
一年多以前,我们
审查了
Splunk机器学习工具包应用程序,您可以使用该应用程序使用各种机器学习算法在Splunk平台上分析机器数据。
今天我们要谈谈过去一年中出现的那些更新。 已经发布了许多新版本,添加了各种算法和可视化效果,从而可以将Splunk中的数据分析提高到一个新的水平。
新算法
在讨论算法之前,应该注意,有一个
ML-SPL API ,您可以使用它加载300多种Python算法的任何开源算法。 但是,为此,您需要能够在某种程度上使用Python进行编程。
因此,我们将注意那些以前仅在处理Python之后才可用的算法,但现在已嵌入到应用程序中,并且每个人都可以轻松使用。
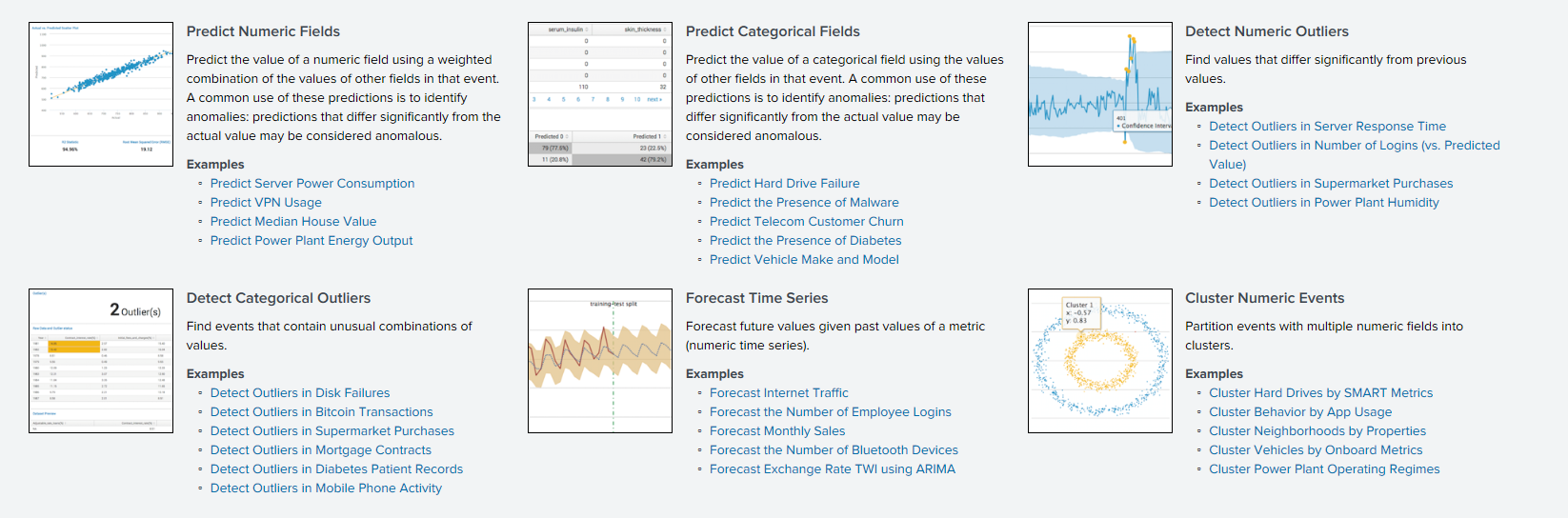 ACF (自相关功能)
ACF (自相关功能)自相关函数通过时移量显示函数及其移位副本之间的关系。 ACF可帮助您找到重复的部分或确定信号的频率,这些信号由于重叠的噪声和其他频率的振动而被隐藏。
PACF (部分自相关函数)私有自相关函数显示两个变量之间的相关性,减去所有内部自相关值的影响。 特定滞后的私有自相关与普通自相关相似,但其计算不包括滞后较小的自相关的影响。 实际上,私有自相关提供了周期性依赖关系的“清晰”图景。
ARIMA (自回归和移动平均的集成过程)ARIMA模型是用于建立短期预测的最受欢迎的模型之一。 自回归值表示时间序列当前值对先前值的依赖关系,模型的移动平均值确定先前预测误差(也称为白噪声)对当前值的影响。
 梯度提升分类器和梯度提升回归器
梯度提升分类器和梯度提升回归器梯度提升是一种用于回归和分类问题的机器学习方法,它以一组弱模型(通常为决策树)的形式创建预测模型。 当每个后续算法试图补偿所有先前算法组成的缺点时,他会分阶段构建模型。 最初,在工作中出现了增强的概念,即是否有可能有很多不好的(与随机定义稍有不同)学习算法来获得好的算法。 在过去的十年中,与神经网络一起,提升一直是最流行的机器学习方法之一。 主要原因是简单性,多功能性,灵活性(构建各种修改的能力),最重要的是高泛化能力。
X均值X均值聚类算法是一种高级的k均值算法,可根据贝叶斯信息准则(BIC)自动确定聚类数。 当没有关于可将该数据划分为的簇数的初步信息时,使用此算法很方便。
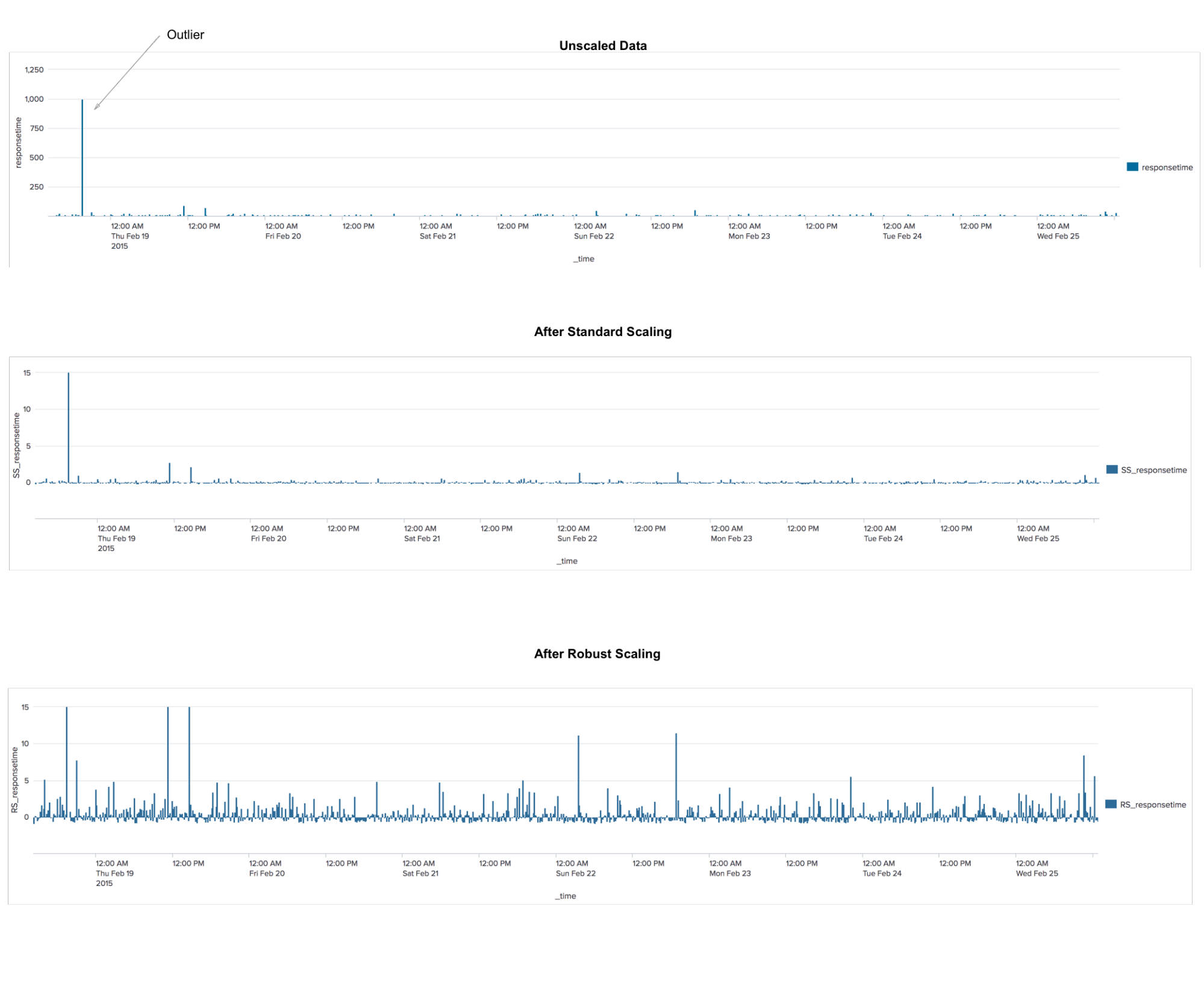
稳健的缩放器这是一种数据预处理算法。 该应用程序类似于StandardScaler算法,该算法对数据进行转换,以使每个特征的平均值为0,方差为1,导致所有特征具有相同的标度。 但是,此缩放不能保证接收到任何特定的最小和最大值属性。 RobustScaler与StandardScaler相似之处在于,由于其应用,这些功能将具有相同的比例。 但是,RobustScaler使用中位数和四分位数代替均值和方差。 这使RobustScaler可以忽略离群值或测量误差,这对于其他缩放方法可能是个问题。
 外国金融发展基金会
外国金融发展基金会一种统计量度,用于评估作为文档集合一部分的文档上下文中单词的重要性。 原理是这样的:如果一个单词经常在文档中找到,而很少在所有其他文档中找到,那么这个单词对文档本身非常重要。
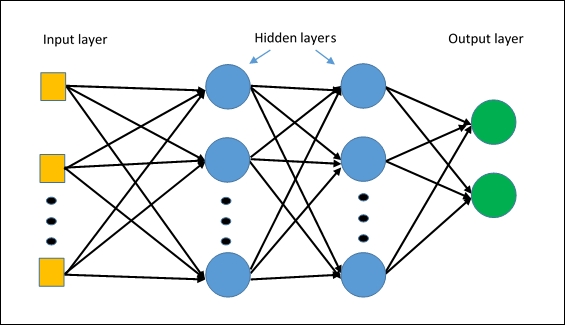
MLP分类器Splunk中的第一个神经网络算法。 该算法基于
多层感知器构建,该
感知器将捕获数据中的非线性关系。
行政管理
在新版本中,应用程序的管理已发生重大变化。
首先,添加了
访问各种模型和实验的
角色模型 。
其次,引入了用于
管理模型的新界面。 现在,您可以轻松查看所拥有模型的类型,检查每个模型的设置(例如,用于训练模型的变量),以及查看或更新每个模型的共享设置。
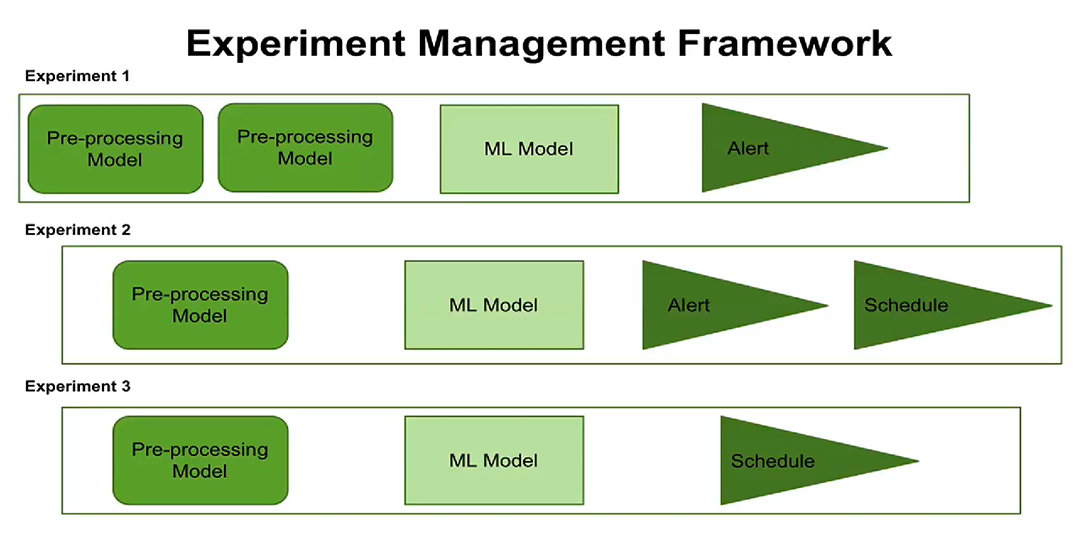
第三,实验管理概念的出现。 现在,您可以按计划配置
实验的执行 ,配置警报。 用户可以查看何时计划运行每个实验,为每个实验配置了哪些处理步骤和参数。
实验管理的新概念现在使您有机会一次创建和管理多个实验,记录执行这些实验的时间以及获得的结果。
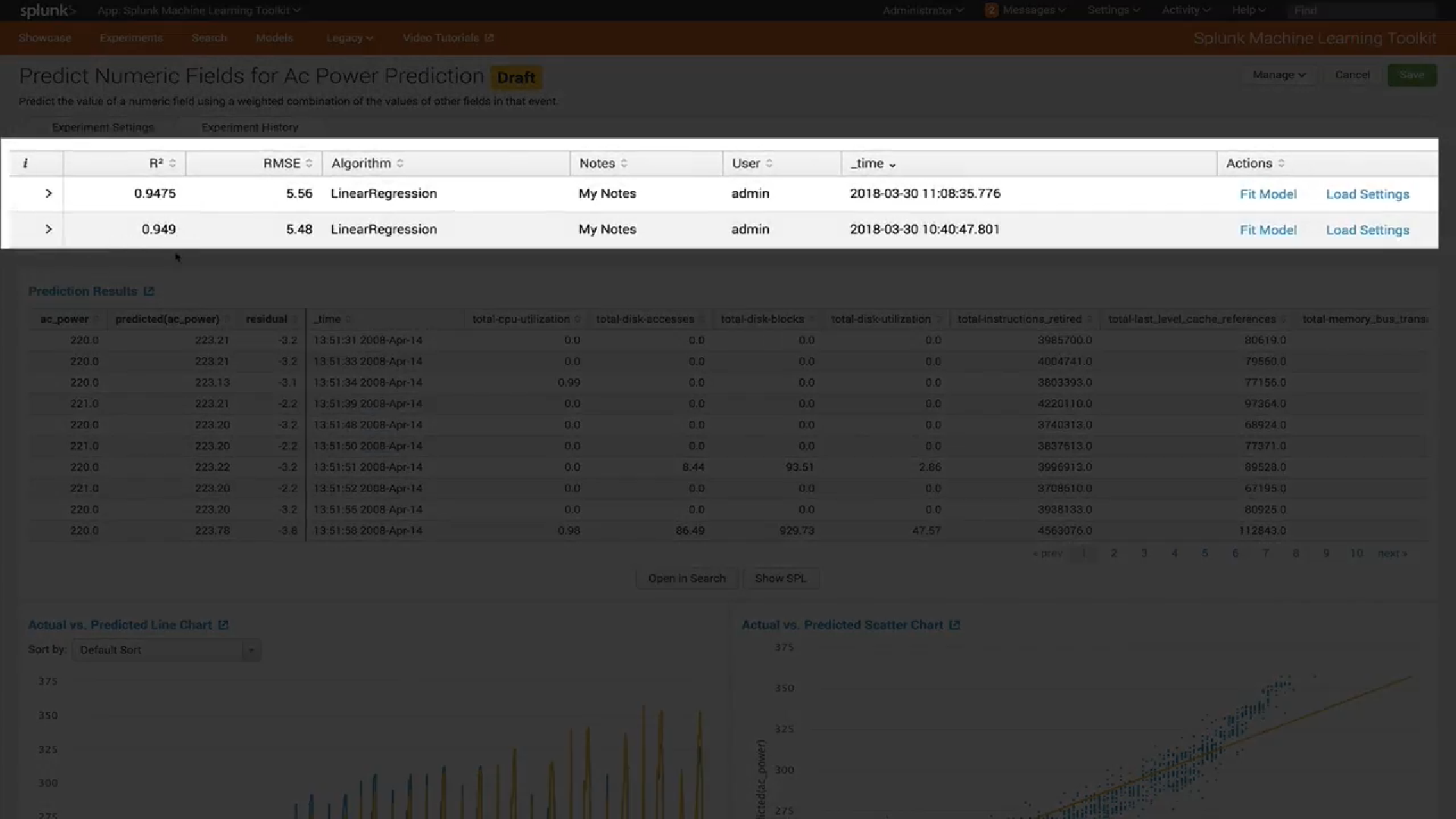
可视化
在最新版本的MLTK 3.4中,添加了一种新型的可视化。 著名的
Box Plot,或者我们也称其为“留着胡须的盒子”。
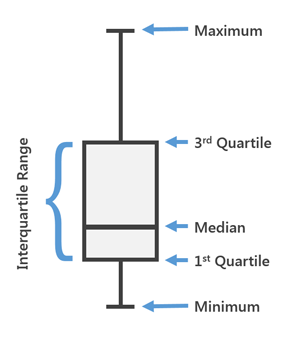
箱形图用于描述性统计,使用它您可以方便地查看中位数(或(如有必要,平均值)),下四分位数和上四分位数,样本的最小和最大值以及异常值。 这些框中的几个可以并排绘制,以直观地比较一种分布。 框的不同部分之间的距离使您可以确定数据的分散程度(分散)和不对称性,并确定异常值。
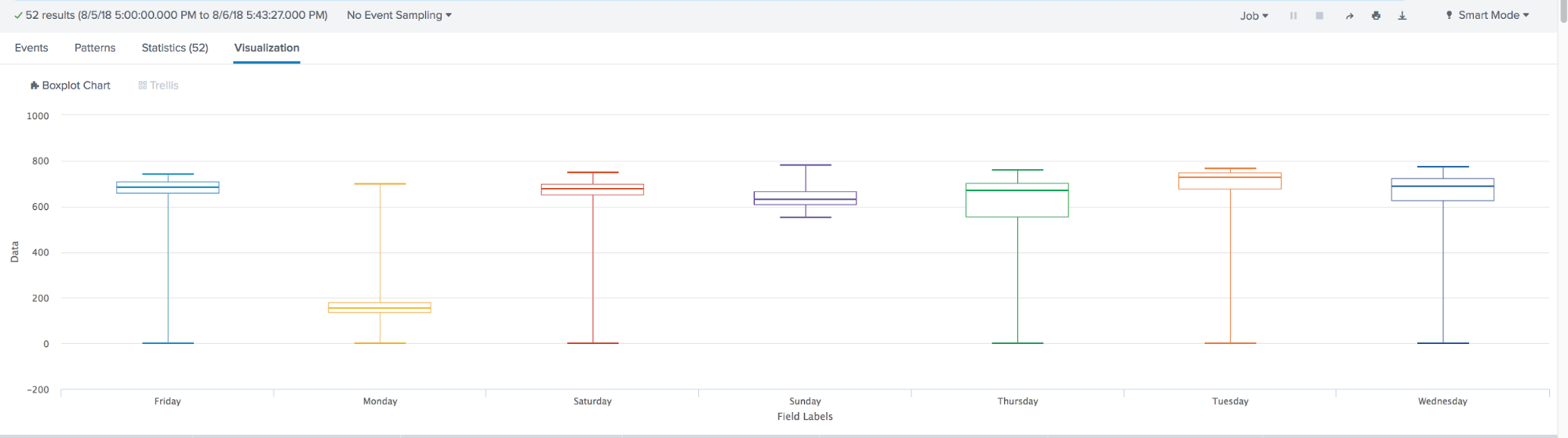
总结起来,一年来,Splunk的机器学习向前迈了一大步。 出现:
- 许多新的内置算法,例如:ACF,PACF,ARIMA,Gradient BoostingClassifier,Gradient Boosting Regressor,X-means,RobustScaler,TFIDF,MLPClassifier;
- 基于角色的访问模型以及管理模型和实验的能力;
- 可视化箱图
