
使用神经网络对人进行细分不会让任何人感到惊讶。 有很多应用程序,例如Sticky Ai , Teleport Live , Instagram ,它们使您可以在手机上实时执行如此困难的任务。
因此,假设地球正面临着外星文明。 并且来自半人马座阿尔法星系的外星人,收到了开发新产品的要求。 他们真的很喜欢Sticky Ai应用程序,该应用程序使您可以裁掉人并制作贴纸,因此他们希望将该应用程序移植到星际市场。
不幸的是,我们在分割应用程序中使用的神经网络仅在人类图像上受到训练,因此,它在外星人上的效果很差。 迫切需要通过外星人来扩展我们的数据集。
向外星人索要数千张照片后,我们开始加价。
挑战:
有外星人图像,您需要为每个图像创建一个黑白蒙版,其中外星人将以白色突出显示,背景以黑色突出显示。
解决方案:
首先,您需要为自由职业者制作一个ToR,以布置图像。 由于我们需要非常高的质量,因此我们将在Photoshop中标记图像。
可以以10页的PDF文档的形式编写TOR,但是:
- 自由职业者通常不阅读TK,而是滚动浏览。
- 在文档中,很难详细描述如何正确,快速地进行标记的算法。
- 编译文档本身需要很多时间。
因此,现在我们已经完全放弃了PDF文档形式的TK,我们在
一种培训视频。 经过这样的创新:
- 自由职业者的生产力提高了一倍(因为视频显示了最快,最优化的标记方式)。
- 自由职业者提出的问题减少了3倍(因为视频显示了每个步骤)。
- 原来,加价成本降低了2倍(因为一个小时的工作价格没有变化,但自由职业者的加价速度却快了两倍)。
应特别注意Photoshop中的标记方法。 Photoshop是一个非常灵活的程序,可以用不同的方式完成标记。 因此,建议事先确定所需的标记质量,研究不同的选择工具,将它们相互比较,然后选择图像处理最快的工具。
一个例子:
有两种突出显示方式:
方法A每张图像需要5分钟。
方法B每个图像花费10分钟。
使用方法A,自由职业者每小时可标记12张图像,因此每张图像的价格为150/12 = 12.5卢布。
使用方法B,自由职业者每小时标记6张图像,因此每张图像的价格为150/6 = 25卢布。
因此,我们找到了突出显示和录制视频说明的最佳方法,下一步是什么?
仍然找到自由职业者。 有许多自由职业者交流,例如Fl.ru , Weblancer , Freelans.ru 。
但是最近,我们一直在使用WORK-ZILLA自由职业者,因为:
- 有相当便宜的劳动力。
- 很多表演者。
- 用户友好的界面,用于创建任务。
要创建任务:
我们注册,补充余额,单击“提交任务”,选择“设计”->“照片处理”。

填写标题和说明,确定完成任务的时间。 处理了几个外星人后,我注意到每个图像平均需要4分钟。 即 每小时输出15张图片,因此我们将一张图片的价格设置为150/15 = 10卢布。

作业发布后,表演者立即开始提供服务。
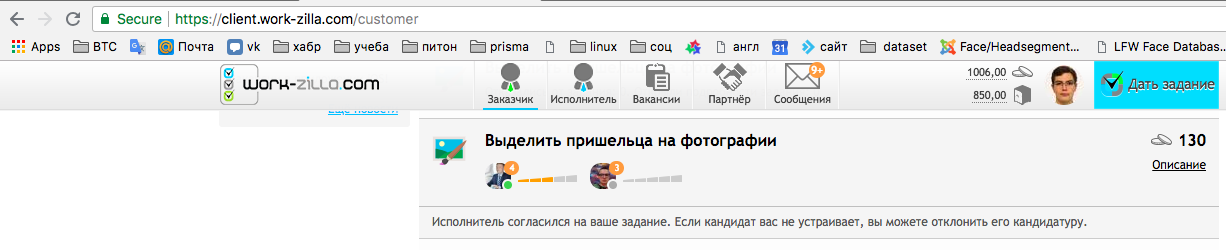
我们根据评论经历的个人资料图片选择最漂亮的一个,并确认是表演者,发布图片。 如您所见,我们花了不到15分钟的时间找到了一名自由职业者。
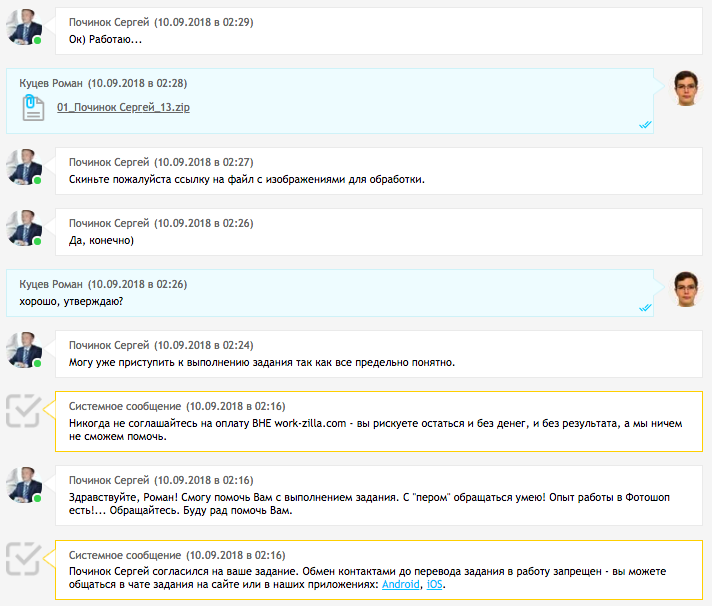
第二天早上,表演者派了份工作。
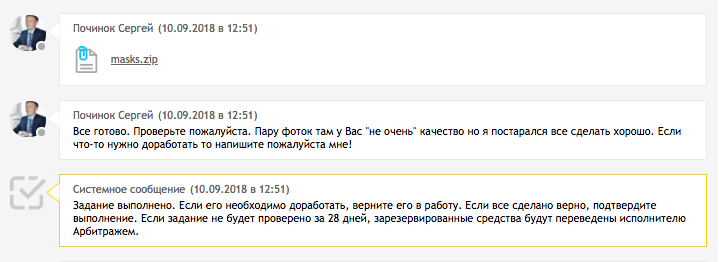
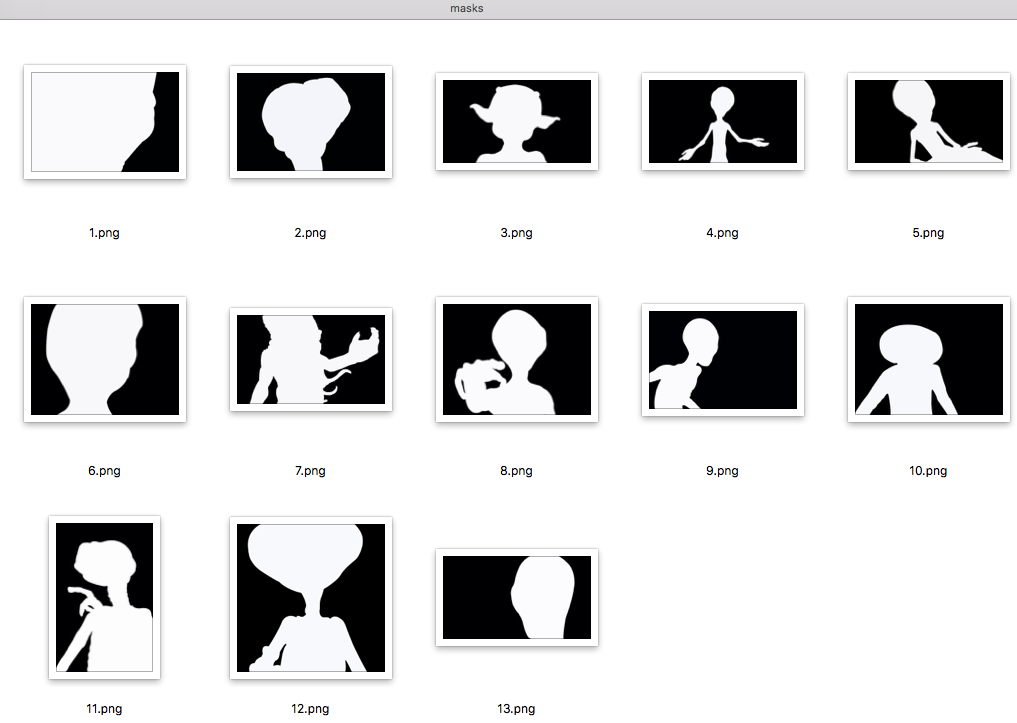
现在如何检查?
当然,您可以在Photoshop中打开每个图像并查看所有内容的突出程度,但是如果20个人同时为您工作并且每个人每天发送40张图像该怎么办?
自动化! 为了便于验证,我在python上实现了以下脚本:
import cv2 import numpy as np import os import shutil from __future__ import print_function from tqdm import tqdm_notebook as tqdm
脚本采用原始图像,蒙版并对其进行拼贴,包括原始图像,切出的背景和切出的外星人。
在查看图像之后,我们注意到艺术家没有很好地选择一张图像。

请更正图像。
自由职业者纠正了我们的所有评论后,我们确认工作并向自由职业者写感谢信。
结果:
假设您需要2,000张外来图像来训练神经网络。
然后,要收集这样的数据集,您将只需要花费2000 x 10 = 20,000卢布,并且如果考虑到一个自由职业者平均每天处理40张图像并且有10个人在标记上工作,那么创建一个数据集将花费2000 /(10 x 40)= 5天。
聚苯乙烯
当然,我们还没有遇到过外星人,Prisma AI团队都不会对外星人进行细分,但是在此示例中,我想向您展示如何为任何任务创建自己的数据集,无论是无人驾驶车辆还是行人检测,都非常简单且具有成本效益确定卫星图像中的森林。