
从人们拾起石头的那一刻起就创造出的每项技术都必须改善人们的生活,发挥其主要功能。 但是,任何技术都可能产生“副作用”,即以创造该技术时没人想到或不想考虑的方式影响一个人和他周围的世界。 一个生动的例子:创造了机器,一个人能够以比以前更快的速度移动长距离。 但是同时污染开始了。
今天,我们将讨论互联网的“副作用”,它不影响地球的大气,而是影响人们自身的思想和灵魂。 事实是,万维网已经成为传播和交换信息,彼此相距遥远的人们之间以及更远的人们之间进行交流的出色工具。 互联网在社会的各个领域都可以提供帮助,从医学到为历史考验平庸的准备。 但是,不幸的是,聚集了很多(有时是无名的)声音和意见的地方充满了人与生俱来的仇恨。
在今天的研究中,科学家将几种算法分解为几个算法,其主要任务是识别令人反感,粗鲁和敌对的信息。 他们设法打破了所有这些算法,从而证明了它们的低效率,并指出了应纠正的错误。 科学家如何打破所谓的工作原理,为什么这样做以及我们都必须得出什么结论—我们将在研究人员的报告中寻找这些以及其他问题的答案。 走吧
研究背景人们之间的社交网络和其他形式的Internet交互已成为我们生活中不可或缺的一部分。 不幸的是,此类服务的许多用户在字面上也理解“言论,思想和表达自由”之类的东西,并以其在网络上具有不雅,熟悉和粗鲁行为的权利来涵盖这一点。 我们每个人都以某种方式面临着这些人的“活动”。 许多人甚至成为此类演讲的对象。 当然,不能否认一个人有权说出自己的想法。 但是,表达自己的想法是一回事,侮辱别人是另一回事。 除了言论自由之外,还利用了匿名性,因为您可以在保持隐身状态的同时对任何人说任何话。 因此,您将不会因不当行为而受到惩罚。
值得解释的是,“我不喜欢”和“这真是个他妈的**,作者在墙上被杀”(这或多或少是体面的选择)这两个词虽然完全相同,但却具有不同的情感色彩。我不喜欢他所见/所读/所听,等等。 但是,如果您禁止某人以这种方式表示不满,是否认为这侵犯了他的权利? 许多人会说“是”。 另一方面,是否值得继续对Internet上呈指数增长的仇恨视而不见,这在大多数情况下是没有道理的。 因此,仇恨是一个存在的地方。 当然,这是一种非常强烈且令人难以置信的消极情绪。 但是,如果一个人讨厌做某件事的人(杀人,强奸和其他不人道的举动),那仍然可以以某种方式辩解。 但是,当仇恨出现在一个完全外星人的讲话中,而这个人没有犯下任何不道德或不人道的东西时,这是一个完全不同的故事。
现在,许多公司和研究小组已决定创建自己的算法,该算法可以分析任何文本并判断
敌对语言*的位置以及表达的程度。 我们今天的英雄决定测试这些算法,尤其是非常受好评的Google Perspective API,它确定了短语“酸度”,即 这句话多少算是侮辱。
仇恨言论* -从该词的名称可以明显看出,这是语言手段的结合,旨在表达对话者之间的生动敌意。 仇恨言论最常见的形式是:种族主义,性别歧视,仇外心理,同性恋恐惧症和对其他事物的敌对形式。
研究人员为自己设定的主要任务是研究最流行的识别仇恨言论的算法,了解他们的工作方法并设法解决它们。
研究算法科学家们选择了几种算法,这些算法的数据库互不相同,这也使我们能够确定最佳的数据库。 一些算法更多地依赖于识别性
含义* ,而其他算法则是宗教性的。 所有算法的共同点是其知识的来源-Twitter。 根据研究人员的说法,这远非完美,因为这项服务有一定的局限性(例如,一条消息中的字符数)。 因此,有效算法的基础应来自不同的社交网络和服务。
内涵* -一种用其他语义或情感阴影为单词或短语着色的方法。 可能会因语言,文化或其他形式的社会隔离而有所不同。 例如:刮风-“那天刮风”(单词的直接含义),“他一直是刮风的人”(在这种情况下,这意味着不稳定和轻浮)。
算法及其功能列表:
排毒 :维基百科项目,用于在编辑评论中识别不适当的语言。 它在
逻辑回归*和
多层感知器*的基础上工作,在字母和单词级别使用
N-gram *模型。 一个单词的N语法的大小从1到3不等,字母-从1到5。
Logistic回归*是用于通过将数据拟合到Logistic曲线来预测事件概率的模型。
多层感知器*是信息感知的模型,由三个主要层组成:S-传感器(接收信号),A-关联元素(处理)和R反应元素(对信号的响应)以及附加层A。
N-gram *是n个元素的序列。
算法库的数据是由第三方收集的,每个注释都由十个评估者评估。
T1 :一种算法,其基础分为Twitter的三种评论类型(仇恨言论,无仇恨言论和中立言论)。 研究人员说,这是唯一具有类似分类的基础。 通过在Twitter上搜索给定模式可以检测到仇恨言论。 此外,发现的结果由三名CrowdFlower员工(现为图八公司,对机器学习和人工智能的研究)进行了评估。 大部分基数(76%)是令人反感的短语,而敌对语言仅占5%。
T2 :使用深度神经网络的算法。 主要重点放在长期短期记忆(LSTM)上。 该算法的基础分为三类:种族主义,性别歧视和什么都没有。 研究人员将前两类归为一类,构成了敌对语言的组成部分。 该基础的基础是16,000条推文。
T1 * ,
T3 :一种基于卷积神经网络(CNN)和受控递归单位(GRU)的算法,使用T1知识库,并针对难民和穆斯林(T3)单独分类。
算法性能通过两种方法测试了算法的性能。 首先,他们按原计划工作。 第二,通过每种算法的数据库训练算法,这是一种经验交流。
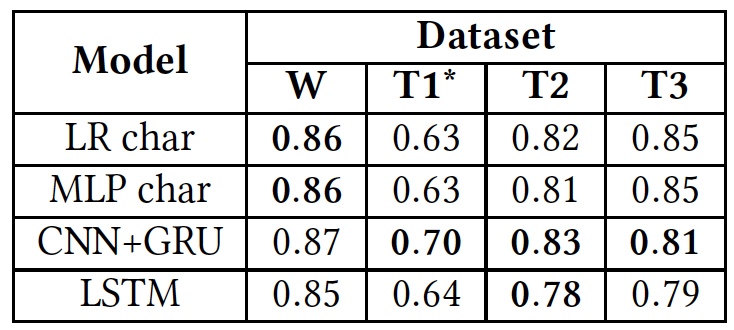 测试结果(使用原始数据库的结果以粗体显示)。
测试结果(使用原始数据库的结果以粗体显示)。从上表可以看出,当应用于不同的文本(数据库)时,所有算法都显示出大致相同的结果。 这表明他们都使用相同类型的文本进行学习。
唯一显着的偏差在T1 *中可见。 据科学家称,这是因为该算法的数据库极不平衡。 众所周知,仇恨言论只占5%。 最初的划分为三类文本,当“侮辱但没有敌对语言”和“中立”文本合并为一组时,又被分为两类,占整个基础的80%。
此外,研究人员对算法进行了重新训练。 首先,使用原始的基础。 之后,每种算法都必须与其他算法一起使用,而不是自己使用。
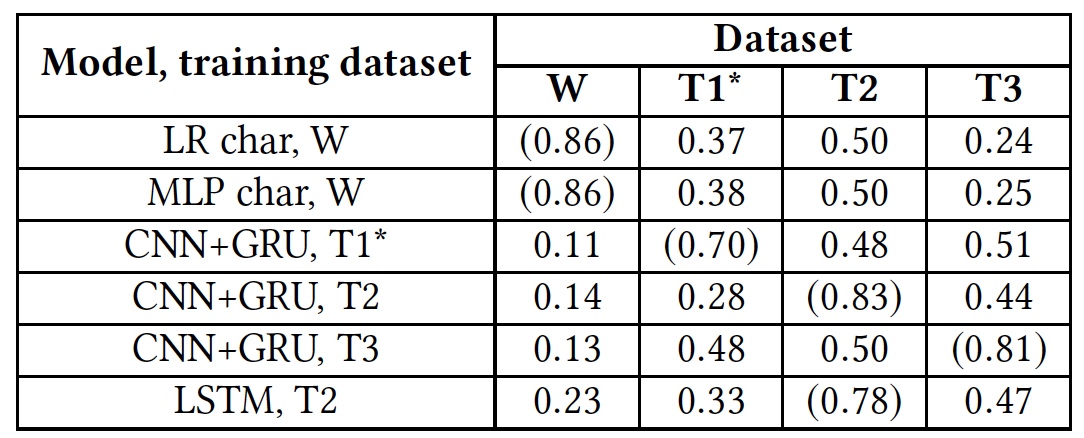 重新训练测试结果(括号中显示使用本机数据库的结果)。
重新训练测试结果(括号中显示使用本机数据库的结果)。该测试表明,所有算法对于使用外部数据库都是完全没有准备的。 这表明仇恨言论的语言指标在不同的数据库中不相交,这可能是由于以下事实:在不同的数据库中匹配的单词很少,或者由于某些短语的解释不准确。
侮辱和仇恨言论研究人员决定特别注意两类文本:令人反感和敌对。 最重要的是,有些算法将它们组合到一个堆中,而另一些则尝试将它们分成独立的组。 当然,侮辱显然是一种消极现象,可以肯定地将其归为具有敌意的一类。 但是,定义侮辱比识别文本中明显的仇恨要复杂得多。
为了测试算法检测侮辱的能力,使用了T1基地。 但是T1 *算法没有参加此测试,因为它已经为这种工作做好了准备,这使得其验证结果有偏差。
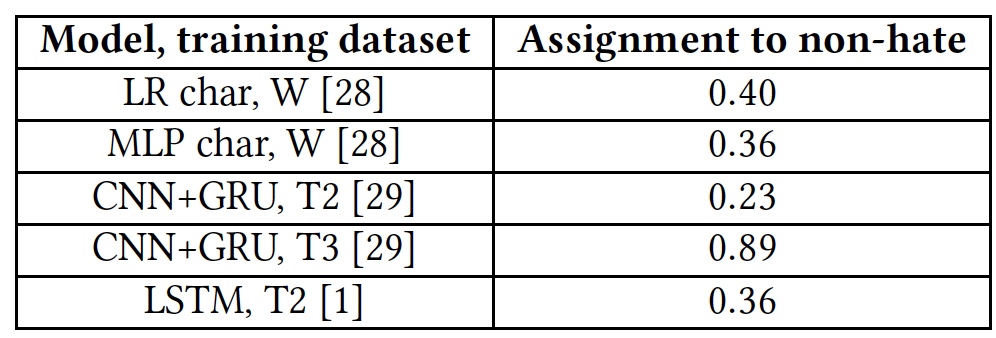 测试结果以检测冒犯性文字。
测试结果以检测冒犯性文字。所有算法均显示出中等的结果。 T3是一个例外,但不能以牺牲他们的才华为代价。 事实是,不熟悉算法的单词会用
unk标签标记。 每个句子中将近40%的单词都带有此标记,该算法会自动将其视为侮辱。 当然,这远非总是正确的。 换句话说,鉴于其词汇量短,T3算法也无法应付任务。
算法的主要问题之一是科学家考虑人为因素。 每种算法的大多数数据库都是由人们收集,分析和评估的。 在这里,结果可能存在很大差异。 同一句话对某些人来说可能是令人反感的,对其他人则是中立的。
同样,缺乏用于理解可以从容地包含粗俗语言但没有任何侮辱或敌对语言的非标准短语的算法,也起到了负面作用。
为了证明这一点,进行了几个短语的测试。 然后重复测试,但是在每个短语中都添加了非常淫秽的单词“
f * ck ”(在表中以字母
F标记)。
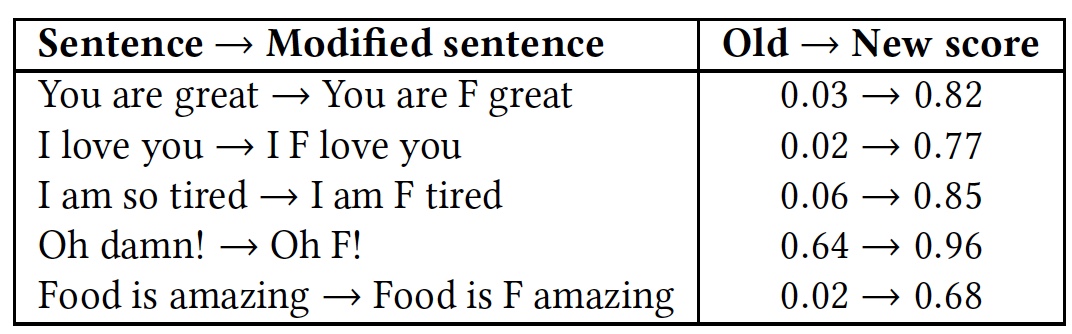 有和没有单词“ f * ck”的短语的比较识别结果。
有和没有单词“ f * ck”的短语的比较识别结果。从表中可以看出,值得在字母F后面加上一个词,因为所有算法都会立即将该短语视为一种敌对语言。 尽管这些短语的本质保持不变,友好,但情感色彩却变得更加明显。
上述的Google Perspective API测试显示了相似的结果。 该算法也无法将侮辱性语言与侮辱区分开,也无法从用来情感修饰词组的简单上位词中侮辱他人。
如何欺骗算法?经常发生的事情是,如果有人破坏了某件事,那么这并不总是不好的。 所有这些都是因为当我们崩溃时,我们发现系统的不足,即它的弱点,应该通过防止重复出现故障来改善这一点。 以上模型也不例外,研究人员决定研究如何破坏他们的工作。 事实证明,这并不比这些算法的创建者想象的难。
算法旁路模型很简单:破解者知道他的文本已被检查,他可以更改输入数据(文本)以避免检测到。 破解者无法访问算法本身及其结构。 简而言之,攻击者仅在用户级别破坏算法。
算法旁路(我们称其为好词“ hacking”)分为三种类型:
- 更改单词:有意的错别字和Leet,即用数字替换一些字母(例如:您今天看起来很棒!-Y0U 100K 6r347 70D4Y!);
- 更改单词之间的空格:添加和删除空格;
- 在短语的末尾添加单词。
第一个黑客程序-更改单词-应该成功完成三个任务:通过算法降低单词的识别程度,避免拼写更正以及保持单词对人的可读性。
该程序交换单词中的两个字母。 优先选择靠近单词中部且彼此靠近的字母。 仅排除单词中的第一个和最后一个字母。 此外,注意单词Leet可以对单词进行修饰,其中一些字母被数字替换:a-4,e-3,l-1,o-0,s-5。
为了应对这些技巧,通过引入拼写检查和训练知识库的随机转换对算法进行了一些改进。 也就是说,不仅主要单词出现在数据库中,而且通过重新排列表格的字母也对其进行了更改。
但是,单词越长,存在的字母重排选项就越多,这扩展了破解程序的功能。
删除或添加空间的方法也有其自身的特点。 删除空格更适合于解析整个单词的相反算法。 但是分析每个字母的算法可以轻松解决空格的问题。
添加空格似乎是一种非常低效的方法,但是它仍然可以欺骗某些算法。 考虑单词整体的模型对短语进行词法分析,将其分解为组成部分(令牌)。 在这种情况下,空格用作单词分隔符,即短语分析的重要元素。 如果有多余的间隙,则算法中无法识别它们之间的单词。 同时,这种旁路方法为人保留了短语的高度可读性。 该方法的工作原理很简单:选择单词中的一个随机字母,然后在其后加一个空格。 结果,该算法先前已知的单词不再是这样。 例如:“讨厌”-“讨厌”。 如果消除了文本中的所有空白,则整个短语对于算法来说将成为他一个难以理解的词。 就像在故事中,女儿给母亲一个新电话,然后她给她写了一条短信,内容是:“亲爱的在电话上留空。” 我们可以阅读该短语,但是算法会将其视为一个单词,这当然是他所不知道的。
但是,如果该算法分别分析字母,则它将能够识别该短语,因此这种黑客方法不适用于这种情况。
为了应对此类攻击,还对算法进行了重新训练。 为了应对空格的增加,算法库通过了一个随机引入空格的程序:n个字母的单词可以用n-1方式用空格分隔。 但是,当算法的复杂度由于输入数据大小的增加而急剧增加时,这导致了组合爆炸。 结果,学习基于众所周知的添加空间方法的算法是极其困难且效率低下的练习。
删除空间也很困难。 如果用他知道的短语来补充算法库,但是没有空格,则只有在应用了这样的短语时,该算法才有效。 值得替换几个字母或一个单词,并且该算法无法识别任何内容。
在通过添加单词的黑客方法中,主要的本质是识别算法的工作原理。 他将单词分为不同类别,分别说“好”和“坏”。 如果短语中有更多“好”的短语,则算法很可能会将整个短语确定为“好”。 反之亦然。 如果您在含义中的“坏”一词中添加一个随机的“好”一词,则可以欺骗算法,并且该短语的含义对于阅读该词的人将保持不变。
hack程序在每个短语的末尾生成随机数(从10到50)或单词。选择了Google提供的最常见的通用英语单词列表作为随机单词的来源。 一张表格,列出了采用上述黑客攻击方法的结果以及算法对此的反应(A-攻击,AT-根据攻击程序的原理进行训练,SC-拼写,RW-删除空格)。为了通过引入其他词来说明解决方法,研究人员使用“ love”一词进行了测试。在攻击性短语的末尾添加了这个词。
一张表格,列出了采用上述黑客攻击方法的结果以及算法对此的反应(A-攻击,AT-根据攻击程序的原理进行训练,SC-拼写,RW-删除空格)。为了通过引入其他词来说明解决方法,研究人员使用“ love”一词进行了测试。在攻击性短语的末尾添加了这个词。 测试结果为“爱”字样。从表中可以看出,该方法能够欺骗所有分析整个单词的算法。单独分析字母的算法也遭受了很大的损失,但是损失不大。早先,Google Perspective API已经过测试,表明它无法识别中立和令人反感的文本。
测试结果为“爱”字样。从表中可以看出,该方法能够欺骗所有分析整个单词的算法。单独分析字母的算法也遭受了很大的损失,但是损失不大。早先,Google Perspective API已经过测试,表明它无法识别中立和令人反感的文本。然后,我们使用了测试词组(出于明显的原因,我不会翻译):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
研究人员在研究中使用了相同的短语。结果明显更好,这表明Google Perspective API得到了增强。但是,将删除空间的方法与在上述每个短语上加上“爱”一词相结合,则显示出完全不同的结果。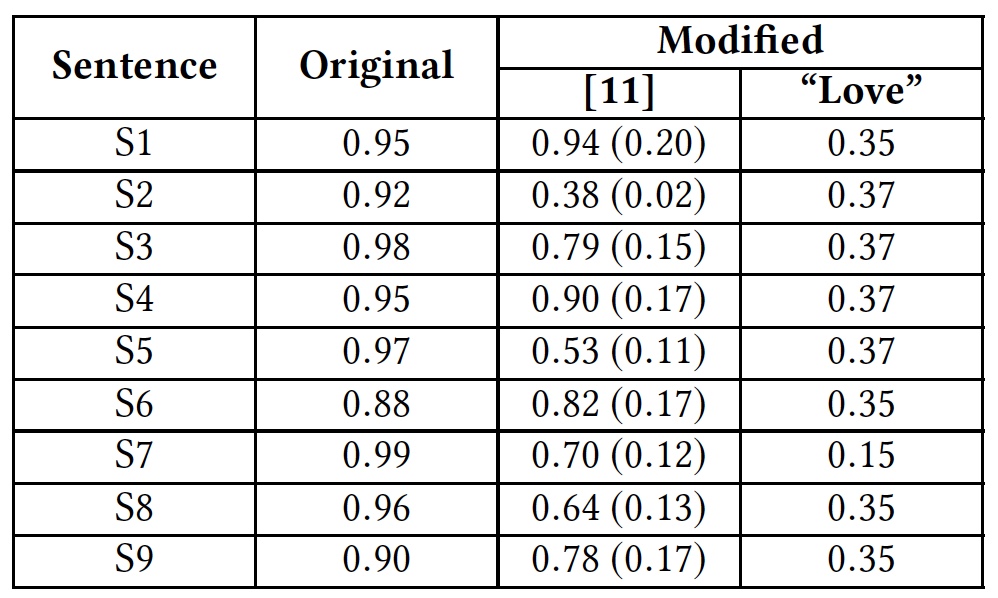 Google Perspective API:短语的“毒性”(冒犯)程度。括号中是当前结果与改进Google Perspective API之前的结果。要更详细地了解这项研究,可以使用此处提供的科学家报告。结语研究人员有意使用欺骗算法的最简单方法来证明其效率低下,并向开发人员指出需要引起注意的薄弱环节。可以在线跟踪攻击性短语的程序当然是个好主意。但是接下来呢?该程序应阻止类似的短语吗?还是她应该建议一个不包含侮辱的替代短语?从道德方面来看,存在很多问题:言论自由,审查制度,行为文化,人人平等等。该计划是否有权决定一个人有权说什么而没有什么权利?可能吧但是,这样的程序的实现应该是无可挑剔的,没有可以用于它的缺陷。而且,尽管科学家们继续为这个问题感到困惑,但社会本身必须自己做出决定-完全的言论自由是如此美丽还是有时受到限制?感谢您与我们在一起。你喜欢我们的文章吗?想看更多有趣的资料吗?通过下订单或将其推荐给您的朋友来支持我们,为我们为您开发的入门级服务器的独特模拟,为Habr用户 提供30%的折扣:关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器?(RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。VPS(KVM)E5-2650 v4(6核)10GB DDR4 240GB SSD 1Gbps至12月免费,在六个月内付款时,您可以在此处订购。戴尔R730xd便宜2倍?只有我们有2 x英特尔Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视从$ 249在荷兰和美国!阅读有关如何构建基础架构大厦的信息。使用Dell R730xd E5-2650 v4服务器花费9000欧元(一分钱)的c类?
Google Perspective API:短语的“毒性”(冒犯)程度。括号中是当前结果与改进Google Perspective API之前的结果。要更详细地了解这项研究,可以使用此处提供的科学家报告。结语研究人员有意使用欺骗算法的最简单方法来证明其效率低下,并向开发人员指出需要引起注意的薄弱环节。可以在线跟踪攻击性短语的程序当然是个好主意。但是接下来呢?该程序应阻止类似的短语吗?还是她应该建议一个不包含侮辱的替代短语?从道德方面来看,存在很多问题:言论自由,审查制度,行为文化,人人平等等。该计划是否有权决定一个人有权说什么而没有什么权利?可能吧但是,这样的程序的实现应该是无可挑剔的,没有可以用于它的缺陷。而且,尽管科学家们继续为这个问题感到困惑,但社会本身必须自己做出决定-完全的言论自由是如此美丽还是有时受到限制?感谢您与我们在一起。你喜欢我们的文章吗?想看更多有趣的资料吗?通过下订单或将其推荐给您的朋友来支持我们,为我们为您开发的入门级服务器的独特模拟,为Habr用户 提供30%的折扣:关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器?(RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。VPS(KVM)E5-2650 v4(6核)10GB DDR4 240GB SSD 1Gbps至12月免费,在六个月内付款时,您可以在此处订购。戴尔R730xd便宜2倍?只有我们有2 x英特尔Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视从$ 249在荷兰和美国!阅读有关如何构建基础架构大厦的信息。使用Dell R730xd E5-2650 v4服务器花费9000欧元(一分钱)的c类?