本说明是JPoint 2018会议上我的报告“如何用低效率的代码破坏性能”的书面版本。您可以在会议页面上观看视频和幻灯片。 在时间表中,该报告标有一杯冰沙,因此不会出现任何超级复杂的情况,这对于初学者而言更可能。
报告主题:
- 如何查看代码以在其中找到瓶颈
- 常见的反模式
- 非明显耙
- 耙式旁路
在场外,他们指出了报告中的一些不准确性/遗漏之处,并在此处指出。 也欢迎发表评论。
绩效对绩效的影响
有一个用户类:
class User { String name; int age; }
我们需要将对象彼此进行比较,因此我们声明equals和hashCode方法:
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
该代码是可行的,但问题不同:该代码的性能是否最佳? 为了回答这个问题,让我们回想一下Object::equals方法的功能:仅当所比较的所有字段都相等时,它才返回正结果,否则结果将为负。 换句话说,一个差异已经足以产生负面结果。
查看为@EqualsAndHashCode生成的代码后@EqualsAndHashCode我们将看到类似以下内容:
public boolean equals(Object that) {
检查字段的顺序与它们声明的顺序相对应,在我们的情况下,这不是最佳解决方案,因为使用equals比较对象比比较简单类型“难”。
好的,让我们尝试使用Idea创建equals/hashCode方法:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
一个想法创建了更智能的代码,该代码知道比较不同类型的数据的复杂性。 好吧,我们将@EqualsAndHashCode ,并将显式编写equals/hashCode 。 现在,让我们看看类扩展时会发生什么:
class User { List<T> props; String name; int age; }
重新创建equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
在比较字符串之前先比较列表,这在字符串不同时没有意义。 乍一看并没有太大区别,因为等长字符串通过符号进行比较(即,比较时间随字符串长度的增长而增加):
有一个不准确的地方java.lang.String::equals 方法是侵入式的 ,因此在执行时没有登录比较。
现在考虑比较两个ArrayList (作为最常用的列表实现)。 检查ArrayList ,我们很惊讶地发现它没有自己的equals实现,但是使用了继承的实现:
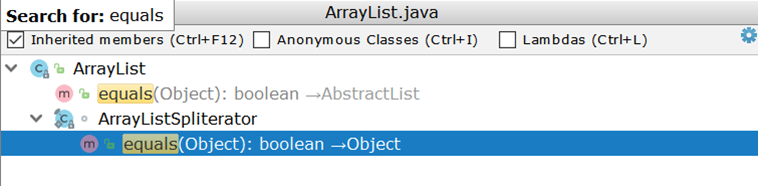
这里重要的是创建两个迭代器并成对通过它们。 假设有两个ArrayList :
理想情况下,比较两个列表的大小就足够了,如果它们不重合,立即返回负结果(就像AbstractSet一样),实际上,将执行99个比较,并且仅在十分之一时就可以清楚看出列表是不同的。
Kotlinites有什么?
data class User(val name: String, val age: Int);
这里的一切就像龙目岛-比较顺序对应于公告的顺序:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
解决方法是,您可以手动组织字段声明。
让任务复杂化
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
该代码包括即使事先可以确定箭头指示的条件的检查结果也要访问数据库。 如果valid变量的值为false,则if块中的代码将永远不会执行,这意味着您可以在没有请求的情况下进行操作:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
请注意当从JpaRepository::findOne返回的实体已经在第一级的缓存中时,下沉就可以忽略不计了-这样就不会有请求了。
没有显式分支的类似示例:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
快速返回可让您延迟请求:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
报告中未出现的相当明显的补充假设某张支票使用类似的实体:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
如果检查使用相同的实体,则应确保在对已加载的字段的调用之后执行对“惰性”子实体/集合的调用。 乍一看,一个额外的请求不会对整体情况产生重大影响,但是当一个动作在一个循环中执行时,一切都会改变。
结论:应该按顺序增加操作/检查的顺序,以增加单个操作的复杂性,也许其中某些操作将不必执行。
周期和批量处理
以下示例不需要特殊说明:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
由于存在多个数据库查询,因此代码运行缓慢。
备注如果在事务外部执行enrollStudents方法, enrollStudents性能会进一步enrollStudents :然后,对osdjrJpaRepository::findOne 每次调用将在新事务中执行(请参见SimpleJpaRepository ),这意味着接收并返回与数据库的连接,以及创建和刷新第一级缓存。
修正:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
让我们测量一组键(10和100个)的运行时间(以微秒为单位) 基准测试
备注如果使用Oracle并传递超过1000个键来findAll ,则将获得异常ORA-01795: maximum number of expressions in a list is 1000 。
同样,在-查询中执行繁重的操作(具有许多键)可能比n次查询更糟糕。 这完全取决于特定的应用程序,因此将循环机械替换为批量处理会降低性能。
关于同一主题的更复杂的示例
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
在这种情况下,我们不能用JpaRepository::findAll替换循环, JpaRepository::findAll这将破坏逻辑:从JpaRepository::findAll获得的所有值都不会为null ,并且if块将不起作用。
对于每个数据库密钥,这一事实将帮助我们解决这一难题
返回实际值或不存在的值。 也就是说,从某种意义上说,数据库就是字典。 包装盒中的Java为我们提供了字典的现成实现HashMap在其之上,我们将构建用于替换数据库的逻辑:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
反例
此代码始终创建一个新的事务来保存实体列表。 下垂始于多次调用打开新事务的方法:
解决方案:立即对整个数据集应用Saver::save方法:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
许多事务合并为一个,这带来了明显的增长(时间以微秒为单位): 基准测试
具有多个事务的示例很难形式化,这不能说是在循环中调用JpaRepository::findOne 。
该方法不仅适用于数据库,因此Tagir lany Valeev走得更远。 如果更早些,我们这样写:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
一切都很好,现在“想法”建议纠正自己:
List<Long> list = new ArrayList<>(); list.addAll(items);
但是,即使此选项也不总是令人满意,因为您可以使其更短,更快:
List<Long> list = new ArrayList<>(items);
比较(以ns为单位的时间)对于ArrayList,此改进显着增加了:
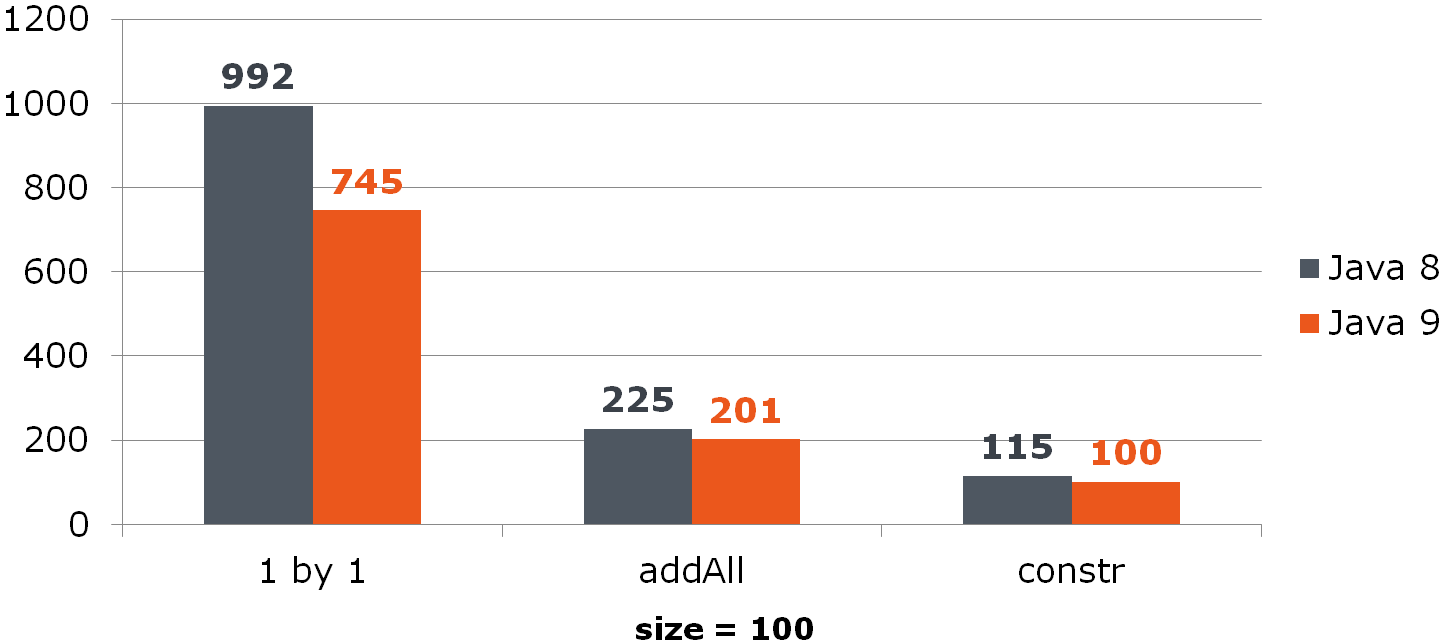
对于HashSet,它并不那么乐观:

基准测试
从ArrayList删除
for (int i = from; i < to; i++) { list.remove(from); }
问题在于实现List::remove方法:
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
解决方案:
list.subList(from, to).clear();
但是,如果源代码中使用了远程值,该怎么办?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
现在,您需要首先浏览清除列表:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
如果您确实要在循环中删除,则更改通过列表的方向将有助于减轻痛苦。 其含义是在清洁单元后移动较少数量的元素:
比较所有三种方法(在列下方是大小为100的列表中已删除项目的百分比):
顺便说一句,有人注意到异常了吗?
看
如果我们删除从末尾移动的所有数据的一半,那么最后一个元素将始终被删除,并且没有移位:
基准测试
结论:批量操作通常比单个操作更快。
范围和表现
此代码不需要任何特殊说明:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
我们缩小范围,这给了减号1的查询:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
在这里,细心的读者应该问:静态分析如何? 为什么Idea不告诉我们表面上的改进?
事实是静态分析的可能性是有限的:如果该方法很复杂(特别是与数据库交互)并且影响了常规状态,那么转移其执行可能会破坏应用程序。 静态分析器能够报告非常简单的执行,例如,在块内的传输不会破坏任何内容。
您可以将变量突出显示用作eratz,但再次使用它时要小心,因为总是可能产生副作用。 您可以使用jetbrains-annotations库中提供的注解@org.jetbrains.annotations.Contract(pure = true)来指示无状态方法:
结论:过多的工作只会使性能恶化,这种情况常常发生。
最不寻常的例子
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
即使不需要事务(此方法的快速返回-1),此实现也会打开事务。
您需要做的就是在需要的地方删除ContractCounter::countContracts内的事务性,然后将其从“外部”方法中删除。
基准测试
结论:控制器和“外向”服务需要摆脱事务性(这不是他们的责任),并且应该删除不需要访问数据库和事务性组件的输入数据验证的整个逻辑。
将日期/时间转换为字符串
永恒的任务之一是将日期/时间转换为字符串。 在八国集团之前,我们这样做:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
随着JDK 8的发布,我们获得了LocalDate/LocalDateTime以及相应的DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
让我们衡量一下它的性能:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
问题:假设我们的服务从外部接收数据,我们不能拒绝java.util.Date 。 如果将LocalDate更快地转换为字符串,将Date转换为LocalDate是否对我们有利? 计算:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
因此,在使用“九”时,转换Date -> LocalDate有益的。 在G8上,转换成本将吞噬DateTimeFormatter -a的所有好处。
基准测试
结论:利用新的解决方案。
另一个“八”
在这段代码中,我们看到了明显的冗余:
Iterator<Long> iterator = items
我们将其删除:
Iterator<Long> iterator = items
对不对? 我在上面已经论证过分的工作会降低性能。 但是在这里,我们删除了多余的部分-并且(突然)情况变得更糟。 要了解正在发生的情况,请使用两个迭代器,并在放大镜下查看它们:
公开 Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

第一个迭代器是常规ArrayList$Itr 。
通过它很简单: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
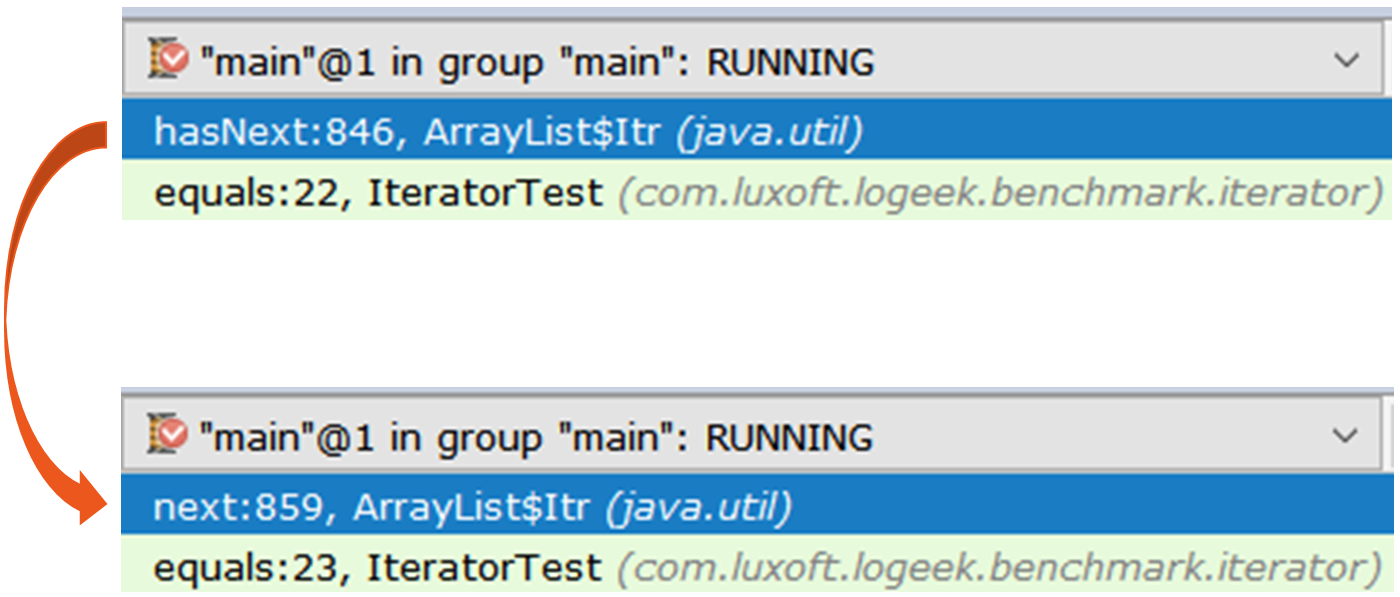
第二个更有趣,它是基于ArrayList$ArrayListSpliterator Spliterators$Adapter 。
让我们看一下通过async-profiler进行的迭代器迭代:
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
可以看出,大部分时间都花在了遍历迭代器上,尽管总的来说,我们并不需要它,因为可以这样进行搜索:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach显然是赢家,但这很奇怪:它仍然基于ArrayListSpliterator ,但是其使用已大大改善。
让我们看一下个人资料: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
在此配置文件中,大部分时间都花在“吞噬” Blackhole内部的值上。 与迭代器相比,大部分时间直接用于执行Java代码。 可以认为,原因是垃圾回收器的比重比迭代器蛮力低。 检查:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
实际上, Stream::forEach提供了一半的内存消耗。
为什么会更快?从头到黑洞的呼叫链如下所示:
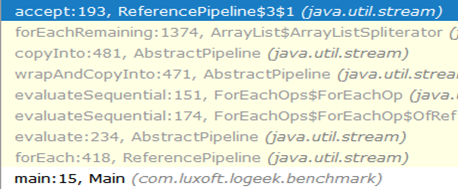
如您所见,对ArrayListSpliterator::tryAdvance的调用从链中消失了, ArrayListSpliterator::forEachRemaining出现了ArrayListSpliterator::forEachRemaining :
高速ArrayListSpliterator::forEachRemaining通过在1个方法调用中使用对整个数组的传递来实现。 当使用迭代器时,段落仅限于一个元素,因此我们始终反对ArrayListSpliterator::tryAdvance 。
ArrayListSpliterator::forEachRemaining可以访问整个数组,并以一个计数周期对其进行ArrayListSpliterator::forEachRemaining ,而无需其他调用。
重要告示请注意机械更换
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
在
items .stream() .map(Long::valueOf) .forEach(bh::consume);
它并不总是等效的,因为在第一种情况下,我们在不影响流本身的情况下将数据的副本用于通道,而在第二种情况下,则直接从流中获取数据。
基准测试
结论:在处理复杂的数据表示时,请做好准备,即使“铁”规则(额外的工作危害)也会停止工作。 上面的示例表明,看似多余的中间列表具有更快实现枚举的优点。
两个技巧
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
引起您注意的第一件事是一个烂的“改进”,即,将一个非零长度的数组传递给Collection::toArray方法。 它详细解释了为什么这样做有害。
第二个问题不是那么明显,并且由于其理解,我们可以在审查者和历史学家的工作之间得出相似之处。
这是罗宾·科林伍德关于此的内容:例如,假设他(历史学家)阅读了《狄奥多西法典》,而在他之前是皇帝的e令。简单地阅读单词和翻译它们的能力并不能理解其历史意义。要欣赏它,历史学家必须想象皇帝试图解决的情况 ...
. :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→