 最近,我们谈到了为什么我们想出自己的RFM细分工具,该细分工具有助于在20秒内完成RFM分析 ,并展示了如何在市场营销中使用其结果。
最近,我们谈到了为什么我们想出自己的RFM细分工具,该细分工具有助于在20秒内完成RFM分析 ,并展示了如何在市场营销中使用其结果。
现在我们来说明它的排列方式。
任务:编写新的RFM分析算法
我们对RFM分析的可用方法不满意。 因此,我们决定制作自己的细分工具:
- 它完全自动运行。
- 从3到15段构建。
- 适应客户的任何活动领域(无关紧要的是什么:鲜花店或电动工具店)。
- 它根据可用数据而不是无法通用的预定义参数来确定段的数量和位置。
- 它选择段,以便它们始终具有使用者(不同于某些段为空时的某些方法)。
如何解决问题
当我们实现任务时,我们意识到它已经超出了人类的能力,因此向人工智能寻求帮助。 为了教导汽车将消费者划分为细分市场,我们决定使用聚类方法。
聚类方法用于搜索数据中的结构并从中选择相似对象的组,这正是RFM分析所需要的。
聚类是指“ 无需老师学习 ” 一类的机器学习方法。 之所以这样称呼一个类,是因为有数据,但是没人知道如何处理它,因此它不能教机器。
我们找不到在市场上使用这种方法的公司。 尽管他们找到了一篇文章 ,其中的作者对此主题进行了科学研究。 但是,正如我们从自己的经验中了解到的那样,从科学到商业绝不是一步之遥。
阶段1.数据处理
需要为集群准备数据。
首先,我们检查它们的值是否正确:负值等。
然后我们消除排放物-具有非同寻常特征的消费者。 它们很少,但是它们会极大地影响结果,而且效果不佳。 为了将它们分开,我们使用一种特殊的机器学习方法-Local Outlier Factor 。

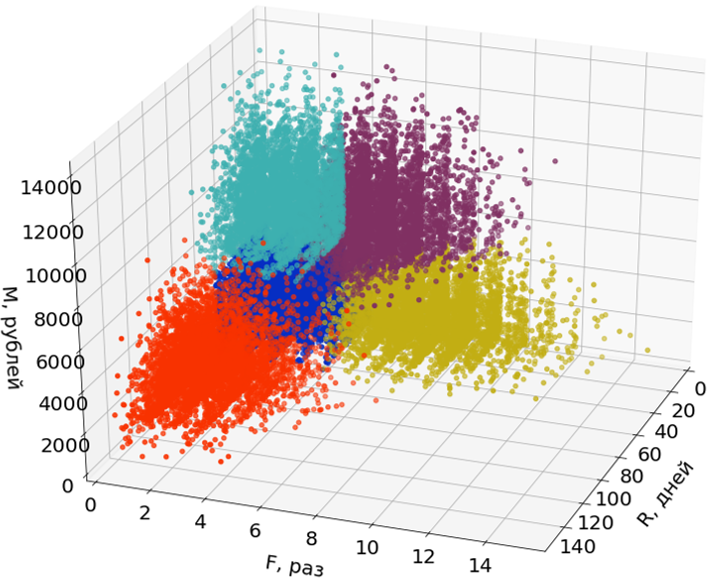
在这些图片中,我仅使用三个维度(R和M)中的两个来促进感知。
排放不参与分段的构造,而是在分段形成后分配给它们。
第二阶段。消费者集群
我将澄清术语:“聚类”是指由于使用聚类算法而获得的对象组,而细分则是最终结果(即RFM分析的结果)。
有几十种聚类算法。 可以在scikit-learn软件包文档中找到其中一些示例。
我们尝试了八种经过各种修改的算法。 大多数没有足够的内存。 或者他们的工作时间趋于无限。 从技术上讲,几乎所有能够解决该任务的算法都给出了可怕的结果:例如,流行的DBSCAN将55%的对象视为噪声,并将其余的对象分为4302个簇。
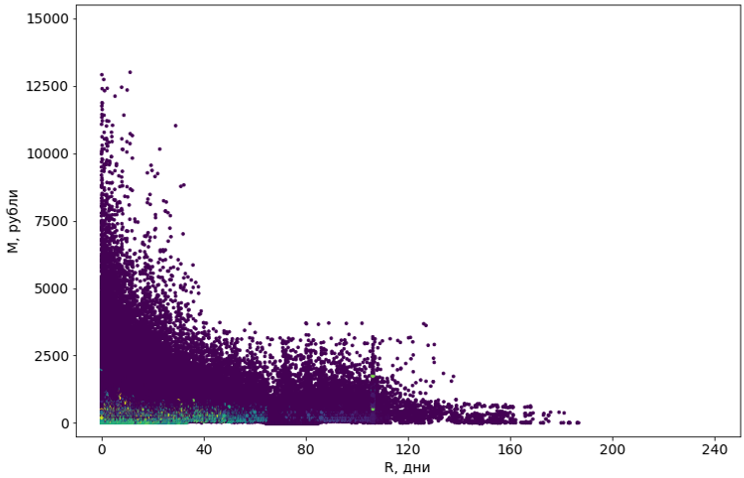
紫罗兰色的物体被定义为“噪音”
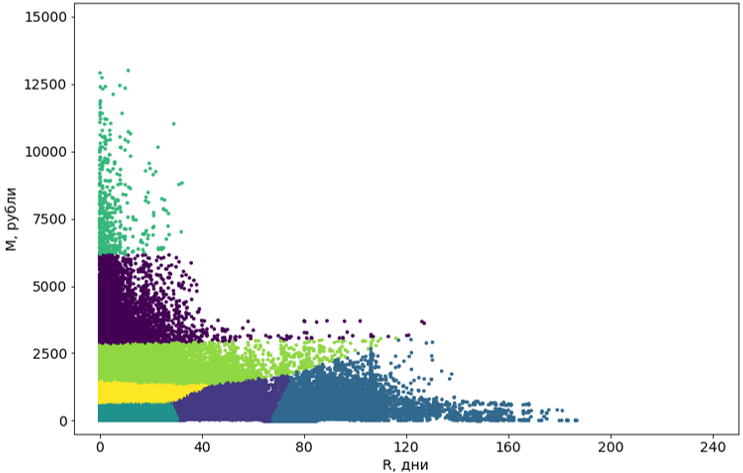
结果,我们选择了K均值 (K-means)算法,因为它不查找点的聚类,而只是将中心周围的点分组。 事实证明,这是正确的决定。
但是首先,我们解决了一些问题:
不稳定 这是大多数聚类算法(包括K-Means)的已知问题。 不稳定性在于这样的事实:由于使用了随机因素,因此反复发射时结果可能会有所不同。
因此,我们进行了多次聚类,然后再次聚类,但是已经是聚类的中心。 作为聚类的最终中心,我们采用结果聚类的中心(即由第一个聚类的中心形成的聚类)。
集群数。 数据可以不同,集群的数量也必须不同。
为了找到每个客户群的最佳集群数量,我们使用不同数量的集群进行集群,然后选择最佳结果 。
速度 K-means算法不是很快,但是可以接受(对于数十万名消费者的平均数,几分钟即可)。 但是,我们运行了很多次:首先,增加稳定性,其次,选择集群数。 并且操作时间大大增加。
为了加速,我们使用Mini Batch K-Means的修改形式。 它不针对所有对象而是仅针对一小部分子样本在每次迭代时重新计算聚类中心。 质量下降很多,但时间却大大减少了。
解决这些问题后,群集便开始成功进行。
阶段3.集群的后处理
使用该算法获得的聚类必须采用易于感知的形式。
首先,我们将这些簇从曲线变成矩形。 实际上,这使它们成为细分。 段的矩形是我们系统的要求,此外,还增加了段本身的可理解性。 为了进行转换,我们使用了另一种机器学习算法- 决策树 。
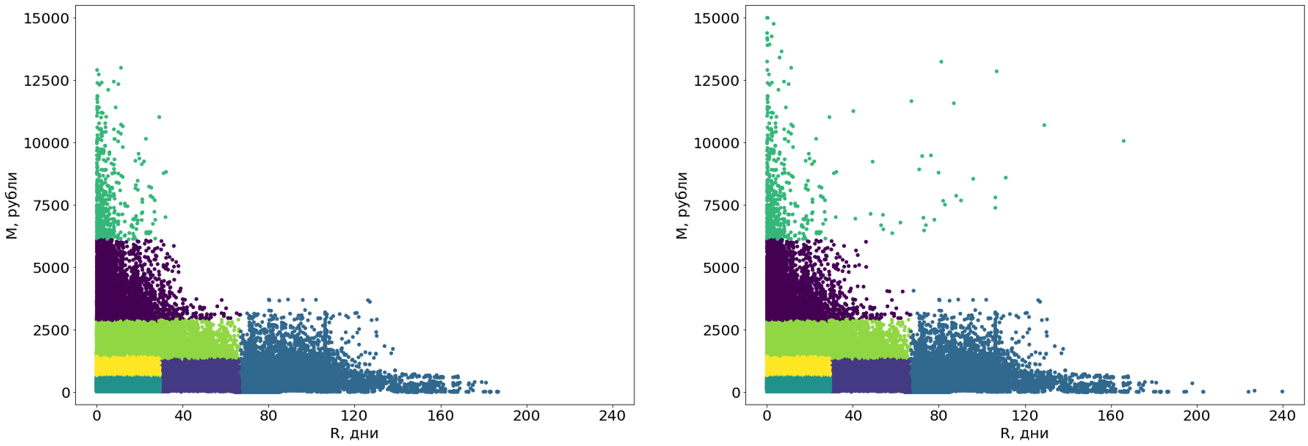
决策树基于无异常数据构建,然后将异常值分配给完成的段
其次,我们做了另一个很酷的事情-段的描述。 一种特殊的算法,使用字典,用实时俄语描述了每个片段,因此人们在看着毫无生气的数字时不会感到渴望。

测试结果
产品准备就绪。 但是在开始销售之前,需要对其进行测试。 也就是说,检查RFM分析是否按照我们的预期进行。
我们知道,了解我们是否做过有价值的事情的最好方法是找出分析对我们的客户有多有用。 我们将这样做。 但这是很长的时间,结果将在以后出现。我们想知道我们现在如何成功地完成了任务。
因此,作为一种更简单,更快速的指标,我们使用了“历史控制组”方法。
为此,我们采用了多个数据库,并在过去的不同时间使用RFM分析对它们进行了细分:一个是六个月前的州数据库,另一个是一年前的数据库,等等。
基于每个基础的每个细分,我们建立了从所选时刻到现在的客户行为的预测。 然后,他们将这些预测与客户的实际行为进行了比较。

六个月控制期的历史对照组的测试示例
在图片中:
- R,F和M列通常表示沿每个轴的段的边界。 这是半年前形式的基础细分的结果。
- “大小”列显示六个月前相对于数据库总大小的段大小。
- “购买概率”和“金额”列是有关未来六个月中实际消费者行为的数据。
- 购买可能性定义为细分市场中购买商品的消费者数量与细分市场中消费者总数的比率。
- 金额-该细分市场中的消费者所花费的总金额相对于所有细分市场中的消费者所花费的总金额。
结果是一致的。 例如,来自我们预测其购买频率很高的细分市场的客户实际上购买频率更高。
尽管基于这样的测试,我们不能保证算法正确运行100%,但我们还是认为它是成功的。
我们了解什么
机器学习确实能够帮助企业解决无法解决或解决得很差的问题。
但是真正的挑战不是Kaggle竞争。 在这里,除了要在给定的指标上获得更高的质量外,您还需要考虑该算法将在多大程度上起作用,它是否对人们来说很方便以及通常来说是否有必要使用ML解决问题或者您可以提出一种更简单的方法。
最后,缺乏正式的质量指标使任务复杂了数倍,因为很难正确评估结果。