本文将重点介绍Web项目中的负载平衡。 许多人认为,解决此问题的方法是在服务器之间分配负载-越精确越好。 但是我们知道这并非完全正确。
从业务角度来看,系统的稳定性更为重要 。
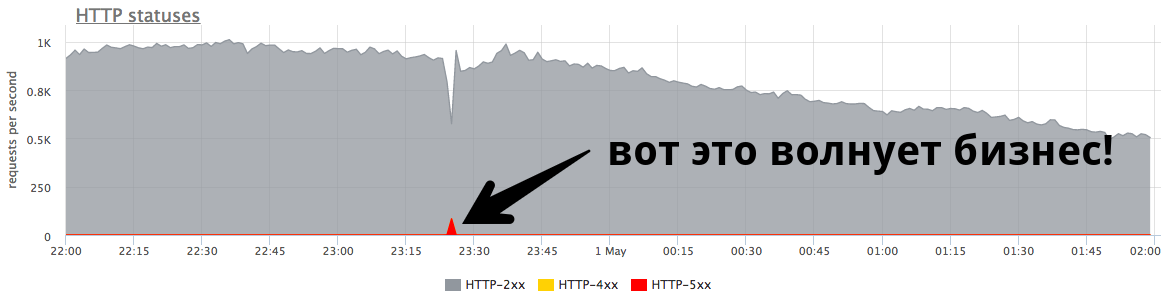
84 RPS的微小分钟峰值为“五百”,这是真实用户收到的五千个错误。 这很多,而且非常重要。 有必要寻找原因,纠正错误,并尝试继续防止这种情况。
Nikolay Sivko (
NikolaySivko )在其关于RootConf 2018的报告中谈到了负载平衡的细微但尚未流行的方面:
- 何时重复请求(重试);
- 如何选择超时值;
- 在事故/拥塞时如何不杀死底层服务器;
- 是否需要健康检查;
- 如何处理闪烁的问题。
正在对该报告进行猫解码。
关于发言人: okmeter.io的联合创始人Nikolay Sivko。 他曾担任系统管理员和一组管理员的负责人。 在hh.ru进行监督操作。 他创建了监视服务okmeter.io。 作为本报告的一部分,监视开发经验是案例的主要来源。
我们要谈什么?
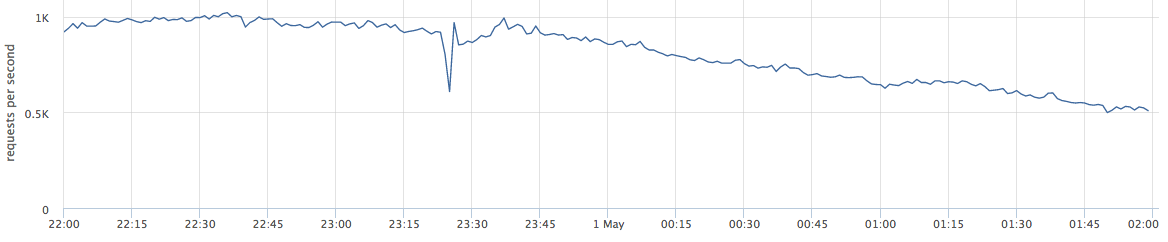
本文将讨论Web项目。 以下是实时生产的示例:该图显示了某个Web服务的每秒请求。
当我谈到平衡时,许多人将其视为“我们需要在服务器之间分配负载-越精确越好”。
实际上,这并非完全正确。 此问题与极少数公司有关。 企业更多时候担心错误和系统稳定性。
图上的小峰值是“五百”,服务器在一分钟内返回,然后停止。 从企业(例如在线商店)的角度来看,这个84 RPS的小高峰是“五百”,对真实用户来说是5040错误。 有些人没有在您的目录中找到任何东西,其他人则无法将商品放在篮子里。 这非常重要。 尽管此峰值在图表上看起来并不大,
但实际用户中很多 。
通常,每个人都有这样的高峰,而管理员并不总是响应这些高峰。 很多时候,当一家企业询问它是什么时,他们会回答他:
- “这是短暂的爆发!”
- “这只是一个发布滚动。”
- “服务器死了,但是一切都已经整齐了。”
- “ Vasya交换了后端之一的网络。”
通常,人们
甚至不试图理解发生这种情况
的原因 ,并且不做任何后期工作,以免再次发生。
微调
我称该报告为“精细调整”(英语:Fine tuning),因为我认为并不是每个人都能完成这项任务,但值得。 他们为什么不到达那里?
- 并非所有人都能完成这项任务,因为当一切正常时,它是不可见的。 这对于问题非常重要。 法卡帕并不是每天都发生,如此小的问题需要非常认真的努力才能解决。
- 您需要考虑很多。 管理员-调整余额的人-通常无法独立解决此问题。 接下来,我们将了解原因。
- 它抓住了底层。 通过影响产品和用户的决策,该任务与开发紧密相关。
我确认是时候执行此任务了,原因有几个:- 世界正在变化,变得更加动态,有许多版本。 他们说,现在每天释放100次是正确的,并且释放是未来的fakap,可能性为50到50(就像遇到恐龙的可能性一样)
- 从技术的角度来看,一切都非常动态。 Kubernetes和其他协调器出现了。 没有很好的旧部署,当某个IP上的一个后端关闭时,更新将滚动,并且服务将启动。 现在,在k8s中推出的过程中,上游IP的列表已完全更改。
- 微服务:现在每个人都通过网络进行通信,这意味着您需要可靠地进行此操作。 平衡起着重要作用。
试验台
让我们从简单的显而易见的案例开始。 为了清楚起见,我将使用测试台。 这是一个提供http-200的Golang应用程序,或者您可以将其切换到“提供http-503”模式。
我们开始3个实例:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
我们通过ngexx通过yandex.tank提供100 rps。
Nginx开箱即用:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
原始场景
在某个时候,以Give 503模式打开一个后端,我们恰好得到了三分之一的错误。
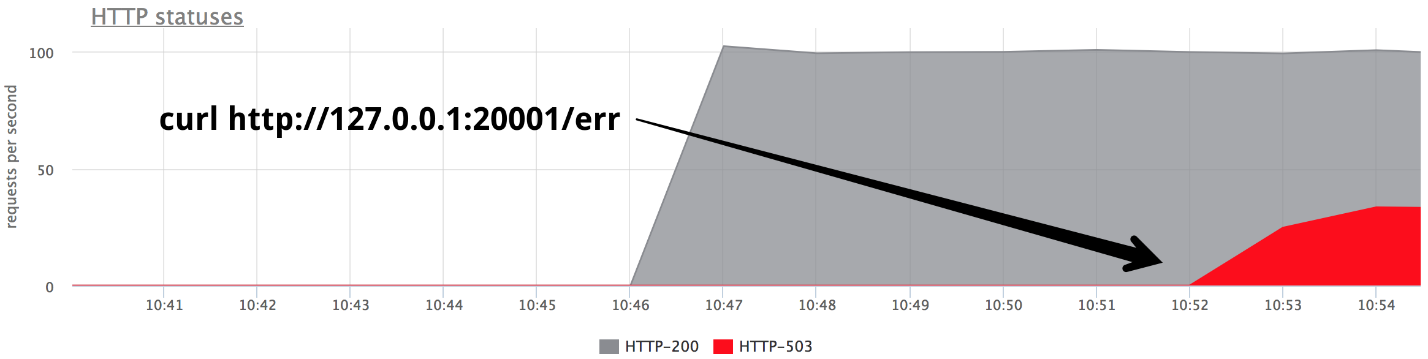
很明显,什么都没有开箱即用:如果nginx从服务器收到
任何响应 ,它就不会重试开箱即用。
Nginx default: proxy_next_upstream error timeout;
实际上,从nginx开发人员的角度来看,这是很合乎逻辑的:nginx无权为您决定要重新定义的内容,而不是要重新定义的内容。
因此,我们需要重试-重试,然后我们开始谈论它们。
重试
有必要在以下之间找到折衷方案:
- 用户的请求是神圣的,会受伤,但会回答。 我们要不惜一切代价回答用户,用户是最重要的。
- 最好通过错误回答而不是使服务器超负荷。
- 数据完整性(针对非幂等请求),即无法重复某些类型的请求。
像往常一样,真相介于两者之间-我们被迫在这三点之间取得平衡。 让我们尝试了解什么以及如何做。
我将失败的尝试分为三类:
1.
运输错误因为HTTP传输是TCP,通常,这里我们讨论连接建立错误和连接建立超时。 在我的报告中,我将提到3种常见的平衡器(我们将进一步讨论Envoy):
- nginx :错误+超时(proxy_connect_timeout);
- HAProxy :超时连接;
- 特使 :连接失败+拒绝流。
Nginx有机会说失败的尝试是连接错误和连接超时。 HAProxy具有连接超时,Envoy也具有标准和正常的所有功能。
2.
请求超时:假设我们向服务器发送了一个请求,并成功连接到服务器,但是答案没有得到解决,我们等待了它,并且我们知道再等待也没有意义。 这称为请求超时:
- Nginx具有:超时(prox_send_timeout * + proxy_read_timeout *);
- HAProxy具有 OOPS :( -原则上不存在。许多人不知道HAProxy如果成功建立了连接,将永远不会尝试重新发送请求。
- 特使可以做的一切:超时|| per_try_timeout。
3.
HTTP状态尽管后端已回答您,但HAProxy之外的所有平衡器均能够处理,但使用某种错误代码。
- nginx :http_ *
- HAProxy : OOPS :(
- 特使 :5xx,网关错误(502、503、504),可重试4xx(409)
超时时间
现在让我们详细讨论超时,在我看来,这值得关注。 不会再有火箭科学了-这只是有关一般发生的情况及其与之关系的结构化信息。
连接超时
连接超时是建立连接的时间。 这是您的网络和特定服务器的特征,并且与请求无关。 通常,连接超时的默认值设置为小。 在所有代理中,默认值都足够大,这是错误的-它应该是
单位,有时是数十毫秒 (如果我们正在谈论一个DC内的网络)。
如果要以比这些单位几十毫秒更快的速度识别有问题的服务器,则可以通过设置一个小的待办事项列表来接收TCP连接来调整后端的负载。 在这种情况下,您可以在应用程序的待办事项已满时,告诉Linux将其重置以溢出待办事项。 然后,您可以比连接超时早一点拍摄“坏”的超载后端:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
请求超时
请求超时不是网络特征,而是
一组请求 (处理程序)的特征。 有不同的请求-严重性不同,内部逻辑完全不同,它们需要访问完全不同的存储库。
Nginx本身
对整个请求没有超时。 他有:
- proxy_send_timeout:两次成功写操作之间的时间write();
- proxy_read_timeout:两次成功读取之间的时间间隔()。
也就是说,如果您的后端缓慢地(一个字节的时间)在超时中给出了某些内容,那么一切都很好。 因此,nginx没有request_timeout。 但是我们正在谈论上游。 在我们的数据中心中,它们是由我们控制的,因此,假设网络不具有低延迟,那么原则上read_timeout可以用作request_timeout。
特使拥有一切:超时|| per_try_timeout。
选择请求超时
我认为现在最重要的是放置哪个request_timeout。 我们从允许用户等待的数量开始-这是一定的最大值。 显然,用户等待的时间不会超过10秒,因此您需要更快地回答他。
- 如果要处理一台服务器的故障,则超时应小于最大允许超时: request_timeout <max。
- 如果要保证两次尝试将请求发送到两个不同的后端,则一次尝试的超时时间等于此允许间隔的一半: per_try_timeout = 0.5 * max。
- 还有一个中间选项-如果第一个后端“变空”,则进行两次乐观尝试 ,但是第二个后端将快速响应: per_try_timeout = k * max(其中k> 0.5)。
有多种方法,但是总的来说,
选择超时很困难 。 总是会有边界情况,例如,有99%的情况下的同一个处理程序在10毫秒内得到处理,但是当我们等待500毫秒时有1%的情况是正常的。 这将必须解决。
将此百分比设置为1%时,需要做一些事情,因为整个请求组应符合SLA的规定,并在100毫秒内满足要求。 这些时候通常会处理应用程序:
- 分页出现在无法在超时时间内返回所有数据的地方。
- 管理员/报告被分为一组单独的url,以增加它们的超时时间,是的则降低用户请求。
- 我们会修复/优化那些不适合我们超时的请求。
在这里,我们需要做出一个决定,从心理学的角度来看,这不是一个简单的决定,如果我们没有时间在规定的时间内回答用户,我们将给出一个错误(就像古老的中国谚语所说:“如果母马死了,那就下车!”)
。之后,从用户的角度监视服务的过程得以简化:
- 如果有错误,则一切都不好,需要对其进行修复。
- 如果没有错误,我们将在正确的响应时间内适应要求,那么一切都很好。
投机性重试#nifig
我们确保选择超时值非常困难。 如您所知,为了简化某些内容,您需要使某些内容复杂化:)
推测性重新授权 -对另一台服务器的重复请求,该请求是由某些条件启动的,但第一个请求不会被中断。 我们从响应速度更快的服务器获取答案。
我没有在平衡器中看到此功能,但是Cassandra(快速读取保护)是一个很好的例子:
speculative_retry = N毫秒|
分位数这样,您
就不必超时 。 您可以将其保持在可接受的水平,并且在任何情况下都可以再次尝试获得对请求的响应。
Cassandra有一个有趣的机会来设置静态speculative_retry或dynamic,然后将通过响应时间的百分比进行第二次尝试。 Cassandra累积有关先前请求的响应时间的统计信息,并调整特定的超时值。 效果很好。
在这种方法中,一切都取决于可靠性和虚假负载之间的平衡,而不是服务器,您提供了可靠性,但有时会收到对服务器的额外请求。 如果您急于某个地方并发送了第二个请求,但第一个请求仍然响应,则服务器会承受更多的负载。 在单个情况下,这是一个小问题。

超时一致性是另一个重要方面。 我们将详细讨论请求取消,但通常来说,如果整个用户请求的超时时间为100毫秒,那么将请求在数据库中的超时时间设置为1 s毫无意义。 有一些系统可以让您动态地执行此操作:服务到服务转移了您等待该请求答案的其余时间。 它很复杂,但是如果您突然需要它,则可以在同一个Envoy中轻松地找到如何做。
关于重试,您还需要了解什么?
不归还点(V1)
这里的V1不是版本1。在航空中有这样一个概念-速度V1。 这是无法降低跑道上加速度的速度。 有必要起飞,然后决定下一步要做什么。
负载均衡器中也没有返回点:
在将1字节的响应传递给客户端时,无法修复任何错误 。 如果后端在此时死亡,则重试将无济于事。 您只能减少触发这种情况的可能性,进行正常关闭,即告诉您的应用程序:“您现在不接受新请求,而修改旧请求!”然后才将其熄灭。
如果控制客户端,则这是一些棘手的Ajax或移动应用程序,它可能会尝试重复该请求,然后您就可以摆脱这种情况。
不归还点[特使]
特使有一个奇怪的把戏。 有per_try_timeout-它限制了每次尝试获取请求响应的次数。 如果此超时有效,但后端已经开始响应客户端,则一切都被中断,客户端收到错误。
我的同事Pavel Trukhanov(
tru_pablo )制作了一个
补丁 ,该
补丁已经存在于Envoy大师中,并且将在1.7版中。 现在它应该按预期的方式工作:如果响应已开始传输,则只有全局超时有效。
重试:需要限制
重试是好的,但是有所谓的杀手级请求:执行非常复杂的逻辑的繁重查询会大量访问数据库,并且通常不适合per_try_timeout。 如果我们一次又一次发送重试,那么我们将杀死我们的基地。 因为
在大多数(99.9%)数据库服务中,没有请求取消 。
取消请求意味着客户端已经取消钩,您需要立即停止所有工作。 Golang正在积极推广这种方法,但是不幸的是,它以后端结束,许多数据库存储库都不支持这种方法。
因此,需要限制重试次数,这几乎允许所有平衡器使用(从现在开始我们不再考虑HAProxy)。
Nginx:- proxy_next_upstream_timeout(全局)
- proxt_read_timeout **为per_try_timeout
- proxy_next_upstream_tries
特使:- 超时(全局)
- per_try_timeout
- num_retries
在Nginx中,可以说我们正在尝试在整个窗口X进行重试,即在给定的时间间隔(例如500毫秒)内,我们进行了尽可能多的重试。 或者有一个设置可以限制重复样本的数量。 在
Envoy中 ,数量或超时(全局)相同。
重试:应用[nginx]
考虑一个示例:我们在nginx 2中设置重试尝试-因此,在收到HTTP 503之后,我们尝试再次向服务器发送请求。 然后关闭
两个后端。
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
以下是我们测试平台的图表。 上面的图中没有错误,因为它们很少。 如果仅留下错误,则很明显它们是存在的。
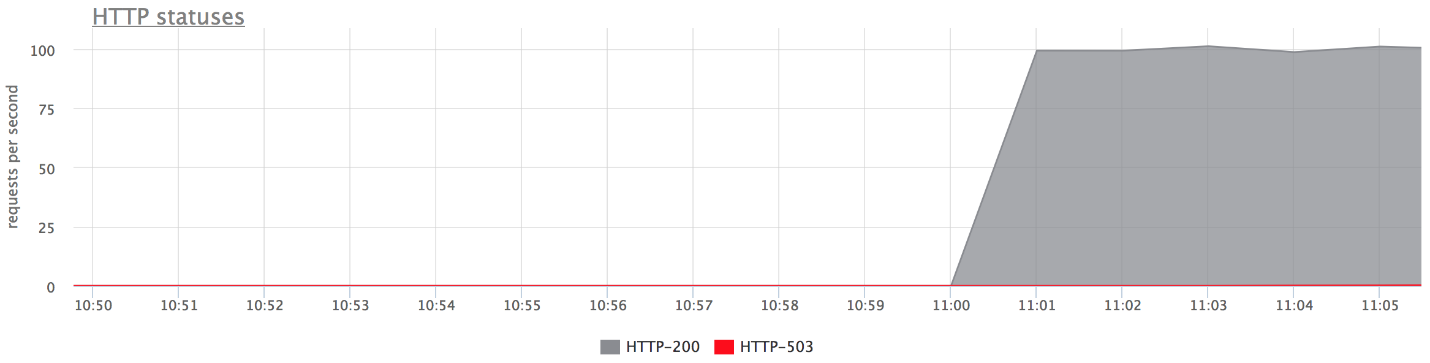
 发生什么事了
发生什么事了- proxy_next_upstream_tries = 2。
- 如果您第一次尝试访问“失效”服务器,而第二次尝试访问另一“失效”服务器,则在两次尝试访问“失效”服务器的情况下都将获得HTTP-503。
- 由于nginx会“禁止”不良服务器,因此几乎没有错误。 也就是说,如果在nginx中从后端返回了一些错误,它将停止进行以下尝试以向其发送请求。 这由fail_timeout变量控制。
但是有错误,这不适合我们。
怎么办呢?我们可以增加重试次数(但随后又要解决“杀手级请求”问题),或者可以降低请求到达“死角”后端的可能性。 这可以通过
运行状况检查来完成
。健康检查
我建议将运行状况检查作为选择“实时”服务器过程的优化。
这绝不提供任何保证。 因此,在执行用户请求期间,我们更有可能仅访问“实时”服务器。 平衡器会定期访问特定的URL,服务器会回答他:“我还活着并且准备就绪。”
健康检查:在后端方面
从后端的角度来看,您可以做一些有趣的事情:
- 检查后端操作所依赖的所有基础子系统的操作是否就绪:建立了与数据库的必要连接数,池具有空闲连接等,等等。
- 如果使用的平衡器不是很智能,则可以在运行状况检查URL上挂起自己的逻辑(例如,从主机上获取负载平衡器)。 服务器可以记住,“在最后一分钟我犯了很多错误-我可能是某种“错误”服务器,在接下来的2分钟内,我将对健康检查做出“五百”答复。 因此,我将禁止自己!” 当您的负载均衡器不受控制时,这有时会很有帮助。
- 通常,检查间隔约为一秒钟,并且您需要运行状况检查处理程序才能杀死服务器。 应该是轻的。
健康检查:实施
通常,这里的每个人都是一样的:
- 要求;
- 超时;
- 我们进行检查的时间间隔。 被欺骗的代理具有抖动 ,即有些随机性,因此所有运行状况检查不会立即出现在后端,也不会杀死它。
- 不健康阈值 -必须经过多少次运行状况检查才能使服务将其标记为不健康的阈值。
- 健康阈值 -相反,必须经过多少次成功尝试才能使服务器恢复运行。
- 附加逻辑。 您可以解析检查状态+正文等。
Nginx仅在Nginx +的付费版本中实现运行状况检查功能。
我注意到
Envoy的功能,它具有运行状况检查
恐慌模式。 当我们禁止“不健康”的主机超过N%(例如70%)时,他认为我们所有的健康检查都在撒谎,并且所有主机实际上都还活着。 在非常糟糕的情况下,这将帮助您避免遇到自己开枪并禁止所有服务器的情况。 这是再次确保安全的方法。
全部放在一起
通常用于健康检查:
在我们国家/地区,倾向于设置nginx + HAProxy,因为nginx的免费版本没有运行状况检查,并且直到1.11.5为止,对后端的连接数量没有限制。 但是此选项很不好,因为HAProxy在建立连接后不知道如何退出。 许多人认为,如果HAProxy在nginx和nginx重试上返回错误,那么一切都会好起来的。 不完全是 您可以使用另一个HAProxy和相同的后端,因为后端池是相同的。 因此,您为自己引入了一个抽象级别,这降低了平衡的准确性,并因此降低了服务的可用性。
我们有nginx + Envoy,但是如果您感到困惑,可以将自己仅限于Envoy。
什么样的特使?
Envoy是一种时尚的青年负载平衡器,最初是用Lyft开发的,用C ++编写。
开箱即用,他今天可以做一堆关于我们的话题的bun头。 您可能将其视为Kubernetes的服务网格。 通常,Envoy充当数据平面,也就是说,它直接平衡流量,并且还有一个控制平面,它提供有关您需要在哪些负载之间分配负载的信息(服务发现等)。
我给你说说他的s头。
为了增加下次尝试重试成功的可能性,您可以睡一会儿,然后等待后端恢复正常。 这样,我们将处理短数据库问题。 特使有
重试的机会 -重试之间暂停。 而且,尝试之间的延迟间隔呈指数增长。 第一次重试发生在0-24毫秒之后,第二次重试发生在0-74毫秒之后,然后对于每次后续尝试,间隔都会增加,并且从该间隔中随机选择特定的延迟。
第二种方法不是特定于Envoy的,而是一种称为“
电路断开” (点亮的断路器或熔断器)的模式。 实际上,当我们的后端变暗时,我们每次都会尝试完成它。 这是因为用户在任何无法理解的情况下都单击刷新页面,从而向您发送越来越多的新请求。 您的平衡器会紧张,发送重试,请求数量增加-负载在增加,在这种情况下最好不要发送请求。
断路器只允许您确定我们处于这种状态,快速排除错误并让后端“屏住呼吸”。
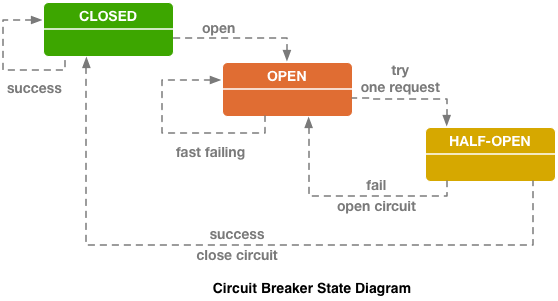 断路器(hystrix像libs), 在ebay的博客上具有 原创性 。
断路器(hystrix像libs), 在ebay的博客上具有 原创性 。上面是Hystrix断路器电路。 Hystrix是Netflix的Java库,旨在实现容错模式。
- 当所有请求都发送到后端并且没有错误时,“保险丝”可以处于“关闭”状态。
- 当触发某个故障阈值时,即发生了一些错误,断路器进入“打开”状态。 它会迅速将错误返回给客户端,并且请求不会到达后端。
- 在特定时间段内,仍有一小部分请求发送到后端。 如果触发错误,则状态保持为“打开”。 如果一切开始正常工作并做出响应,则“保险丝”将关闭并且工作继续。
因此,在Envoy中,这还不是全部。 对于一个特定的上游组,最多只能有N个请求,这一事实有较高的限制。 如果更多,则这里有问题-我们返回错误。 不能再进行N次有效重试(即当前正在发生的重试)。
您没有重试,发生了爆炸-发送重试。 特使了解到,不止N个异常,并且所有请求都必须以错误发出。
断路[特使]- 群集(上游组)最大连接数
- 集群最大未决请求
- 群集最大请求
- 集群最大活动重试次数
这个简单的方法效果很好,它是可配置的,您不必提出特殊的参数,并且默认设置非常好。
断路器:我们的经验
我们曾经有一个HTTP指标收集器,也就是说,安装在客户服务器上的代理通过HTTP将指标发送到我们的云中。 如果我们在基础架构中有任何问题,则代理会将指标写入其磁盘,然后尝试将其发送给我们。
代理不断尝试向我们发送数据,他们不会为我们以某种方式做出错误响应而感到不安,并且不会离开。
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
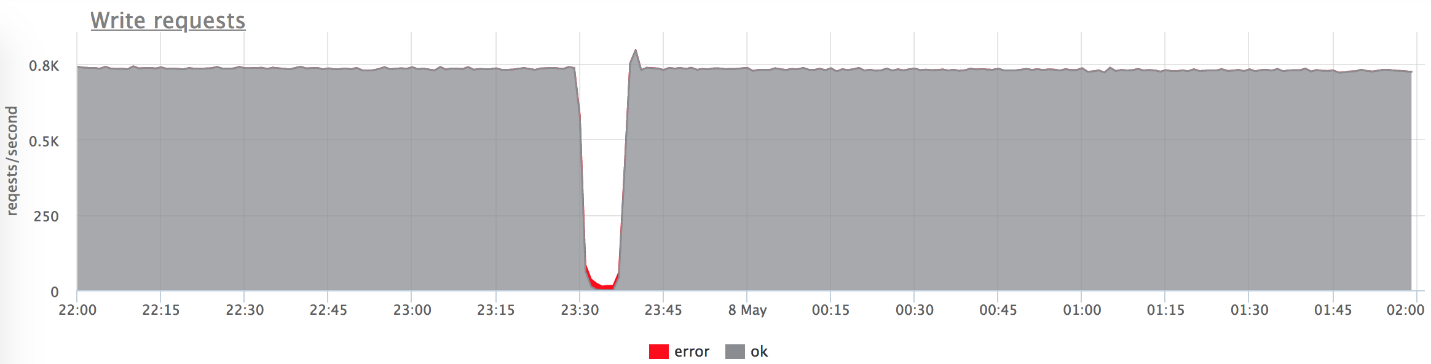
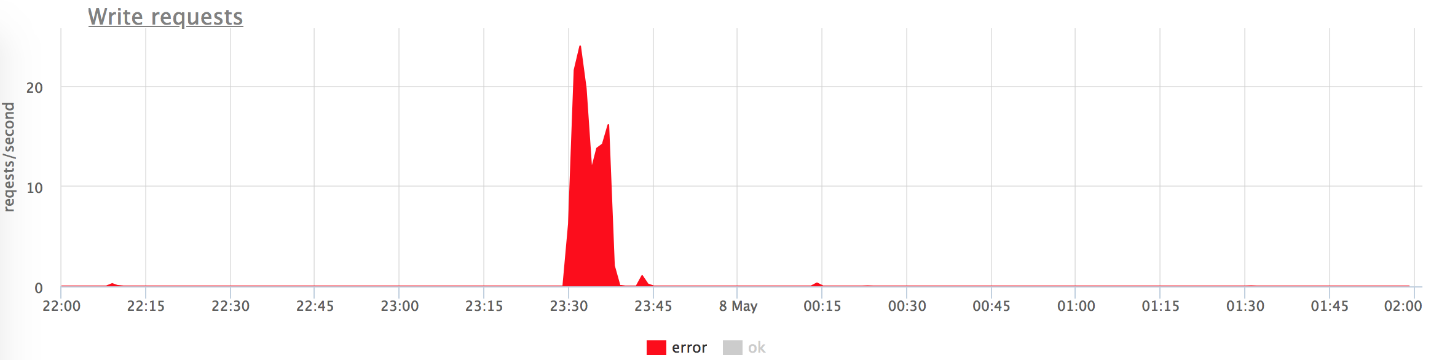
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
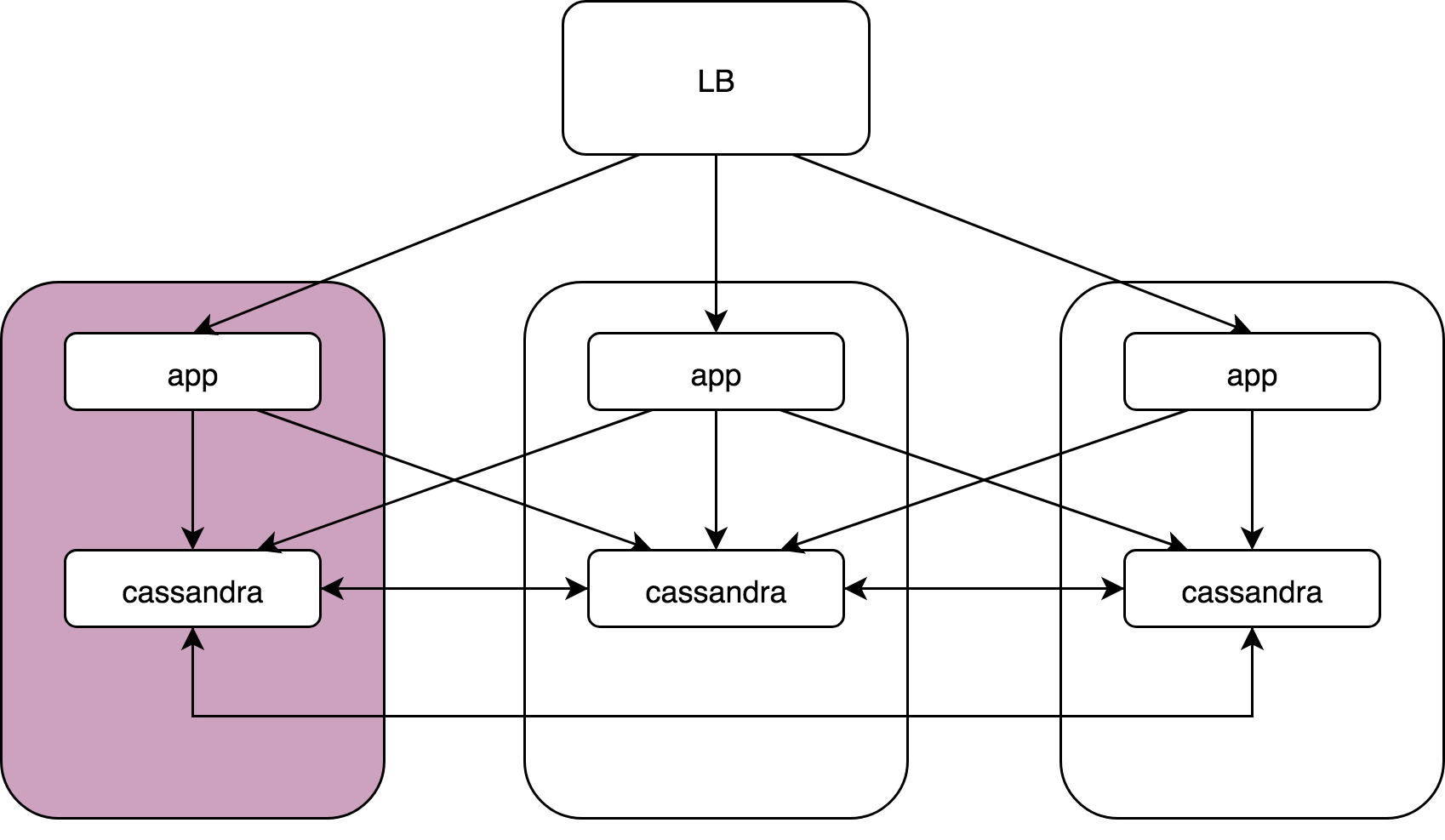
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .