在机器学习领域,最流行的模型类型之一是决定性的树和基于它们的合奏。 树木的优点是:易于解释,对初始依赖性的类型没有限制,对样本大小的软要求。 树木也有一个主要缺陷-易于重新训练。 因此,几乎总是将树木组合成整体:随机森林,梯度增强等。复杂的理论和实践任务是将树木组成并将其组合成整体。
在同一篇文章中,我们将考虑从已经训练
XGBoost树集成模型生成预测的过程,以及流行的梯度提升
XGBoost和
LightGBM中的实现功能。 此外,读者还将熟悉Go的
leaves库,这使您无需使用原始库的C API即可预测树木的整体。
树木从哪里生长?
首先考虑一般规定。 它们通常与树木配合使用,其中:
- 节点中的分区根据一种功能发生
- 二叉树-每个节点都有一个左右后代
- 对于重要属性,决策规则包括将属性值与阈值进行比较
我从
XGBoost文档中获取了此插图
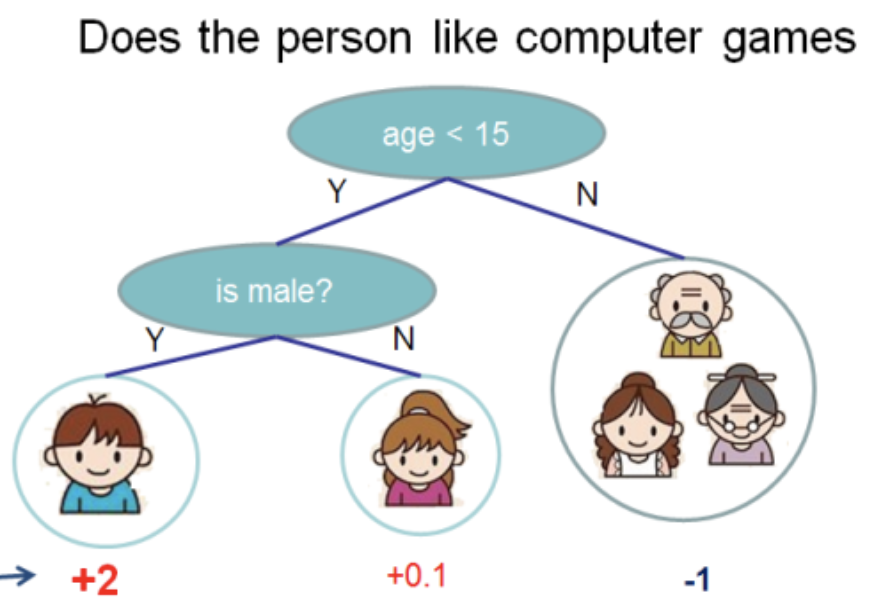
在这棵树中,我们有2个节点,2个决策规则和3个工作表。 在圆圈下面,指示值-将树应用于某个对象的结果。 通常,将变换函数应用于计算树或树集合的结果。 例如,针对二进制分类问题的
S形 。
要从通过梯度增强获得的树木集合中获得预测,您需要添加所有树木的预测结果:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
在下文中,将有
C++ ,如
XGBoost和
LightGBM就是用这种语言编写的。 我将忽略无关的细节,并尝试给出最简洁的代码。
接下来,考虑
Predict隐藏的内容以及树的数据结构的结构。
XGBoost树
XGBoost具有几种树(在OOP的意义上)。 我们将讨论
RegTree (请参阅
include/xgboost/tree_model.h ),根据文档,这是主要的。 如果仅保留对预测很重要的细节,则该类的成员看起来将尽可能简单:
class RegTree {
GetNext规则在
GetNext函数中实现。 对该代码进行了少许修改,而不会影响计算结果:
这里有两件事:
RegTree仅适用于真实属性(类型float )- 支持跳过的特征值
核心是
Node类。 它包含树的局部结构,决策规则和工作表的值:
class Node { public:
可以区分以下功能:
- 工作表表示为
cleft_ = -1节点 info_字段表示为union ,即 两种类型的数据(在这种情况下相同)共享一个内存,具体取决于节点的类型sindex_的最高有效位负责跳过其属性值的对象的位置
为了能够跟踪从调用
RegTree::Predict方法到接收答案的路径,我将提供缺失的两个函数:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
在
GetLeafIndex函数中
GetLeafIndex我们循环遍历树节点,直到到达叶子为止。
LightGBM树
LightGBM没有该节点的数据结构。 相反,Tree
Tree的数据结构(
include/LightGBM/tree.h文件)包含值的数组,其中节点号用作索引。 叶子中的值也存储在单独的数组中。
class Tree {
LightGBM支持分类功能。 使用位字段提供支持,该位字段存储在
cat_threshold_用于所有节点。 在
cat_boundaries_存储位字段的哪一部分对应于哪个节点。 用于分类情况的
threshold_字段将转换为
int并与
cat_boundaries_的索引相对应,以搜索位字段的开头。
考虑分类属性的决定性规则:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
可以看到,根据
missing_type值
NaN自动降低沿树的右分支的解。 否则,将
NaN替换为0。在位字段中搜索值非常简单:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
即,例如,对于分类属性
int_fval=42检查数组中是否设置了第41位(从0开始编号)。
这种方法有一个明显的缺点:如果分类属性可以采用较大的值,例如100500,则对于该属性的每个决策规则,将创建一个最大为12564字节的位字段!
因此,希望对分类属性的值进行重新编号,以使它们从0连续变为最大值 。
就我而言,我对
LightGBM进行了说明性更改并
接受了它们 。
处理物理属性与
XGBoost并没有太大区别,为简洁起见,我将跳过此内容。
leaves-Go中的预测库
XGBoost和
LightGBM非常强大的库,用于在决策树上构建梯度
LightGBM模型。 要在需要机器学习算法的后端服务中使用它们,必须解决以下任务:
- 离线定期训练模型
- 后端服务中的模型交付
- 在线投票模型
对于编写加载的后端服务,
Go是一种流行的语言。 通过C API和cgo
XGBoost或
LightGBM并不是最简单的解决方案-程序的构建很复杂,由于粗心的处理,您可能会发现
SIGTERM ,这是系统线程数的问题(库中的OpenMP与运行时线程)。
因此,我决定使用
XGBoost或
LightGBM内置的模型在纯
Go上编写一个库,以进行预测。 它被称为
leaves 。

该库的主要功能:
- 对于
LightGBM型号
- 从标准格式(文本)读取模型
- 支持物理和分类属性
- 缺失价值支持
- 使用分类变量优化工作
- 仅具有预测数据结构的预测优化
- 对于
XGBoost模型
这是一个最小的
Go程序,该程序从磁盘加载模型并显示预测:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
库API最少。 要使用
XGBoost模型
XGBoost只需调用
leaves.XGEnsembleFromReader方法而不是上面的方法即可。 可以通过调用
PredictDense或
model.PredictCSR来批量进行预测。 在
叶子测试中可以找到更多的使用场景。
尽管
Go运行速度比
C++慢(主要是由于运行时和运行时检查工作量大),但由于进行了许多优化,所以可以达到与调用原始库的C API相当的预测速度。
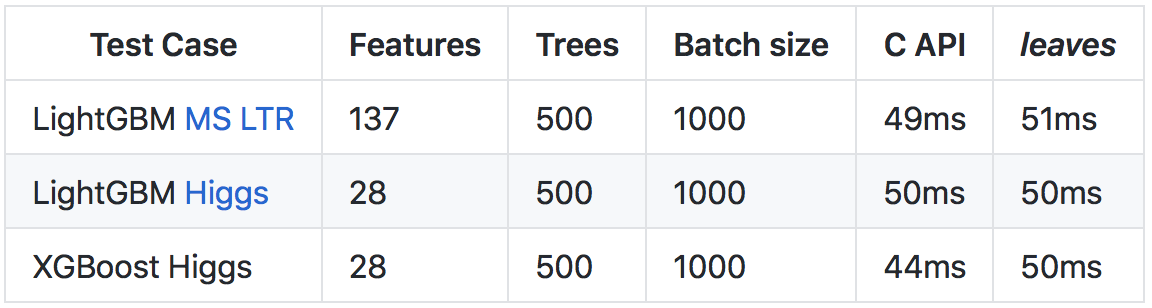
有关结果和比较方法的更多详细
信息,请参见github上的
存储库 。
见根
我希望本文为
XGBoost和
LightGBM的树实现打开大门。 如您所见,基本结构非常简单,我鼓励读者利用开放源代码-在对代码的工作方式有疑问时研究代码。
对于那些对使用Go语言在其服务中使用梯度增强模型感兴趣的人,我建议您熟悉
叶子库。 使用
leaves您可以在生产环境中的机器学习中轻松使用领先的解决方案,而与原始C ++实现相比,几乎不会损失速度。
祝你好运!