使用Struct类型和只读修饰符有时会导致性能下降。 今天,我们将讨论如何使用一个开源代码分析器-ErrorProne.NET避免这种情况。

您可能从我以前的出版物中知道“
C#中的'in'-修饰符和只读结构 ”(“
C#中的修饰符和C#中的只读结构”)和“ C#中
的ref 局部变量 和ref返回的性能陷阱 ”((使用局部变量和带有ref修饰符的返回值时的性能陷阱)),使用结构要比看起来困难得多。 撇开可变性的问题,我注意到带有只读修饰符(只读)的结构在只读上下文中的行为有很大不同。
假定在需要高性能的编程脚本中使用了结构,并且要有效地使用它们,您应该对编译器生成的各种隐藏操作有所了解,以确保结构保持不变。
这是您应记住的简短警告列表:
- 使用按值传递或返回的大型结构可能会导致关键程序执行路径上的性能问题。
xY会导致创建x的保护副本:
x是一个只读字段;x类型是没有只读修饰符的结构;Y不是字段。
如果x是带有in修饰符的参数,带有ref readonly修饰符的局部变量或调用通过只读引用返回值的方法的结果,则相同的规则也适用。
这里有一些规则要牢记。 而且,最重要的是,依赖于这些规则的代码非常脆弱(也就是说,对代码所做的更改会立即在代码或文档的其他部分产生重大更改-大约Transl。)。 有多少人会注意到替换为
public readonly int X ; 在
public int X { get; } public int X { get; }在没有readonly修饰符的常用结构中是否会显着影响性能? 还是很容易看到使用in修饰符而不是按值传递参数会降低性能? 当在循环中使用参数的in属性,并且每次迭代都创建保护性副本时,这实际上是可能的。
这种结构的特性从字面上吸引了分析仪的发展。 听到了电话。 认识
ErrorProne.NET-一组分析器,可通知您有关在使用结构时更改程序代码以改善其设计和性能的可能性。
带有消息输出“使X结构成为只读”的代码分析
避免在使用结构时出现细微错误和对性能造成负面影响的最佳方法是在可能的情况下将其设置为只读。 结构声明中的readonly修饰符清楚地表达了开发人员的意图(强调结构是不可变的),并有助于编译器避免在上面提到的许多上下文中产生安全副本。
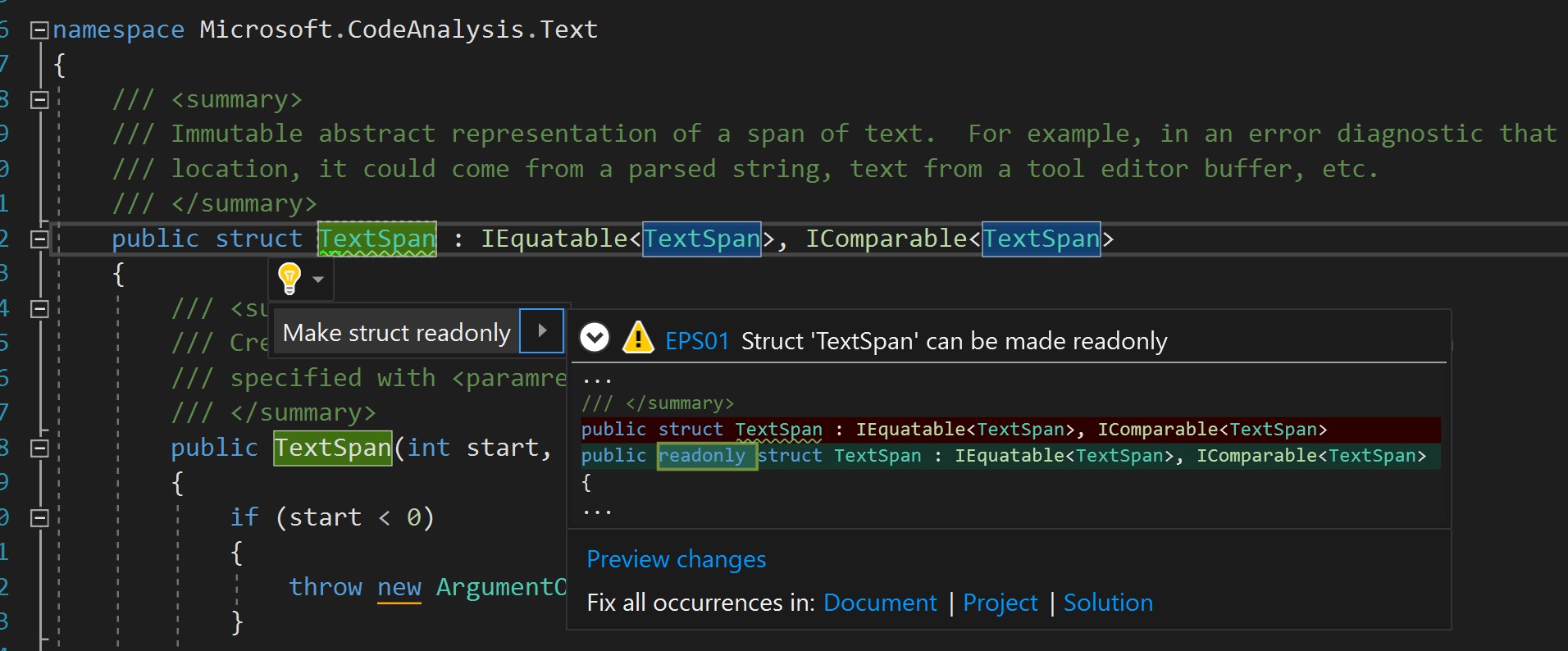
声明只读结构不会违反代码完整性。 您可以在批处理模式下安全地运行修复程序(修复代码的过程),并将整个软件解决方案的所有结构声明为只读。
ref只读修改器的友好性
下一步是评估使用新功能(在修饰符,本地读取变量,引用变量等中)的安全性。 这意味着编译器不会创建会降低性能的隐藏保护性副本。
可以考虑三种类型的类型:
- ref只读友好结构,其使用永远不会导致保护性副本的创建;
- 对只读不友好的结构,在只读的上下文中使用它总是导致保护性副本的创建;
- 中性结构-取决于只读上下文中使用的成员,其使用可能会引起保护性复制的结构。
第一类包括只读结构和POCO结构。 如果结构是只读的,则编译器将永远不会生成保护性副本。 在只读上下文中使用POCO结构也是安全的:对字段的访问被认为是安全的,并且不会创建保护性副本。
第二类是没有只读修饰符的结构,其中不包含开放字段。 在这种情况下,在只读上下文中对公共成员的任何访问都将导致创建保护性副本。
最后一类是具有公共或内部字段以及公共或内部属性或方法的结构。 在这种情况下,编译器会根据所使用的成员来创建保护性副本。
如果使用in修饰符传递了“不友好的”结构,并将其存储在局部变量ref只读中,则这种分隔有助于立即生成警告。

如果将“不友好的”结构用作只读字段,则分析器不会显示警告,因为在这种情况下没有其他选择。 in和ref只读修饰符经过专门设计,可避免创建冗余副本。 如果这些修饰符的结构“不友好”,则您还有其他选择:按值传递参数或将副本保存在局部变量中。 在这方面,只读字段的行为有所不同:如果要使类型不可变,则必须使用这些字段。 请记住:代码必须清晰,优美,并且仅次于速度。
密件抄送分析
编译器执行许多对用户隐藏的动作。 如上一篇
文章中所示,很难看到何时创建保护副本。
分析器检测以下隐藏副本:
- 密件抄送的唯读栏位。
- 密件抄送。
- ref只读局部变量的密件抄送。
- 密件抄送返回ref只读。
- 调用扩展方法时,密件抄送将结构实例的值作为参数使用带有此修饰符的参数。
public struct NonReadOnlyStruct { public readonly long PublicField; public long PublicProperty { get; } public void PublicMethod() { } private static readonly NonReadOnlyStruct _ros; public static void Samples(in NonReadOnlyStruct nrs) {
请注意,仅当结构大小≥16字节时,分析仪才会显示诊断消息。
在实际项目中使用分析仪
按值转移大型结构,结果是编译器创建保护性副本会显着影响性能。 性能测试的结果至少表明了这一点。 但是这些现象将如何在端到端时间方面影响实际应用?
为了使用真实代码测试分析仪,我将它们用于两个项目:Roslyn项目和我目前在Microsoft从事的内部项目(该项目是对性能有严格要求的独立计算机应用程序); 为了清楚起见,我们将其称为“项目D”。
结果如下:
- 具有高性能要求的项目通常包含许多结构,并且大多数结构都是只读的。 例如,在Roslyn项目中,分析器发现了约400个可以只读的结构,在D项目中,发现了约300个。
- 在具有高性能要求的项目中,仅应在特殊情况下创建盲副本。 我在罗斯林(Roslyn)项目中只发现了少数这种情况,因为大多数建筑物都具有公共场所而不是公共财产。 这样可以避免在结构存储在只读字段中的情况下创建保护性副本。 项目D中有更多的盲副本,因为它们中至少有一半具有只读属性(只读访问权限)。
- 使用in修饰符传递的甚至相当大的结构可能对程序的运行时间几乎没有影响(几乎觉察不到)。
我更改了项目D中的所有300个结构,使其变为只读状态,然后更正了数百种使用情况,指示它们与in修饰符一起传递。 然后,我针对各种性能场景测量了端到端的传输时间。 差异在统计学上不显着。
这是否意味着上述功能没有用? 一点也不
在具有高性能要求的项目上进行工作(例如,在Roslyn或“项目D”上)意味着大量人员花费大量时间进行各种类型的优化。 实际上,在某些情况下,我们代码中的结构是使用ref修饰符传递的,并且某些字段声明为不带readonly修饰符以排除保护性副本的生成。 使用in修饰符传递结构时,生产率缺乏增长,这可能意味着代码已得到优化,并且在其通过的关键路径上没有过度复制结构。
这些功能该怎么办?
我相信对于结构使用readonly修饰符的问题不需要太多考虑。 如果结构是不可变的,则readonly修饰符会明确地强制编译器做出这样的设计决定。 缺少此类结构的保护性副本只是一种好处。
今天,我的建议如下:如果该结构可以是只读的,则一定要这样做。
使用其他考虑的选项会产生细微差别。
预优化与预悲观?
赫伯·萨特(Herb Sutter)在他的著作《
C ++编码标准:101条规则,建议和最佳实践 》中介绍了“初步悲观化”的概念。
“ Ceteris paribus,代码复杂性和可读性,一些有效的设计模式和编码习惯用法自然会从您的指尖流失。 这样的代码不比其悲观的替代方案更难编写。 您无需进行初步优化,但可以避免自愿悲观。”
从我的角度来看,带有in修饰符的参数就是这种情况。 如果您知道结构相对较大(40个字节或更多),则可以始终使用in修饰符将其传递。 使用in修饰符的成本相对较低,因为您不需要调整调用,这样做的好处是真实的。
相反,对于带有只读ref修饰符的局部变量和返回值,情况并非如此。 我想说的是,在对库进行编码时应使用这些功能,最好在应用程序代码中拒绝它们(仅在对代码进行性能分析不能揭示复制操作确实存在问题的情况下)。 使用这些功能需要付出额外的努力,并且代码阅读器很难理解它。
结论
- 对结构尽可能使用readonly修饰符。
- 考虑将in修饰符用于大型结构。
- 考虑将局部变量和返回值与ref readonly修饰符一起使用来对库进行编码,或者在代码分析结果表明这很有用的情况下。
- 使用ErrorProne.NET可以检测代码问题并共享结果。