System.IO.Pipelines是一个新的库,可简化.NET中的代码组织。 如果必须处理复杂的代码,很难确保高性能和准确性。 System.IO.Pipelines的任务是简化代码。 削减更多细节!

该库的产生是.NET Core开发团队努力使Kestrel成为
业界最快的Web服务器之一的结果 。 它最初被认为是Kestrel实现的一部分,但已经发展成为可重用的API,在2.1版中可作为一流的BCL API(System.IO.Pipelines)使用。
她能解决什么问题?
为了正确分析来自流或套接字的数据,您需要编写大量标准代码。 同时,存在许多使代码本身及其支持复杂化的陷阱。
今天出现了什么困难?
让我们从一个简单的任务开始。 我们需要编写一个TCP服务器来从客户端接收行分隔的消息(\ n)。
带有NetworkStream的TCP服务器
偏差:如同在任何需要高性能的任务中一样,应根据应用程序的功能来考虑每种特定情况。 如果网络应用程序的规模不是很大,那么花资源来使用各种方法可能就没有意义,稍后将对此进行讨论。
使用管道之前的常规.NET代码如下所示:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
请参阅
github上的sample1.cs该代码可能会与本地测试一起使用,但是它有很多错误:
- 也许在一次调用ReadAsync之后,将不会收到整个消息(到该行的末尾)。
- 它忽略stream.ReadAsync()方法的结果-实际传输到缓冲区的数据量。
- 该代码不处理在单个ReadAsync调用中接收多行。
这些是最常见的流数据读取错误。 为了避免它们,您需要进行一些更改:
- 您需要缓冲传入的数据,直到找到新行。
- 有必要分析返回到缓冲区的所有行。
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
请参阅
github上的sample2.cs我再说一遍:这可以在本地测试中使用,但是有时字符串长度超过1 Kb(1024字节)。 必须增加输入缓冲区的大小,直到找到新行。
此外,在处理长字符串时,我们会将缓冲区收集到数组中。 我们可以使用ArrayPool改进此过程,它可以避免在分析来自客户端的长行时重新分配缓冲区。
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
参见github上的sample3.cs该代码可以工作,但是现在缓冲区大小已更改,因此出现了许多副本。 还使用更多的内存,因为逻辑不会在处理行后减少缓冲区。 为避免这种情况,您可以保存缓冲区列表,而不是每次字符串到达的长度大于1 Kb时都更改缓冲区的大小。
此外,在完全为空之前,我们不会增加1 KB的缓冲区大小。 这意味着我们将越来越小的缓冲区转移到ReadAsync,结果,对操作系统的调用次数将增加。
我们将尝试消除这种情况,并在现有缓冲区的大小小于512字节时立即分配一个新缓冲区:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
请参阅github上的sample4.cs结果,代码非常复杂。 在搜索定界符期间,我们跟踪填充的缓冲区。 为此,请使用一个列表,该列表在搜索新的行分隔符时显示缓冲的数据。 结果,ProcessLine和IndexOf将接受List而不是字节[],偏移量和计数。 解析逻辑将开始处理缓冲区的一个或多个段。
现在,服务器将处理部分消息,并使用共享内存来减少整体内存消耗。 但是,需要进行一些更改:
- 在ArrayPoolbyte中,我们仅使用Byte []-标准管理的数组。 换句话说,当执行ReadAsync或WriteAsync函数时,缓冲区的有效期与异步操作的时间(与操作系统自己的I / O API进行交互)有关。 由于固定的内存无法移动,因此会影响垃圾收集器的性能,并可能导致阵列碎片化。 您可能需要更改池的实现,具体取决于异步操作等待执行的时间。
- 通过中断读取和处理逻辑之间的链接可以提高吞吐量。 我们得到了批处理的效果,现在解析逻辑将能够读取大量数据,处理较大的缓冲区块,而不是分析单个行。 结果,代码变得更加复杂:
- 必须创建两个彼此独立工作的循环。 第一个将从套接字读取数据,第二个将分析缓冲区。
- 所需要的是一种告诉解析逻辑数据变得可用的方法。
- 还必须确定如果循环从套接字读取数据的速度过快会发生什么。 如果解析逻辑跟不上读取周期,我们需要一种调整读取周期的方法。 这通常称为“流量控制”或“流动阻力”。
- 我们必须确保数据安全传输。 现在,这组缓冲区在读取周期和解析周期中都被使用;它们在不同的线程上彼此独立工作。
- 内存管理逻辑还涉及两个不同的代码段:从缓冲池借用数据(从套接字读取数据),以及从缓冲池返回(这是解析逻辑)。
- 执行解析逻辑后,在返回缓冲区时必须格外小心。 否则,我们有机会返回仍将套接字读取逻辑写入其中的缓冲区。
复杂性开始蔓延(这远非所有情况!)。 要创建高性能网络,您需要编写非常复杂的代码。
System.IO.Pipelines的目的是简化此过程。
TCP服务器和System.IO.Pipelines
让我们看看System.IO.Pipelines的工作原理:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
请参阅github上的sample5.cs我们的线路阅读器的流水线版本有两个循环:
- FillPipeAsync从套接字读取并写入PipeWriter。
- ReadPipeAsync从PipeReader读取并分析传入的行。
与第一个示例不同,没有专门分配的缓冲区。 这是System.IO.Pipelines的主要功能之一。 所有缓冲区管理任务都将传输到PipeReader / PipeWriter实现。
该过程得以简化:我们仅将代码用于业务逻辑,而不是实现复杂的缓冲区管理。
在第一个循环中,首先调用PipeWriter.GetMemory(int)从主编写器获取一定数量的内存。 然后调用PipeWriter.Advance(int),它告诉PipeWriter实际将多少数据写入缓冲区。 接下来是对PipeWriter.FlushAsync()的调用,以便PipeReader可以访问数据。
第二个循环使用由PipeWriter写入但最初从套接字接收的缓冲区。 当返回对PipeReader.ReadAsync()的请求时,我们将获得一个ReadResult,其中包含两个重要消息:以ReadOnlySequence形式读取的数据以及逻辑数据类型IsCompleted,该逻辑数据类型告知读取器写入器是否已完成工作(EOF)。 找到行终止符(EOL)并分析了字符串后,我们会将缓冲区拆分为多个部分,以跳过已处理的片段。 此后,调用PipeReader.AdvanceTo,它告诉PipeReader已消耗了多少数据。
在每个周期结束时,阅读器和写入器均完成。 结果,主通道释放所有分配的内存。
系统管道
部分阅读
除了管理内存,System.IO.Pipelines还执行另一个重要功能:它扫描通道中的数据,但不使用它。
PipeReader具有两个主要的API:ReadAsync和AdvanceTo。 ReadAsync从通道接收数据,AdvanceTo告诉PipeReader读取器不再需要这些缓冲区,因此您可以摆脱它们(例如,将它们返回到主缓冲池)。
以下是HTTP分析器的示例,该分析器从部分通道数据缓冲区读取数据,直到接收到合适的起始行。

ReadOnlySequenceT
通道实现存储在PipeWriter和PipeReader之间传递的相关缓冲区的列表。 PipeReader.ReadAsync公开ReadOnlySequence,它是一种新型的BCL,由一个或多个ReadOnlyMemory <T>段组成。 它类似于Span或Memory,它使我们有机会查看数组和字符串。
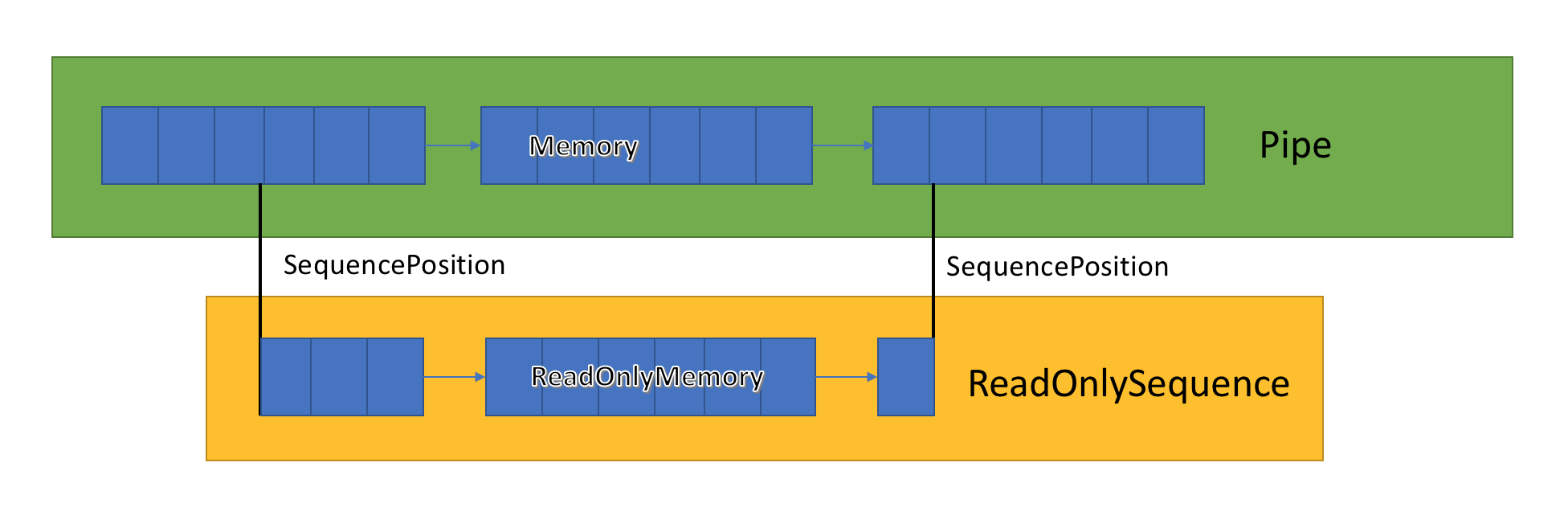
通道内部有指针,这些指针显示读取器和写入器在突出显示的常规数据集中的位置,并在写入和读取数据时对其进行更新。 SequencePosition是缓冲区的链接列表中的单个点,用于有效地分隔ReadOnlySequence <T>。
由于ReadOnlySequence <T>支持一个或多个段,因此高性能逻辑的标准操作是根据段数分隔快速路径和慢速路径。
例如,下面是一个将ASCII ReadOnlySequence转换为字符串的函数:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
请参阅
github上的sample6.cs流阻和流量控制
理想情况下,读取和分析可以协同工作:读取流消耗来自网络的数据并将其放入缓冲区,而分析流创建合适的数据结构。 分析通常比从网络复制数据块花费更多的时间。 结果,读取流很容易使分析流超载。 因此,读取流将被迫减慢速度或消耗更多内存以保存分析流的数据。 为了确保最佳性能,需要在暂停频率和分配大量内存之间取得平衡。
为了解决此问题,管道具有两个数据流控制功能:PauseWriterThreshold和ResumeWriterThreshold。 PauseWriterThreshold确定在PipeWriter.FlushAsync暂停之前需要缓冲多少数据。 ResumeWriterThreshold确定记录器恢复操作之前读取器可以消耗多少内存。
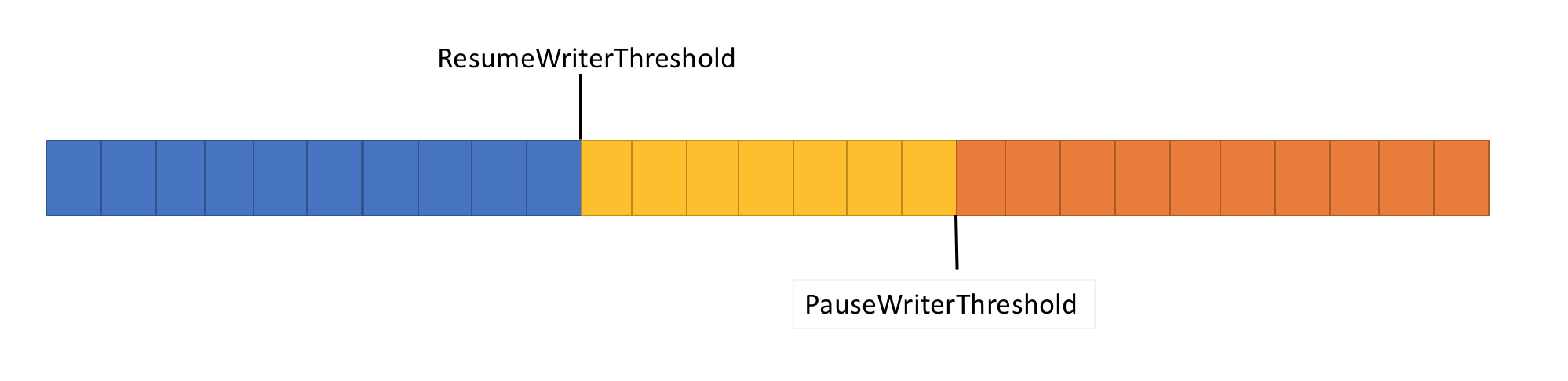
当管道流中的数据量超过PauseWriterThreshold中设置的限制时,PipeWriter.FlushAsync将“锁定”,而当其下降到ResumeWriterThreshold中设置的限制以下时,“解锁”。 为了防止超出消耗限制,仅使用两个值。
I / O调度
使用异步/等待时,通常在池线程或当前的SynchronizationContext中调用后续操作。
在执行I / O时,仔细监视执行位置非常重要,以便更好地利用处理器缓存。 这对于Web服务器等高性能应用程序至关重要。 System.IO.Pipelines使用PipeScheduler确定在哪里执行异步回调。 这使您可以非常精确地控制将哪些流用于I / O。
实际应用程序的一个示例是Kestrel Libuv传输,其中在事件循环的专用通道上执行I / O回调。
PipeReader模板还有其他好处。
- 一些基本系统支持“等待而不缓冲”:您不需要分配缓冲区,直到基本系统中出现可用数据为止。 因此,在具有epoll的Linux上,在数据准备就绪之前,您无法提供读取缓冲区。 这样可以避免出现许多线程在等待数据的情况,而您需要立即保留大量的内存。
- 默认管道使编写网络代码的单元测试变得容易:解析逻辑与网络代码分开,并且单元测试仅在存储器的缓冲区中运行此逻辑,而不是直接从网络使用它。 通过发送部分数据,还可以轻松测试复杂的模式。 ASP.NET Core使用它来测试Kestrel的http解析工具的各个方面。
- 允许用户代码使用主要OS缓冲区的系统(例如,已注册的Windows I / O API)最初适合使用管道,因为PipeReader实现始终提供缓冲区。
其他相关类型
我们还向System.IO.Pipelines添加了许多新的简单BCL类型:
如何使用输送机?
这些API位于nuget包
System.IO.Pipelines中 。
有关使用管道处理小写消息的示例.NET Server 2.1服务器应用程序(来自上面的示例),请参见
此处 。 可以使用dotnet run(或Visual Studio)启动它。 在该示例中,期望从端口8087上的套接字传输数据,然后将接收到的消息写入控制台。 您可以使用诸如netcat或putty之类的客户端连接到端口8087。 发送一个小写的消息,看看它如何工作。
当前,管道在Kestrel和SignalR上运行,我们希望将来它将在许多网络库和.NET社区的组件中找到更广泛的应用。