
从一开始,我们就计划了工程和产品解决方案,以使Discord非常适合与朋友一起玩时进行语音聊天。 这些解决方案使团队规模较小且资源有限,可以极大地扩展系统。
本文讨论了Discord用于音频/视频聊天的各种技术。
为了清楚起见,我们将整个用户组和渠道称为“组”(行会)-在客户端中,它们被称为“服务器”。 相反,术语“服务器”是指我们的服务器基础结构。主要原则
Discord中的每个音频/视频聊天都支持许多参与者。 我们看着成千上万的人轮流在大群聊中聊天。 这样的支持需要客户端-服务器体系结构,因为随着参与者数量的增加,对等网络对等网络变得非常昂贵。
通过Discord服务器路由网络流量还可以确保您的IP地址永远不可见-并且没有人会发起DDoS攻击。 通过服务器进行路由还有其他优点:例如,审核。 管理员可以快速关闭入侵者的声音和视频。
客户端架构
Discord可在许多平台上运行。
- 网络(Chrome / Firefox / Edge等)
- 独立应用程序(Windows,MacOS,Linux)
- 手机(iOS / Android)
我们只能以一种方式支持所有这些平台:通过重用
WebRTC代码。 该实时通信规范包括网络,音频和视频组件。 该标准
由万维网联盟和
Internet工程组采用 。 WebRTC在所有现代浏览器中均可用,并且可以作为在应用程序中实现的本机库。
Discord中的音频和视频在WebRTC上运行。 因此,浏览器应用程序依赖于浏览器中WebRTC的实现。 但是,用于台式机,iOS和Android的应用程序使用在其自己的WebRTC库之上构建的单个C ++多媒体引擎,该引擎特别适合我们的用户需求。 这意味着应用程序中的某些功能比浏览器中的功能更好。 例如,在我们的本机应用程序中,我们可以:
- 当使用耳机时所有应用程序都被自动静音时 ,默认情况下绕过Windows Volume Mute。 当您和您的朋友进行突袭并协调Discord聊天活动时,这是不可取的。
- 使用您自己的音量控制代替全局操作系统混音器。
- 处理原始音频数据以检测语音活动并在游戏中广播音频和视频。
- 减少静音期间的带宽和CPU消耗-即使在任何给定时间进行最多数量的语音聊天中,也只有少数人同时讲话。
- 为按键通话模式提供系统范围的功能。
- 与音频视频数据包一起发送其他信息(例如,聊天中的优先级指示符)。
拥有自己的WebRTC版本意味着所有用户都需要频繁更新:这是我们试图自动化的耗时过程。 但是,由于我们的播放器具有特定功能,因此付出了努力。
在Discord中,通过输入语音通道或呼叫来启动语音和视频通信。 也就是说,连接始终由客户端启动-这降低了客户端和服务器部分的复杂性,并且还提高了容错能力。 如果基础结构发生故障,参与者可以简单地重新连接到新的内部服务器。
在我们的控制之下
通过本机库的控件,您可以实现某些功能,而与WebRTC的浏览器实现不同。
首先,WebRTC依靠会话描述协议(
SDP )在参与者之间协商音频/视频(每个数据包交换最多10 KB)。 在其自己的库中,WebRTC的较低级API(
webrtc::Call )用于创建流-入站和出站。 连接到语音通道后,信息交换最少。 这是后端服务器的地址和端口,加密方法,密钥,编解码器和流标识(大约1000个字节)。
webrtc::AudioSendStream* createAudioSendStream( uint32_t ssrc, uint8_t payloadType, webrtc::Transport* transport, rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory, webrtc::Call* call) { webrtc::AudioSendStream::Config config{transport}; config.rtp.ssrc = ssrc; config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}}; config.encoder_factory = audioEncoderFactory; const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2}; config.send_codec_spec = webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat); webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config); audioStream->Start(); return audioStream; }
另外,WebRTC使用交互式连接建立(
ICE )来确定参与者之间的最佳路由。 由于我们有每个客户端都连接到服务器,因此不需要ICE。 如果您位于NAT之后,这可以使您提供更可靠的连接,并且还可以使IP地址对其他参与者保密。 客户端定期ping通,以使防火墙维持打开的连接。
最后,WebRTC使用安全实时传输协议(
SRTP )对媒体进行加密。 使用基于标准TLS的数据报传输层安全性(
DTLS )协议设置加密密钥。 内置的WebRTC库允许您使用
webrtc::Transport API来实现自己的传输层。
我们决定使用更快的
Salsa20加密代替DTLS / SRTP。 此外,我们不会在静音期间发送音频数据,这种情况很常见,尤其是在大型聊天室中。 这样可以节省大量带宽和CPU资源,但是,客户端和服务器都必须随时准备就绪,才能停止接收数据并重写音频/视频数据包的序列号。
由于Web应用程序使用基于浏览器的
WebRTC API实现,因此不能放弃SDP,ICE,DTLS和SRTP。 客户端和服务器交换所有必要的信息(交换数据包时,小于1200个字节)-并基于此信息为客户端建立SDP会话。 后端负责解决桌面和浏览器应用程序之间的差异。
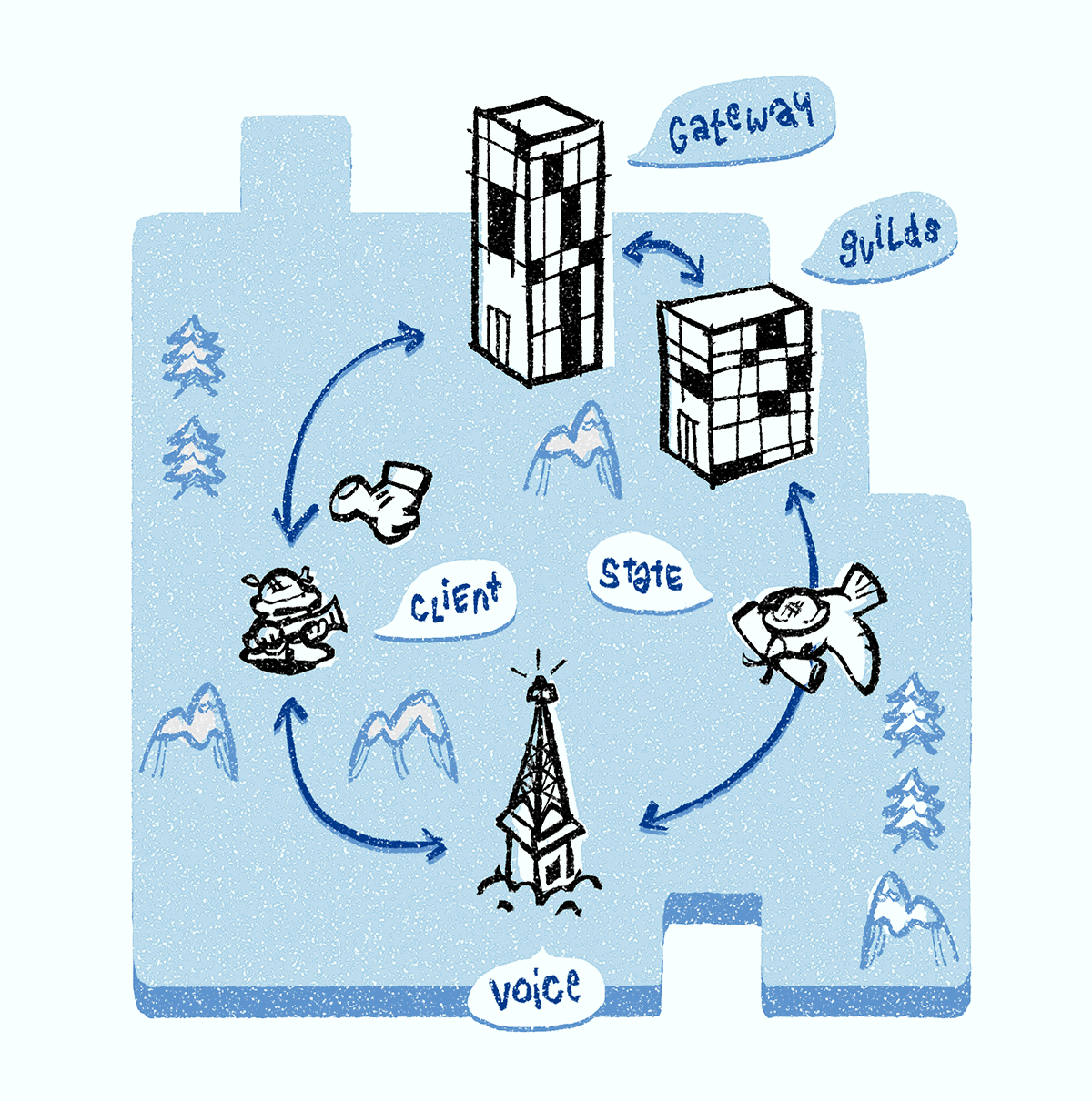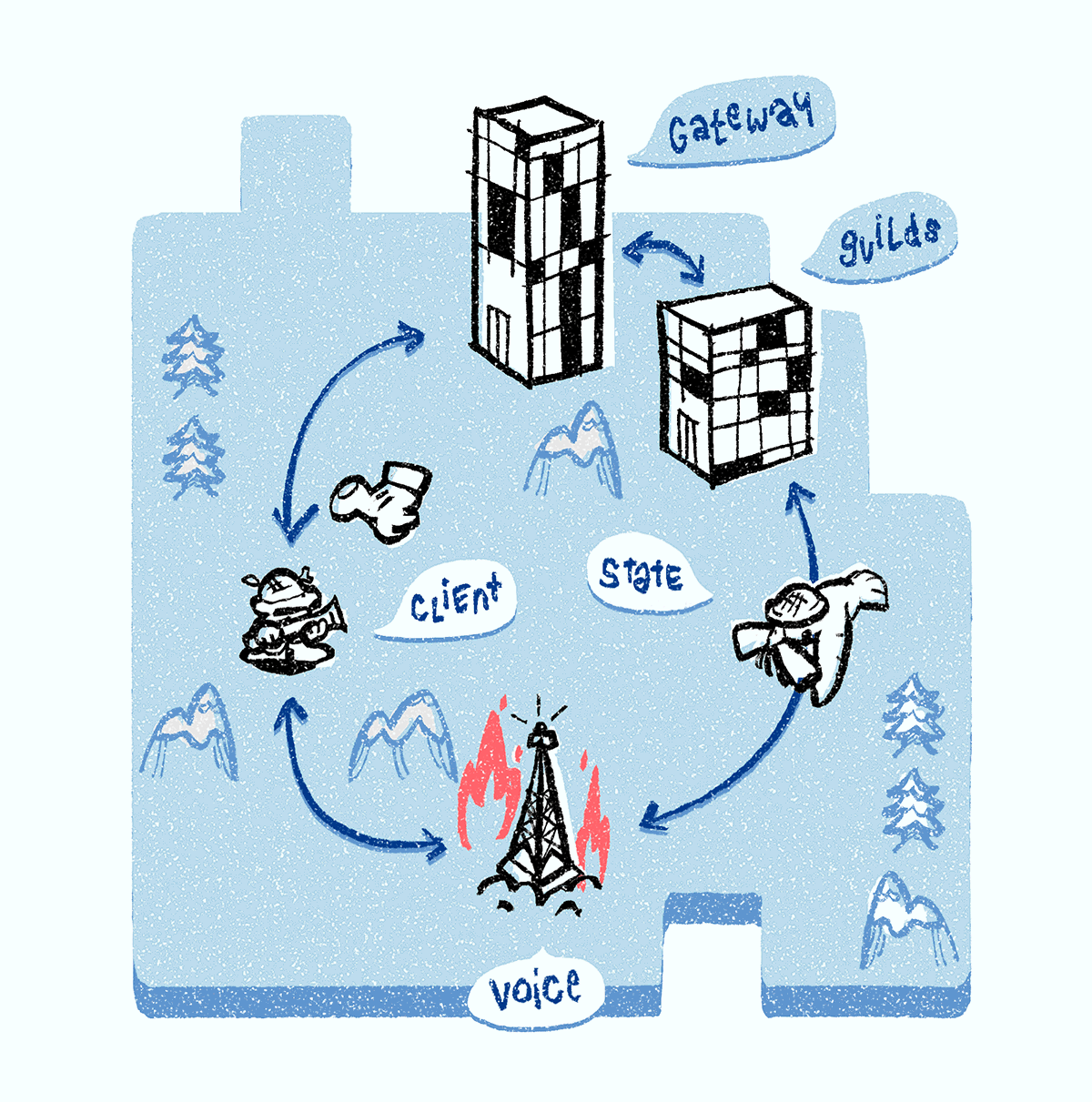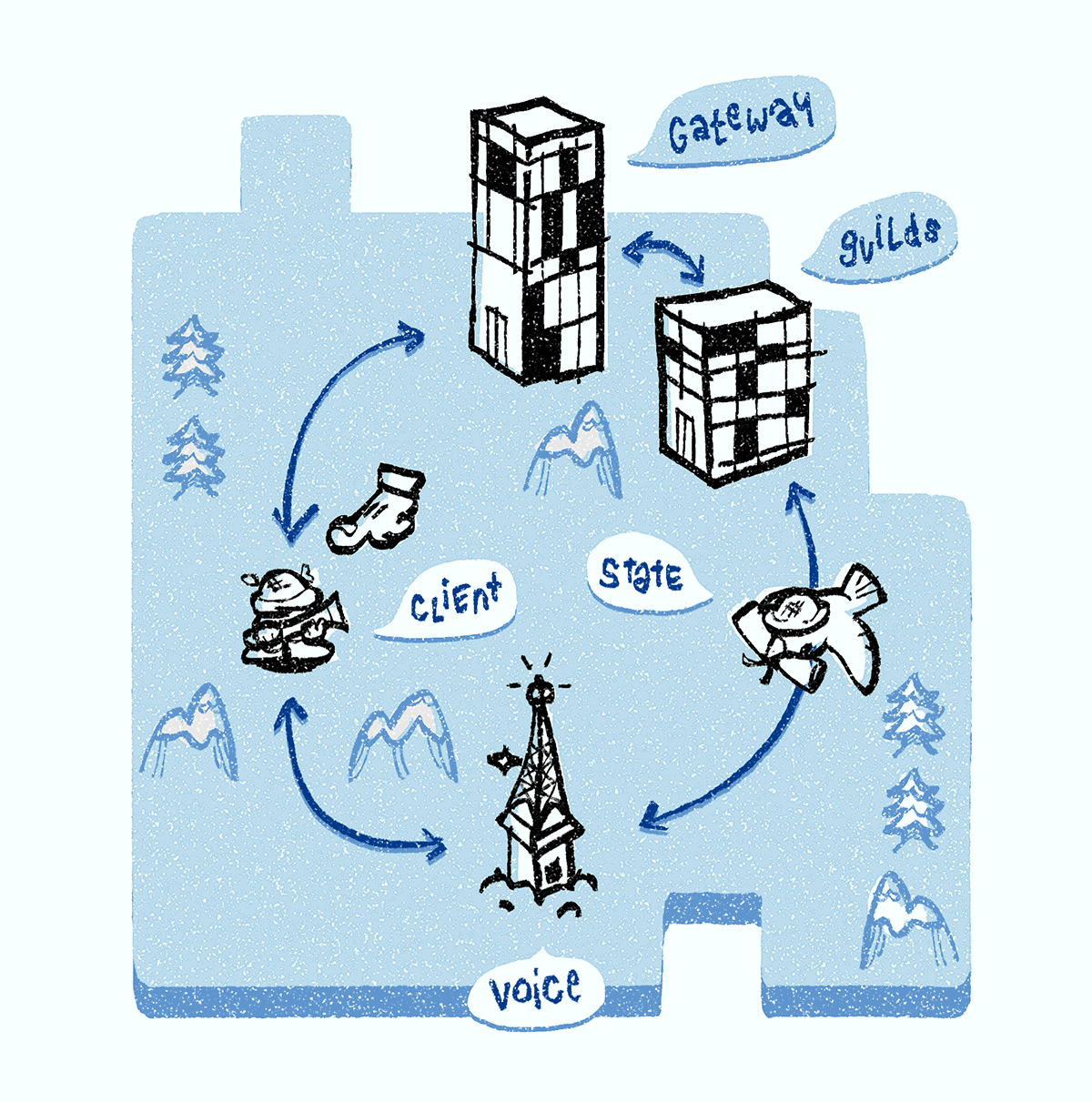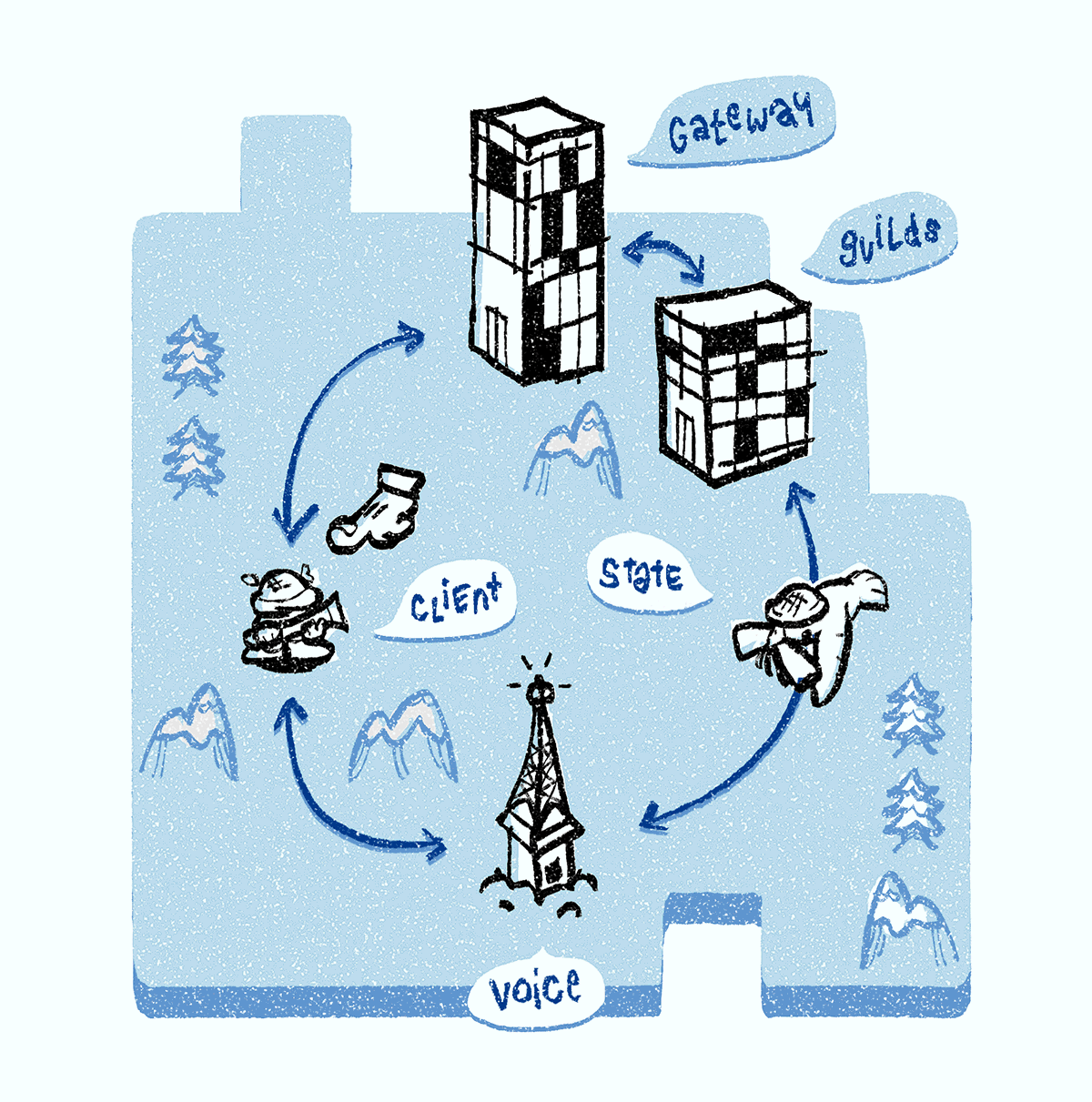
后端架构
后端有几种语音聊天服务,但我们将重点关注三种服务:Discord Gateway,Discord Guilds和Discord Voice。 我们所有的信号服务器都是用
Elixir编写的,这使我们能够重复使用代码。
联机时,客户端支持与Discord网关的WebSocket连接(我们称为WebSocket
网关连接)。 通过此连接,您的客户端会收到与组和频道,文本消息,状态包等相关的事件。
连接到语音通道时,连接状态由语音状态
对象显示。 客户端通过网关连接更新此对象。
defmodule VoiceStates.VoiceState do @type t :: %{ session_id: String.t(), user_id: Number.t(), channel_id: Number.t() | nil, token: String.t() | nil, mute: boolean, deaf: boolean, self_mute: boolean, self_deaf: boolean, self_video: boolean, suppress: boolean } defstruct session_id: nil, user_id: nil, token: nil, channel_id: nil, mute: false, deaf: false, self_mute: false, self_deaf: false, self_video: false, suppress: false end
连接到语音通道后,将为您分配Discord语音服务器之一。 他负责向通道中的每个参与者传输声音。 一组中的所有语音通道都分配给一个服务器。 如果您是第一个聊天,则Discord Guilds服务器负责使用下面描述的过程将Discord Voice服务器分配给整个组。
不和谐语音服务器目标
每个Discord Voice服务器都会定期报告其状态和负载。
如上一篇文章中所述,此信息放置在服务发现系统中(我们使用
etcd )。
Discord Guilds服务器监视服务发现系统,并为该组分配该区域中使用最少的Discord Voice服务器。 选中后,所有语音状态对象(Discord Guilds服务器也支持)被传输到Discord Voice服务器,以便它可以配置音频/视频转发。 通知客户端所选的Discord Voice服务器。 然后,客户端打开与语音服务器的
第二个 WebSocket连接(我们称为WebSocket
语音连接),该服务器用于配置多媒体转发和语音指示。
当客户端显示“正在
等待端点”状态时,这意味着Discord Guilds服务器正在寻找最佳的Discord Voice服务器。
语音连接消息表示客户端已与选定的Discord语音服务器成功交换UDP数据包。
Discord语音服务器包含两个组件:信号模块和多媒体中继单元,称为选择性转发单元(
SFU )。 信号模块完全控制SFU,并负责生成流标识符和加密密钥,重定向语音指示器等。
我们的SFU(使用C ++)负责在通道之间引导音频和视频流量。 它是独立开发的:对于我们的特殊情况,SFU可提供最佳性能,因此可最大程度地节省成本。 当主持人违反(使服务器静音)时,不会处理其音频数据包。 SFU还充当本机应用程序和基于浏览器的应用程序之间的桥梁:它为浏览器和本机应用程序实现传输和加密,并在传输期间转换数据包。 最后,SFU负责处理
RTCP协议,该协议用于优化视频质量。 SFU收集并处理来自接收者的RTCP报告-并通知发送者哪个频段可用于视频传输。
容错能力
由于只有Discord Voice服务器可以直接从Internet获得,因此我们将对其进行讨论。
信号模块持续监控SFU。 如果崩溃,它会立即重启,并且服务暂停最少(丢失了几个数据包)。 SFU状态由信号模块恢复,而无需与客户端进行任何交互。 尽管SFU崩溃很少见,但我们使用相同的机制来更新SFU,而不会中断服务。
当Discord Voice服务器崩溃时,它不会响应ping-并从服务发现系统中删除。 客户端还注意到由于WebSocket语音连接断开而导致服务器崩溃,然后
客户端通过WebSocket网关连接请求
ping语音服务器 。 Discord Guilds服务器确认故障,查询服务发现系统,并为该组分配新的Discord Voice服务器。 然后,不和谐公会将所有语音状态对象发送到新的语音服务器。 所有客户端都会收到有关新服务器的通知,并连接到该服务器以启动多媒体设置。
经常,Discord Voice服务器属于DDoS(我们通过传入IP数据包的快速增加看到这一点)。 在这种情况下,我们执行与服务器崩溃时相同的过程:将其从服务发现系统中删除,选择一个新服务器,将所有语音通信状态对象传输到该服务器,然后将新服务器通知客户端。 当DDoS攻击消退时,服务器将返回服务发现系统。
如果小组所有者决定选择一个新的区域进行投票,我们将遵循非常类似的程序。 Discord Guilds Server与服务发现系统协商,在新区域中选择最佳的可用语音服务器。 然后,他将语音通信状态的所有对象转换为该对象,并向客户端通知新服务器。 客户端断开与旧的Discord Voice服务器的当前WebSocket连接,并与新的Discord Voice服务器创建新的连接。
缩放比例
Discord Gateway,Discord Guilds和Discord Voice的整个基础结构都支持水平缩放。 Discord Gateway和Discord Guilds在Google Cloud中工作。
我们在全球13个地区(位于30多个数据中心)拥有850多个语音服务器。 如果数据中心和DDoS发生故障,该基础架构可提供更大的冗余。 我们与多个合作伙伴合作,并在其数据中心中使用我们的物理服务器。 最近,增加了南非地区。 由于在客户端和服务器体系结构方面的工程努力,Discord现在能够同时以超过220 Gbit / s和每秒1.2亿个数据包的传出流量为超过260万语音聊天用户提供服务。
接下来是什么?
我们不断监控语音通信的质量(指标从客户端发送到后端服务器)。 将来,此信息将有助于自动检测和消除降级。
尽管我们在一年前启动了视频聊天和截屏视频,但是现在它们只能用于私人消息中。 与音频相比,视频需要更多的CPU能力和带宽。 挑战在于平衡带宽量和用于确保最佳视频质量的CPU / GPU资源,尤其是当通道中的一组游戏玩家位于不同设备上时。
可扩展视频编码 (SVC)技术是H.264 / MPEG-4 AVC标准的扩展,可以成为该问题的解决方案。
由于与传统的网络摄像头相比,FPS和分辨率更高,因此截屏视频需要比视频更多的带宽。 我们目前正在努力在桌面应用程序中支持基于硬件的视频编码。