
这是针对人工智能领域的开发人员的一系列培训文章中的最后一篇文章。 它讨论了创建深度学习模型以生成音乐,选择正确的模型和数据预处理的步骤,并介绍了设置,训练,测试和修改BachBot的过程。
音乐生成-考虑任务
使用人工智能(AI)解决许多问题的第一步是将问题简化为可以通过AI解决的基本问题。 这样的问题之一就是序列预测,它被用于自然语言翻译和处理应用中。 我们生成音乐的任务可以简化为预测音序的问题,并且将针对音符序列进行预测。
选型
有几种不同类型的神经网络可以视为模型:直接分布神经网络,递归神经网络和长期记忆神经网络。
神经元是结合形成神经网络的基本抽象元素。 本质上,神经元是一种在输入端接收数据并输出结果的功能。
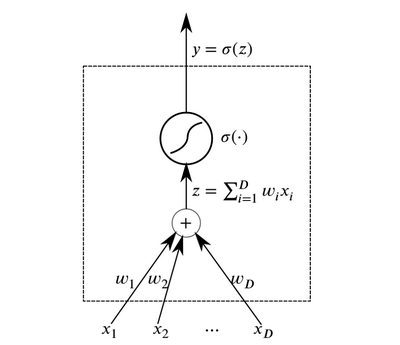 神经元
神经元可以组合在输入端接收相同数据并已连接输出的神经元层,以构建
具有直接传播的
神经网络 。 由于通过数层传递数据时的非线性激活函数的组成,这种神经网络显示出很高的结果(所谓的深度学习)。
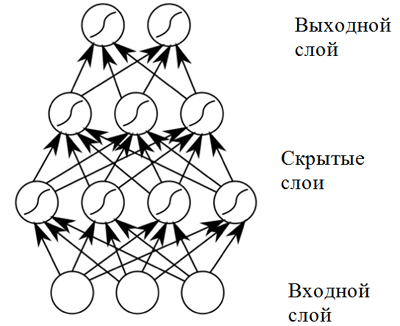 直接分布神经网络
直接分布神经网络直接分布神经网络在广泛的应用中显示出良好的效果。 然而,这种神经网络的一个缺点是不允许其用于与音乐创作有关的任务(顺序预测):它具有固定尺寸的输入数据,并且音乐作品的长度可能不同。 另外,
直接分布神经网络没有考虑先前时间步长的输入,这使得它们对解决序列预测问题不是很有用! 称为
递归神经网络的模型更适合此任务。
递归神经网络通过在隐藏节点之间引入链接来解决这两个问题:在这种情况下,在下一个时间步,节点可以在上一个时间步接收有关数据的信息。
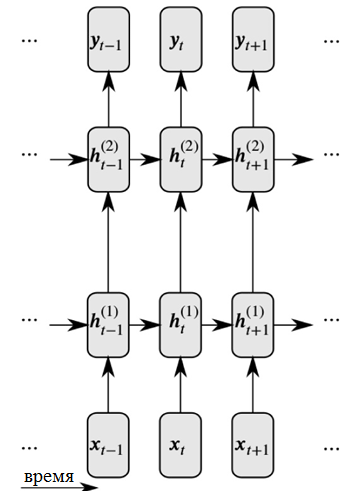 递归神经网络的详细表示
递归神经网络的详细表示如图所示,每个神经元现在都从先前的神经层和先前的时间接收输入。
处理大输入序列的递归神经网络会遇到所谓的
消失梯度问题 :这意味着来自较早时间步长的影响会迅速消失。 这个问题是音乐创作任务的特征,因为在音乐作品中存在重要的长期依赖关系,必须加以考虑。
为了解决梯度消失的问题,可以使用递归网络的一种改进,称为
具有长短期记忆的神经网络(或LSTM神经网络) 。 通过引入存储单元可以解决此问题,该存储单元由三种类型的“门”仔细监视。 单击以下链接以获取更多信息:
有关LSTM神经网络的一般信息 。
因此,BachBot使用基于LSTM神经网络的模型。
预处理
音乐是一种非常复杂的艺术形式,包括各种维度:音高,节奏,节奏,动态阴影,清晰度等等。 为了简化此项目中的音乐
,仅考虑声音的音高和持续时间 。 此外,所有和弦都被
移调到C大调或A小调的音调,并且音符持续时间
在时间上 (四舍五入)被
量化为十六分音的最接近倍数。 采取这些行动是为了降低音乐的复杂性并提高网络性能,同时音乐的基本内容保持不变。 使用music21库对音符的音调和时长进行标准化的操作。
def standardize_key(score): """Converts into the key of C major or A minor. Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474 """
用于标准化所收集作品中关键人物的代码,输出中使用C大写或A小调的键使用
music21库的
Stream.quantize()函数将时间量化为最接近十六分音符的
倍数 。 以下是与数据集进行初步处理之前和之后相关的统计信息的比较:
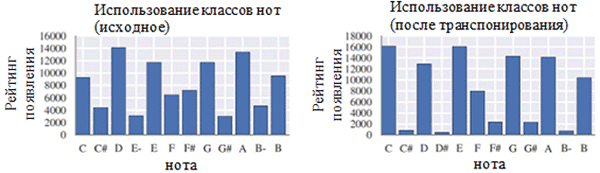 在预处理之前(左)和预处理之后(右)使用每类笔记。 音符类别是一个音符,而不管其八度音阶如何。
在预处理之前(左)和预处理之后(右)使用每类笔记。 音符类别是一个音符,而不管其八度音阶如何。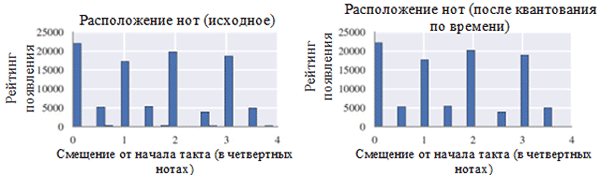 预处理之前(左侧)和之后(右侧)的音符位置
预处理之前(左侧)和之后(右侧)的音符位置从上图中可以看出,合唱的原始音调到C大调或C小调(A小调)的音调极大地影响了所收集作品中使用的音符类别。 尤其是,主键(C大调)和A小调(A小调)(C,D,E,F,G,A,B)中的音调出现次数增加了。 您还可以观察到音符F#和G#的小峰,这是因为它们以旋律A小调(A,B,C,D,E,F#和G#)的升序出现。
另一方面,时间量化的影响要小得多。 这可以用高分辨率的解析度来解释(类似于四舍五入到许多有效数字)。
编码方式
在对数据进行预处理之后,有必要将合唱编码为可以使用递归神经网络轻松处理的格式。 所需的格式是
令牌序列 。 对于BachBot项目,在音符级别(每个记号代表一个音符)而不是和弦(每个记号代表一个和弦)选择编码。 此解决方案将字典的大小从128个
4和弦减少到128个可能的音符,从而提高了工作效率。
为BachBot项目创建了音乐作品的原始编码方案。 合唱分为与十六分音符相对应的时间步长。 这些步骤称为框架。 每个帧包含一个元组序列,这些元组以数字乐器接口(MIDI)的格式表示音符的音高值,以及将该音符绑定到相同高度的先前音符的符号(音符,绑定符号)。 框架中的音符按照高度的降序编号(女高音→alt→中音→低音)。 每个框架也可以有一个标记词组结尾的框架。 Fermata由音符上方的点号(。)表示。
START和
END符号被添加到每个合唱的开始和结尾。 这些符号引起模型的初始化,并允许用户确定合成何时结束。
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
END编码两个和弦的示例。 每个和弦持续小节的第八拍,第二个和弦伴有一个农场。 序列“ |||” 标记帧的结尾 def encode_score(score, keep_fermatas=True, parts_to_mask=[]): """ Encodes a music21 score into a List of chords, where each chord is represented with a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]). If `keep_fermatas` is True, all `has_fermata`s will be False. All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`. Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames. """ encoded_score = [] for chord in (score .quantize((FRAMES_PER_CROTCHET,)) .chordify(addPartIdAsGroup=bool(parts_to_mask)) .flat .notesAndRests):
使用特殊编码方案对音乐21音调进行编码的代码模型任务
在上一部分中,给出了一个说明,该说明表明自动合成的任务可以简化为预测序列的任务。 特别是,模型可以根据以前的音符预测最可能的下一个音符。 为了解决此类问题,最适合使用具有长短期记忆(LSTM)的神经网络。 形式上,模型应该预测P(x
t + 1 | x
t ,h
t-1 ),基于当前标记(x
t )和先前的隐藏状态(h
t-1 )下一个可能的音符(x
t + 1 )的概率分布。 。 有趣的是,相同的操作由基于递归神经网络的语言模型执行。
在组合模式下,使用
START令牌初始化模型,然后选择下一个最可能的令牌。 之后,模型将继续使用前一个音符和前一个隐藏状态选择下一个最可能的标记,直到生成END标记为止。 该系统包含的温度元素会增加一定程度的随机性,以防止BachBot一次又一次地组成同一作品。
损失函数
训练模型进行预测时,通常需要将某些功能最小化(称为损失函数)。 此功能描述了模型预测和地面真实性之间的差异。 BachBot最小化了预测分布(x
t +1 )与目标函数的实际分布之间的交叉熵损失。 将交叉熵用作损失函数是完成许多任务的良好起点,但是在某些情况下,您可以使用自己的损失函数。 另一种可接受的方法是尝试使用各种损失函数并应用一个模型,以将验证期间的实际损失降至最低。
培训/测试
在训练递归神经网络时,BachBot使用值为x
t +1的令牌校正来代替应用模型预测。 这个过程称为强制学习,用于确保收敛,因为模型预测在训练开始时自然会产生较差的结果。 相反,在验证和合成期间,应将模型x
t +1的预测重新用作下一个预测的输入。
其他注意事项
为了提高该模型的效率,使用了LSTM神经网络常用的以下实用方法:归一化梯度截断,消除方法,数据包归一化和截断时间误差回传(BPTT)方法。
归一化的梯度截断方法消除了梯度值不受控制的增长的问题(梯度梯度消失的问题,这是使用LSTM存储单元的体系结构解决的)。 使用此技术,超过某个阈值的梯度值将被截断或缩放。
排除方法是一种在网络训练期间断开(排除)某些
随机选择的神经元的技术。 这样可以避免过度拟合并提高归纳质量。 当模型针对训练数据集进行了优化,并且在较小程度上适用于该数据集之外的样本时,就会出现过度拟合的问题。 排除方法通常会使训练过程中的损失更加严重,但在验证阶段会有所改善(下文对此进行了详细介绍)。
对于1000个元素的序列,在递归神经网络中对梯度的计算与在1000层直接分布神经网络中的前向和后向通道的成本相等。 随着时间的推移
,截断错误回传 (BPTT)方法用于减少训练期间更新参数的成本。 这意味着错误仅在从当前时刻算起的固定时间步长内传播。 请注意,由于以前的许多时间步长已经揭示了潜伏状态,因此使用BPTT方法仍然可以长期学习。
参量
以下是递归神经网络/具有长短期记忆的神经网络模型的相关参数列表:
- 层数 。 增加此参数可能会提高模型的效率,但是训练它会花费更长的时间。 另外,太多的层会导致过度拟合。
- 潜伏状态的维数 。 增加此参数可能会增加模型的复杂性,但是,这可能导致过度拟合。
- 向量比较的维度
- 截断错误随时间的反向传播之前的序列长度 /帧数。
- 排除神经元的概率 。 在每个更新周期内将神经元从网络中排除的概率。
选择最佳参数集的方法将在本文后面讨论。
实施,培训和测试
平台选择
当前,有许多平台可让您以各种编程语言(甚至包括JavaScript!)实现机器学习模型。 流行的平台包括
scikit-learn ,
TensorFlow和
Torch 。
Torch库被选为BachBot项目的平台。 最初,尝试使用TensorFlow库,但那时它使用了广泛的递归神经网络,这导致了GPU RAM的溢出。 Torch是由快速编程语言LuaJIT *支持的科学计算平台。 Torch平台包含出色的库,可用于神经网络和优化。
模型实施和培训
显然,实现会因您选择的语言和平台而异。 要了解BachBot如何使用Torch来实现具有长期,短期记忆的神经网络,请查看用于训练和设置BachBot参数的脚本。 这些脚本可以在
Feynman Lyang GitHub网站
上找到
。1-train.zsh脚本是浏览存储库的一个很好的起点。 有了它,您可以找到
bachbot.py文件的路径。
更准确地说,用于设置模型参数的主要脚本是
LSTM.lua文件。 训练模型的脚本是
train.lua文件。
超参数优化
为了搜索超参数的最佳值,使用了网格搜索方法,并使用了以下参数网格。
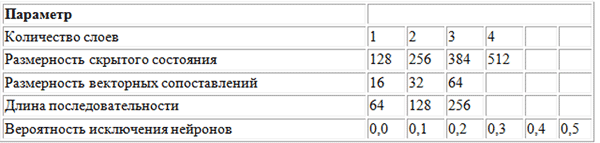 BachBot在网格搜索中使用的参数的网格
BachBot在网格搜索中使用的参数的网格网格搜索是对所有可能的参数组合的完整搜索。 其他建议的用于优化超参数的方法是随机搜索和贝叶斯优化。
网格搜索结果检测到的最佳超参数集如下:层数= 3,隐藏状态的维数= 256,向量比较的维数= 32,序列长度= 128,消除神经元的概率= 0.3。
该模型在训练期间达到0.324的交叉熵损失,在验证阶段达到0.477。 学习曲线图表明,学习过程在30次迭代(使用单个GPU时约等于28.5分钟)后收敛。
训练期间和验证阶段的损耗图也可以说明每个超参数的影响。 我们特别感兴趣的是消除神经元的可能性:
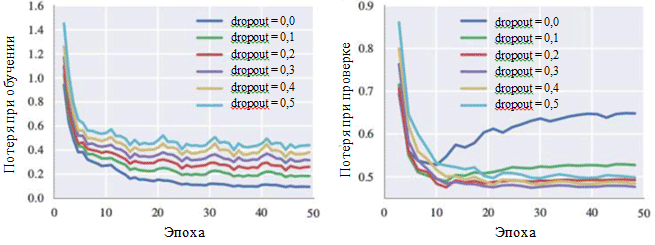 学习各种排除方法设置的曲线
学习各种排除方法设置的曲线从图中可以看出,消除方法确实避免了过拟合的发生。 尽管排除概率为0.0,但训练期间的损失最小,但在验证阶段,损失具有最大值。 较大的概率值会导致训练期间损失增加,而在验证阶段损失减少。 使用BachBot进行验证时,在验证阶段的最小损失值是固定的,例外概率为0.3。
替代评估方法(可选)
对于某些型号(尤其是对于创作应用程序,例如作曲音乐),丢失可能不是衡量系统成功的适当方法。 相反,人的主观感知可能是最好的标准。
BachBot项目的目的是自动创作与Bach自己的作品没有区别的音乐。 为了评估结果是否成功,对互联网上的用户进行了调查。 调查以竞赛形式出现,要求用户确定哪些作品属于BachBot项目,哪些属于Bach。
调查结果显示,被调查的参与者(759名接受不同程度的培训的人)仅在59%的案例中能够准确地区分两个样本。 这仅比随机猜测的结果高9%! 自己尝试
BachBot调查 !
使模型适应统一
现在,BachBot可以基于当前音符和先前的隐藏状态计算P(x
t + 1 | x
t ,h
t-1 ),即下一个可能音符的概率分布。 该顺序预测模型随后可以适于协调旋律。 需要这样一种经过改编的模型来协调通过情感调节的旋律,作为带有幻灯片显示的音乐项目的一部分。
在进行模型和声时,会提供预定的旋律(通常这是女高音的一部分),然后模型应为其余部分创作音乐。 为了完成此任务,使用了贪婪的“最佳第一”搜索,并限制了旋律音符是固定的。 贪婪算法涉及从局部角度来看最佳的决策。 因此,以下是用于协调的简单策略:
假设x t是提议的协调中的标记。 在时间步骤t,如果音符对应于旋律,则x t等于给定的音符。 否则,根据模型的预测,x t等于最可能出现的下一个音符。 可以在Feynman Lyang GitHub网站上找到用于这种模型调整的代码: HarmModel.lua , harmonize.lua 。
以下是使用上述策略使摇篮曲Twinkle,Twinkle,Little Star与BachBot协调一致的示例。
 BachBot(在女高音部分)协调Twinkle,Twinkle,Little Star的摇篮曲。 中提琴,中音和低音的部分也充满了BachBot
BachBot(在女高音部分)协调Twinkle,Twinkle,Little Star的摇篮曲。 中提琴,中音和低音的部分也充满了BachBot在此示例中,女高音部分给出了催眠曲“闪烁”,“闪烁”,“小星星”的旋律。 此后,使用BachBot使用协调策略填充中提琴,中音和低音的部分。
这就是听起来 。
尽管BachBot在执行此任务方面表现出良好的性能,但是与该模型相关联的某些限制。 更准确地说,该算法
不会期待旋律,而仅使用旋律的当前音符和过去的上下文来生成后续音符。 当人们调和旋律时,它们可以覆盖整个旋律,从而简化了适当调和的推导。 该模型无法执行此操作的事实可能会由于限制使用后续信息(导致错误)而导致
意外 。 为了解决这个问题,可以使用所谓的
波束搜索 。
使用波束搜索时,将检查各种运动线。 例如,可以考虑使用四个或五个最可能的注释,而不是仅使用当前正在执行的最可能的注释,然后再使用这些注释中的每一个继续工作。 检查各种选项可以帮助模型
从错误中恢复 。 光束搜索通常用于自然语言处理应用程序中以创建句子。
现在,可以通过这种协调模型传递借助情感调制的旋律以完成它们。