以EXE的形式提供了一个安装程序,可在一台计算机上安装服务器,Hazelcast和Elasticsearch。 最初,我们将此安装版本称为“演示”,但现在很明显,这是最受欢迎的部署选项。