ClickHouse开发团队负责人Alexey Milovidov的这份报告概述了一些著名的DBMS。 其中有些已经过时,有些已经停止了发展而被放弃了。 Alexey在列出的示例中吸引了人们关注有趣的体系结构解决方案,了解了它们的命运,并解释了您的开源项目应满足的要求。
-我的报告将关于数据库。 我马上问你,这张幻灯片上显示了哪个地铁图? 所有行都采用一种方式。
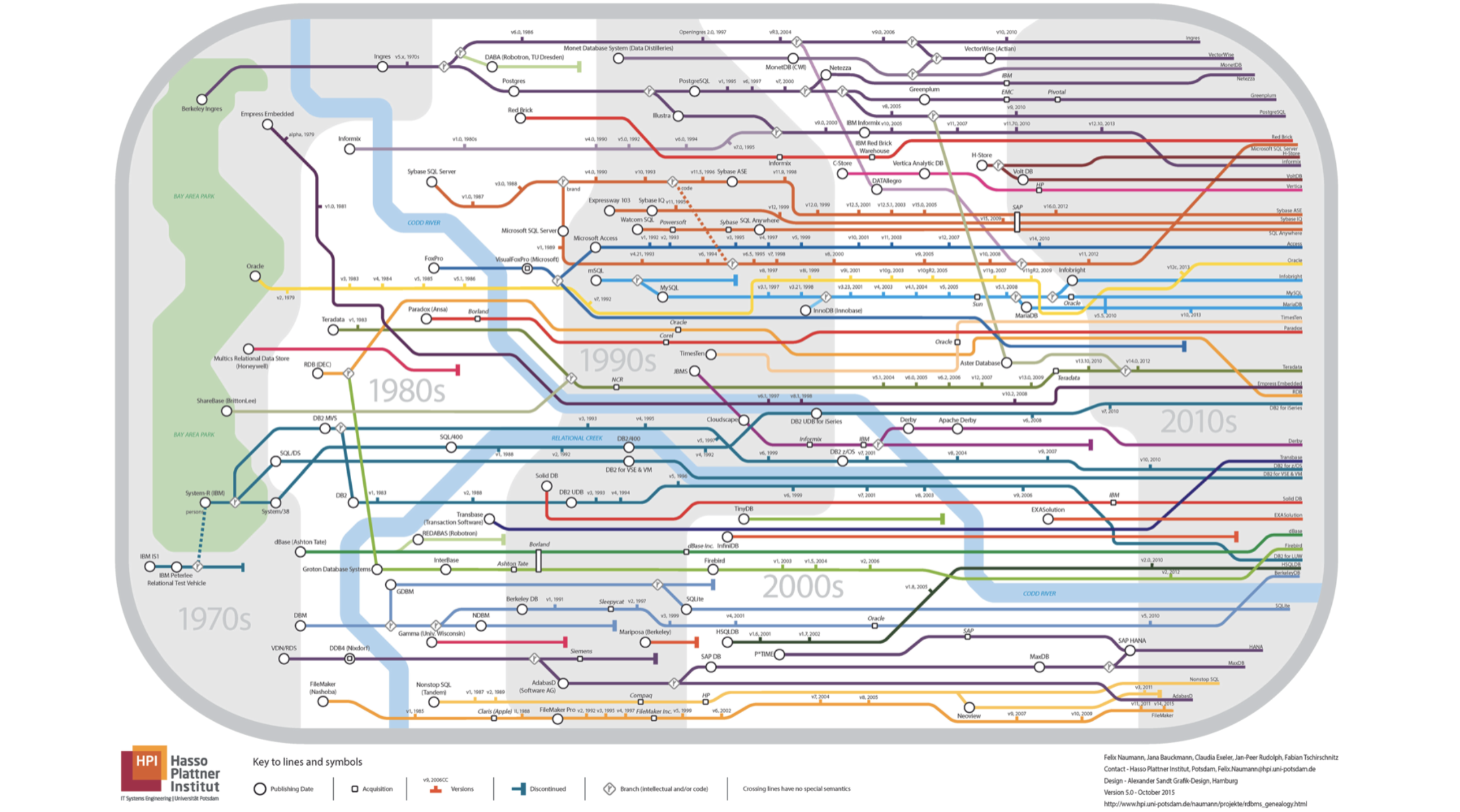
一切都错了,这根本不是地下的,它是关系数据库的血统书。 如果仔细观察,您会发现这条河就是
科达河。
我不会谈论它们。 没有什么比谈论MySQL,PostgreSQL或类似的东西更无聊了? 相反,我将讨论制作数据库。

手动组装。 几乎没人知道的系统。 它们不是由一个人设计的,就是被长期遗弃的。

第一个示例是EventQL。 如果您听说过此系统,请举手。 除了在Yandex中工作并且已经听完我的报告的人以外,没有一个人。 因此,将这个系统包括在我的评论中并没有白费。

这是专为事件处理和分析而设计的分布式列数据库引擎。 它执行非常快速的SQL查询,自2016年7月26日开放源代码,用C ++编写,ZooKeeper用于协调,除此之外没有任何依赖关系。 它让我想起了什么。 我们出色的系统,每个人都已经知道这个名字。 EventQL类似于ClickHouse,但是更好。 分布式,大规模并行,面向列,可扩展至PB,快速范围请求-一切都很清楚,我们拥有了一切。 几乎完全支持SQL 2009,实时插入和更新,跨集群自动分配数据,甚至还有用于描述图形的ChartSQL语言。 太棒了! 这就是我们向所有人保证的和我们所没有的。
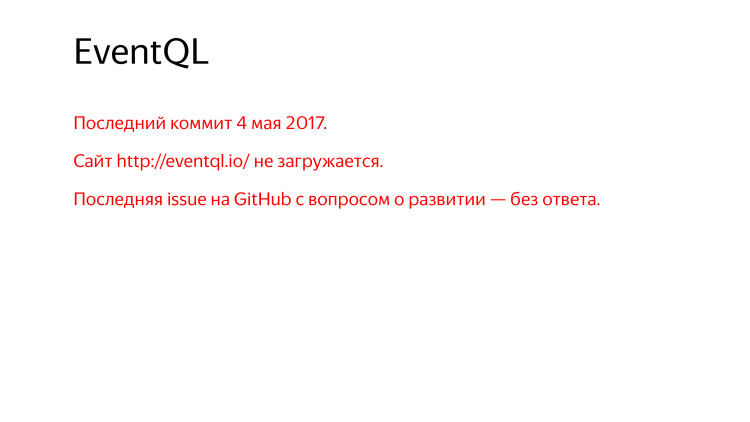
但是,大约在一年前的最后一次提交中,有一个未加载的网站,您必须通过web.archive.org进行监视。
在GitHub上询问-您的开发计划是什么,接下来会发生什么? 没有人回答。
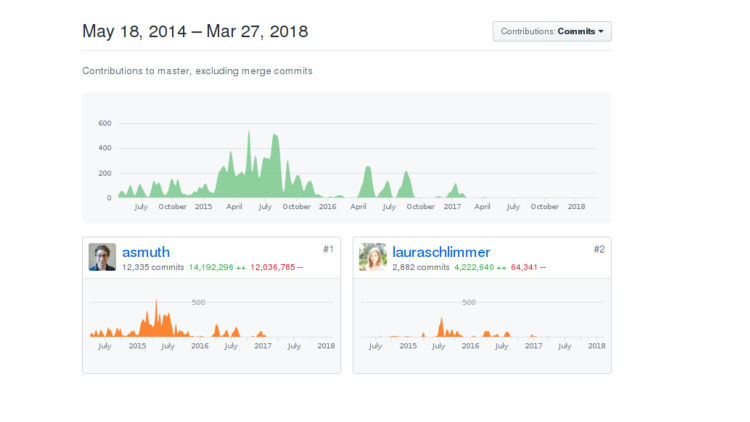
该系统有两个开发人员。 一个是后端开发人员,第二个是前端开发人员。 我不会向他们展示谁可能会为自己猜测。 由DeepCortex制造。 这个名字看起来很熟悉,但是有很多公司使用Deep和词Cortex一词。 DeepCortex是柏林的一家知名公司。 该系统从2014年开始开发,内部开发了很长时间,然后发布到开源中,一年后被废弃。

看起来像这样:他们把她扔向空中,想了想,突然有人注意到她,或者她会飞到某个地方。 不幸的是,没有。
另一个缺点是AGPL许可证,这相对不方便。 即使它对您的公司使用没有严格限制,但仍然经常有人担心,法律部门可能对此有一些反对意见。
我开始寻找发生了什么,为什么它没有被开发。 我查看了开发者的帐户,原则上一切都很好,这个人住了,继续提交,但是所有提交到私有存储库。 目前还不清楚发生了什么。

该人搬到另一家公司并失去了对支持的兴趣,或者公司的优先级发生了变化,或者出现了一些生活状况。 也许公司本身并不感到很糟糕,所以开源是为了以防万一。 或者只是累了。 我不知道确切的答案。 如果有人知道,请告诉我。

但是所有这一切都没有白费。 首先,ChartSQL用于图表的声明性描述。 现在,在用于ClickHouse的Tabix数据可视化系统中使用了类似的方法。 EventQL有一个博客,但是,当前不可用,您必须浏览web.archive.org,其中有.txt文件。 该系统非常熟练地实施,如果您有兴趣,可以阅读代码并查看有趣的体系结构解决方案。
现在只剩下她了。 下一个系统将赢得所有人的青睐,我会考虑,因为它有最好,最美味的名字。 Alenka系统。
我想添加一张巧克力包装的照片,但恐怕会出现版权问题。 什么是阿伦卡?

这是一个分析型DBMS,它在图形加速器上执行查询。 Openors,Apache 2许可,1103星,用CUDA编写,有点C ++,来自Minsk。 甚至还有一个JDBC驱动程序。 自2012年起开始营业。 但是,自2016年以来,由于某种原因该系统不再开发。

这是一个私人项目,不是公司的财产,而是一个人的项目。 这是一个研究原型,旨在探索如何在GPU上快速处理数据的可能性。 Mark Litvinchik提供了一些有趣的测试,如果有兴趣,您可以看一下博客。 可能许多人已经在那里看到了他对ClickHouse最快的测试。

我没有答案,为什么会放弃该系统,只是猜测。 现在一个人为nVidia工作,这可能只是一个巧合。

这是一个很好的例子,因为它增加了人们的兴趣和视野,您可以看到并了解如何做到这一点,以及系统如何在GPU上工作。
但是,如果您对此主题感兴趣,还有很多其他选择。 例如,MapD系统。
谁听说过MapD? 得罪了。 这是一家大胆的创业公司,还在开发GPU数据库。 最近根据Apache 2许可以开源形式发布,我不知道它是干什么的,反之亦然。 该启动非常成功,以开源形式进行布局,反之亦然,将很快关闭。
有一个PGStorm。 如果您精通PostgreSQL,那么您应该了解PGStorm。 也是开源的,由一个人开发。 在封闭系统中,有BrytlytDB,Kinetica和生产商业智能系统的俄罗斯公司Polymatic。 分析,可视化等等。 对于数据处理,它也可以使用图形加速器,这可能很有趣。

有可能做比GPU更酷的事情吗? 例如,有一个系统在FPGA上处理数据。 这是踢火。 她随软件一起以铁的形式交付了自己的解决方案。 没错,该公司很久以前就关闭了,这种解决方案非常昂贵,并且当某些供应商将这种机柜带给您时,该解决方案无法与其他此类机柜竞争,并且一切运行都神奇。
此外,有些处理器包含用于加速SQL的指令-在新的SPARC处理器模型中,Silicon中的SQL。 但是您不必认为您是在Assembler中编写联接的,它并不存在。 有一些简单的指令可以使用一些简单的算法和一些过滤来进行解压缩。 原则上,它不仅可以加速SQL。 例如,英特尔处理器具有一组用于处理字符串的SSE 4.2指令。 当它出现在2008年的某个时候时,英特尔网站上有一篇文章,标题为“使用新的英特尔处理器指令来加速XML处理”。 这里差不多。 也可以使用对加速数据库有用的说明。
另一个非常有趣的选择是将部分过滤数据的任务转移到SSD。 现在,SSD已经变得非常强大,这是一台带有控制器的小型计算机,如果您真的尝试的话,基本上可以将代码上传到其中。 您的数据将从SSD读取,但会立即进行过滤,仅将必要的数据传输到您的程序。 非常酷,但所有这些仍处于研究阶段。 这是有关VLDB的文章,请阅读。
此外,还有一个ViyaDB。

它是在一个月前打开的。 “未排序数据的分析数据库。” 为什么在名称中加上“ unsorted”,尚不清楚为什么要强调。 什么,在只有排序数据库的其他数据库中,您可以工作吗?
一切都很好,GitHub上的源代码,Apache 2.0许可,用最现代的C ++编写的一切都很好。 一个开发人员,但是什么也没有。

举个例子,我最喜欢的就是出色的发布准备。 因此,令我惊讶的是没有人听到。 有一个很棒的网站,有文档,有一篇关于Habré的文章,有一篇有关Medium,LinkedIn和Hacker News的文章。 那又怎样 这一切都是徒劳的吗? 您还没有看过任何一个。 他们在这里说,哈伯不是蛋糕。 好吧,也许吧,但是很棒。
这个系统是什么样的?

数据在RAM中,系统正在处理聚合数据。 预聚合正在进行中。 分析查询系统。 最初有一些SQL支持,但是它才刚刚开始开发,最初必须使用某种JSON编写查询。 在有趣的功能中,您向它发出请求,然后将C ++代码编写到您的请求本身中,该代码会生成,编译,动态加载并处理您的数据。 您的请求将如何得到最佳处理。 理想的是专门为您的要求编写的C ++代码。 有伸缩性,并且Consul用于协调。 如您所知,这也是一个优点,它比ZooKeeper凉爽。 还是不行 我不确定,但好像是。
该系统所基于的一些前提有些矛盾。 我是各种技术的狂热爱好者,所以我不想骂任何人。 这只是我的意见,也许我错了。
前提是为了不断地将新数据记录到系统中,包括追溯到一个小时前,一天前,一个星期前的事件。 同时,立即对这些数据运行分析查询。

作者声称,为此,系统必须在内存中。 事实并非如此。 如果您对为什么感兴趣,可以阅读文章“ Yandex.Metrica中数据结构的演变”。 房间里有一个人在读书。
不必将数据存储在RAM中。 如果您有兴趣解决此问题,我不会说需要做什么以及要安装什么系统。

你能学到什么? 一个有趣的体系结构解决方案是C ++中的代码生成。 如果您对此主题感兴趣,可以关注这样的研究项目DBToaster。 EPFL Institute Research,可在GitHub,Apache 2.0上找到。 Scala代码,您在此处进行SQL查询,此代码为您生成C ++源,它将以最佳方式从某处读取和处理数据。 可能,但不确定。

这只是用于代码生成和查询处理的一种方法。 还有一种更流行的方法-LLVM代码生成。 最重要的是,程序实际上是在Assembler中动态编写代码。 好吧,不是真的,在LLVM上。 以MemSQL为例。 这最初是OLTP数据库,但也非常适合分析。 封闭的,专有的C ++最初是在此处用于代码生成的。 然后他们切换到LLVM。 怎么了 您编写了C ++代码,必须对其进行编译,并且这花费了宝贵的五秒钟时间。 而且,如果您的请求大致相同,则只需生成一次代码即可。 但是,当涉及到分析时,您那里有一些临时请求,而且很有可能每次它们不仅不同,甚至结构也不同。 如果代码生成是在LLVM上进行的,则需要花费毫秒或数十毫秒的时间,不同的是,有时甚至更长。
另一个示例是Impala。 也使用LLVM。 但是,如果我们谈论ClickHouse,则那里也有代码生成,但是ClickHouse主要依赖矢量请求处理。 解释器,但是可以在数组上使用,因此它非常快地运行,就像kdb +这样的系统。
另一个有趣的例子。 我评论中最好的徽标。

第一个也是唯一的关系型开源数据库管理系统,专门为数据仓库和商业智能而设计。 GitHub上有Apache 2许可证,该许可证曾经是GPL,但已更改并正确完成。 它是用Java编写的。 最近一次提交是六年前。 最初,该系统是由非营利组织Eigenbase开发的,该组织的目标是开发一个框架,该框架是数据库的最大可扩展代码库,不仅是OLTP,而且是例如用于分析的LucidDB本身,以及另一个用于处理流数据的StreamBase。

六年前发生了什么? 良好的体系结构,可扩展的代码库,多个开发人员。 很棒的文档。 现在什么都没有加载,但是您可以通过WebArchive看到它。 强大的SQL支持。

但是出了点问题。 这个主意很好,但这是由一个非营利组织捐赠的一些钱,附近有两家创业公司。 由于某种原因,一切都弯曲了。 他们找不到融资,没有热心者,所有这些初创公司很久以前就关闭了。
但不是那么简单。 所有这些都没有白费。

有这样的框架-Apache Calcite。 它是SQL数据库的一种前端,可以解析查询,分析,执行各种优化转换,制定查询执行计划,并提供现成的JDBC驱动程序。
想象一下,您突然醒来,心情很好,就决定开发关系型DBMS。 你永远不知道,它发生了。 现在您可以使用Apache Calcite,您只需要添加数据存储,读取数据,查询处理,复制,容错,分片,一切都很简单。 Apache Calcite基于LucidDB代码库,它是一个如此先进的系统,他们从那里获取了整个前端,现在,它以某种改编的形式用于几乎所有的Apache,Hive,Drill,Samza,Storm产品,甚至MapD,尽管事实它是用C ++编写的,因此以Java方式连接了此代码。

所有这些有趣的系统都使用Apache Calcite。
下一个系统是InfiniDB。 从这些名字头昏眼花。

有Calpont,最初是InfiniDB专有系统,因此销售经理联系了我们公司并向我们出售了该系统。 参与其中很有趣。 他们说,一个分析性的DBMS,比Hadoop更快,比面向对象的列更快,而且自然而然,所有查询都将快速运行。 但是后来他们没有集群,系统也没有扩展。 我说没有集群-我们无法购买。 我看,在发布InfiniDB 4.0版本半年后,我们添加了与Hadoop的集成,可扩展性,一切都很好。
六个月过去了,源代码可在开源中获得。 然后我以为我坐在那里,正在开发一些东西,我们必须接受它,已经准备好了一些东西。
他们开始研究如何适应,使用。 一年后,该公司破产了。 但是源代码可用。
这称为事后开源。 那很好。 如果某家公司感觉不佳,则必须至少保留一些遗产,以便其他人可以使用它。

一切都是徒劳的。 基于InfiniDB源,MariaDB现在具有一个名为ColumnStore的表引擎。 实际上,这就是InfiniDB。 公司不再存在,人们现在在其他地方工作,但是遗产仍然存在,这真是太好了。 每个人都了解MariaDB。 如果使用它,并且需要快速固定面向列的分析引擎,则可以使用ColumnStore。 秘密地说,这不是最佳解决方案。 如果您需要最好的解决方案,那么您会知道该去哪里和使用什么。
名称中包含单词Infini的另一个系统。 他们有一个奇怪的徽标,这条线似乎弯了下来。 还有另一种难以理解的字体,由于某种原因没有抗锯齿,就好像在Paint中绘制一样。 而且所有信件都很大,可能会吓倒竞争对手。

我是各种技术的爱好者,非常尊重各种有趣的解决方案。 我不是在开玩笑,无需思考。
这个系统是什么样的? 这不再是分析系统,而是OLTP。 一种用于处理超大规模交易的系统。 有一个站点,此系统的优点是该站点正在加载。 因为当我查看所有其他内容时,我已经习惯了域名停放之类的事情。 可用资源。 现在是GPL。 它曾经是AGPL,但幸运的是,作者很快对其进行了更改。 用C ++编写的多个开发人员于2013年11月发布到开源,并于2014年1月被放弃。 一个半月。 怎么了 有什么意义? 为什么这样

具有初始SQL支持的OLTP数据库,这是一个个人项目,没有公司支持。 Hackers News的作者本人说,他在开源上发布文章,希望吸引将从事此产品工作的爱好者。

这种希望永远注定要失败。 你有一个主意,你很棒,你是一个狂热者。 所以你必须做这个主意。 其他人不太可能会因此受到启发。 否则,您将不得不努力激励他人。 因此,很难指望在世界的另一端会出现一个人,他会开始在GitHub上添加其他人的代码。
其次,也许只是低估了复杂性。 DBMS开发并不是20分钟的冒险。 这是困难的,长期的,昂贵的。
这是一个非常有趣的案例,许多人都听说过RethinkDB。 该示例不是分析基础,不是OLTP,而是面向文档的示例。

该系统已多次更改其概念。 重新考虑。 假设在2011年,有报道说这是MySQL的引擎,在SSD上的速度是其官方网站上写的速度的一百倍。 据说这是一个具有memcached协议的系统,也针对SSD进行了优化。 不久之后,它成为了实时应用程序的数据库。 也就是说,为了订阅数据并直接实时接收更新。 假设各种互动聊天,在线游戏。 试图找到一个利基市场。
面向文档的系统,JSON数据模型。在这方面,该系统经常与MongoDB进行比较。虽然这是不公平的。表现良好的开发人员如何看待MongoDB?MongoDB必须死。这些不是我的话,我不希望任何人受到伤害,正如PostgreSQL Professional的Oleg所说。总体而言,此类开发人员如何看待?Mongo-他们做错了所有事情。他们无法正确实现共识协议,甚至系统也无法很好地应对保存数据的任务。似乎在具有此更好功能的新版本中,它并不是特别早。RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . 怎么了 ?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
可靠的母公司支持。没有任何评论。没有限制性的许可证,这样其他公司就不会吓到法律部门,这些人什么都不怕。系统的好处应该来自根本原因。说,如果您有一个用于XML处理的数据库,这在某种程度上不是很好。也许没有人需要用XML存储数据。如果您有一个面向文档的数据库,那就是另一个。每个人都需要保存文档,无论是什么。另外,对社区发展的支持对于良好的开源非常重要。这不仅意味着您需要保留请求请求。这意味着-您需要人们感觉自己存在,回答问题,产品正在开发。这将成为一个良好而生动的开源。就这样,谢谢。