几个月前,在一项回顾展中,我们决定尝试一起阅读。
我们的格式:
- 选择一本书。
- 我们确定一周内需要阅读的部分。 选择小音量。
- 在星期五,我们讨论阅读的内容。
- 我们在非工作时间阅读,在工作时间进行讨论。
- 读完本书后,我们共同选择以下内容。
有什么好处:
- 读书动机和阅读能力。
- 技能发展(包括未来)。
- 团队中思维方式和术语的统一。
- 信心的增长。
- 说话的另一个原因。
我们最近阅读的书籍之一是《
设计数据密集型应用程序》 。 是的,那本有猪的书。 每个人都非常喜欢这本书,因此我决定在这里进行复习,以便更多的人阅读。
 原始品质的地图
原始品质的地图出版商彼得将这本书翻译成俄文。 但是我们读的是原文,所以我不保证这些术语的翻译会匹配。 而且,我们故意不翻译部分术语。
本书的第一部分致力于数据处理系统的基础。
第一章指出,此类系统的重要属性是可靠性,可伸缩性和易于维护。
第二章介绍各种数据模型。 描述了常用的关系型和面向文档的DBMS,以及鲜为人知的图形和列数据库。
前几章是最新的,确定了本书的范围。 在下面的许多地方,作者引用了第一章。 公平地说,我们可以说这本书充满了交叉引用。
从第一章开始,令人惊讶的是来源的数量(每章后面都有参考书目)。 所有章节都精心安排了数十篇文章(博客和科学文章)和书籍的链接。 一些章节的来源数量超过一百。
第三章从最简单的键值存储的源代码开始:
它甚至可以工作,非常擅长写作,但是,当然,并非没有阅读问题。
立即提供了用于提高性能的选项。 描述哈希索引,SSTable,b树和LSM树。 所有这些都在手指上进行了解释,但是显示了在熟悉的数据库中如何使用这种结构。
专注于实践是本书的另一个标志。 大多数示例和食谱都很实用,以至于我遇到了几乎所有相关内容。
第四章介绍编码:从常规的JSON和XML到Protobuf和AVRO。 我们并不总是有意识地选择格式,它通常是由一种或另一种技术作为整体施加的。 但是了解它在内部的工作原理,格式的优缺点是很酷的。
作者没有专门使用术语序列化,因为该术语在数据库中还有一个含义。
这些章节的内容比我的简短介绍要丰富得多。 第一部分还描述了OLTP和OLAP之间的区别,如何安排全文搜索和列数据库,REST和消息代理中的搜索。
本书的第二部分讨论了分布式数据处理系统。 几乎所有已或多或少加载的现代系统都具有多个副本或子系统(微服务)。
当我们第一次开始一起练习阅读时,我们只是讨论了笔记,有趣的地方和想法。 在某个时候,我们意识到我们只是没有足够的对话,在讨论之后,一切很快就被遗忘了。 然后,我们决定加强实践,并增加了思维导图填充。 创新就是这本书。 从第二部分开始,我们开始维护每一章的思维导图 。 因此,每一章都将涉及我们的思维导图。 我们使用了coggle.it
第五章介绍复制。
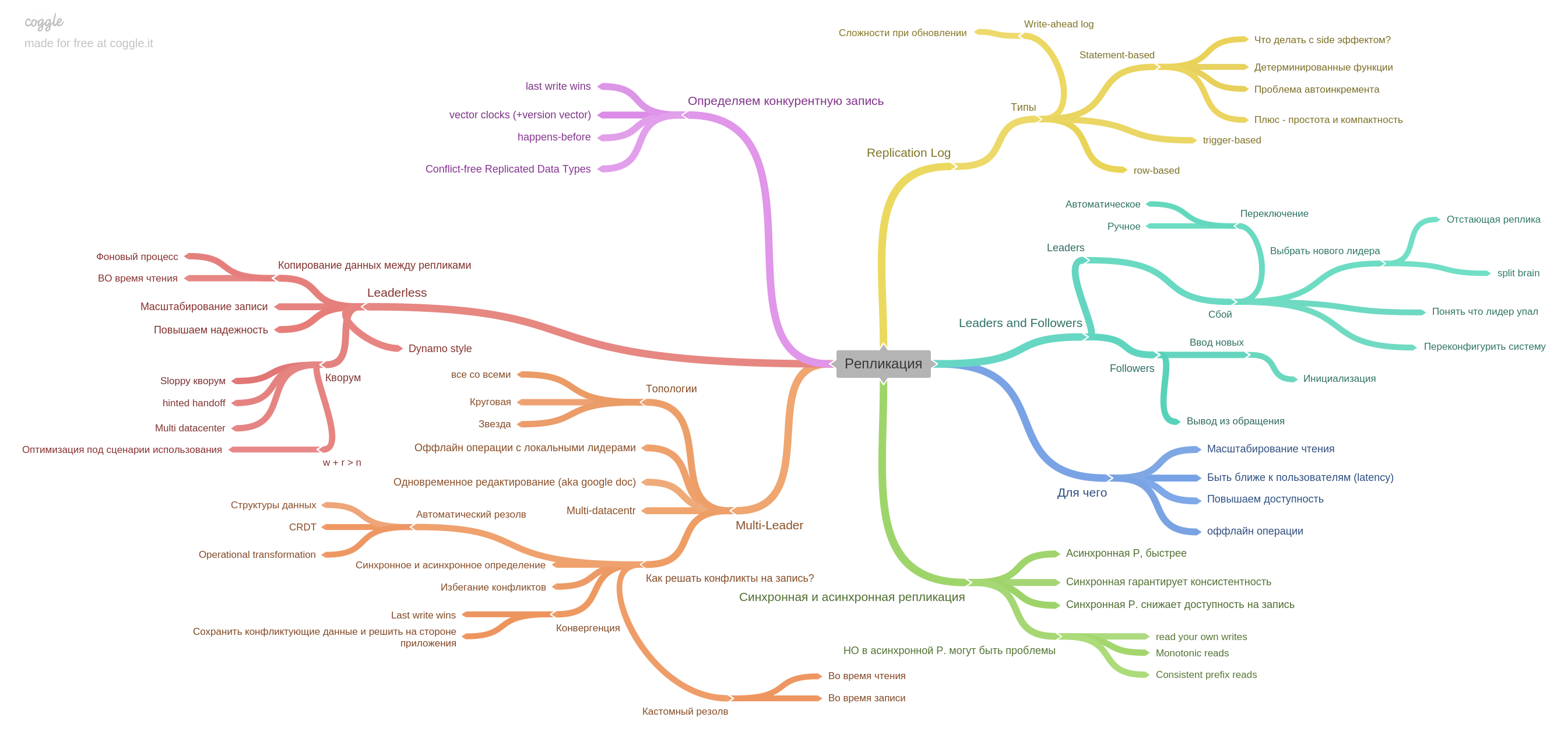
此处收集了有关副本的所有基本信息:单原版,多原版,复制日志以及如何在无领导者系统中保留竞争记录。
第六章介绍了分区(又名分片和其他术语)。
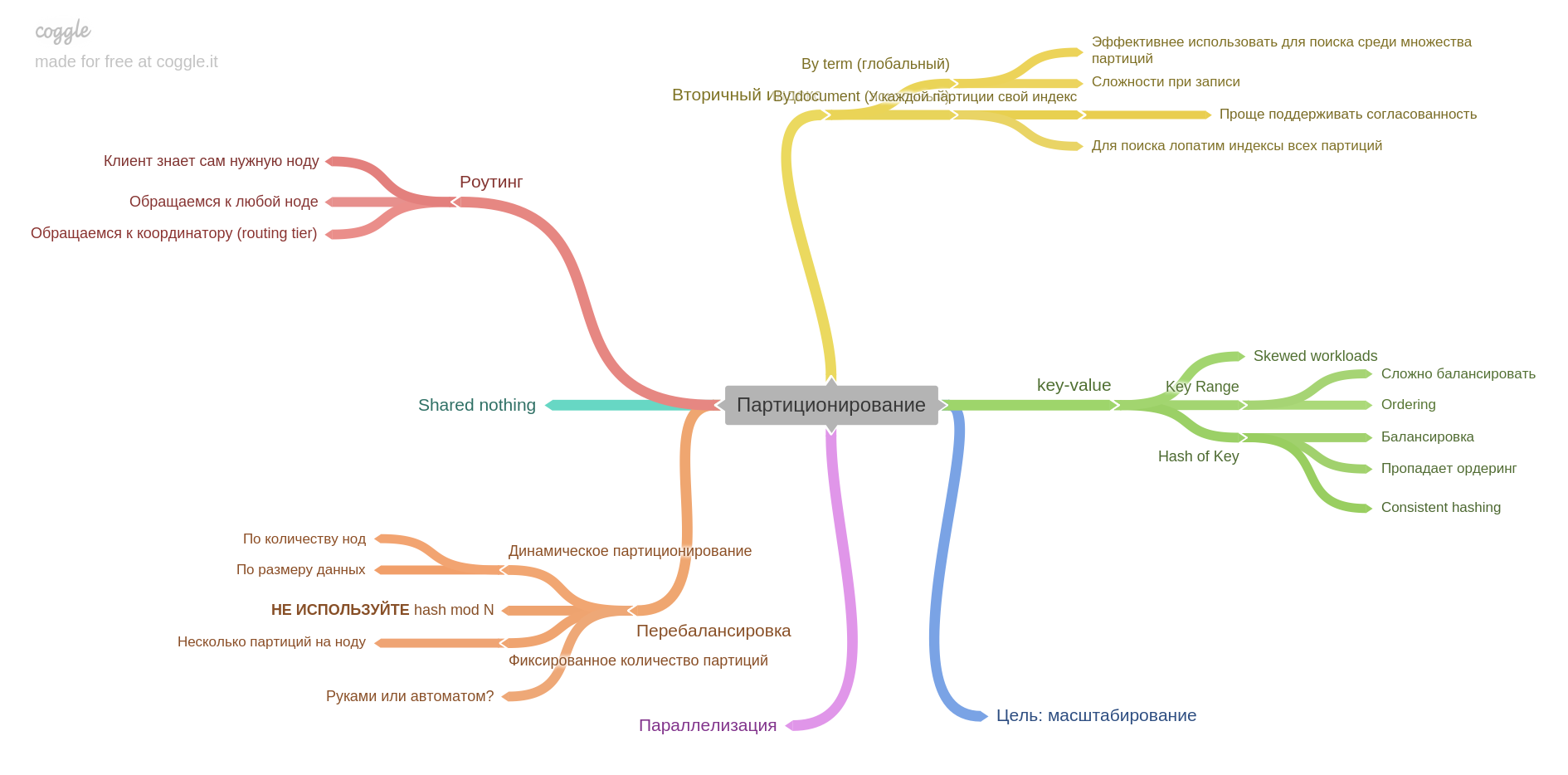
您将学习如何将数据分解为碎片,可以解决哪些问题以及要解决哪些问题,如何建立索引和平衡数据。
第七章 :交易。
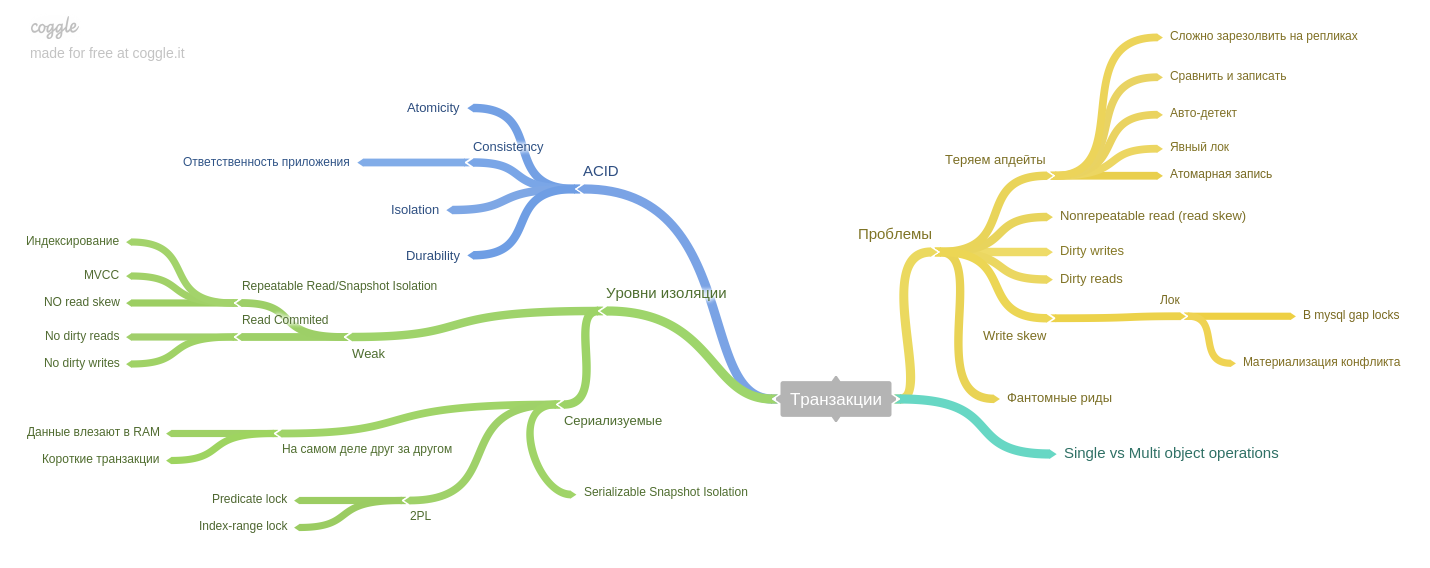
描述了现象(读取偏斜,写入偏斜,幻像读取等),以及ACID样式数据库的隔离级别如何帮助避免问题。
第八章:关于分布式系统特有的问题。
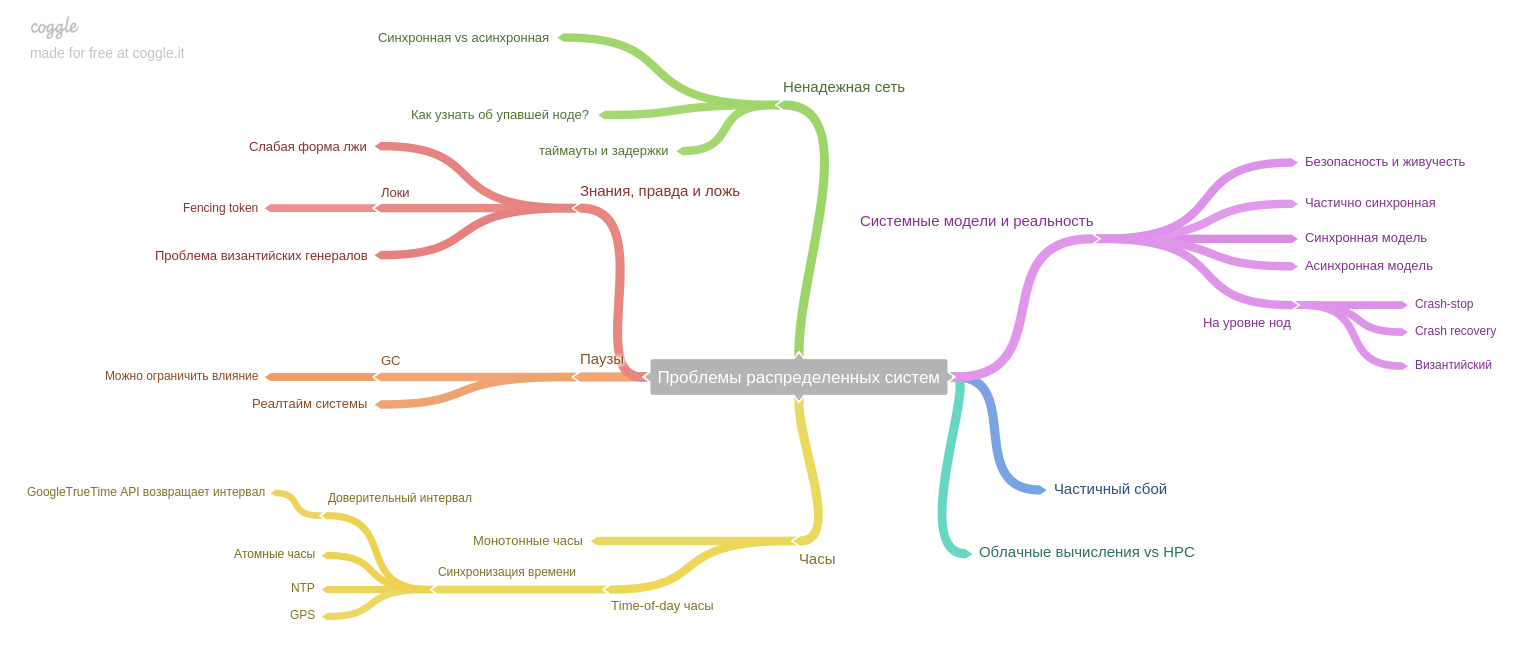
作者强调了一个重要的想法:如果系统较早在一台机器上运行,并且在发生故障的情况下,整个系统就会停止工作(并接受任何新数据)。 因此,故障后的数据保持一致状态,但是今天,在副本和微服务时代,只有部分系统关闭。 因此,我们面临一个新问题:在部分故障,网络不可靠的持续问题等情况下确保数据一致性。
第九章描述了一致性和共识,并介绍了一个重要的概念:线性化。 我记得头很硬而且适合我的头)
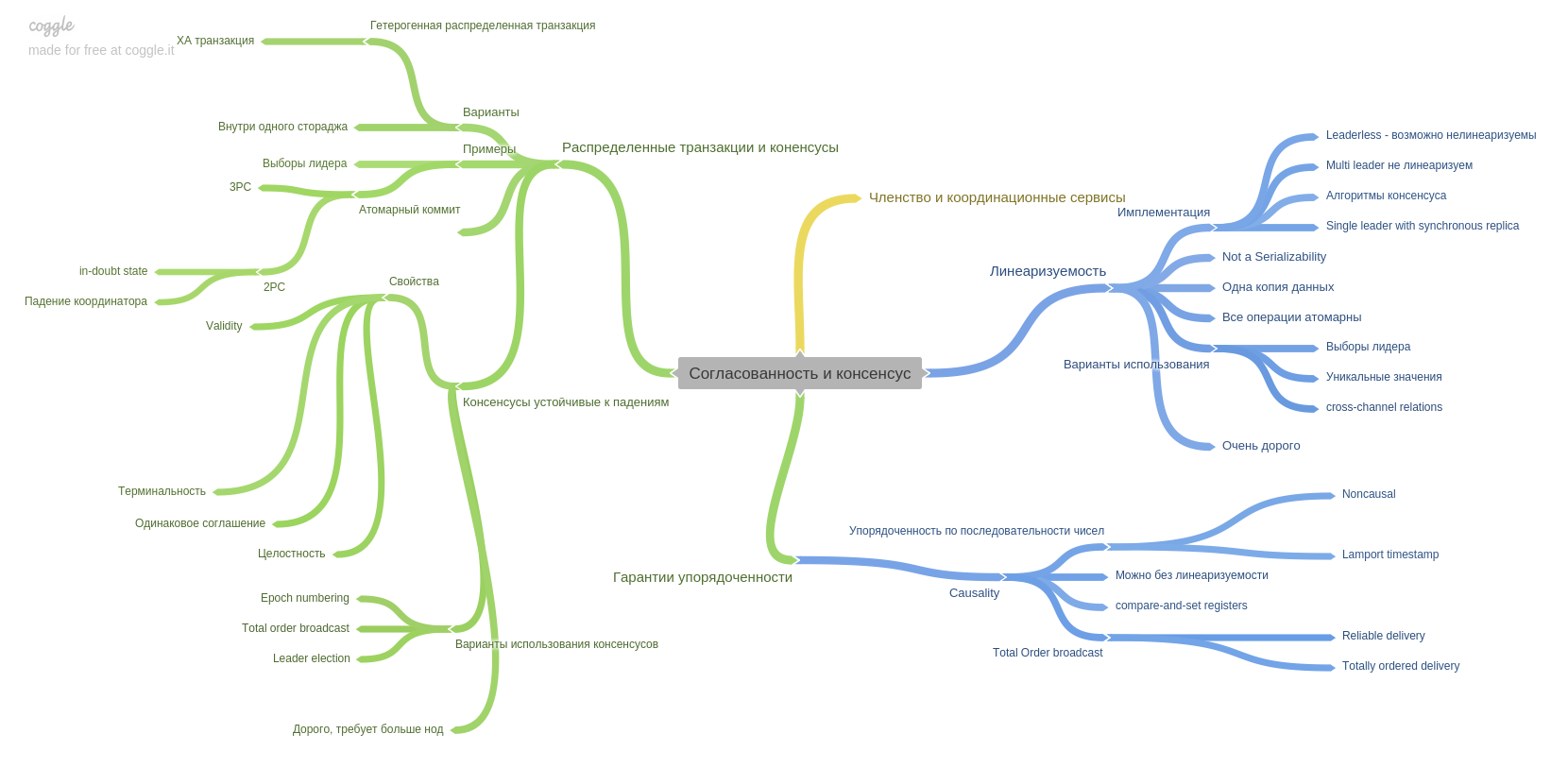
本章还介绍了两阶段提交技术及其缺点。 此外,在本章中,您还将阅读有关有序保证的信息。 现代系统如何以及为您提供什么。
本书的第三部分专门介绍派生数据(没有确定的译文)。 结果,作者提出了一个想法,即所有索引,表,实例化视图都只是日志上的缓存。 仅日志包含最相关的数据,其他所有数据均已延迟,为方便起见。
第十章。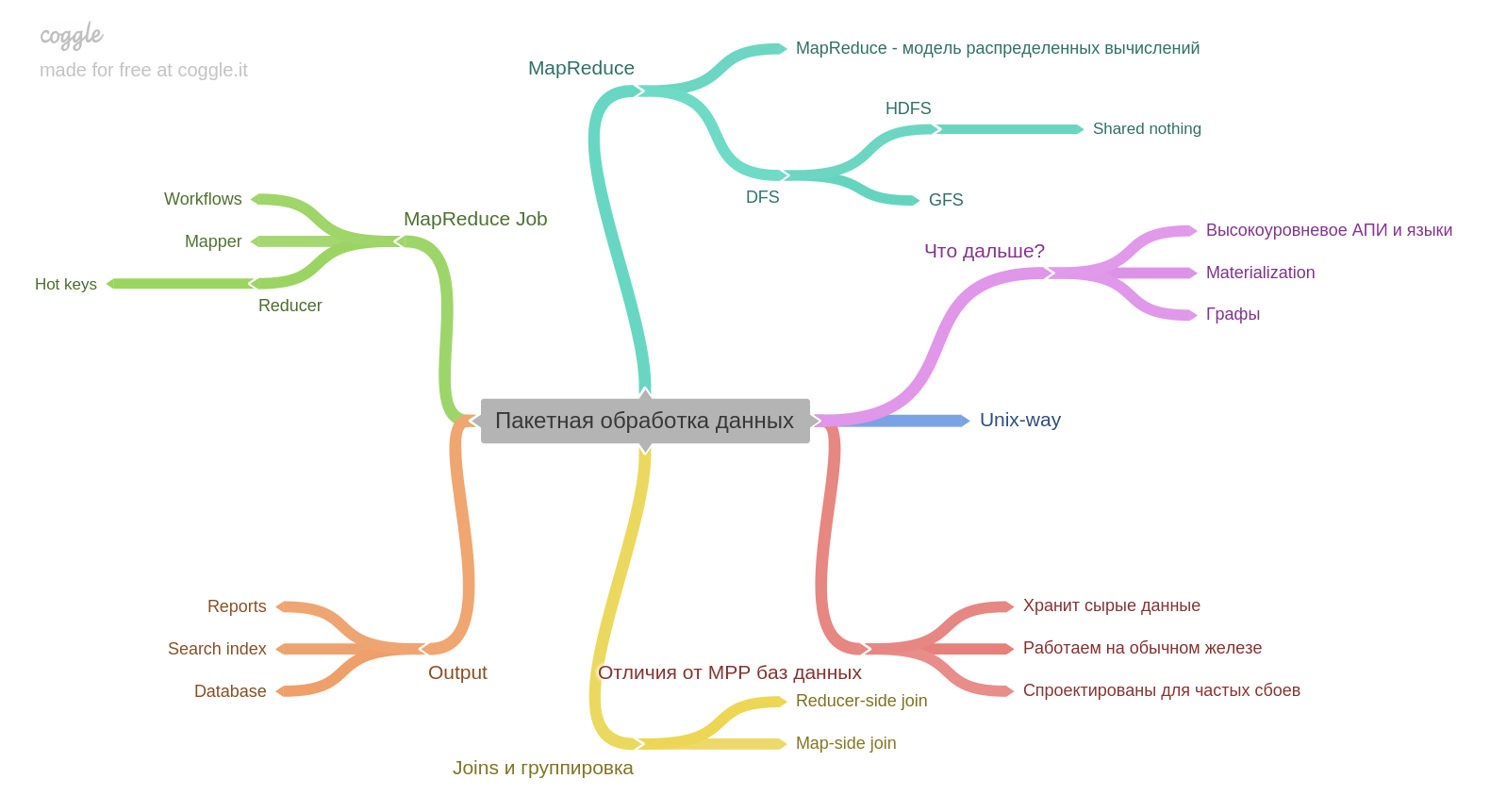
如果您有Hadoop或MapReduce的经验,也许您将学到很少的新知识。 但是我没有工作,这很有趣。 对我来说重要的一点-批处理的结果本身可以成为另一个数据库的基础。
第11章。流数据处理。
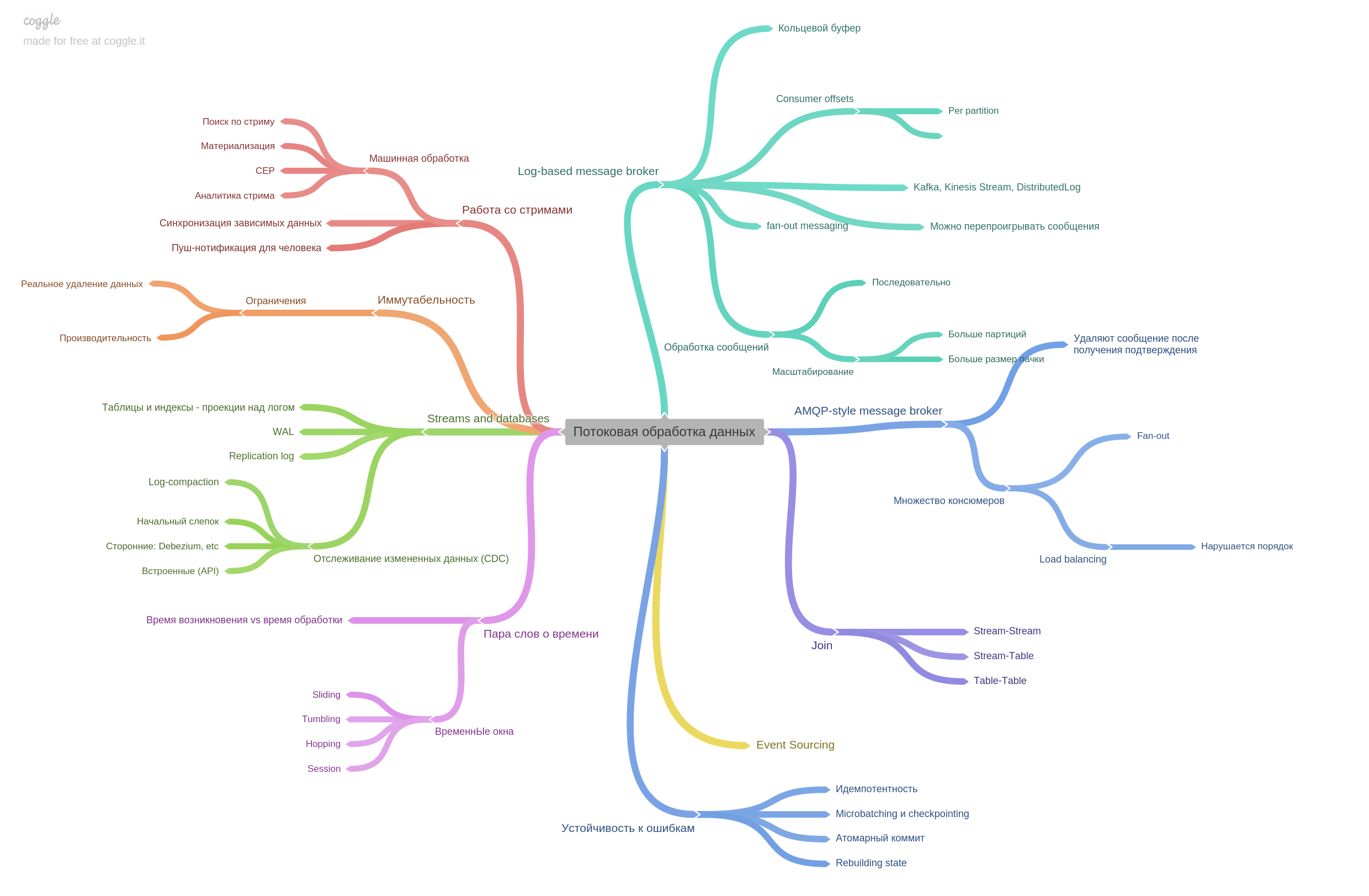
描述了消息代理,以及AMPQ样式与基于日志的样式有何不同。 实际上,本章还包含许多其他信息。 阅读非常有趣。
上一章是关于未来的。 期望什么,研究人员和工程师的想法已经忙碌了。
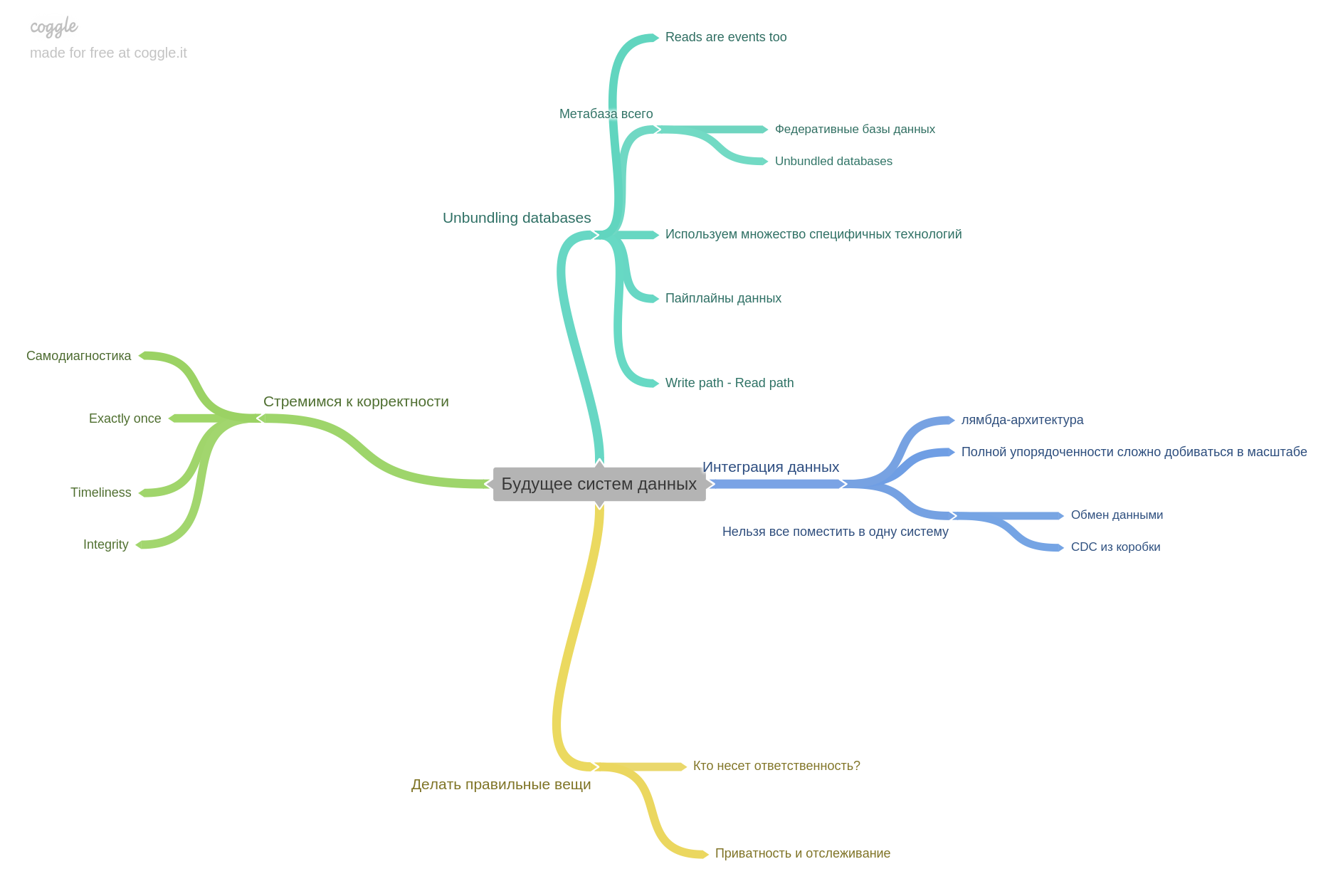
我的评论到此结束。 重要的是要理解,我在每一章中只做部分论文。 这本书内容如此密集,以至于不可能简短地讲述,而是完全重述。
我个人认为这本书是过去几年中最好的技术。 我强烈建议阅读。 不仅要阅读,还要努力。 遵循参考书目中的链接,使用真正的DBMS。
阅读本书之后,您可以在技术数据库访谈中轻松回答许多问题。 但这不是重点。 作为一名开发人员,您会变得更加冷静,您将了解各种数据库的内部结构,优缺点,并思考分布式系统的问题。
我准备在评论中讨论本书本身以及我们一起阅读的习惯。
看书!