 六个月前,我们完成了所有无状态服务到kubernetes的迁移。 乍一看,任务非常简单:您需要部署集群,编写应用程序规范然后运行。 由于对确保服务工作稳定性的痴迷,我不得不立即开始了解k8的工作原理并测试各种故障情况。 我对与网络相关的所有问题都有很多疑问。 其中一些问题是kubernetes中服务的运行。
六个月前,我们完成了所有无状态服务到kubernetes的迁移。 乍一看,任务非常简单:您需要部署集群,编写应用程序规范然后运行。 由于对确保服务工作稳定性的痴迷,我不得不立即开始了解k8的工作原理并测试各种故障情况。 我对与网络相关的所有问题都有很多疑问。 其中一些问题是kubernetes中服务的运行。
该文档告诉我们:
- 推出应用程序
- 设置活动/准备样本
- 创建服务
- 然后一切都会起作用:负载平衡,故障转移等。
但是实际上,一切都有些复杂。 让我们看看它是如何工作的。
一点理论
此外,我的意思是,读者已经熟悉kubernetes设备及其术语;我们只记得什么是服务。
服务是k8的本质,它描述了一组炉床和访问它们的方法。
例如,我们启动了应用程序:
apiVersion: apps/v1 kind: Deployment metadata: name: webapp spec: selector: matchLabels: app: webapp replicas: 2 template: metadata: labels: app: webapp spec: containers: - name: webapp image: defaultxz/webapp command: ["/webapp", "0.0.0.0:80"] ports: - containerPort: 80 readinessProbe: httpGet: {path: /, port: 80} initialDelaySeconds: 1 periodSeconds: 1
$ kubectl get pods -l app=webapp NAME READY STATUS RESTARTS AGE webapp-5d5d96f786-b2jxb 1/1 Running 0 3h webapp-5d5d96f786-rt6j7 1/1 Running 0 3h
现在,要访问它,我们必须创建一个服务,在该服务中我们确定要访问的通道(选择器)以及在哪些端口上:
kind: Service apiVersion: v1 metadata: name: webapp spec: selector: app: webapp ports: - protocol: TCP port: 80 targetPort: 80
$ kubectl get svc webapp NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE webapp ClusterIP 10.97.149.77 <none> 80/TCP 1d
现在,我们可以从群集中的任何计算机访问我们的服务:
curl -i http://10.97.149.77 HTTP/1.1 200 OK Date: Mon, 24 Sep 2018 11:55:14 GMT Content-Length: 2 Content-Type: text/plain; charset=utf-8
一切如何运作
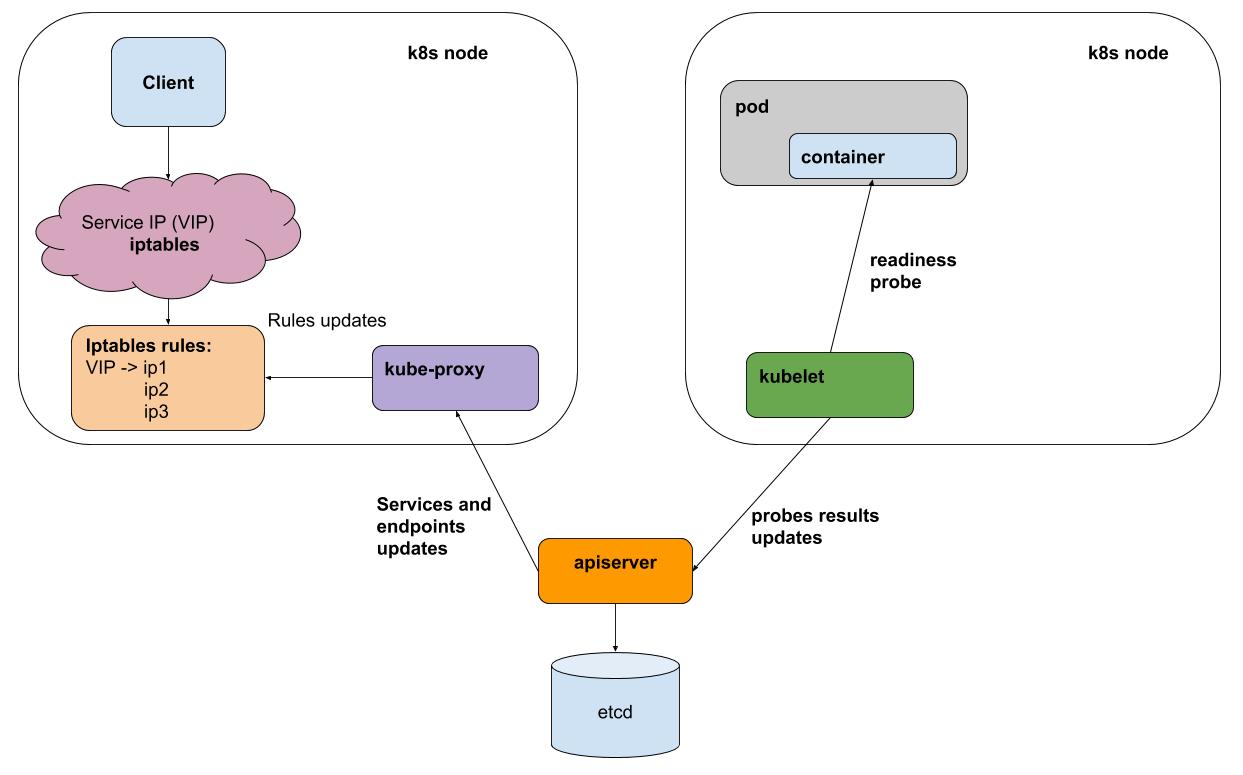
非常简化:
- 您是否已将kubectl应用了部署规范
- 魔术发生了,在这种情况下,其细节并不重要
- 结果,该应用程序的工作节点原来位于某些节点上
- 每个kubelet间隔(每个节点上的k8s代理)对在其节点上运行的所有Pod执行活动/就绪状态样本后,会将结果发送到apiserver(与k8s大脑的接口)
- 每个节点上的kube-proxy从apiserver接收有关服务的所有更改以及参与服务的炉床的通知
- kube-proxy反映了基础子系统 (iptables,ipvs)的所有配置更改
为简单起见,请考虑默认的代理方法iptables。 在iptables中,我们的虚拟IP为10.97.149.77:
-A KUBE-SERVICES -d 10.97.149.77/32 -p tcp -m comment --comment "default/webapp: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BL7FHTIPVYJBLWZN
流量流向KUBE-SVC-BL7FHTIPVYJBLWZN链 ,在该链中 ,流量分布在其他2个链之间
-A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-UPKHDYQWGW4MVMBS -A KUBE-SVC-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp:" -j KUBE-SEP-FFCBJRUPEN3YPZQT
这些是我们的豆荚:
-A KUBE-SEP-UPKHDYQWGW4MVMBS -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.10:80 -A KUBE-SEP-FFCBJRUPEN3YPZQT -p tcp -m comment --comment "default/webapp:" -m tcp -j DNAT --to-destination 10.244.0.11:80
测试炉膛之一的故障
我的webapp测试应用程序能够切换到“错误提示”模式,为此,您需要提取“ / err” URL。
测试中间的ab -c 50 -n 20,000结果在其中一个炉膛上拉了“ / err”:
Complete requests: 20000 Failed requests: 3719
这里的要点不是具体的错误数(它们的数目将根据负载而有所不同),而是它们的数目。 通常,我们将“不良”问题置于不平衡状态,但在切换服务的客户端时会收到错误消息。 错误的原因很容易解释:准备就绪测试每秒钟执行一次kubelet +多一点时间来散布有关未回答测试的信息。
IPVS后端对kube-proxy(实验性)有帮助吗?
真的不是! 它解决了代理优化的问题,提供了自定义平衡算法,但没有解决故障处理的问题。
如何成为
此问题只能由可以重试(重试)的平衡器解决。 换句话说,对于http,我们需要一个L7平衡器。 此类kubernetes平衡器已经以入口的形式(暗示为迁移到集群中的一个点,但总体上确实满足其需求)的形式或作为单独层的实现(例如服务网格,例如istio)而得到了充分利用 。
在生产中,由于额外的复杂性,我们尚未开始使用入口或服务网格。 我认为,这种抽象在需要经常配置大量服务的情况下很有帮助。 但是,与此同时,您“付出”了可控性和简单的基础架构。 您将花费额外的时间来弄清楚如何为特定服务设置rettai和超时。
我们如何
我们使用无头k8s服务。 此类服务没有虚拟ip,因此kube-proxy和iptables不参与其工作。 对于每种此类服务,您都可以通过DNS或API获取实时炉床列表。
对于与其他服务交互的应用程序,我们使用envoy制作一个sidecar容器。 Evoy会通过DNS定期接收所有必要服务的Pod的最新列表,最重要的是,如果出现错误,它可以反复尝试查询其他Pod。 您可以在每个节点上将其作为DaemonSet运行,但是如果此实例失败,则使用该实例的所有应用程序都将停止运行。 由于此代理的资源消耗很小,因此我们决定在sidecar容器变体中使用它。
这基本上就是istio所做的事情,但是在我们的案例中,平衡已转向简单性(无需学习istio,无需遇到bug)。 也许这种平衡会改变,我们将开始使用istio之类的东西。
我们okmeter.io kubernetes无疑已经扎根,我们相信它的进一步分发。 我们的服务中正在支持监视k8s,敬请期待!