时间不多了,很快这种发展几乎一无所有,但我仍然没有时间描述它。
这将是关于联邦一级拥有大量分支机构和分支机构的公司。 但是,像往常一样,这一切都是从很久以前的一家小商店开始的。 多年来,发生了相当迅速和自发的发展,分支机构,部门和其他办公室出现了,并且在那时,IT基础架构没有得到应有的重视,这也是经常发生的情况。 当然,1C77随处可见,没有任何复制和缩放的储备,因此,您知道,最终我们得出的结论是,Sprut-Frankenstein的触角用胶带绑住了-在每个分支中都有一个与中心碱基交换的自主突变体在“膝盖高”模式下,只有几本参考书,没有这些书,那是根本不可能的,其余的是自主的。 一段时间以来,他们对中心办公室的分支机构的副本(数十个!)感到满意,但其中的数据滞后了几天。
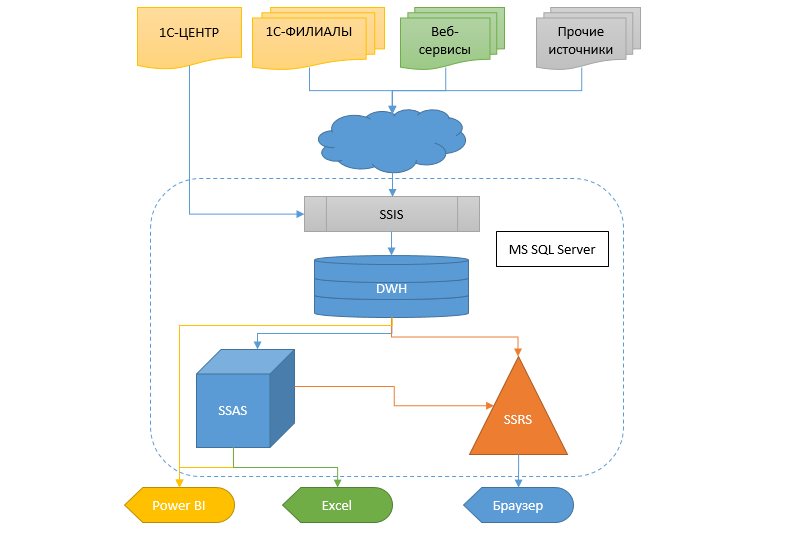
但是,现实需要更快,更灵活地获取信息,并且还需要做其他事情。 从这样一个规模的会计系统转移到另一个会计系统仍然是一片沼泽。 因此,决定创建一个数据仓库(DX),在该仓库中信息将从不同的数据库中流出,以便以后的其他服务和多维数据集,SSRS报告和泄漏形式的分析系统可以从此CD接收数据。
展望未来,我要说的是,向新会计系统的过渡几乎已经完成,这里描述的大多数项目都将在不久的将来被削减,因为这是不必要的。 对不起,当然,但是什么也做不了。
以下是一篇很长的文章,但是在您开始阅读之前,请允许我说,我决不会将此决定作为标准来通过,但是也许有人会从中找到有用的东西。
我将从对该项目的一般方法开始,为此选择了SSDT作为开发环境,随后在Git中发布了该项目。 我认为,今天有足够多的文章和教程来描述此工具的优势。 但是有一些问题是在这种环境之外的。
枚举和数据库版本的存储
关于版本和枚举,该项目的要求是:
- 方便地编辑和跟踪项目中数据库版本的更改
- 方便管理员通过SSMS查看数据库版本
- 将版本更改的历史记录保存在数据库本身中(部署的对象和时间)
- 在项目中存储枚举
- 轻松编辑和跟踪转账更改
- 如果没有增量版本,则将数据库部署锁锁定在现有锁上
- 安装新版本,记录历史记录,传输和重组应在一个事务中执行,并在任何阶段出现故障时完全回滚
因为 传输通常包含逻辑并且是基本值,没有这些值,就不可能将记录添加到其他表中(由于FK外键),实质上,它们与元数据一起是数据库结构的一部分。 因此,任何枚举元素的更改都会导致数据库版本的增加,并且必须确保与该版本一起增加记录的部署期间。
我认为在不增加版本的情况下阻止部署的所有优点都是显而易见的,其中之一是如果已经早先成功执行了发布脚本,则无法重新运行发布脚本。
尽管通常建议数据库网络仅使用主要版本(不带分数),但我们决定使用XY格式的版本,其中Y是在表,列,列表元素的名称或其他较小内容的描述中纠正拼写错误时的补丁程序,例如在存储过程中添加注释等。 在所有其他情况下,都会建立主要版本。
也许对于某人而言,没有什么比
这更明显了。 但是在适当的时候,我就如何在数据库项目中存储转移的内部争议花了很多神经和精力,因此是风水(
按照我的想法 ),与他们合作很方便,同时最大程度地减少错误的可能性。
通常,使用传输,一切都很简单-我们在项目中创建一个PostDeploy文件,并在其中编写代码以填充表。 使用合并或拖曳-这就是您喜欢的方式。 我们希望闪烁一下,以预先检查目标表中的记录数是否超过源(项目)中的记录数。 如果超过,则抛出异常以引起注意,因为它很奇怪。 为什么源中的记录更少? 因为一个人多余吗? 为什么突然呢? 如果数据库已经有链接? 尽管我们使用外键(FK)(不允许您删除记录),但是如果有链接,我们仍然希望保留此选项。 结果,PostDeploy变成了一个不可读的工作表,因为对于每个要填充的表,除了值本身之外,还存在验证码,合并等。
但是,如果在SQLCMD模式下使用PostDeploy,则有可能将代码块提取到单独的文件中,因此,仅保留结构化的文件名列表来填充PostDeploy中的枚举。
数据库版本有些细微差别。 互联网一直在争论数据库版本的存储位置,外观以及通常是否需要将其存储在某个地方? 假设我们决定需要它,将它存储在项目的哪个位置? 在PostDeploy脚本的某个地方,还是将其放在脚本第一行中声明的变量中?
我认为,两者都不是。 当将其存储在单独的文件中时,此功能更加方便。
有人会说-项目属性中有dacpac,您可以在其中设置版本。 当然,您甚至可以按照
此处的描述将此版本拖入脚本中,但这很不方便-要更改数据库版本,您需要走很远的地方,单击一堆按钮。 我不了解Microsoft的逻辑-他们将它与排序,兼容性级别等数据库参数一起藏在一个遥远的角落,因为数据库版本作为排序参数的变化通常是“经常”,对吧? 如果进行持续的开发,那么每次部署新版本时都会建立该版本,因此,跟踪更改的便利性也起着重要作用,因为当点亮一个带有友好名称的已更改文件时,这是一回事,而当点亮.sqlproj项目文件时,其中XML格式的行很多,并且在该行中间的某个位置突出显示了一个更改的数字,但不是很明显。
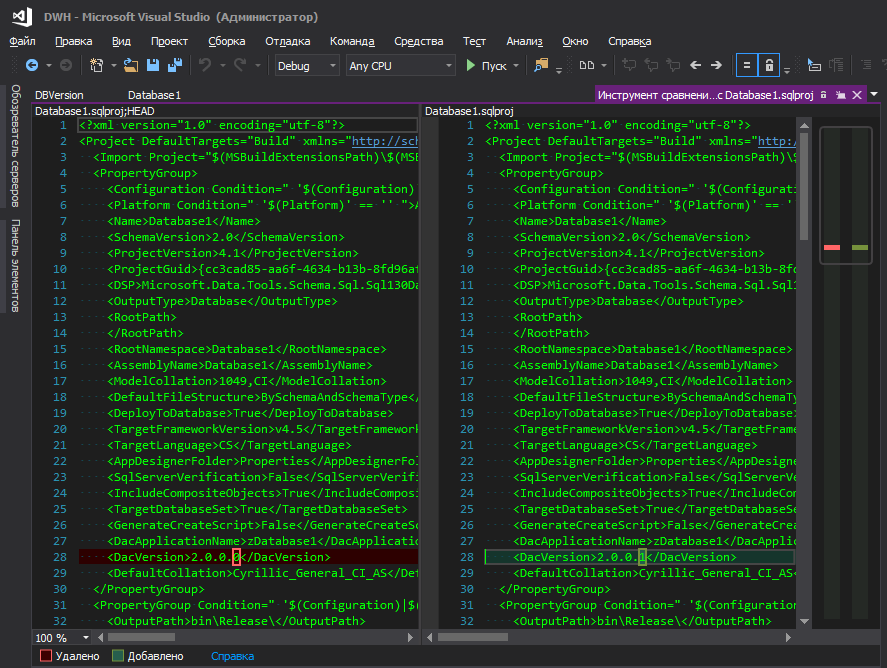
这样更好
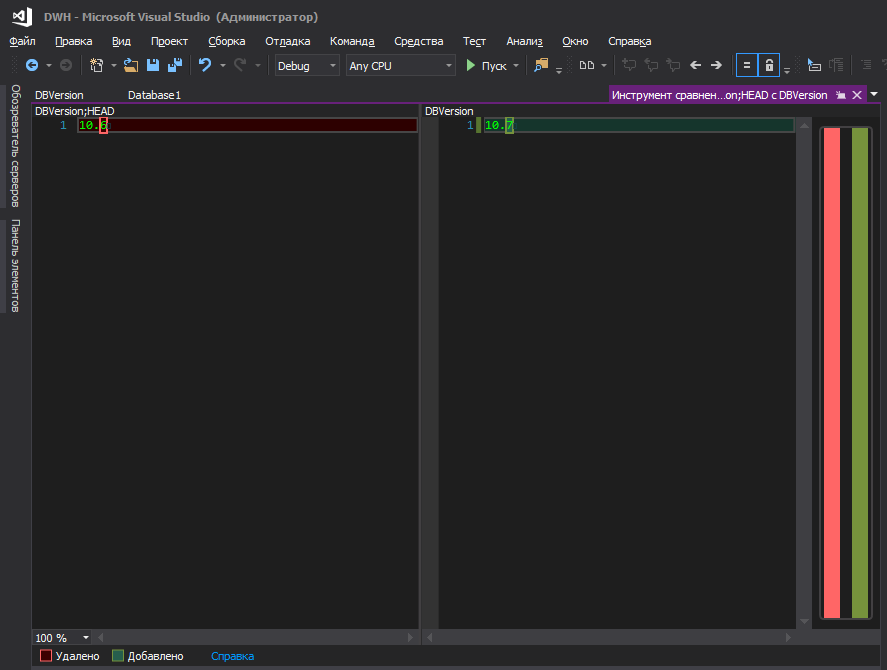
但是,也许这些只是我的蟑螂,您不应该注意它们。
现在的问题是:已经在部署的数据库中存储此版本的位置。 再次,dacpac似乎做得很漂亮-它将所有内容都写到系统板上,但是要查看版本,您需要执行请求(或者可以执行该请求,但是我只是不知道如何烹调它们?似乎在旧版SSMS中有一个接口可以用于此操作,现在不)
select * from msdb.dbo.sysdac_instances_internal
对于管理员(不仅是),这不是很方便。 将版本直接显示在数据库本身的属性中更加合乎逻辑。

还是不行
为此,您需要向项目中添加文件,该文件包含在内部版本中,以描述高级属性。
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
是的,它们是空的,在发布脚本中看起来很难看,但是没有它们就不能做。 如果项目中未对它们进行描述,并且它们将存在于数据库中,那么Studio将在每次部署时尝试删除它们。 (已经进行了许多尝试来简洁地解决此问题,并且没有不必要的部署选项,但无济于事)
我们将在PostDeploy脚本中为其设置值。
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty无需任何检查,因为从PostDeploy启动该块时,如果不存在所有属性,则已经创建了所有属性。
好吧,最好保留有关谁在何时部署数据库的历史记录。
通过选中“
高级发布选项”窗口中的“
启用事务脚本”框,可以使用标准工具在事务中执行元数据更改的部署。 但是此标志不会影响脚本(Pre / Post)的部署,并且它们可以继续运行而无需事务。 当然,没有什么可以阻止事务从PostDeploy脚本的开头开始,但是它将是与元数据分开的事务,并且我们的任务是在PostDeploy中发生异常时回滚元数据更改。
解决方案很简单-在PreDeploy中启动事务,然后在PostDeploy中提交,并且出于这些目的,请勿在发布设置中使用任何选中标记。
为了方便地将数据库版本存储在项目中并在部署过程中将其注册在所需的位置,可以使用SQLCMD变量。 但是,我不想将版本存储在代码的繁杂部分中,而是希望将其存储在表面上。
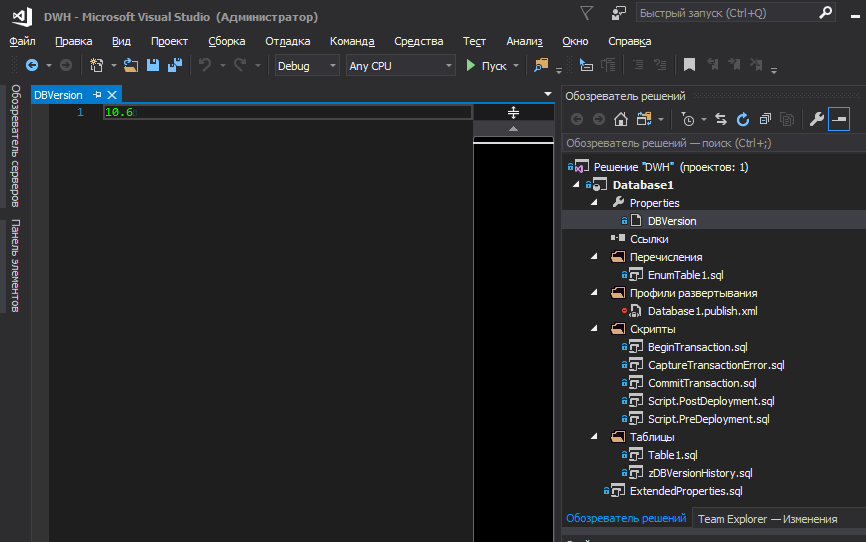
为了将数据库版本放在一个单独的文件中,并在项目级别从那里管理版本,我们在.sqlproj中添加以下块:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
这是MSBuild在构建文件并基于读取的数据创建临时文件之前从文件中读取一行的指令。 MSBuild将创建一个临时的
SetPreDepVarsTmp.sql文件,该文件将
:setvar DBVersion $(ExtDBVersion)行
:setvar DBVersion $(ExtDBVersion) ,其中
$(ExtDBVersion)是从存储数据库版本的文件中读取的值。
经过此类操作后,您可以从PreDeploy脚本中引用此临时文件并在其中启动全局事务:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
中级版本最初,为ExtendedProperties.sql文件分配的不是空值,而是变量中的值
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
依次由MSBuild将变量自动注册到SetPreDepVarsTmp.sql文件中,如下所示:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
使用这种方法,您不需要在PostDeploy中重新安装这些属性,但是麻烦的是SetPreDepVarsTmp.sql包含静态值,并且如果发布脚本是现在生成的,但是在一小时或更晚的第二天(开发人员检查了很长时间)之后就部署了例如,在视觉上),属性中指定的发布日期将不同于实际的发布日期,并且与历史记录中的日期不一致。
BeginTransaction.sql文件的内容本质上,这只是从Studio选中“
启用事务脚本”复选框时生成的标准事务开始块进行复制粘贴,但是我们以自己的方式使用它。 在脚本中,只有临时表名称已从
#tmpErrors更改为
#tmpErrors ,因此,如果有人打开该复选框,则不会发生名称冲突。
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
PostDeploy脚本 declare @TableName VarChar(255) = null
SkipEnumDeploy变量已经很清楚了,它允许您跳过更新清单的阶段;这对于较小的外观更改很有用。 尽管从宗教的角度来看,这可能不是正确的,但是在开发阶段肯定是有用的。
文件
CaptureTransactionError.sql和
CommitTransaction.sql也是从Studio设置上述标志时生成的标准交易算法中复制粘贴(经过较小的更正)的,现在我们可以自己播放。
内容CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
内容EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
部署
Publish脚本将具有以下结构
当然,理想情况下,我希望该版本在发布时显示

但是,您无法将文件中的值拉到该窗口中,尽管MSBuild会读取该值并将其通过.sqlproj文件中的其他指令(如上例所示)放入ExtDBVersion属性中,但该构造
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
不滚动。
续集开发人员在其
网络日记中写下了如何完成此工作。 根据它们的版本,魔术在于
SqlCommandVariableOverride指令,该指令很简单-向.sqlproj项目文件中添加几行
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
完成。 不错的尝试,但是没有。 也许当这篇博客文章发表时,一切都奏效了,但是从那时起,在这些美国,您已经举行了三届总统大选,没人知道明天会有什么指示停止。

一个同志
在这里尝试了所有选择,但没有一个选择。
因此,从dacpac获取版本,或将其存储在PostDeploy中,或存储在单独的文件中,或_________(输入您的版本)。
与1C集成
第一个问题是1C77没有应用程序服务器或其他守护程序,允许它在不启动平台的情况下与其进行交互。 那些使用1C77的人知道她没有完整的控制台模式。 您可以使用参数运行平台,甚至可以基于参数进行操作,但是控制台参数很少,其用途有所不同。 但是即使有他们的帮助,您也可以将它们组合在一起。 但是,它可能会意外地飞出,它可能会弹出一个模式窗口,并等待某人单击“确定”和其他超级按钮。 也许,最大的问题-平台的速度有很多不足之处...因此,只有一种解决方案-直接查询1C数据库。 有了这样的结构,您不仅可以接受并编写这些查询,而且好处是整个社区一次都开发了一个很棒的工具-1C ++(1cpp.dll),这对他们来说是不可思议的! 该库允许您以1C的形式编写查询,然后将其转换为表和字段的真实名称。 如果任何人都不知道,则可以使用伪名称编写请求,看起来像这样
select from $.
这样的请求是人类可以理解的,但是服务器上没有这样的表和字段,还有其他名称,因此1C ++会将其转换为
select SP5278 from SC2235
服务器已经理解了这样的请求。 每个人都很高兴,没有人发誓-一个人也不是服务器。 在这里,问题似乎已经解决。
第二个问题在于配置平面:在分支机构中使用一种配置,在中心局中使用另一种配置,在分支机构中使用第三种配置! 课?!! 1我也这么认为。 而且,它们不是典型的,甚至不是典型的遗产,而是在维京人时期完全从头开始编写的,不幸的是,并不是最好的架构师为这些配置奠定了基础。例如,《实现》文档在每种配置中都有一组不同的详细信息。 但是,不仅某些字段的名称不同,当详细信息的名称相同时,这更有趣,而且存储在其中的数据的含义也不同。

在配置中,几乎不使用任何寄存器,所有内容都建立在复杂的文档上。 因此,有时我不得不在一个干净的事务上写一整张纸,包括大量的案例和联接,以重复配置中某些过程的逻辑,该过程在表单的文本字段中显示一些信息。
我们必须向开发团队致敬,这些年来,开发团队一直支持他们从“执行者”那里继承的东西,这是一项艰巨的工作-支持它甚至优化某些东西。 直到您看到-您不了解,我自己最初都不相信所有事情都可能如此复杂。 问-为什么不从头开始重写? 普遍缺乏资源。 公司发展如此之快,以至于尽管有一大批程序员,但他们根本无法满足业务需求,更不用说重写整个概念了。
我们继续讲述请求的故事。 显然,所有用于数据提取的块都变成了存储,以便以后可以绕过1C平台在服务器端启动它们。 规则是这样的:一个存储负责检索一个实体。 因为 愿望清单在开始阶段已经积累了很多,因为多年来变得很痛苦,然后出现了数十个存储文件。
第三个问题是如何提高开发速度和质量,然后如何支持所有这些怪物? 编写1C ++的请求,然后将其转换结果复制粘贴到存储中? 此外,这非常不方便且乏味,而且出错的可能性很高-复制错误的一个或错误的一个或不选择查询的最后一行,然后在没有查询的情况下进行复制。 在直接进行1C查询时尤其如此,因为没有诸如
Directory。Nomenclature。Article的伪名称,只有真实名称
SC2235.SP5278 ,因此将请求从商品目录下复制到检索顾客的商店非常简单。 当然,由于目标表中字段的类型和数量不匹配,请求很可能会下降,但是存在相同的图板,例如枚举,其中只有两列是ID和Name。 通常,仅保留某种自动化即可。 好吧,足够的歌词,让我们开始吧!
我希望存储开发过程可以归结为以下内容:
- 我们使用伪名称修复SQL查询并保存它
- 我们按下魔术按钮,然后在出口处收到转换后的SQL上已更正的存储过程,并已清除至服务器
一些细节
为了解决第三个问题,编写了外部处理(.ert)。 处理中有许多过程,每个过程都包含用于使用伪名提取一个实体的查询文本,例如
select * from $.
在处理表格上,有一个用于显示特定过程结果的字段,即 请求转换为服务器可以理解的形式,以便您可以快速尝试。 另外,
调试块总是添加到该请求中,其中包含变量的声明,测试数据库的名称,服务器等。 它仅保留在SSMS中复制粘贴并按F5键。 当然,您可以从处理本身执行此请求,但是您可以理解请求计划以及所有这些……通常,这就是调试的方式。 因为 有几种配置;在处理中,可以将带有对象伪名的相同查询文本转换为针对不同配置的最终查询。 实际上,在一个会议术语中引用的名称是SC123,在另一个会议中引用的名称是SC321。 但是1C ++允许您在运行时加载不同的配置,并根据字典为每个配置生成单独的输出。
接下来,将批处理运行模式添加到处理中,当它自动启动每个配置的每个过程时,每个过程的输出都将写入.sql文件(以下称为基本文件)。 因此,我们得到了一堆基本文件的组合,这些组合随后将使用VS自动转换为存储过程。 值得注意的是,基本文件包含
调试块 。
似乎为什么不立即对存储过程的最终文件做出结论,并在此过程中保留所有内容? 事实是,对于某些测试,有必要在声明所有变量的批处理中运行查询的调试版本,再加上我希望绕过1C从VS管理存储过程名称,因为这是合逻辑的,不是吗?
顺便说一句,基本文件也存储在项目中,当然,现成的存储过程的文件也存储在项目中。 任何时候都可以在不启动1C的情况下在SSMS中打开基础文件并执行该文件,而不必担心变量声明。
在处理中,所有带有请求的过程也是模板,具有相同的参数集,但是在该过程中,仅使用必要的参数。 在某些情况下,涉及到所有事情,而在某些情况下,两个就足够了。 因此,添加新过程归结为复制模板并使用查询本身填充参数。
其中一个处理过程的代码,之后将变成存储过程
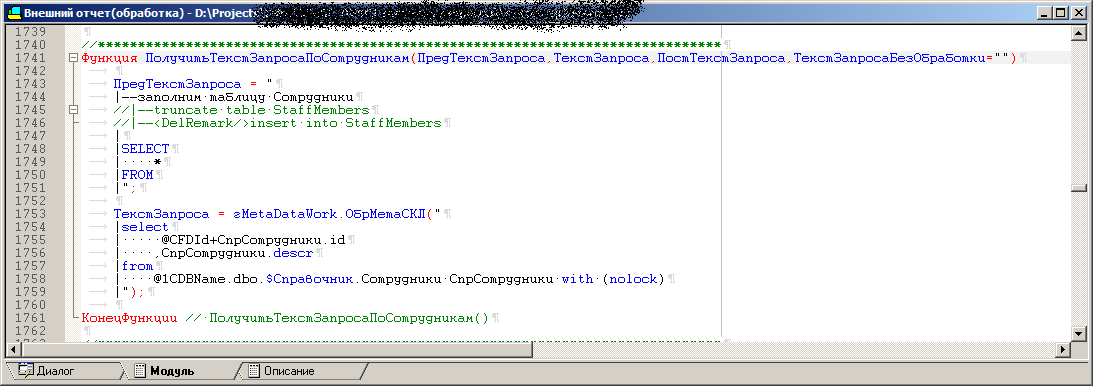
最终查询是这样的:
++"("+OPENQUERY()+")"+
加工外观

切换配置时,“数据”列表中用于卸载项目的可用(必要)项目列表会更改。 如果可能,将1C中的过程代码尽可能地统一。 如果提取了交易对手,并且这些目录在不同的配置中不一致,则生成过程中会有不同的情况,例如:此块对每个人都是固定的,仅针对这种confon将此块添加到最终请求中,而另一个对另一个confon。 事实证明,在一个实体的存储过程中,但是在不同的配置中,它们不仅可以因表名而异,而且可以因一个实体中存在而另一实体中不存在的整个连接块而不同。 当然,输出字段的集合是相同的,并且对应于接收器表或SSIS包的容器,对于一些配置,其中的字段原则上不是这些细节,因此某些字段会被存根阻塞。
魔术按钮Visual Studio具有MSbuild和出色的T4模板等工具。 因此,作为魔术按钮,用C#编写了T4脚本,它是:
- 在注册表中注册一个空配置(否则1C将显示一个模式窗口,其中包含建议注册conf并等待用户操作的建议)
- 在SQL Server上为此konf创建一个空数据库,因为没有它,1C会报错
- 启动1C,并通过OLE告诉它执行处理(相同的.ert),还将唯一的GUID传输到1C
- 输出是一系列具有现成(已转换)请求的文件和一个标记文件,在启动时收到的GUID被写入其中
- 从注册表中删除conf的注册,并从服务器中删除一个临时的空数据库
- 检查令牌文件的内容。 如果标记文件包含我们在启动时传递给1C的GUID,则表示它工作到最后,没有崩溃等,然后转到下一步,否则我们显示错误
- 我们创建存储。
- 我们使用gcomp对.ert文件进行反编译,以获取模块文本和处理形式,然后我们将其转换为Unicode,以便随后发送至Git并在其中正确显示。 对于那些不使用1C的用户:.ert文件是二进制文件,而Studio和git一起吹嘘.ert文件已更改,但是不清楚其中到底有什么更改,也许只是有人将按钮向左移动了一个像素(没有理由就无法接受)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
. 做完了
?因为 , , .sqlproj,
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
,
OPENQUERY , 1 , , , ,
EXEC .
OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
— . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
ETL
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
因为 1 , , . , ,
truncate .
, ( ) -, « 1-» .
SSIS
,
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). 即 , . , , . - — . .
, (.. ) .
, , .
聚苯乙烯
, , , , . — , . - , , .