TL; DR :作者从GoFlow , Kafka , ClickHouse , Grafana和Go上的拐杖编译了NetFlow / sFlow收集器。
您好,我是一名开发人员,真的很想知道基础架构中正在发生的事情。 我也喜欢涉足其他人的事务,这次我爬入了网络。
假设您拥有自己的网络设备,以及一袋一堆的单片,微服务和单片微服务,它们以数据库,缓存和FTP服务器的形式依赖于Internet。 有时,这个书包的一些居民开始在网络中调皮。
这里只是这些恶作剧的几个例子:
- 在40个流中在指定窗口之外备份;
- 配置错误将一个DC中的应用程序发送到另一个DC的高速缓存;
- 在下一个机架中将应用程序问题发送到同一缓存“每秒从缓存中给我这个半兆的对象”每秒200次。
来自交换机端口或VM的SNMP计数器将仅大致了解正在发生的事情,但是我希望问题分析的准确性和速度。 NetFlow / IPFIX和sFlow协议可以解决,它们直接从网络设备生成丰富的流量信息。 仍然需要将其放在某个地方并以某种方式进行处理。
在可用的NetFlow收集器中,已考虑以下内容:
- 流程工具-我不喜欢文件存储(选择事件花了很长时间,特别是在对事件做出反应期间进行选择)或MySQL(拥有数十亿行表似乎是一个荒凉的主意);
- Elasticsearch + Logstash + Kibana是非常消耗资源的一堆,最多使用6个2.2 GHz老年CPU内核,每秒可接收5000个流。 但是,Kibana允许您在浏览器中粘贴任何类型的过滤器,这很有价值。
- vflow-不喜欢输出格式(JSON,未经修改,无法将其添加到同一Elasticsearch);
- 盒装解决方案-不喜欢价格高昂或与所选产品相差很小的产品。
并选择了在RIPE 75上的Louis Poinsignon的演示文稿中进行描述。 一个简单的收集器的一般方案如下:
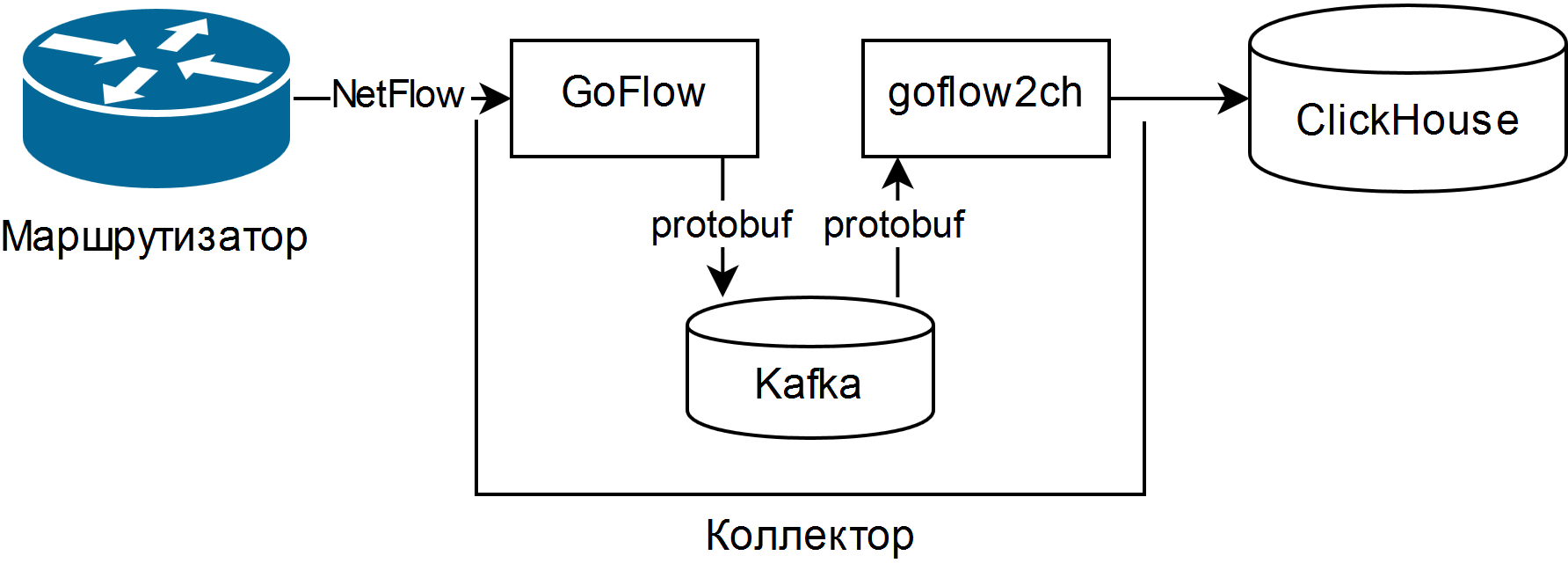
GoFlow解析NetFlow / sFlow数据包,并将其以protobuf格式放入本地Kafka中。 自行编写的“铲” goflow2ch从Kafka获取消息,并将其分批传输到Clickhouse,以提高生产率。 该方案根本没有解决高可用性问题,但是对于每个组件,都有常规的或多或少简单的外部方法来提供它。
测试表明,每秒解析和维护相同的5000个线程的CPU成本约占CPU内核的四分之一,每个略微被截断的流平均消耗11-14字节的磁盘空间。
要显示信息,请使用ClickHouse的Web UI(称为Tabix)或Grafana的插件 。
该方案的优点:
- 能够使用SQL方言询问有关网络状态的任意问题;
- 低资源需求和水平可扩展性。 老式/慢速处理器和磁性硬盘将可用;
- 如有必要,将收集完整的数据管道以分析网络事件,包括使用Kafka Streams,Flink或类似物进行实时分析;
- 能够将存储空间更改为最小数量的能力。
缺点也很体面:
- 要提出问题,您需要非常了解SQL及其ClickHouse的方言;没有现成的报告和图表;
- Kafka,Zookeeper和ClickHouse形式的许多新运动部件。 前两个是Java语言,可能会导致宗教排斥。 对我个人而言,这不是问题,因为所有这些已经在组织中以某种方式使用;
- 必须写代码。 从Kafka到ClickHouse的“铲”传输数据,或从GoFlow直接记录的适配器。
达到的功能:
- 确保根据Kafka和ClickHouse中数据的大小调整旋转角度,然后检查它是否确实有效。 在Kafka中,日志分区的大小受到限制,而在ClickHouse中,按任意键进行分区。 每小时创建一个新分区,每隔10分钟删除一次不必要的分区,可以很好地进行操作监视,并且只需几行就可以创建一个脚本。
- “铲子”受益于消费群体的使用,允许您添加更多的“铲子”以实现规模和容错能力;
- 当“铲子”或ClickHouse崩溃时(例如,来自大量请求和/或错误地有限的资源),Kafka允许您不会丢失数据,但是,最好是仔细配置数据库;
- 如果您将收集sFlow,请记住,默认情况下,某些交换机会随时更改数据包采样率,并针对每个流进行指示。
结果,从开源组件和蓝色电气磁带中获得了一种工具,可用于实时监控网络状况,也可以实时监控历史状况。 尽管他的膝盖很深,但他已经帮助减少了有时解决一些事件的时间。