
对疯狂的恐惧是智人最强大的恐惧症之一。 两百年前,亚历山大·普希金(Alexander Pushkin)写下了他著名的《上帝禁止我迷失方向》。 现在,在进步的二十一世纪,几乎没有什么改变,我们仍然害怕获得性精神障碍。 例如,在俄罗斯,痴呆症比癌症和中风更使人恐惧:45%的受访者称其为老年最可怕的疾病(Health Mail.ru门户上的
调查数据)。
幸运的是,今天的医学在痴呆症方面的努力比普希金时代要成功得多。 通过早期诊断,可以预防人格衰退并保留认知能力。 最近,大阪大学开发了一个程序,用于基于人工智能的痴呆早期诊断。 该项目使用了机器学习算法和在与病人和健康人一起工作过程中获得的数据; 诊断准确性为93%。
什么是痴呆症,如何识别
让我们从定义开始。 痴呆症-获得性痴呆症,认知活动持续下降,缺乏知识和实践技能,难以或不可能获得新的痴呆症。 它是由于脑部损害而发生的,大多数情况下是在老年时。 痴呆伴有阿尔茨海默氏病(占病例的60%),血压正常的脑积水,颅内肿瘤和脓肿。
要“目视”识别痴呆症并不容易:即使亲密的人也可能多年没有注意到一个人出了什么问题。 当他们发现亲戚在去商店的途中忘记了自己的名字或迷路时,大脑的变化已经太过分了。
这种“失明”主要是由于我们社会中的痴呆症受到污名化,人们对此一无所知。 疾病的一个特征也起作用:变化逐渐发生。
但是,医生能够在早期识别痴呆症。 为此,对患者进行心理检查(最著名的一项是韦克斯勒检查),并通过脑脊髓液检查和MRI检查以确认诊断。
“韦克斯勒测验(或韦氏测验)是衡量智力发展水平的最著名测验之一。 由David Wexler在1939年设计。 该测试基于韦克斯勒(D. Wexler)智力的分层模型,并诊断了通用智力及其组成部分-言语和非言语智力。“ 维基百科
现有系统麻烦且不太方便,因为患者需要与神经科医生见面并花费时间通过测试。 如果每年检查所有老年人的痴呆症状,医生的负担将增加数倍。
 世卫组织预测到2050年痴呆症病例将增加三倍
世卫组织预测到2050年痴呆症病例将增加三倍人工智能帮助
大阪大学提出了解决该问题的方案:他们与奈良科学技术学院合作,开发了一个程序,该程序可以对人进行采访并分析他的言语和面部表情。 该程序基于人工智能; 他在对健康人和确诊为痴呆症的人进行访谈的基础上进行了研究。 该程序将人分类为“有痴呆症状”或“无痴呆症状”,准确度为93%。 这对应于“模拟”方法中最有效的方法。
如何运作通过针对痴呆症的计算机测试后,老年人与该程序的化身进行了交流-一个动画女孩。 她问在字幕中重复的问题,并“听”答案。 之后,程序通过几个参数分析测试参与者的语音和面部表情并显示结果。
正如来自奈良和大阪的科学家在描述他们工作的
出版物中解释的那样,他们创造了一个“监禁”了老年人的化身:彩绘的女孩说话速度慢,并且在短语停顿之后。 单词在大字幕中重复。 当测试参与者回答时,系统会识别该语句,之后,化身点了点头。 开发者从日本流行的动画程序MikuMikuDance中借用了这项技术:根据用户的说法,这会使角色更加生动。
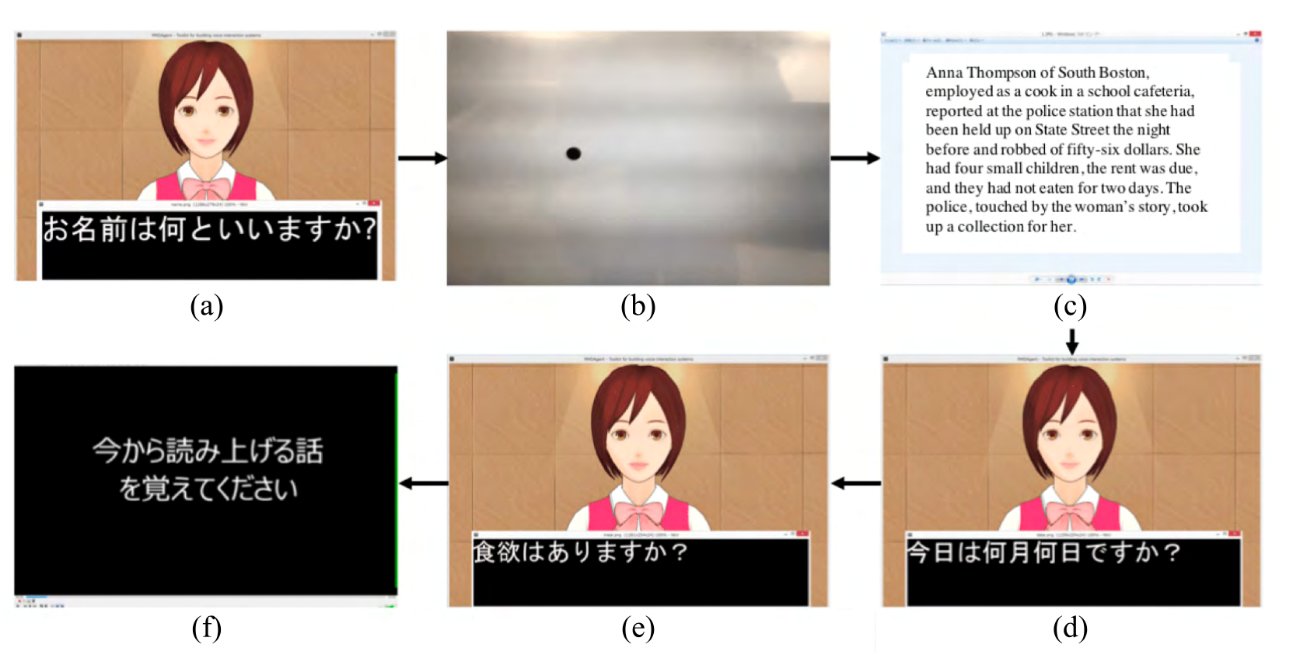 开发的测试包括几种对话和场景:a)患者谈论自己; b)测试他专心的能力; c)阅读; f)讲故事-要求患者回忆一个故事; e)随机问题(例如,“您的食欲如何?”)。
开发的测试包括几种对话和场景:a)患者谈论自己; b)测试他专心的能力; c)阅读; f)讲故事-要求患者回忆一个故事; e)随机问题(例如,“您的食欲如何?”)。测试中有六个模块,它们基于不同的方法。 第一个是介绍性的(简单的问题“您叫什么名字?”和“您几岁?”)。 它向用户介绍了系统,并提供了时间来适应管理。 以下是基于两种评估认知能力的权威方法的功能块:韦克斯勒测试和简要心理状态评估量表(MMSE)。 测试中还包含一些随机的问题和答案(“什么年?”,“你睡得好吗?”,“日本首相是谁?”),在程序的答案中,它分析的信息不多于语音参数。
在这项工作中,科学家依靠对痴呆症患者言语的研究:他们难以理解短语,长时间使用单词,并且活跃词汇量减少。 但是为了分析所有选定参数中的语音,该程序花了很长时间进行机器学习。
工具与方法为收集资料,选择了29名参与者:14名-大阪大学医院确诊为痴呆的患者; 15-没有此诊断的老年人。 他们每个人都听了测试题并回答了。
之后,开发人员将音频文件与视频分离,并使用Audacity应用程序手动转录数据,从而将语音分解为单独的语句。 随后,对材料进行了几个因素分析。
1)语音功能:语音功率,发音速度和声音嘶哑。 这些参数是根据频谱图估算的。 化身的问题与受访者的答案之间的差距也得到了分析。
2)语言的特点。 使用Mecab程序,我们分析了重要单词的数量和“不确定的声音”-“ mmmm”,“ ehhh”。 使用相同单词的频率以及它们与“不确定声音”的关系可以对词汇进行大致评估。
3)图片。 开发人员从描述女性模特的视频中识别出31张幸福面孔和30张中性面孔的样本。 分析了每个脸部的68个特征(眉毛的高度,嘴唇的角,眼睛的宽度等)。 基于这些数据,人工智能学会了确定脸上是否有微笑。
在与受访者的访谈中,该程序针对每个帧确定受访者是否微笑; 收集的统计信息称为“微笑指数”。 患有阿尔茨海默氏症的人往往微笑的频率更高,因此他们会高估该指数。 相反,与其他与痴呆症有关的精神疾病相比,情绪会下降。
还监视了凝视的方向:研究表明,一些痴呆患者不再与对话者保持眼神交流。
为了处理结果,我们使用了带有线性核和逻辑回归的支持向量机算法(SVM,或支持向量法)。 这是一个有效解决任务的二元分类器:将受访者分配给“有痴呆症状”或“无痴呆症状”的人群。
前景展望开发人员计划使该程序适应其他语言和其他民族(她用日语学习)。 还计划改进模块。 首先,根据不是年轻模特的面孔,而是老年人的面孔,获取一个用于分析面部表情的新数据集。 这将提高表达式识别的准确性。 其次,扩大对照组以从各种类型的精神障碍患者那里获得更多数据。 计划该程序不仅将学习确认痴呆症状的存在,而且还将通过外部体征来确定其类型:当医生做出诊断时,这将很重要。
PS在11月,Smile-Expo将在基辅(11月14日)和莫斯科(11月22日)举行两次人工智能大会。
在莫斯科,会议发言人将讨论人工智能,大数据,机器学习,聊天机器人和信息安全; 将比较人工智能和机器人过程自动化(使用程序模拟用户操作)。 会议将主持一个主题为“人工智能与物联网:期望与现实”的讨论小组。
在基辅,会议
的主要目标将是利用人工智能构建有关业务流程自动化的知识。 重点将放在业务流程中的AI实施上:实施的盈利领域,效率计算,项目管理。