
扩展DBMS是一个不断前进的未来。 DBMS在硬件平台上进行了改进和扩展,而硬件平台本身提高了生产率,内核数量和内存-阿喀琉斯正在追赶乌龟,但还没有赶上乌龟。 扩展DBMS的问题已全面展开。
Postgres Professional不仅在理论上而且在实践上都存在扩展问题:与客户进行扩展。 并且不止一次。 本文将讨论其中一种情况。
如果PostgreSQL是具有多个处理器和多个数据总线的单个主板,则PostgreSQL在NUMA系统上的扩展性很好。 一些优化可以在
这里和
这里阅读。 但是,还有另一类系统,它们具有数个主板,它们之间的数据交换是通过互连进行的,而一个OS实例正在它们上运行,对于用户而言,该设计就像一台机器。 尽管从形式上说,此类系统也可以归因于NUMA,但从本质上讲,它们更接近于超级计算机,例如 对节点本地内存的访问和对相邻节点内存的访问在根本上是不同的。 PostgreSQL社区认为,在这样的架构上运行的唯一Postgres实例是问题的根源,并且还没有系统的方法来解决它们。
这是因为使用共享内存的软件体系结构从根本上设计用于以下事实:不同进程对其自身和远程内存的访问时间或多或少具有可比性。 在我们使用多个节点的情况下,对共享内存作为快速通信通道的赌注不再证明其合理性,因为由于延迟,将请求执行特定操作的请求发送给节点(节点)非常“便宜”有趣的数据,而不是在总线上发送此数据。 因此,对于超级计算机以及通常具有多个节点的系统而言,群集解决方案至关重要。
这并不意味着需要结束多节点系统和典型的Postgres共享内存体系结构的结合。 毕竟,如果postgres流程大部分时间都在本地进行复杂的计算,那么这种架构甚至会非常高效。 在我们的情况下,客户端已经购买了功能强大的多节点服务器,因此我们不得不解决PostgreSQL的问题。
但是问题很严重:最简单的写请求(在一条记录中更改多个字段值)在几分钟到一个小时的时间内执行。 正如后来证实的那样,这些问题恰恰是由于拥有大量的内核以及相应地在节点之间交换相对较慢的请求的执行过程中的根本并行性而在其全部荣耀中得以体现。
因此,该文章实际上是出于双重目的:
- 分享经验:如果在多节点系统中数据库认真运行,该怎么办。 从何处开始,如何诊断向何处移动。
- 描述如何通过高并发度解决PostgreSQL DBMS本身的问题。 包括获取锁的算法中的更改如何影响PostgreSQL的性能。
服务器和数据库
该系统由8个刀片组成,每个刀片中有2个插槽。 总共有300多个核心(超跑除外)。 快速轮胎(专有制造商技术)连接叶片。 并不是说它是一台超级计算机,而是一个DBMS实例,其配置令人印象深刻。
负载也相当大。 超过1 TB的数据。 每秒约3000笔交易。 超过1000个与postgres的连接。
开始处理每小时的录制期望后,我们要做的第一件事是将光盘写入光盘,这是造成延迟的原因。 一旦出现了难以理解的延迟,就开始专门在
tmpfs上进行测试。 图片未变。 磁盘与它无关。
诊断入门:视图
由于问题很可能是由于“敲打”相同对象的过程的激烈竞争而引起的,因此首先要检查的是锁。 在PostgreSQL中,有一个视图
pg.catalog.pg_locks和
pg_stat_activity用于这种检查。 第二个版本已经在9.6版中,添加了有关进程正在等待什么的信息(
Amit Kapila,Ildus Kurbangaliev )
wait_event_type 。 在此描述该字段的可能值。
但首先,只需数:
postgres=
这些是实数。 达到200,000个锁。
同时,这样的锁挂在命运不佳的请求上:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
读取缓冲区时,DBMS在写“
exclusive时使用
share锁。 也就是说,写锁仅占所有请求的不到1%。
在
pg_locks视图中,锁类型并不总是看起来像用户
文档中所述 。
这是火柴板:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
SELECT模式FROM pg_locks查询显示,CREATE INDEX(没有CONCURRENTLY)将等待234 INSERT和390 INSERT
buffer content lock 。 一种可能的解决方案是“教导”来自不同会话的INSERT,以减少与缓冲区的相交。
是时候使用perf
perf实用程序收集大量诊断信息。 在
record模式下,它将系统事件的统计信息写入文件(默认情况下,它们在
./perf_data ),在
report模式下,它分析收集的数据,例如,您可以过滤仅涉及
postgres或给定
pid :
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
结果,我们将看到类似
例如,
此处以及
pg wiki中都描述了如何使用
perf诊断PostgreSQL。
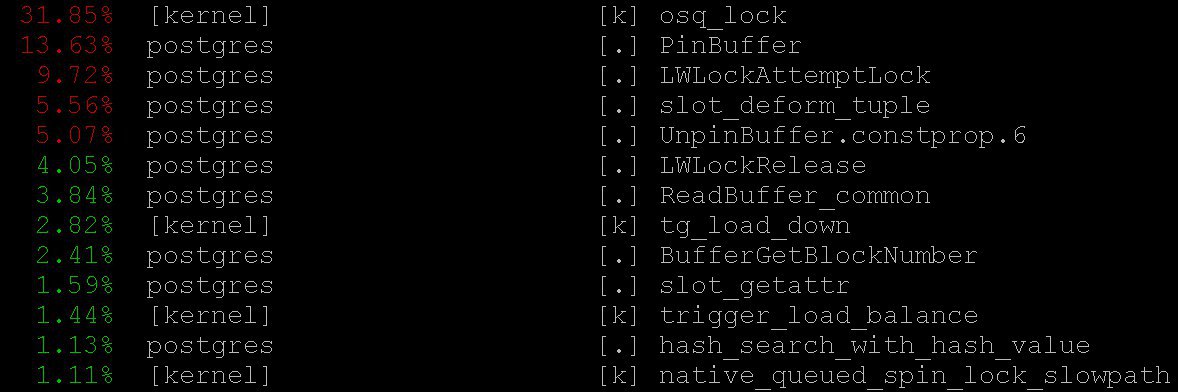
在我们的案例中,即使是最简单的模式也可以为
perf top重要信息
perf top ,这当然是出于
top操作系统的精神。 在
perf top我们看到了处理器大部分时间都花在核心
PinBuffer()以及
PinBuffer()和
LWLockAttemptLock().函数上
LWLockAttemptLock(). 。
PinBuffer()是一个增加对缓冲区引用的计数器(将数据页映射到RAM)的函数,这要归功于postgres进程知道哪些缓冲区可以被强制使用,哪些不能。
LWLockAttemptLock() -
LWLock的捕获功能。
LWLock是一种具有
shared和
exclusive两个级别的锁,无需定义
deadlock ,而是将锁预先分配给
shared memory ,等待进程在队列中等待。
这些功能已经在PostgreSQL 9.5和9.6中进行了认真的优化。 直接使用原子操作代替了它们内部的自旋锁。
火焰图
没有它们是不可能的:即使它们没有用,仍然值得一提。它们非常美丽。 但是它们很有用。 这是来自
github的说明,不是来自我们的案例(我们和客户都尚未准备好公开细节)。

这些精美的图片非常清楚地显示了处理器的周期。 相同的性能可以收集数据,但是
flame graph智能地可视化数据,并根据收集的调用堆栈构建树。 例如,您可以
在此处阅读有关火焰图分析的更多信息,并
在此处下载所需的一切。
在我们的案例中,火焰图上可见大量的
nestloop 。 显然,在众多并发读取请求中大量表的JOIN导致了大量
access share锁。
perf收集的统计信息显示了处理器周期的去向。 尽管我们看到处理器的大部分时间都是通过锁来进行的,但是我们并没有看到导致如此长的锁期望的确切原因,因为我们没有确切看到锁期望发生的位置,因为 CPU时间不会浪费在等待上。
为了自己查看期望,您可以向系统视图
pg_stat_activity建立一个请求。
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
透露:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(此处的星号仅替换我们未公开的请求详细信息)。
您可以看到值
buffer_content (阻止缓冲区的内容)和
buffer_mapping (阻止哈希板的
shared_buffers的组件)。
为gdb提供帮助
但是为什么对这些类型的锁有如此高的期望呢? 有关期望的更多详细信息,我必须使用
GDB调试器。 使用
GDB我们可以获得特定过程的调用堆栈。 通过应用采样,即 收集一定数量的随机调用堆栈后,您可以了解哪些堆栈期望值最高。
考虑编译统计信息的过程。 我们将考虑“手动”统计信息收集,尽管在现实生活中使用了自动执行此操作的特殊脚本。
首先,需要将
gdb附加到PostgreSQL进程中。 为此,请找到服务器进程的
pid ,例如
$ ps aux | grep postgres
假设我们发现:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
然后将
pid插入调试器:
igor_le:~$gdb -p 2025
进入调试器后,我们将写入
bt [即
backtrace ]或
where 。 我们获得了有关此类型的很多信息:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
收集了包括所有postgres进程的调用堆栈在内的统计信息后,在不同的时间点重复收集了这些统计信息,我们发现
relation extension lock内的
buffer partition lock relation extension lock持续了3706秒(约一个小时),即,锁在缓冲区的哈希表中经理,这是取代旧缓冲区所必需的,以便随后用对应于表扩展部分的新缓冲区替换它。 还注意到一定数量的
buffer content lock锁定,这与锁定
B-tree索引页以进行插入的预期相对应。

首先,对于如此可怕的等待时间有两种解释:
- 有人拿着这个
LWLock卡住了。 但这不太可能。 因为缓冲区分区锁内部没有发生任何复杂的事情。 - 我们遇到了
LWLock某些病理行为。 也就是说,尽管事实上没有人锁得太久,但他的期望却持续了很长时间。
诊断补丁和树木处理
通过减少同时连接的数量,我们可能会释放对锁的请求流。 但这就像投降。 相反,Postgres Professional的首席架构师
Alexander Korotkov (当然,他帮助撰写了这篇文章)提出了一系列补丁。
首先,有必要更详细地了解这场灾难。 无论最终工具的质量如何,它们自己制造的诊断补丁也将很有用。
编写了一个补丁,详细记录了
relation extension花费的时间,以及
RelationAddExtraBlocks()函数内部发生的事情,因此我们找出了
RelationAddExtraBlocks().内部所花费的时间
RelationAddExtraBlocks().为了支持他,在
pg_stat_activity中写了另一个补丁,报告了我们现在在
relation extension正在做的事情。 这样做是这样的:
relation扩展时,
application_name变为
RelationAddExtraBlocks 。 现在可以使用
gdb bt和
perf方便地分析此过程,并提供最大的详细信息。
实际上,医疗(而非诊断)补丁被写入了两个。 第一个修补程序更改了
B‐tree树叶子锁的行为:早些时候,当请求插入时,叶子被作为
share被阻止,然后它被
exclusive 。 现在他立刻变得
exclusive 。 现在,该补丁
已提交给
PostgreSQL 12 。 幸运的是,今年
亚历山大·科罗特科夫(Alexander Korotkov)获得
了提交者的
身份 -俄罗斯的第二位PostgreSQL提交者和公司的第二位。
NUM_BUFFER_PARTITIONS值也从128增加到512,以减少映射锁的负载:将缓冲区管理器哈希表分为较小的块,以希望减少每个特定块的负载。
应用此修补程序后,缓冲区内容上的锁定已消失,但是尽管
NUM_BUFFER_PARTITIONS增加了,但
buffer_mapping仍然存在,也就是说,我们提醒您要阻塞缓冲区管理器哈希表的各个部分:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
甚至还不多。 B树不再是瓶颈。
heap-扩展脱颖而出。
良心的治疗
接下来,亚历山大提出以下假设和解决方案:
buffer parittion lock缓冲区时,我们会在
buffer parittion lock等待很多时间。 也许在同一个
buffer parittion lock有一些非常需要的页面,例如某些
B‐tree的根。 此时,从读取请求开始有持续不断的
shared lock请求流。
LWLock的等待线“不公平”。 由于可以一次获取任意数量的
shared lock ,因此,如果已经获取
shared lock ,则后续的
shared lock将通过而不会排队。 因此,如果共享锁流的强度足够大,以至于它们之间没有“窗口”,那么等待
exclusive lock将几乎达到无穷大。
要解决此问题,您可以尝试提供-锁的“绅士”行为补丁。 它唤醒了
shared locker的良心,当已经存在
exclusive lock时,它们会诚实地排队(有趣的是,沉重的锁
hwlock良心没有问题:它们总是诚实地排队)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
一切都很好! 没有长
insert 。 尽管在仪表板上的锁仍然存在。 但是要做的是,这些就是我们小型超级计算机轮胎的特性。
此补丁也已
提供给社区 。 但是,无论社区中这些补丁的命运如何发展,都无法阻止它们进入
Postgres Pro Enterprise的下一版本,后者是专为系统负载较重的客户而设计的。
品德
高道德轻量级
share锁-跳过队列的
exclusive块解决了多节点系统中每小时延迟的问题。 由于
share lock流量过多,
buffer manager哈希标记无法正常工作,因此没有机会获得替代旧缓冲区和加载新缓冲区所需的锁。 数据库表的缓冲区扩展问题仅是由此造成的。 在此之前,可以通过访问
B-tree来扩展瓶颈。
PostgreSQL不是为NUMA体系结构和超级计算机而设计的。 适应这样的Postgres架构是一项巨大的工作,需要(甚至可能需要)许多人甚至公司的共同努力。 但是,可以缓解这些体系结构问题带来的不愉快后果。 我们必须:导致类似于所描述的延迟的负载类型是非常典型的,来自其他地方的相似求救信号继续传给我们。 类似的问题在较早出现-在内核较少的系统上,其后果并不那么可怕,并且可以使用其他方法和其他补丁来解决症状。 现在出现了另一种药物-不是通用的,但显然有用。
因此,当PostgreSQL将整个系统的内存用作本地内存时,节点之间的高速总线无法与本地内存的访问时间进行比较。 任务的出现是因为这种困难,通常是紧急的,但很有趣。 解决这些问题的经验不仅对决策者有用,而且对整个社区都是有用的。
