
我爱Ceph。 我已经和他一起工作了4年(0.80.x- 12.2.6 ,12.2.5)。 有时我对他如此热情,以至于我在他的公司里呆了很多晚,而不是和我的女朋友在一起。 我在该产品中遇到了各种问题,直到今天我仍然继续生活。 有时,我为轻松的决定而欣喜,有时,我梦想与开发人员见面以表达我的愤慨。 但是Ceph仍在我们的项目中使用,并且至少在我看来,它可能会用于新任务中。 在这个故事中,我将分享我们使用Ceph的经验,以某种方式表达自己对这个解决方案我不满意的话题,也许会帮助那些正在研究它的人。 大约一年前,当我带来Dell EMC ScaleIO(现在称为Dell EMC VxFlex OS)时开始发生的事件促使我撰写本文。
这绝不是Dell EMC或其产品的广告! 就个人而言,我对大型公司以及像VxFlex OS这样的黑匣子并不满意。 但是,您知道,世界上所有事物都是相对的,并且以VxFlex OS为例,从操作的角度显示Ceph是什么非常方便,我将尝试做到这一点。
参量 大约是4位数字!
Ceph服务,例如MON,OSD等 具有用于设置各种子系统的各种参数。 参数在配置文件中设置,守护程序在启动时读取它们。 可以使用“注入”机制方便地随时更改某些值,如下所述。 如果忽略了存在数百个参数的那一刻,一切将几乎都是超级:
锤子:
> ceph daemon mon.a config show | wc -l 863
发光:
> ceph daemon mon.a config show | wc -l 1401
事实证明,两年内有500个新参数。 通常,参数化很酷,理解这个列表的80%并不容易。 据我估计,该文档描述了约20%的内容,在某些地方还不清楚。 必须在项目的github或邮件列表中找到对大多数参数含义的理解,但这并不总是有用的。
这是我最近感兴趣的几个参数的示例,我在一个Ceph-gadfly的博客中找到了它们:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
本着最佳实践的精神编写代码注释。 好像,我理解这些单词,甚至大致理解它们的含义,但它不会给我带来什么。
或者在这里:Luminous中的osd_op_threads消失了,只有源代码帮助找到了新名称: osd_peering_wqthreads
我也喜欢特别全面的选择。 这家伙显示增加rgw_num _rados_handles是好的 :
另一个花花公子认为> 1是不可能的,甚至是危险的 。
我最喜欢的事情是,当初学者在其博客文章中提供配置示例时,所有参数都是(从我看来)从同类型的另一博客中无意识地复制的,因此,除了代码作者从那里徘徊以外,一堆没人知道的参数配置到配置。
我也只是疯狂地对待他们在Luminous中所做的事情。 有一个超酷的功能-即时更改参数,而无需重新启动进程。 例如,您可以更改特定OSD的参数:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
或用'*'代替12,所有OSD上的值都会更改。 真的很酷。 但是,就像在Ceph中一样,这是用左脚完成的。 Bai设计并非所有参数值都可以随时更改。 更准确地说,可以设置它们,并且它们将在输出中显示为更改,但是实际上,只有少数几个被重新读取和重新应用。 例如,您必须重新启动进程才能更改线程池的大小。 因此,团队执行者了解以这种方式更改参数是没有用的-他们决定打印一条消息。 你好
例如:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
big昧。 实际上,在注射后可以去除池。 也就是说,此警告与此参数无关。 好的,但是仍然有数百个参数,包括非常有用的参数,它们也会发出警告,并且无法检查其实际适用性。 目前,我什至无法通过代码了解注入后应用了哪些参数,哪些没有应用。 为了提高可靠性,您必须重新启动服务,这很令人生气。 激怒是因为我知道有注入机制。
VxFlex OS呢? 诸如MON(在VxFlex中为MDM),OSD(在VxFlex中为SDS)之类的类似过程也具有配置文件,其中包含许多参数。 没错,他们的名字也没说什么,但是好消息是我们从未像Ceph那样求助于他们。
技术债务
当您与Ceph接触到当今最相关的版本时,一切似乎都很好,并且您想写一篇积极的文章。 但是,当您与他一起生活在0.80版的产品中时,一切似乎并不那么乐观。
在Jewel之前,Ceph进程以root用户身份运行。 Jewel决定他们应该从用户“ ceph”那里工作,这需要更改Ceph服务使用的所有目录的所有权。 看来这吗? 想象一下一个OSD服务于2 TB全容量SATA磁盘。 因此,以完全磁盘利用率并行(到不同的子目录)使用这样的磁盘,需要花费3-4个小时。 想象一下,例如,您有300个这样的磁盘。 即使更新节点(立即拥有8到12个磁盘),也会获得相当长的更新,其中群集将具有不同版本的OSD,并且在更新服务器时,一个数据副本更少。 总的来说,我们认为这是荒谬的,重建了Ceph软件包并让OSD以root身份运行。 我们决定在输入或更换OSD时将其转移给新用户。 现在我们每月要更改2-3个驱动器,并增加1-2个驱动器,我认为我们可以在2022年之前解决这个问题)。
粉碎可调
CRUSH是Ceph的心脏,一切都围绕着它。 这是一种算法,通过该算法,可以以伪随机方式选择数据位置,并且借助该算法,与RADOS群集一起使用的客户端将可以找到需要的数据(对象)存储在哪个OSD上。 CRUSH的关键功能是不需要任何元数据服务器,例如Lustre或IBM GPFS(现为Spectrum Scale)。 CRUSH允许客户端和OSD直接相互交互。 当然,尽管很难比较原始的RADOS对象存储和文件系统(以我为例),但是我认为这个想法很明确。
反过来,CRUSH可调参数是影响CRUSH操作的一组参数/标志,至少在理论上使其更有效。
因此,当从Hammer升级到Jewel时(自然测试),出现警告,说可调参数配置文件的参数对于当前版本(Jewel)不是最佳的,建议将配置文件切换为最佳配置。 总的来说,一切都很清楚。 坞站说这很重要,这是正确的方法,但是也有人说,在进行数据交换之后,会有10%的数据被拒绝。 10%-听起来并不可怕,但我们决定对其进行测试。 对于集群来说,它的容量大约是产品的10倍,并且每个OSD的PG数量相同,并充满了测试数据,因此产生了60%的反抗! 例如,想象一下,如果有100TB的数据,则60TB的数据将在OSD之间移动,而这正是客户端负载不断增加,要求延迟的原因! 如果我还没有说的话,我们提供s3,即使在晚上,rgw的负载也不会少很多,其中静态网站上的负载分别是8和4。 总的来说,我们认为这不是我们的方法,特别是因为在我们尚未在产品中使用的新版本上进行这样的重建至少太乐观了。 另外,我们有很大的存储桶索引,它们的重建非常差,这也是延迟切换配置文件的原因。 关于指数将分别低一些。 最后,我们只是删除了警告,并决定稍后再返回。
而且在测试中切换配置文件时,CentOS 7.2内核中的cephfs-clients掉了下来,因为它们无法使用新配置文件的更新哈希算法。 我们不在产品中使用cephfs,但是如果我们以前这样做,这将是不切换配置文件的另一个原因。
顺便说一句,码头说如果叛乱期间发生的事情不适合您,您可以回滚个人资料。 实际上,在全新安装Hammer版本并升级到Jewel之后,配置文件如下所示:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
重要的是,它是“未知的”,如果您尝试通过将其切换为“旧版”(如坞站中所述)或什至是“锤子”来停止重建,那么反叛不会停止,它将按照其他可调参数继续进行,而不是“最佳。” 通常,需要对所有内容进行彻底检查和再次检查,ceph是不受信任的。
粉碎权衡
如您所知,这个世界上的所有事物都是平衡的,缺点对所有优点都适用。 CRUSH的缺点是,即使在相同重量的情况下,PG在不同OSD之间的分布也不均匀。 另外,没有什么可以阻止不同的PG以不同的速度增长,而散列函数将下降。 具体地说,尽管它们具有相同的尺寸和相应的重量,但OSD的利用率范围为48-84%。 我们甚至尝试使服务器的重量相等,但是,仅此而已,就是我们的完美主义者。 无花果在磁盘上的IO分布不均匀这一事实,最糟糕的是,当您达到集群中至少一个OSD的完整状态(95%)时,整个记录将停止并且集群变为只读状态。 整个集群! 群集仍然充满空间也没关系。 一切,最后,出来! 这是CRUSH的体系结构功能。 假设您正在休假,某些OSD打破了85%的标记(默认情况下为第一个警告),并且您有10%的库存以防止记录停止。 积极进行录音的10%并不是很多/很长。 理想情况下,采用这种设计,Ceph需要值班人员在这种情况下可以遵循准备好的说明。
因此,我们认为这意味着不平衡集群中的数据,因为 一些OSD接近接近满刻度(85%)。
有几种方法:
最简单的方法是有点浪费并且不是很有效,因为 数据本身可能不会从拥挤的OSD中移走,或者移动可以忽略不计。
这导致所有更高存储桶(CRUSH术语)层次结构,OSD服务器,数据中心等的权重发生变化。 结果是数据的移动,包括不是来自必要OSD的数据。
我们尝试减少了一个OSD的权重,在填充了另一个OSD的数据后,我们减少了它,然后减少了第三个,我们意识到我们将长期玩这个游戏。
这是通过调用“ ceph osd按使用权重调整”来完成的。 这导致所谓的OSD调整重量发生变化,并且较高铲斗的重量不变。 这样一来,数据就可以在一台服务器的不同OSD之间进行平衡,而不会超出CRUSH存储桶的限制。 我们真的很喜欢这种方法,我们考察了空运行将对产品进行哪些更改并对其执行了哪些操作。 一切都很好,直到重新筹集资金到中间为止。 再次使用谷歌搜索,阅读新闻稿,尝试不同的选择,最后发现停止是由于上述配置文件中缺少一些可调参数导致的。 我们再次陷入技术债务。 结果,我们沿着添加磁盘和最无效的重建的道路前进。 幸运的是,我们仍然需要这样做,因为 计划以足够的容量切换CRUSH配置文件。
是的,我们知道作为mgr一部分的平衡器(发光的和更高的),该平衡器旨在通过在晚上(例如)晚上在OSD之间移动PG来解决数据分布不均的问题。 但是,即使在当前的《模仿》中,我仍未听到对其作品的正面评价。
您可能会说技术债务纯粹是我们的问题,我可能会同意。 但是在Ceph投入使用的四年中,我们仅记录了一次停机时间s3,该过程持续了整整1个小时。 然后,问题不在RADOS中,而在RGW中,RGW键入了默认的100个线程,结果死机,大多数用户无法满足请求。 它仍然在锤子上。 在我看来,这是一个很好的指标,这是由于我们没有突然行动,而对Ceph的一切都持怀疑态度,这一事实得以实现。
野生GC
如您所知,直接从磁盘删除数据是一项艰巨的任务,在高级系统中,删除被延迟或根本没有完成。 Ceph也是一个高级系统,对于RGW,在删除s3对象时,不会立即从磁盘上删除相应的RADOS对象。 RGW将s3对象标记为已删除,并且单独的gc流直接从RADOS池中删除对象,并因此从磁盘推迟。 更新为Luminous后,gc的行为发生了显着变化,尽管gc参数保持不变,但它开始更加积极地工作。 用这个词来形容,我的意思是,我们开始看到gc在对服务的外部监视进行延迟延迟的工作。 这伴随着rgw.gc池中的IO高 但是,我们面临的问题不仅仅是IO。 当gc运行时,会生成许多形式的日志:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
其中开头的0是打印此消息的日志记录级别。 实际上,没有任何地方可以将日志记录降低到零以下。 结果,大约1 GB的日志,我们在几个小时内生成了一个OSD,如果ceph节点不是无盘的,一切都会很好的。我们通过PXE将OS直接加载到内存中,并且不使用本地磁盘或NFS,NBD作为系统分区(/)。 事实证明,无状态服务器。 重新引导后,整个状态将由自动化滚动。 我将在另一篇文章中以某种方式描述它是如何工作的,现在重要的是为“ /”分配6 GB的内存,其中〜4通常是可用的。 我们将所有日志发送到Graylog,并使用比较激进的日志轮换策略,通常不会遇到磁盘/ RAM溢出的任何问题。 但是我们还没有做好准备,因为有12个OSD,“ /”服务器很快就装满了,服务生不能按时响应Zabbix中的触发器,并且由于无法写日志,OSD刚开始停止。 结果,我们降低了gc的强度,票证没有开始,因为 它已经存在了,我们在cron中添加了一个脚本,其中当超过一定数量时,我们强制OSD日志截断,而无需等待logrotate。 顺便说一句, 增加了测井水平 。
展示位置组和可扩展性
我认为,PG是最难理解的抽象。 需要PG才能使CRUSH更有效。 PG的主要目的是对对象进行分组,以减少资源消耗,提高生产力和可伸缩性。 直接,单独寻址而不将它们组合到PG中将非常昂贵。
PG的主要问题是确定新池的数量。 从Ceph博客:
“为您的集群选择正确数量的PG有点荒唐可笑,而且是可用性的噩梦。”
这总是非常特定于特定的安装,并且需要大量的思考和计算。
关键建议:
- OSD上的PG太多是不好的;在重新平衡/恢复期间,用于维护和刹车的资源将超支。
- OSD上的PG很少损坏,性能会受到影响,并且OSD的填充不均匀。
- PG的数字必须是2的倍数。这将有助于获得“粉碎的力量”。
在这里,它燃烧着我。 PG的数量或对象数量不受限制。 服务一个PG需要多少资源(实际数量)? 它取决于大小吗? 它是否取决于此PG的副本数量? 如果我有足够的内存,快速的CPU和良好的网络,应该洗个澡吗?
您还需要考虑集群的未来增长。 PG号不能减少-只能增加。 同时,不建议这样做,因为从本质上讲,这意味着将PG的一部分拆分为新的和狂野的重建。
“增加池的PG计数是Ceph群集中影响最大的事件之一,如果可能,应避免在生产群集中使用。”
因此,如果可能,您需要立即考虑未来。
一个真实的例子。
一个由3个服务器组成的群集,每个服务器具有14x2 TB OSD,总共42个OSD。 副本3,有用的地方〜28 TB。 要在S3下使用,您需要计算数据池和索引池的PG数量。 RGW使用更多的池,但是这两个是主要池。
我们进入PG计算器 (有一个这样的计算器),考虑到OSD上推荐的100 PG,我们只能得到1312 PG。 但是,并非一切都那么简单:我们有一个介绍性的集群-该集群肯定会在一年之内增长三倍,但铁将在稍后购买。 我们将“每个OSD的目标PG”增加了三倍,达到300,得到4480 PG。
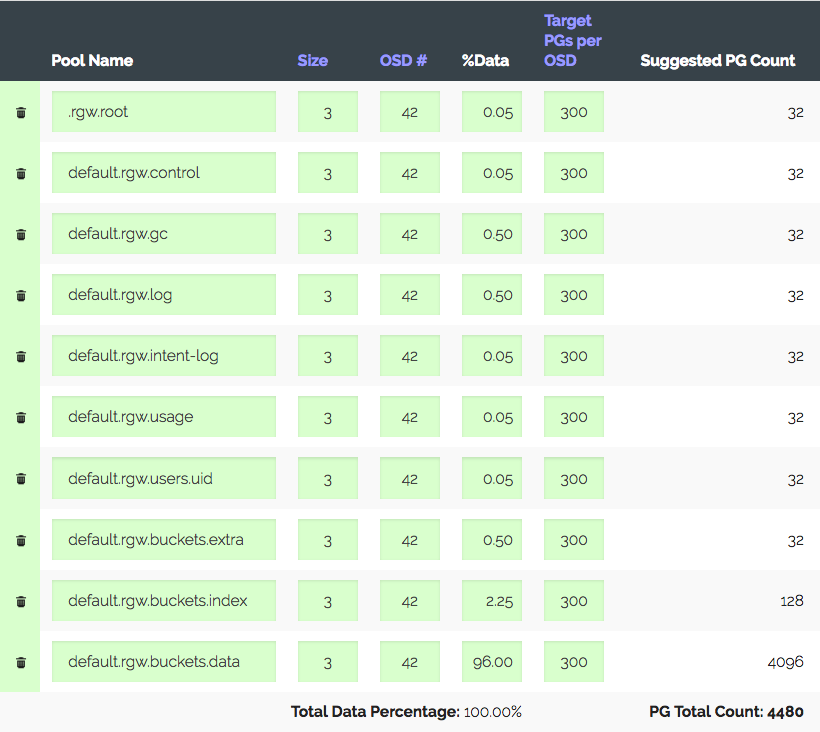
设置相应池的PG数量-我们收到警告:每个OSD的PG太多...到达。 在OSD上获得了约300 PG,上限为200(发光)。 顺便说一句,以前是300。 最有趣的是,不允许所有不必要的PG对等,这不仅仅是警告。 结果,我们认为我们在做所有正确的事情,提高极限,关闭警告,然后继续前进。
另一个真实的例子更有趣。
S3,可用容量为152 TB,1.81 TB时为252 OSD,在OSD上约为105 PG。 集群逐渐增长,一切都很好,直到我们国家的新法律出台为止,都需要增长到1 PB,即+〜850 TB,同时您还需要保持性能,这对于S3来说是相当不错的。 假设我们使用6 TB(5.7实)TB的磁盘,并考虑到副本3,则获得+ 447 OSD。 考虑到当前的OSD,我们将获得699个OSD,每个OSD具有37个PG,并且如果考虑到不同的权重,原来的OSD仅具有十几个PG。 所以你告诉我这将如何容忍? 综合衡量具有不同数量PG的群集的性能非常困难,但是我进行的测试表明,要获得最佳性能,必须从50 PG到2 TB OSD。 那进一步的增长又如何呢? 在不增加PG数量的情况下,可以转到PG到OSD 1:1的映射。 也许我听不懂?
是的,您可以使用所需数量的PG为RGW创建新池,并将单独的S3区域映射到该池。 甚至在附近建立新的集群。 但是您必须承认这些都是拐杖。 事实证明,由于其概念PG具有保留,它似乎可以很好地扩展Ceph。 您要么不得不忍受残酷的折磨,然后为增长做准备,要么在某个时候重建集群中的所有数据,或者对性能进行评分,并接受发生的事情。 或经历全部。
我很高兴Ceph的开发人员了解 PG对用户来说是一个复杂而多余的抽象,他最好不了解它。
“在Luminous中,我们已经采取了重大步骤,最终消除了将群集驱动到沟渠中的最常用方法之一,并且期待着我们的目标是最终完全隐藏PG,以使它们不再是大多数用户必须了解或了解的东西。考虑“。
在vxFlex中,没有PG或任何类似物的概念。 您只需将磁盘添加到池中就可以了。 依此类推,直到16 PB。 想象一下,无需计算任何内容,这些PG的状态也不会堆积,整个增长过程中磁盘都被统一处理。 因为 磁盘作为整体提供给vxFlex(其上没有文件系统),无法评估完整性,也完全没有这样的问题。 我什至不知道该如何传达给您。
“需要等待SP1”
另一个故事是“成功”。 如您所知,RADOS是最原始的键值存储。 在RADOS之上实现的S3也是原始的,但仍具有更多功能。 , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
性能表现
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
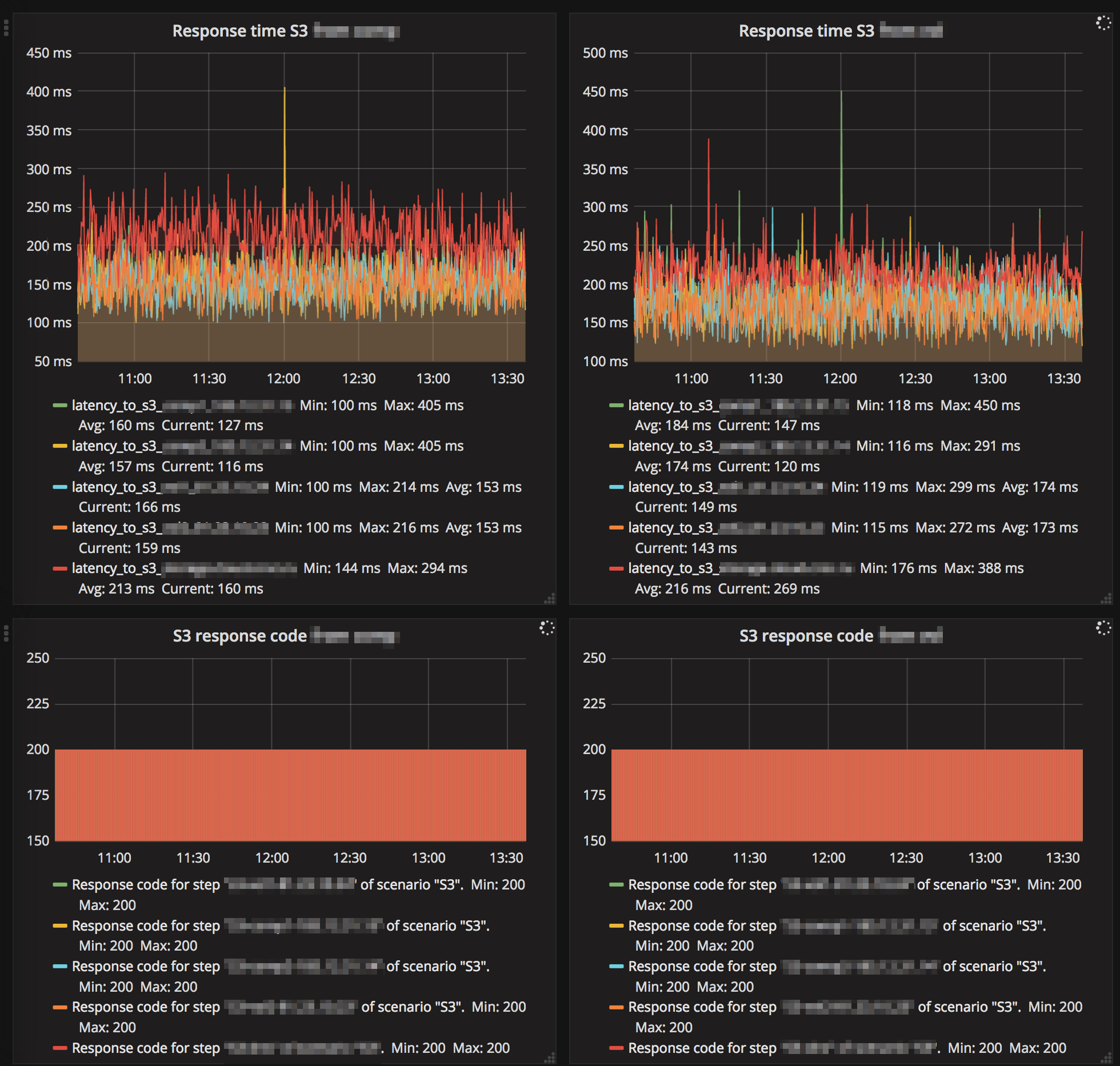
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
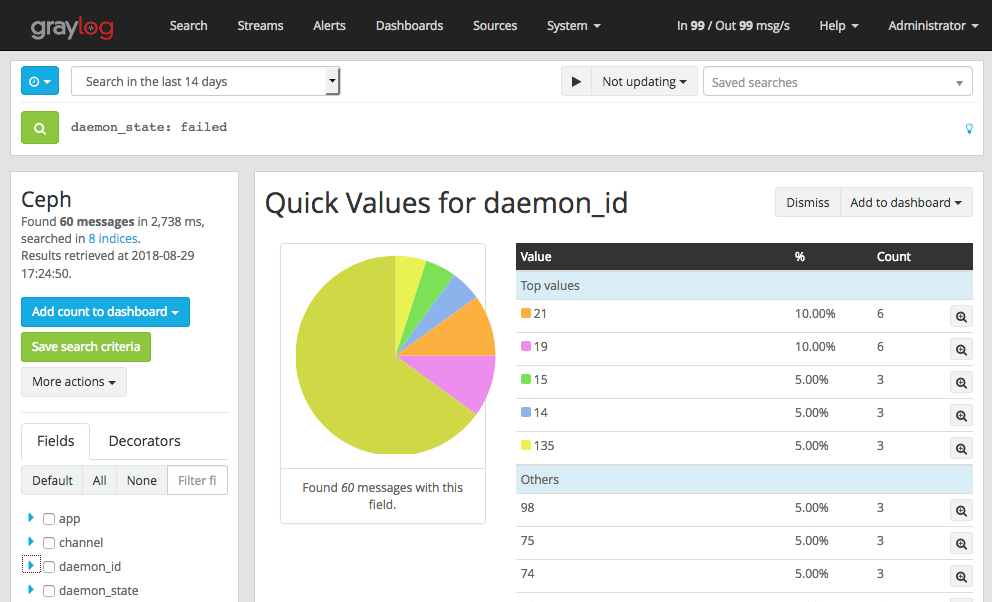
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
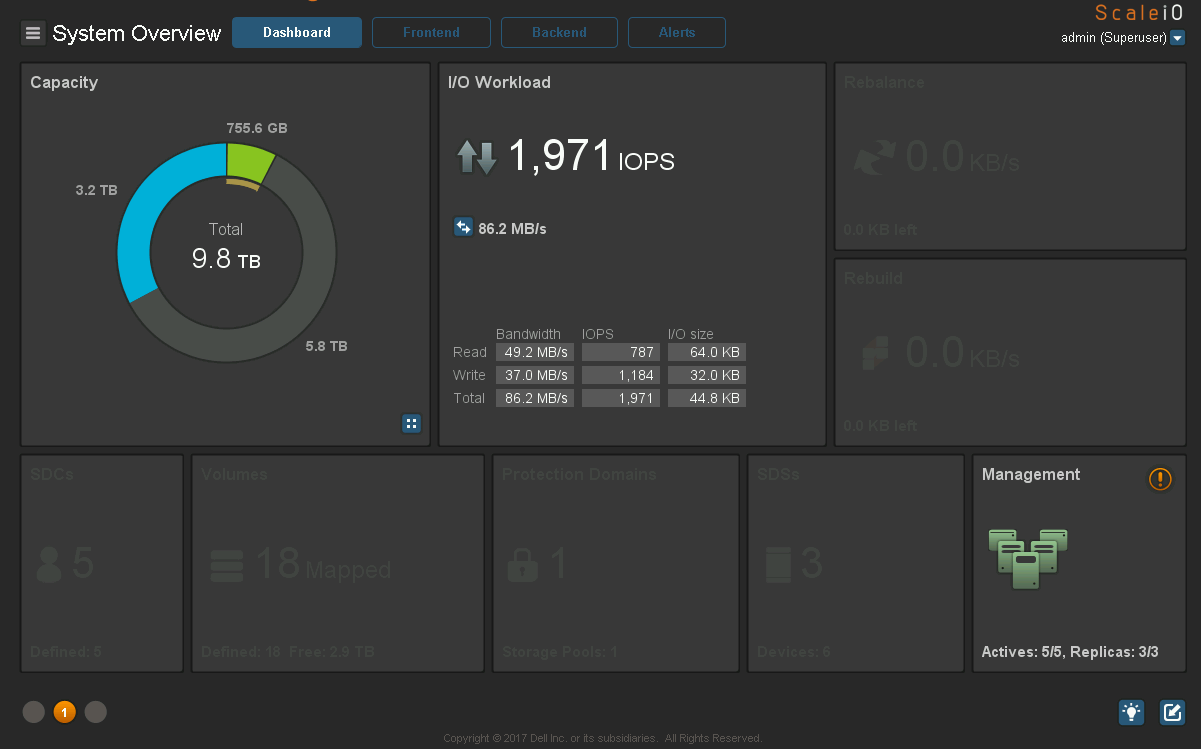
:

IO :
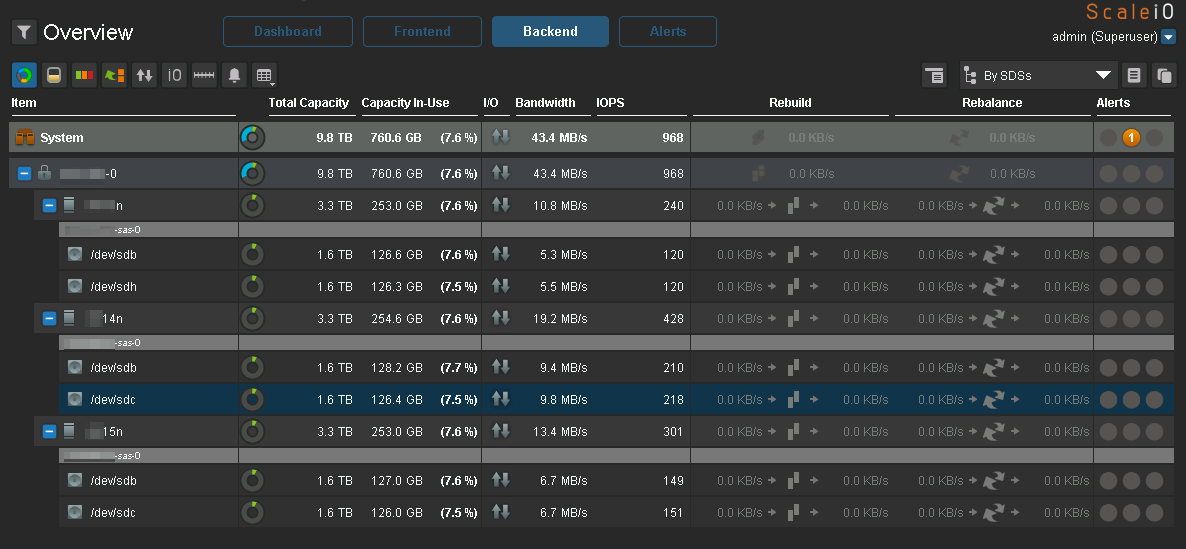
IO, Ceph.
:
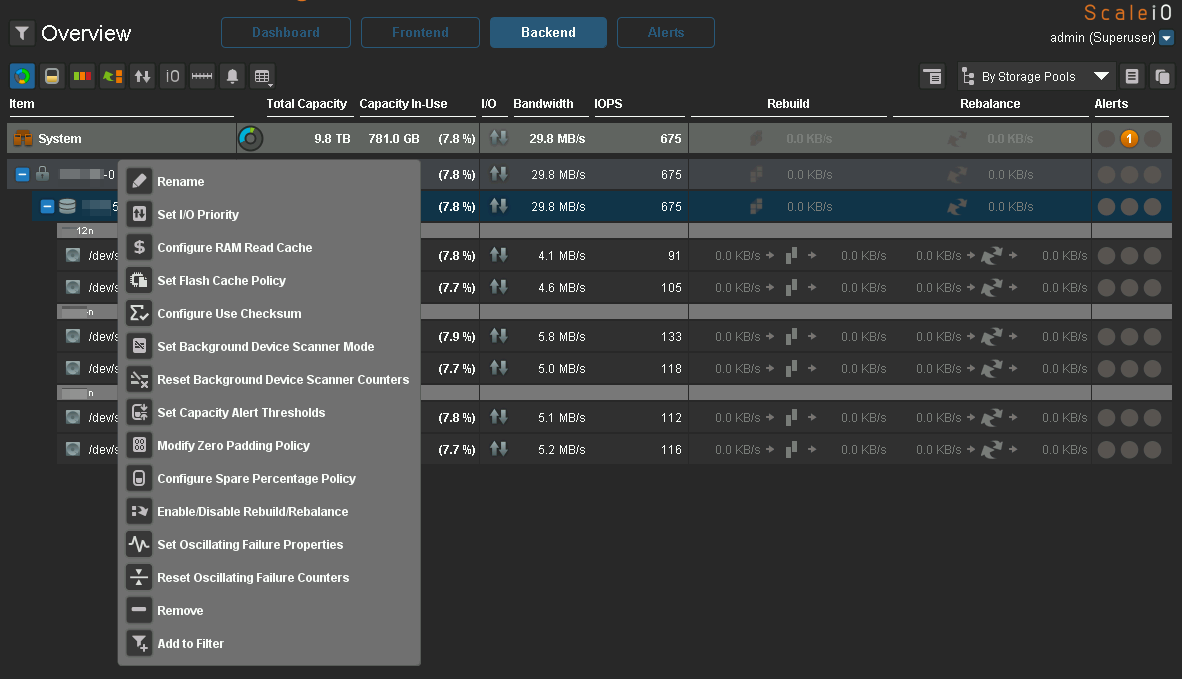
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
结论
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!