 文章翻译: 实验者的经验法则
文章翻译: 实验者的经验法则Web门户的所有者,从最小到最大,例如Amazon,Facebook,Google,LinkedIn,Microsoft和Yahoo,都在尝试通过优化各种指标(从重用次数到花费的时间和收入)来改善其网站。 我们已经被Amazon,Booking.com,LinkedIn和Microsoft上的数千个实验所吸引,我们希望分享从这些实验及其结果中得出的七个经验法则。 我们认为,这些规则在优化网络和控制实验之外的分析过程中均适用。 虽然有例外。
为了使这些规则更加重要,我们将给出一些真实的例子,其中大部分将是首次出版。 之前已经提出了一些规则(例如,“速度很重要”),但是我们在假设中补充了可以用于设计实验的假设,并分享了其他示例,这些示例使我们对速度在哪些地方特别重要以及哪些地方更加重要有所了解。页面并不重要。
本文有两个目的。
首先 :教导实验者良好的品味规则,这将有助于优化网站。
第二 :为KDD社区提供新的主题,以探讨这些规则的适用性,它们的改进以及例外的存在。
引言
从最小到最大的门户网站的所有者都在尝试改善其网站。 领先的公司使用基准测试(例如A / B测试)来评估更改。 这是通过Amazon [1],Ebay,Etsy [2],Facebook [3],Google [4],Groupon,Intuit [5],LinkedIn [6],Microsoft [7],Netflix [8],ShopDirect [9]完成的。 ,雅虎和Zynga [10]。
我们与许多公司(包括Amazon,Booking.com,LinkedIn和Microsoft)合作,在网站优化方面积累了经验。 例如,必应(Bing)和领英(LinkedIn)在任何给定时间进行数百次并行实验[6; 11]。 由于我们参加的实验种类繁多,因此已经建立了经验法则,我们将在此处进行讨论。 它们已由实际项目确认,但是任何规则都有例外(我们还将讨论它们)。 例如,72条规则是金融领域有用经验法则的一个很好的例子。 它声称您需要将年增长率乘以72才能大致确定将投资翻倍的年数。 在正常情况下,该规则非常有用(当利率在4%至12%之间波动时),但是在其他领域则不起作用。
由于这些规则是根据对照实验的结果制定的,因此即使未在现场进行对照实验,它们也非常适用于站点优化和简单分析(尽管在这种情况下将无法准确评估所做更改的效果)。
您将在本文中找到:
- 试用网站的有用规则。 它们仍在开发中,我们需要另外评估其应用范围,并确定这些规则是否有新的例外。 在“大规模在线控制实验”一文中讨论了使用控制实验的重要性[11]。
- 改进以前的规则。 其他作者[12; 13]和我们[14]已经表达了诸如“速度问题”之类的观点。 但是在设计实验时我们做了一些假设,我们将讨论一些研究,这些研究表明在页面的某些区域中,速度特别重要,而在其他区域则不是。 我们还改进了“成千上万的用户”的旧规则,该规则回答了进行控制实验需要多少人的问题。
- 首次公开了对照实验的真实例子。 在亚马逊,必应和LinkedIn,控制实验被用作开发过程的一部分[7; 11]。 许多仍然不使用控制实验的公司可以通过引入新的开发范式[7,15]来从处理变更的其他示例中受益匪浅。 已经使用控制实验的公司将从描述的见解中受益。
控制实验,数据以及从数据中提取知识的过程
我们将在此处讨论在线控制实验,其中将用户随机分组(例如,以显示各种站点选项)。 此外,划分是持续进行的,也就是说,每个用户在整个实验过程中都会有相同的体验(始终会向他显示相同的网站版本)。 记录用户与网站的互动情况(点击次数,页面浏览量等),并根据其基础计算关键指标(点击率,每位用户的会话数,用户的收入)。 进行统计测试以分析计算的指标。 如果对照组的指标(查看站点的旧版本)与实验组的指标(查看站点的新版本)之间的差异具有统计显着性,那么我们也很有可能说所做的更改将影响实验中观察到的指标。 有关详细信息,请参见“网络上的受控实验:调查和实用指南” [16]。
我们参加了许多实验,这些实验的结果不正确,并花费了大量时间和精力来了解原因并找到解决方法。 文章[17]和[18]中描述了许多陷阱。 我们想强调一些有关进行在线控制实验的数据以及从这些数据中获取知识的过程的问题:
- 数据源是我们上面讨论的真实站点。 不会有任何人工生成的信息。 所有示例均基于真实的用户交互,并且在删除漫游器后会计算指标[16]。
- 示例中的用户组是从目标受众的均匀分布中随机抽取的(即,例如,必须单击链接以查看正在研究的更改的用户)[16]。 用户标识的方法取决于站点:如果用户未登录,则使用cookie;如果用户已登录,则使用其登录名。
- 清除漫游器后,用户组的大小范围从数十万到数百万(示例中指示了确切的值)。 在大多数实验中,这是必要的,以便度量标准的细微差异具有很高的统计意义。
- 注意到的结果在p值<0.05时具有统计学意义,通常更低。 惊人的结果(在规则1中)至少再次被再现,因此基于Fisher累积概率检验的累积p值的值远远小于必要值。
- 每个实验都是我们的亲身经历,至少由一位作者验证了标准误区的存在。 每个实验进行至少一周。 在整个实验过程中,展示站点选项的观众份额保持稳定(以避免辛普森悖论的影响),我们在实验过程中观察到的观众比例与实验启动时设定的比例一致[17]。
实验经验法则
前三个规则与更改对关键指标的影响有关:
- 小小的变化会产生很大的影响;
- 变化很少会产生很大的积极影响;
- 您尝试重复别人宣布的辉煌成就的尝试更有可能失败。
以下4条规则彼此独立,但是每条规则都很有用。
规则1:小的更改可能会对关键指标产生重大影响
曾经使用过网站的人都知道,任何小的更改都会对关键指标产生很大的负面影响。 一个小的JavaScript错误可能导致无法付款,而破坏堆栈的小的错误可能导致服务器崩溃。 但是,我们将重点关注关键指标的积极变化。 好消息是,在许多例子中,微小的变化导致关键指标得到了改善。 布赖恩·艾森伯格(Bryan Eisenberg)写道,在Doctor Footcare的网站上删除购买表单上的优惠券输入字段可将转化率提高1000%[20]。 Jared Spool写道,取消购买时的注册要求,每年给一家大型零售商带来3亿美元的收入[21]。
尽管如此,我们在个人实验过程中并未看到如此重大的变化。 但是,我们看到了小变化带来的巨大改进,投资回报率出乎意料的高(利润与投入的工作成本之比很高)。
我们还想指出的是,我们正在讨论的是稳定的效果,而不是“太阳上的闪光”或具有特殊新闻/病毒效果的功能。 《是!:50种经过科学证明的说服力的方法》一书中描述了一个我们不想要的东西的例子[22]。 电视节目的作者Collen Szot在Couch Store电视频道上打破了20年的销售记录,他在标准信息栏上替换了三个字,从而导致购买数量大增。 Collen推导出“如果操作员正忙,请再次致电”,而不是“操作员正在等待,请立即致电”。 作者用以下社会学证据对此进行了解释:观众认为,如果热线电话很忙,那么喜欢他们的人也在观看新闻频道。
如果定期使用上述技巧,则效果会得到平衡,因为用户已经习惯了。 在这种情况下的对照实验中,效果很快消失。 因此,我们建议您进行至少两个星期的实验并监控动态。 尽管在实践中,这种事情很少见[11; 18]。 当更改本身产生短期影响或使用最终资源进行处理时,我们观察到此类更改产生积极影响的情况与推荐系统相关。
例如,当LinkedIn更改了“您可能认识的人”功能算法时,它仅产生了一次性的点击指标激增。 而且,即使算法工作得更好,每个用户都知道有限的人数,并且在联系了他的主要熟人之后,任何新算法的效果都会下降。
示例:在新选项卡中打开链接。 一系列三个实验
2008年8月,MSN UK对900,000多名用户进行了一项实验,其中到HotMail的链接在新选项卡(或旧版本浏览器的新窗口)中打开。 我们先前曾报道[7],这种最小的更改(一行代码)导致MSN用户的参与度增加。 以首页上每位用户的点击数衡量的参与度,在点击HotMail的用户中增长了8.9%。
2010年6月,我们在美国的270万MSN用户中重现了该实验,结果相似。 实际上,这也是具有新颖性的功能示例。 在将其推广给所有用户的第一天,有20%的评论是负面的。 在第二周,不满意的比例下降到4%,在第三和第四周下降到2%。 关键指标的改进一直保持稳定。
2011年4月,美国的MSN对超过1200万的用户进行了非常大的实验,他们打开了一个页面,并在新标签中显示了搜索结果。 以用户点击次数衡量的参与度增长了5%。 这是MSN曾经实现的与用户参与相关的最佳功能之一,并且对代码进行了微不足道的更改。
所有主要的搜索引擎都尝试在新标签页/窗口中打开链接,但是“搜索结果页面”的结果并不令人印象深刻。
示例:字体颜色
2013年,Bing对字体颜色进行了一系列实验。 胜出选项如右图1所示。 这是三种颜色的更改方式:
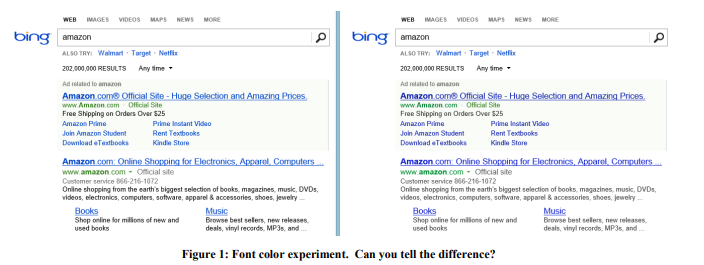
这样改变的代价? 便宜:只需替换CSS文件中的几种颜色即可。 实验结果表明,用户更快地实现了他们的目标(严格定义成功是一个商业秘密),并且该修订版的获利每年增加了1000万美元。 我们对如此惊人的结果表示怀疑,因此我们在更大的3200万用户样本上重现了该实验,结果得到了证实。

示例:在正确的时间提供正确的报价
早在2004年,Amazon开始页面就包含两个插槽,它们的内容均经过自动测试,因此可以更好地显示可以更好地改善目标指标的内容。 获得亚马逊信用卡的报价高居榜首,这令人惊讶,因为 该报价的每次展示点击次数很少。 但事实是该应用程序非常有利可图,因此尽管点击率很小,但期望值却很高。 但是,是否成功选择了这样的宣布地点? 不行 结果,该提案以及福利的一个简单示例被移至用户在添加产品后看到的购物车。 因此,在每个产品的示例中都强调了该建议的优势。 如果用户已将商品添加到购物篮中,那么这显然是要进行购买的意图,现在是时候进行这种报价了。

对照实验表明,这种简单的变化每年可带来数千万美元的收入。
示例:防病毒
广告是一项有利可图的业务,用户安装的“免费”软件通常包含恶意部分,该部分会阻塞广告页面。 例如,图2显示了带有恶意程序的用户的Bing结果页面的外观,该恶意程序向该页面添加了很多广告(以红色突出显示)。
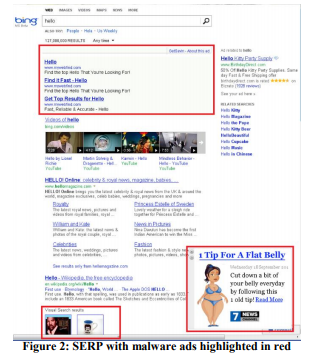
用户通常甚至不会注意到,这么多的广告不是由他们访问的网站显示,而是由他们不小心安装的恶意代码显示。 该实验难以实现,但在思想上相对简单:更改修改DOM的基本过程,并限制能够修改页面的应用程序。 该实验是针对380万用户执行的,这些用户的计算机具有用于编辑DOM的第三方代码。 在测试组中,这些更改被阻止。 结果表明,所有关键指标均得到了改善,其中包括每位用户的会话数(即 人们访问网站的频率更高。 此外,用户可以更成功,更快地完成任务,年收入增加几百万美元。 我们将在规则4中讨论的页面加载速度对于受实验影响的页面已降低了数百毫秒。
Bing的另外两个小改动是严格保密的,需要几天的时间才能开发完成,每一个小改动都导致广告收入每年增加近1亿美元。 微软在2013年10月发布的季度报告中说:“由于每个搜索和每个页面的利润增加,搜索广告收入增长了47%。” 这两个变化对上述利润增长做出了重大贡献。
在这些示例之后,您可能会认为组织应该关注许多小的变化。 但是下面您会发现事实并非如此。 是的,突破是基于很小的变化而发生的,但是却非常罕见且出乎意料:在Bing中,可能有500个实验之一实现了如此高的ROI和可再现的阳性结果。 我们并不是说这些结果在其他领域是可重复的,我们只是想传达这个想法:进行简单的实验是值得的,并且可能最终会取得突破。
专注于小变化而产生的危险是增量主义:一个自重的组织必须进行一系列具有潜在高ROI的变化,但同时,必须进行几项重大变化才能赢得大奖[23]。
规则2:更改很少会对关键指标产生重大的积极影响
正如阿尔·帕西诺(Al Pacino)在电影《每个星期日》中所说,胜利是一厘米接一厘米的。 每年在Bing等网站上进行的成千上万次实验。 大多数失败,成功的则对关键指标的影响为0.1%-1.0%,从而使总体影响下降。 发生了先前规则中描述的效果显着的小变化,但是很少见。
请注意以下两点很重要:
- 关键指标不是与可以轻松改进的单个功能相关的特定指标,而是对整个组织重要的指标:例如,每个用户的会话数[18]或达到用户目标的时间[24]。
开发功能时,只需突出显示它或使其变大,就很容易显着提高对该功能(或其他功能度量)的点击次数。 但是,要提高整个页面或整个用户体验的点击率是挑战所在。 大多数功能只会在页面上产生点击,从而在不同区域之间重新分配点击。 - 指标应划分为小段,因此更容易优化。 例如,一个团队能否轻松改善Bing的天气查询指标或在Amazon上购买电视节目? 添加一个很好的比较工具。 但是,由于细分市场的规模,关键指标的10%的改善将溶解在整个产品的指标中。 例如,将1%的细分提高10%将对整个项目造成约0.1%的影响(大约,因为如果细分指标与平均值不同,那么效果也可能不同)。
该规则的重要性非常重要,因为在实验过程中会出现误报错误。 它们有两种原因:
- 首先是统计造成的。 如果我们每年进行一千次实验,那么误报误差为0.05的可能性就会导致这样一个事实,即对于一个固定的指标,我们将获得数百次的误报结果。 而且,如果我们使用几个互不相关的指标,那么这个结果只会增强。 甚至像Bing这样的大型网站也没有足够的流量来提高敏感性,并得出p值较低的结论(例如每位用户的会话数)。
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
如果我们具有等于⅓的初步成功概率(如我们在[7]中所述,这是Microsoft实验之间的平均值),那么真正具有统计学意义的正向实验的后验概率为89%。 如果实验是我们在第一条规则中提到的实验之一,那么当500中只有1个包含突破性解决方案时,则概率降为3.1%。
这个规则的一个有趣的结果是,坚持一个人比独自发展要容易得多。 在一家公司中着重于统计意义的决策更有可能产生积极影响。 例如,如果我们的实验成功率为10-20%,那么如果我们对那些成功并在其他搜索引擎中投入使用的功能进行测试,那么我们的成功水平将会更高。 反之亦然:其他搜索引擎也必须测试Bing已实施的事情并将其付诸实施。
有了经验,我们学会了不相信看起来好得令人难以置信的结果。 人们对不同情况的反应不同。 他们怀疑出现了问题,并以其强大的新功能研究了实验的负面结果,提出了问题,并出于这个结果的原因更深入地进行了搜索。 但是,如果结果仅仅是正面的,那么怀疑就会减少,人们开始庆祝,而不是深入研究并且不寻找异常。
当结果异常出色时,我们习惯于遵循Twyman法则[27]:看起来有趣或不同的一切通常都是错误的。
可以用贝叶斯推理来解释特威曼定律。 根据我们的经验,我们知道很少有突破。 例如,几次实验大大改善了我们的指导指标,即每位用户的会话数。 想象一下,我们在实验中遇到的分布是正常的,以0点为中心,标准偏差为0.25%。 如果实验表明关键指标的值增加了+ 2%,则我们称其为Twyman定律,并说这是一个非常有趣的结果,与平均值相差8个标准差,并且排除其他因素的可能性为10
-15 。 即使具有统计意义,对初步的期望仍然很高,我们将推迟成功的庆祝活动,并更深入地寻找第二种假阳性错误的原因。 经常应用Twyman定律证明
=NP 。 今天,如果任何网站编辑收到这样的证据,都不会高兴。 他很可能会立即回答一个模板答案:“在您证明P = NP时,在X页上犯了一个错误。”
示例:代理Office Online指标
Cook和他的团队[17]谈论了他们与Microsoft Office Online进行的一项有趣的实验。 团队测试了一种新的页面设计,其中一个按钮非常醒目,要求为产品付费。 团队想要衡量的关键指标:每位用户的购买次数。 但是,跟踪真实的购买需要修改计费系统,这在当时是很困难的。 然后,团队决定使用“导致购买的点击次数”指标,并应用公式
( ) * = 次数,计算从点击到购买的转化次数。
令他们惊讶的是,在实验中,点击次数减少了64%。 如此令人震惊的结果迫使人们对数据进行更深入的分析,结果证明从点击到购买稳定转换的假设是错误的。 实验页面显示了产品的成本,吸引了较少的点击,但是点击该产品的用户的资格更高,并且从点击到购买的转化率更高。
示例:从慢速页面获得更多点击
JavaScript已添加到Bing搜索结果页面。 该脚本通常会减慢页面速度,因此每个人都希望对关键参与度指标(例如用户的点击次数)产生轻微的负面影响。 但是结果却相反,点击次数更多! [18]尽管有积极的动力,我们还是遵循了特威曼定律并解决了这个难题。 点击跟踪广告基于网络信标,如果用户离开页面,某些浏览器将不会拨打电话。 [28]因此,JavaScript影响了点击计数的准确性。
示例:Bing Edge
在2013年的几个月中,Bing将其内容交付网络从Akamai更改为自己的Bing Edge。 将流量切换到Bing Edge已与许多其他改进结合在一起。 几个团队报告说,他们改进了关键指标:Bing主页的点击率增加了,功能开始被更频繁地使用,流出量开始减少。 因此,所有这些改进都与干净的点击计数有关:Bing Edge不仅提高了页面速度,而且还提高了点击传递能力。 为了评估效果,我们发起了一个实验,其中使用跟踪页面的方法替换了灯塔跟踪点击的方法。 此技术用于广告中,导致点击次数略有减少,从而降低了每次点击的效果。 结果表明,点击损失百分比下降了60%以上! 而且在此期间宣布的大多数成就都是改善点击传递的结果。
示例:MSN必应搜索
自动完成是一个下拉列表,其中提供了在有人键入请求时完成请求的选项。 MSN计划使用一种新的和改进的算法来改进此功能(功能开发团队随时准备解释为什么他们的新算法比旧算法具有先验的优势,但是当看到实验结果时,他们通常会感到沮丧)。 该实验取得了巨大成功;使用MSN的Bing进行的搜索数量大大增加了。 遵循我们的规则,我们开始理解并发现,当用户单击工具提示时,新代码进行了两个搜索查询(其中一个在搜索结果出现后立即被浏览器关闭)。
因此,对于许多积极成果的解释可能并不那么令人兴奋。 我们的任务是找到对用户的真正影响,而Twyman的规则确实有助于这一点,并有助于理解许多实验结果。
规则编号3。 您的利益会有所不同。
有许多成功的控制实验的文献记录实例。 例如,“
哪个测试赢了? ”包含数百个A / B测试示例,并且列表每周更新一次。
尽管这是产生思想的重要力量,但这些示例仍存在一些问题:
- 质量各不相同。 在这些研究中,公司的某人谈论A / B测试的结果。 有专家评估吗? 是否执行正确? 有排放吗? p值是否足够小(我们看到已发布的A / B检验的p值大于0.05,通常认为这在统计学上不重要)? 我们之前讨论过陷阱吗?测试作者没有正确检查哪些陷阱?
- 在一个域中有效的方法可能在另一域中无效。 例如,尼尔·帕特尔[29]建议在提供30天试用版而不是“ 30天退款保证”的广告中使用“免费”一词。 这可能适用于一种产品和一个受众,但是我们怀疑结果将在很大程度上取决于产品和受众。 约书亚·波特(Joshua Porter)[30]指出,调用“立即开始”的按钮“红色胜于绿色”。 但是,由于我们没有看到很多带有红色的号召性用语按钮的网站,因此,显然,这种结果的再现效果不佳。
- 新颖性和第一次的效果。 我们在实验中实现了稳定性,并且在许多示例中进行的许多实验还没有进行到足以检查这种效果的时间。
- 结果解释不正确。 一些隐藏的原因或特定因素可能不会被认识或误解。 我们举两个例子。 其中之一是第一个记录在案的对照实验。
例子1 坏血病是由维生素C缺乏引起的疾病。在16至18世纪,它杀死了100,000多人,其中大多数是长时间航行并在海中停留超过水果和蔬菜生存时间的水手。 1747年,詹姆斯·林德(James Lind)博士指出,坏血病在地中海地区的船只上受到的影响较小。 他开始给一些水手送柠檬和橙子,让其他人按常规饮食。 实验非常成功,但是医生不明白原因。 在英国皇家海事医院,他用浓柠檬汁治疗坏血病的病人,他称之为抢劫。 医生通过加热将其浓缩,从而破坏了维生素C。Lind失去了信心,经常诉诸放血。 1793年,进行了实际测试。 柠檬汁已成为水手日常饮食的一部分。 坏血病很快就消失了,英国水手们仍然被称为柠檬草。
例子2 玛丽莎·梅耶(Marissa Mayer)谈到了一项实验,其中Google将搜索页上的搜索结果数量从10个增加到了30个。在Google上进行搜索的用户的流量和利润下降了20%。 她怎么解释的? 就像,该页面需要多半秒钟才能生成。 当然,生产力是一个重要因素,但是我们怀疑这仅影响了很小一部分损失。 这是我们对原因的看法:
- Bing进行了隔离的减速实验[11],在此期间仅性能发生了变化。 250毫秒的服务器响应延迟影响了收入约1.5%和点击率0.25%。 这是一个很大的影响,可以假设500毫秒分别对收入和点击率产生3%和0.5%的影响,但对20%的影响不大(假设此处适用线性近似)。 Bing [32]中的旧测试显示了对点击的类似效果,并且对收入的影响较小,延迟了2秒。
- Google的杰克·布鲁塔格(Jake Brutlag)在博客中写到了一个实验[12],该实验表明,将搜索结果从100毫秒减至400毫秒会对特定的搜索次数产生重大影响,范围介于0.2%和0.6%之间,效果非常好与我们的实验相比,但与Marissa Mayer的结果相去甚远。
- BIng进行了一次实验,显示了20条搜索结果,而不是10条。利润的损失完全消除了添加其他广告的麻烦(这使页面速度稍慢一些)。 我们认为广告与搜索算法的比例比效果重要得多。
我们对各种来源发布的A / B测试的许多出色结果表示怀疑。 检查实验结果时,请问自己对实验的信任程度如何? 请记住,即使这个想法在一个站点上可行,也没有必要在另一个站点上可行。 我们能做的最好的事情是谈论实验的复制及其成功或失败。 这将对科学最有益。
规则4:速度意味着很多
使用控制实验测试其功能的Web开发人员很快意识到站点性能或速度是关键参数[13; 14; 33]。 即使站点运行稍有延迟,也会影响测试组的关键指标。
评估效果影响的最佳方法是进行单独的减速实验,即 只是增加延迟。 图3显示了性能与被测指标(点击率,单位成功率和收益)之间关系的标准图。 通常,网站越快越好(此图越高)。 放慢测试组相对于对照组的工作,您可以衡量性能对您感兴趣的指标的影响。 重要的是要注意:
- 在这里和现在(图表中的虚线)衡量减慢对测试组的影响,具体取决于站点和受众。 如果网站或受众群体发生变化,则性能下降可能会不同地影响关键指标。
- 实验显示了减速对关键指标的影响。 当您尝试评估其第一个实现无效的新功能的效果时,这可能非常有用。 假设它将M的度量提高X%,同时将网站的速度降低T%。 使用带减速度的实验,我们可以评估减速度对度量M的影响,校正特征的影响并获得预测的影响X'%(逻辑上假设这些影响具有可加性)。 因此,我们可以回答以下问题:“如果有效实施关键指标,它将如何影响关键指标?”。
- 我们可以假设站点将开始更快地运行并帮助计算优化工作的投资回报率这一事实将如何影响关键指标。 使用线性近似(泰勒级数的第一项),我们可以假设对度量的影响在两个方向上都是相同的。 我们假设垂直增量在两个方向上相同,而符号不同。 因此,通过对各种值进行减速度试验,我们可以粗略地想象出加速度将如何影响这些相同的值。 我们在必应(Bing)进行了此类测试,我们的理论已得到充分证实。
绩效有多重要? 至关重要。 正如格雷格·林德德(Greg Linded)所说[34 p.10],在亚马逊,100毫秒的减速导致销售额下降1%。 来自Bing和Google [32]的演讲者展示了性能对关键指标的重大影响。
示例:服务器减速实验
我们在Bing进行了为期两周的实验,以将10%的用户的服务速度降低100毫秒,将其他10%的用户的服务速度降低250毫秒。 事实证明,每100毫秒的服务加速将收入提高0.6%。 从这里开始,甚至出现了一个短语,可以很好地反映我们组织的本质:
工程师将服务器性能提高10毫秒(眨眼速度的1/30),将为他的公司带来超过一年的收入。 每毫秒都很重要。
在上述实验中,我们放慢了服务器的响应时间,然后放慢了页面上所有元素的运行时间。 但是页面上有更多重要的部分,而没有那么重要的部分。 例如,用户可能不知道屏幕范围之外的项目尚未加载。 但是,是否有任何立即显示的元素可以放慢速度而不会损害用户? 正如您将在下面看到的那样,有这样的元素。
示例:右面板的性能不是很关键
在Bing中,一些称为快照的元素位于右侧面板中,并且在稍后加载(在window.onload事件之后)。 我们最近进行了一项实验:右侧面板的元素放慢了250毫秒。 如果这影响了关键指标,那么它微不足道,以至于我们什么都没注意到。 实验涉及近2000万用户。
页面加载时间(PLT)通常使用window.onload事件来计算,以表明有用的浏览器活动已完成。 但是今天,在使用现代浏览器时,该指标存在严重缺陷。 如Steve Souders [32]所示,Amazon页面的顶部在2秒内呈现,而windows.onload在5.2秒内触发。 Schurman [32]指出,他们能够动态呈现页面,因此对他们来说,非常迅速地显示页眉很重要。 反之亦然:在Gmail中,windows.onload将在3.3秒后触发,而此时只有下载栏出现在屏幕上,所有内容将在4.8秒后显示。
有一些与时间相关的指标,例如:第一个结果的时间(例如,Twitter上第一个tweet的时间,结果页面上的第一个搜索结果)。 但是术语“感知的性能”始终用于描述这样的页面速度,以便用户感知页面的速度。 “感知性能”的概念比严格表述的描述更容易直观地描述,因此,没有浏览器计划实现
perception.ready()事件。 为了解决此问题,使用了许多假设和假设,例如:
- 页面顶部(AFT)时间[37]。 度量为显示页面所有顶部像素的时刻。 该实现基于启发式处理,当处理视频,GIF,滚动画廊和其他更改页面顶部的动态内容时,启发式处理特别复杂。 可以将阈值设置为“绘制像素的百分比”,以避免可能增加测量指标的小的无关紧要的元素的影响。
- 速度索引[38]是AFT的某种概括,它平均显示可见页面元素在屏幕上出现的时间。 速度不会受到出现太晚的小元素的影响,但仍然受更改页面顶部的动态内容的影响。
- 页面阶段时间和用户可用性时间[39]。 页面阶段时间-每个页面呈现阶段所需的时间。 , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
结论
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
- Kohavi,Ron和Round,Matt。Amazon.com上的前线Internet分析。[编辑]吉姆·斯特恩。加利福尼亚州圣巴巴拉(Santa Barbara),加利福尼亚:锡,2004年。ai.stanford.edu/〜ronnyk / emetricsAmazon.pdf。
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010。
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.