大家好!
今天,我将告诉您
hh.ru我们如何考虑实验的手动统计信息。 我们将查看数据的来源,处理方式以及遇到的陷阱。 在本文中,我将分享一种通用的体系结构和方法,其中最少会有真实的脚本和代码。 主要读者是对hh.ru中数据分析基础结构的结构感兴趣的新手分析师。 如果这个主题很有趣-请在评论中写下,我们可以在以下文章中深入研究代码。
您可以在
另一篇文章中了解如何考虑A / B实验的自动指标。

我们分析什么数据以及它们来自何处
我们分析访问日志和我们自己编写的任何自定义日志。
95.108.213.12--[2018年8月13日:04:00:02 +0300] 200“ GET /雇主/ 2574971 HTTP / 1.1” 12012“-”“ Mozilla / 5.0(兼容; YandexBot / 3.0; + http:// /yandex.com/bots)“”-“” gardabani.headhunter.ge“” 0.063“-”“ 1534122002.858”-“” 192.168.2.38:1500“” [0.064]“ {15341220027959c8c01c51a6e01b682f} 200 https 1-” -“--[35827] [0.000 0]
178.23.230.16--[13 / Aug / 2018:04:00:02 +0300] 200“ GET /空缺/ 24266672 HTTP / 1.1” 24229“ hh.ru/vacancy/24007186?query=bmw ”“ Mozilla / 5.0( Macintosh; Intel Mac OS X 10_10_5)AppleWebKit / 603.3.8(KHTML,例如Gecko)版本/ 10.1.2 Safari / 603.3.8“-”“ hh.ru”“ 0.210”“ last_visit = 1534111115966 :: 1534121915966; hhrole =匿名; 地区= 1; tmr_detect = 0%7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558“” 1534122002.859“”-“” 192.168.2.239:1500“” [0.208]“ {1534122002649b7eef2e901d8c9c0469} 200 https 1-”-“--[[35927] [0.001 0]
在我们的体系结构中,每个服务都在本地写入日志,然后通过自行编写的客户端-服务器日志(包括nginx访问日志)收集在中央存储库中(以下称为日志)。 开发人员可以访问此计算机,并可以在必要时手动记录日志。 但是如何在合理的时间内吞噬数百GB的日志呢? 当然,将它们倒入Hadoop!
数据来自hadoop?
Hadoop不仅存储服务日志,还上传prod数据库。 每天在hadoop中,我们上传一些分析所需的表。
服务日志以三种方式进入hadoop。
- 到达额头的方式 -cron在晚上从日志存储中启动,而rsync将原始日志上传到hdfs。
- 这种方式很时髦 -来自服务的日志不仅会倒入公共存储中,而且还会倒入kafka中,在那里flume从中读取它们,进行预处理并将它们保存在hdfs中。
- 该路径是过时的 -在kafka之前的日子里,我们编写了自己的服务,该服务从存储中读取原始日志,从预处理中获取原始日志,然后将其上传到hdfs。
让我们更详细地考虑每种方法。
前额路径
Cron运行常规的bash脚本。
我们记得,在日志存储库中,所有日志都是普通文件的形式,文件夹结构是这样的:/logging/java/2018/08/10/{service_nameasure/*.log
Hadoop将其文件存储在大致相同的文件夹结构中hdfs-raw / banner-versions / year = 2018 / month = 08 / day = 10
我们用作分区的年,月,日。
因此,我们只需要形成正确的路径(第3-4行),然后选择所有必需的日志(第6行),然后使用rsync将它们填充到hadoop中(第8行)即可。
这种方法的优点:缺点:时尚的方式
由于我们使用自写脚本将日志上传到存储库,因此合理地将功能不仅上传到服务器,而且还上传到kafka。
优点- 在线日志(填写kafka时会显示hadoop中的日志)
- 您可以进行预处理
- 它可以很好地负载,您可以上传大型日志
缺点- 困难的设置
- 我必须写代码
- 铸造过程的更多部分
- 对事件进行更复杂的监视和分析
老式的方式
它仅在缺少kafka时才与时尚有所不同。 因此,它继承了先前方法的所有缺点和某些优点。 Java中的一个单独的服务(ustats-uploader)会定期读取必要的文件,对其进行预处理,然后将其上传到hadoop。
优点缺点因此,数据进入了Hadoop并准备进行分析。 让我们停下来一点,记住什么是hadoop,以及为什么可以在其中消耗数百GB数据的速度比常规grep快得多。
Hadoop的
Hadoop是一个分布式数据仓库。 数据不位于任何单独的服务器上,而是分布在多台计算机之间,并且也不存储在一个实例中,而是存储在多个实例中-这样做是为了确保可靠性。 数据处理速度的基础在于与传统数据库相比方法的变化。
对于常规数据库,我们从中提取数据并将其发送给客户端,客户端进行某种分析并将结果返回给分析师。 因此,为了更快地计数,我们需要有很多客户并并行处理请求(例如,按月划分数据-每个客户可以读取其月份的数据)。
在hadoop中,情况恰恰相反。 我们将代码(正是我们要计算的代码)发送到数据,并且此代码在集群上执行。 众所周知,数据存在于许多计算机上,因此每台计算机仅对其数据执行代码并将结果返回给客户端。
许多人可能听说过
map-reduce ,但是编写用于分析的代码不是很方便和快捷,而用SQL编写则要简单得多。 因此,出现了可以将SQL对用户透明地变为map-reduce的服务,并且分析人员可能不会怀疑如何实际考虑他的请求。
在hh.ru中,我们为此使用hive和presto。 Hive是第一个,但是我们正在逐渐转向presto,因为它可以更快地满足我们的要求。 作为GUI,我们使用色相和齐柏林飞艇。
对于我来说,在jupyter中考虑使用python进行分析更为方便,这使我们能够一键式读取并在输出中获取格式正确的excel表,从而节省了大量时间。 写在评论中,本主题将引至另一篇文章。
让我们回到分析本身。
如何理解我们要考虑的?
产品经理承担了计算实验结果的任务
我们发送电子邮件时事通讯,其中我们为申请人发送合适的职位空缺(每个人都喜欢这种邮件吗?)。 我们决定略微改变这封信的设计,并想了解它是否变得更好。 为此,我们将考虑:
让我提醒您,我们所拥有的只是访问日志和数据库。 我们需要根据链接点击次数来制定指标。
从字母到空缺的过渡次数
转换是对
hh.ru/vacancy/26646861的GET请求。 要了解转换的来源,我们添加以下格式的utm标签:Utm_source = email_campaign_123。 对于访问日志中的GET请求,将提供有关参数的信息,我们只能从邮件列表中过滤转换。
过渡后的回应数
在这里,我们可以简单地从新闻通讯中计算出对职位空缺的回复数量,但随后的统计数据将是不正确的,因为除了我们的来信以外,回复可能会受到其他因素的影响,例如,购买了ClickMe中的广告来填补职位空缺,因此回复的数量长大了。
对于如何制定答复数量,我们有两个选择:
- 响应是在hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861上的POST,该POST具有引用hh.ru/vacancy/26646861?utm_source=email_campaign_123 。
- 这种方法的细微之处在于,如果用户切换到一个空缺,然后在站点周围走了一会儿,然后对空缺做出响应,那么我们将不计入该空缺。
- 我们可以记住切换到hh.ru/vacancy/26646861的用户的ID,并根据数据库计算白天的空缺评论数。
方法的选择由业务需求决定,通常第一个选择就足够了,但这完全取决于产品经理正在等待什么。
可能发生的陷阱
- 并非所有数据都在hadoop中,您需要从prod数据库中添加数据。 例如,在日志中通常只包含id,并且如果您需要一个名称-则该名称在数据库中。 有时您需要通过resume_id搜索用户,并且该用户也存储在数据库中。 为此,我们将数据库的一部分卸载到hadoop中,从而使连接更加简单。
- 数据可能是曲线。 对于Hadoop和我们向其中加载数据的方式,这通常是一场灾难。 根据数据的不同,空值可以为null,None,none,空字符串等。每种情况下都需要小心,因为数据实际上是不同的,以不同的方式和不同的用途加载。
- 整个期间的计数很高。 例如,我们需要计算当月的过渡和响应。 这大约是3 TB的日志。 甚至hadoop都会花很长时间。 通常第一次编写100%的工作请求是很困难的,因此我们通过反复试验来编写它。 每次等待20分钟是很长的时间。 解决方法:
- 1天后在日志上调试请求。 由于我们已经在hadoop中对数据进行了分区,因此可以很快地计算出1天的日志记录。
- 将必要的日志上传到临时表。 通常,我们了解我们感兴趣的URL,并且可以为这些URL的日志创建一个临时表。
就个人而言,第一种选择对我来说更方便,但是有时我需要创建一个临时表,这取决于具体情况。 - 最终指标的失真
- 最好过滤日志。 例如,您需要注意响应代码,重定向等。可以肯定的是,数据越少越好,但准确性却更高。
- 度量标准中的中间步骤越少越好。 例如,切换到空缺是一个步骤(GET请求/空缺/ 123)。 响应为两个(转换为空缺+ POST)。 链越短,错误越少,度量标准就越准确。 有时会发生转换之间的数据丢失,并且通常无法计算某些内容的情况。 为了解决这个问题,我们需要在开发实验之前考虑一下要考虑的内容和方法。 单独记录必要的事件有很大帮助。 我们可以拍摄必要的事件,因此事件链将更加准确,并且计数更加容易。
- 漫游器可以产生许多过渡。 您需要了解漫游器可以到达的位置(例如,在需要授权的页面上,而不应该在这些页面上),并过滤该数据。
- 大麻烦-例如,在一个组中可以有一个申请人,这产生了所有响应的50%。 统计信息会出现偏差,此类数据也需要过滤。
- 很难根据访问日志制定要考虑的内容。 这有助于了解代码库,经验和chrome开发工具。 我们从产品中读取了指标的描述,并亲身在站点上进行了重复操作,并查看生成了哪些过渡。
最后,让我们讨论一下计算结果的外观。
计算结果
在我们的示例中,有2个组和2个指标构成一个渠道。
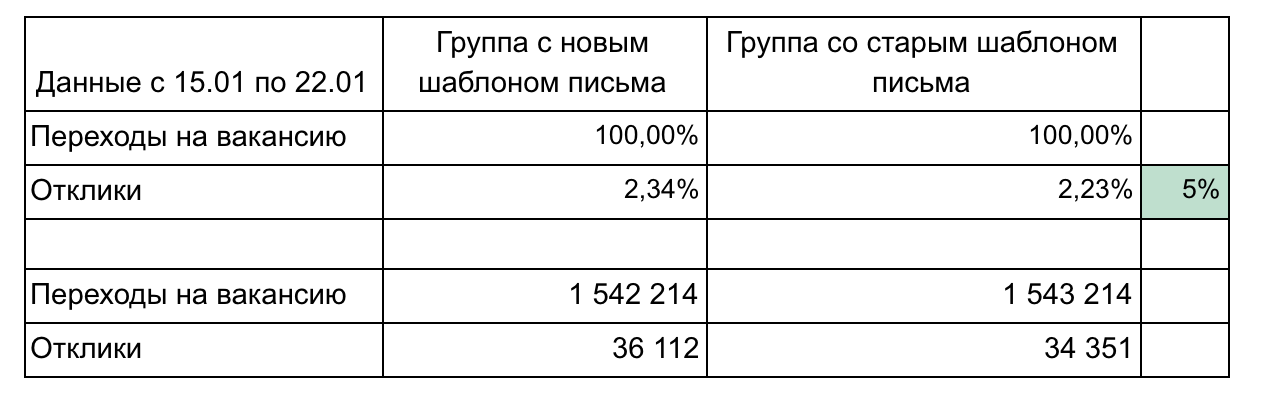
报告结果的建议:
- 除非需要,否则不要使零件过载。 越小越好(例如,在这里我们可以分别显示每个空缺或按天点击)。 专注于一件事。
- 演示结果期间可能需要详细信息,因此请考虑您可能要问的问题并准备详细信息。 (在我们的示例中,详细信息可以根据发送电子邮件后的转换速度-1天,3天,一周,按专业领域对职位空缺进行分组)
- 记住统计意义。 例如,100次点击和15次点击的1%更改是微不足道的,并且可能是随机的。 使用计算器
- 尽可能地自动化,因为您将不得不数数次。 通常在实验过程中,人们已经想了解事情的进展。 实验之后,可能会出现问题,您需要澄清一些问题。 因此,有必要计数3-4次,如果每个计算都是10个查询的序列,然后手动复制到excel,那会很麻烦并且会花费很多时间。 学习python,它将节省大量时间。
- 保证时使用图形表示结果。 内置的蜂巢和齐柏林飞艇工具使您可以直接创建简单的图形。
有必要经常考虑各种指标,因为我们将几乎所有任务发布为A / B实验的一部分。 计算并不复杂,经过2-3次实验后,人们对如何执行此操作有了一个了解。 请记住,访问日志存储了许多有用的信息,这些信息可以为公司省钱,帮助您推广想法并证明哪种更改选项更好。 最主要的是能够获得此信息。