现代的文本编辑器不仅可以发出提示音,而且不能离开程序。 事实证明,它们内部代谢非常复杂。 想知道正在采取什么技巧来快速重新计算坐标,如何将样式,折叠和软包装附加到文本上以及如何对其进行全部更新,功能数据结构和优先级队列与文本有什么关系以及如何欺骗用户-欢迎来到猫!

本文基于Alexei Kudryavtsev与Joker 2017的
报道 。Alexei在JetBrains中编写Intellij IDEA已有大约10年的时间。 在剪切下,您将找到报告的视频和文本成绩单。
文本编辑器内部的数据结构
要了解编辑器的工作原理,让我们编写它。

就是这样,我们最简单的编辑器已准备就绪。
在编辑器内部,文本最容易存储在Java类StringBuffer中的字符数组中,或者存储相同的字符(就内存组织而言)。 要通过偏移量获取某些字符,我们调用StringBuffer.charAt(i)方法。 为了将在键盘上键入的字符插入其中,我们调用StringBuffer.insert()方法,该方法会将字符插入到中间的某个位置。
尽管此编辑器简单易用,但最有趣的是,您可以发明出最好的主意。 它既简单又几乎总是很快。
不幸的是,此编辑器出现了比例尺问题。 想象一下,我们在其中打印了很多文本,并且打算在中间插入另一个字母。 将会发生以下情况。 我们迫切需要通过将所有其他字母向前移动一个字符来释放该字母的空间。 为此,我们将字母移动一个位置,然后移动下一个位置,依此类推,直到文本的最后。
这是它在内存中的外观:
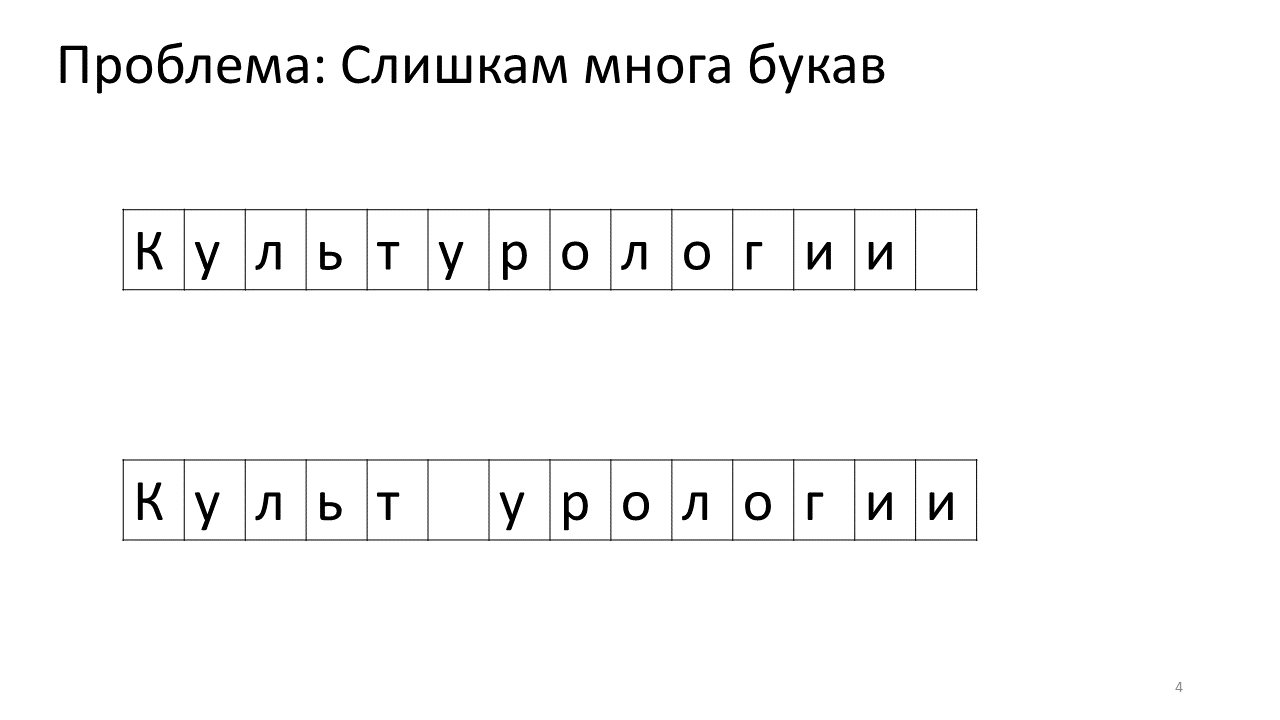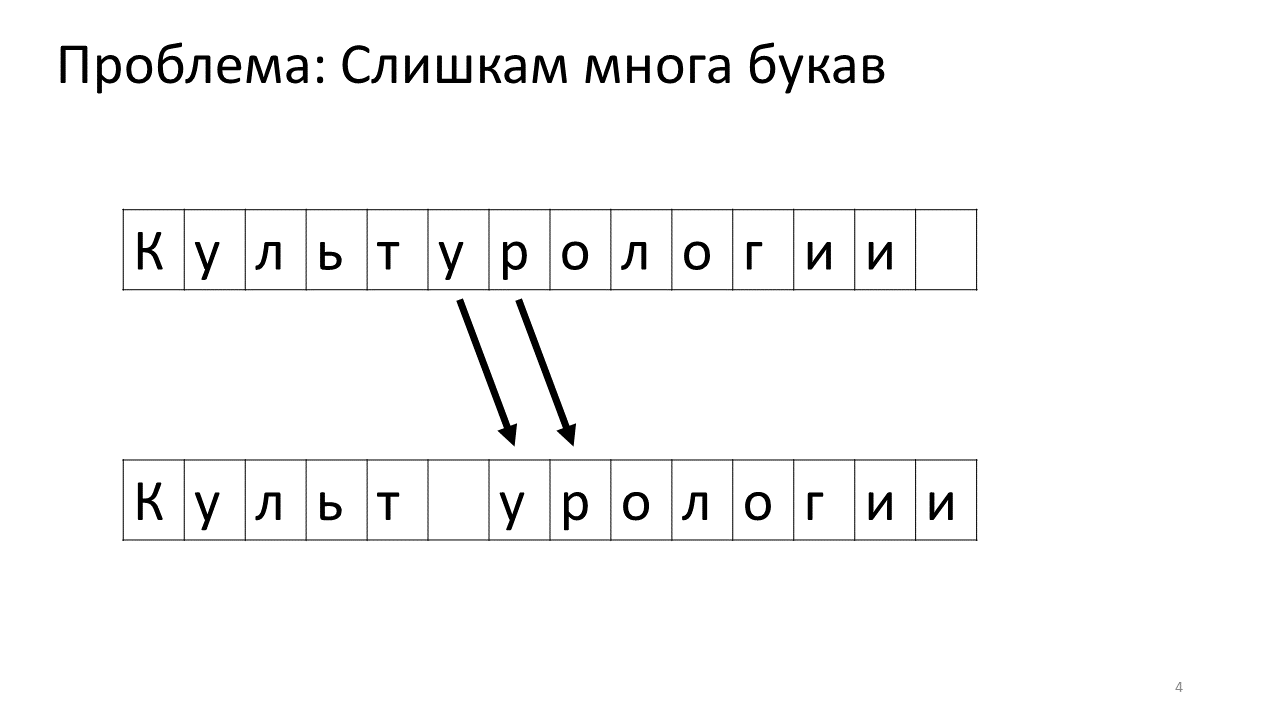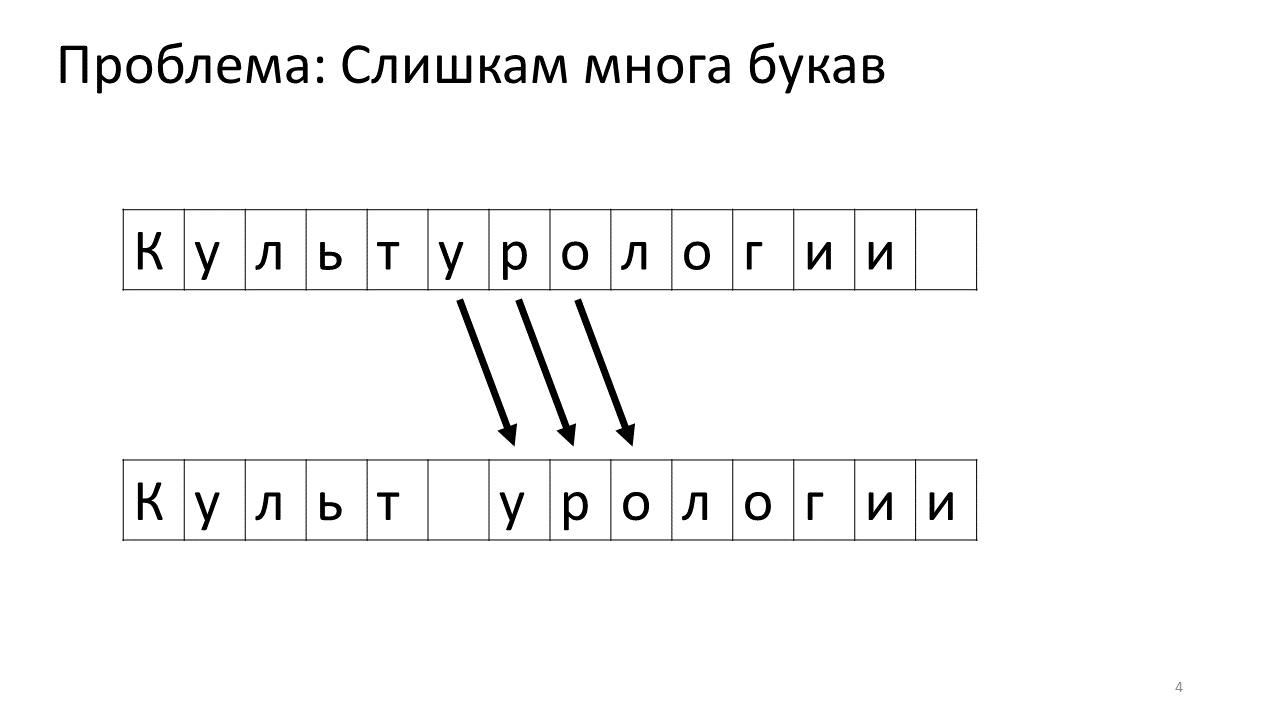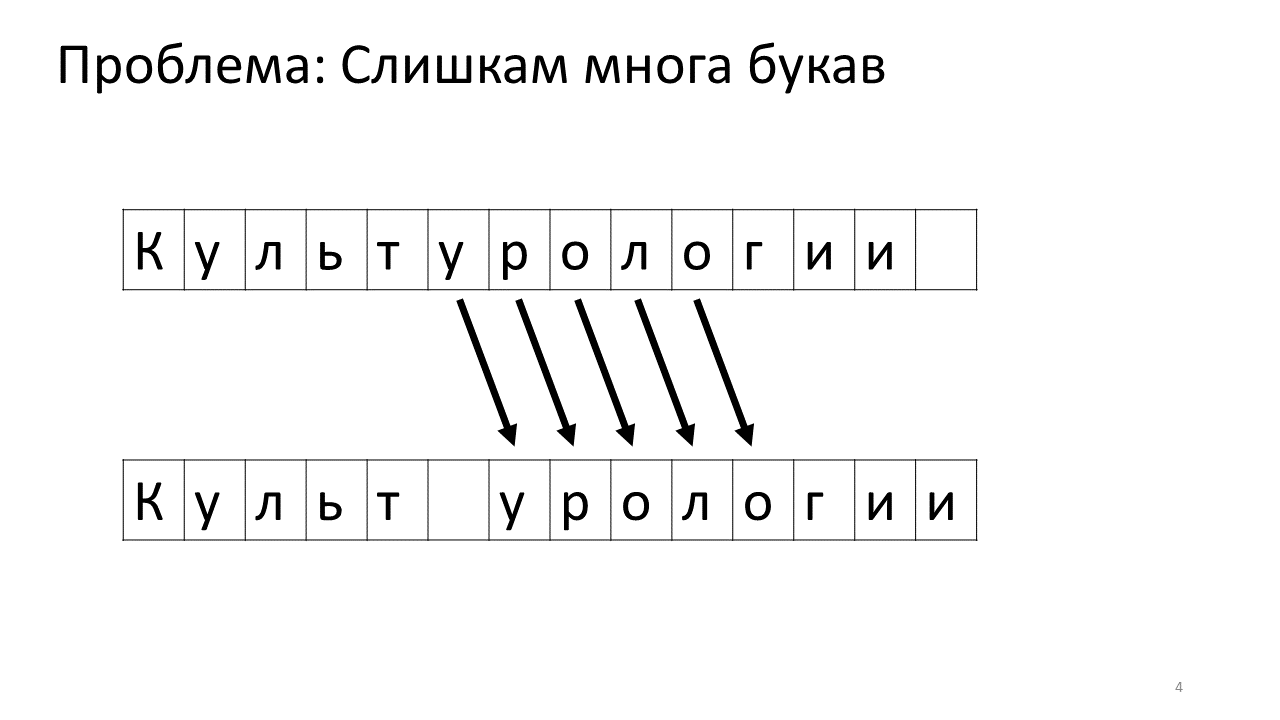
转移所有这么多兆字节不是很好:这很慢。 当然,对于现代计算机而言,这是一件小事-来回移动的某种可悲的兆字节。 但是对于非常活跃的文本更改,这可能会很明显。
为了解决在中间插入字符的问题,很久以前提出了一种称为“间隙缓冲区”的解决方法。
间隙缓冲
差距就是差距。 正如您可能想象的那样,缓冲区是一个缓冲区。 Gap Buffer数据结构是一个空缓冲区,以防万一,我们将其保留在文本中间。 如果需要打印某些内容,可以使用此小型文本缓冲区进行快速键入。

数据结构有所变化-数组保留在原位,但是出现了两个指针:在缓冲区的开头和结尾。 要从编辑器获取某个偏移量的字符,我们需要了解它是在此缓冲区之前还是之后,并稍微校正偏移量。 要插入一个字符,我们首先需要将间隙缓冲区移到该位置并用这些字符填充它。 而且,当然,如果我们超出了缓冲区的范围,则将以某种方式重新创建它。 这就是图片中的样子。

如您所见,我们首先在一个小的间隙缓冲区(蓝色矩形)上移动了很长时间到编辑位置(简单地依次从其左右边缘交换字符)。 然后,我们使用此缓冲区,在其中键入字符。
如您所见,没有兆字节字符的移动,插入速度非常快,而且持续了一定的时间,似乎每个人都很高兴。 一切似乎都很好,但是如果我们的处理器非常慢,则来回移动间隙缓冲区和文本会浪费大量时间。 在兆赫兹很小的时候,这一点尤其明显。
件表
就在那时,一家名为Microsoft的公司编写了文本编辑器Word。 他们决定采用另一种想法来加快编辑速度,即“ Piece Table”,即“ Piece Table”。 他们建议将编辑器的文本保存在最简单的相同字符数组中,该字符数组将不会更改,并将所有更改与这些相同的编辑片段放在单独的表中。

因此,如果我们需要按偏移量查找某个字符,则需要找到我们编辑过的片段并从中提取该字符,如果不存在,请转到原始文本。 插入符号变得更加容易,我们只需要创建这个新片段并将其添加到表中即可。 这是图片中的外观:
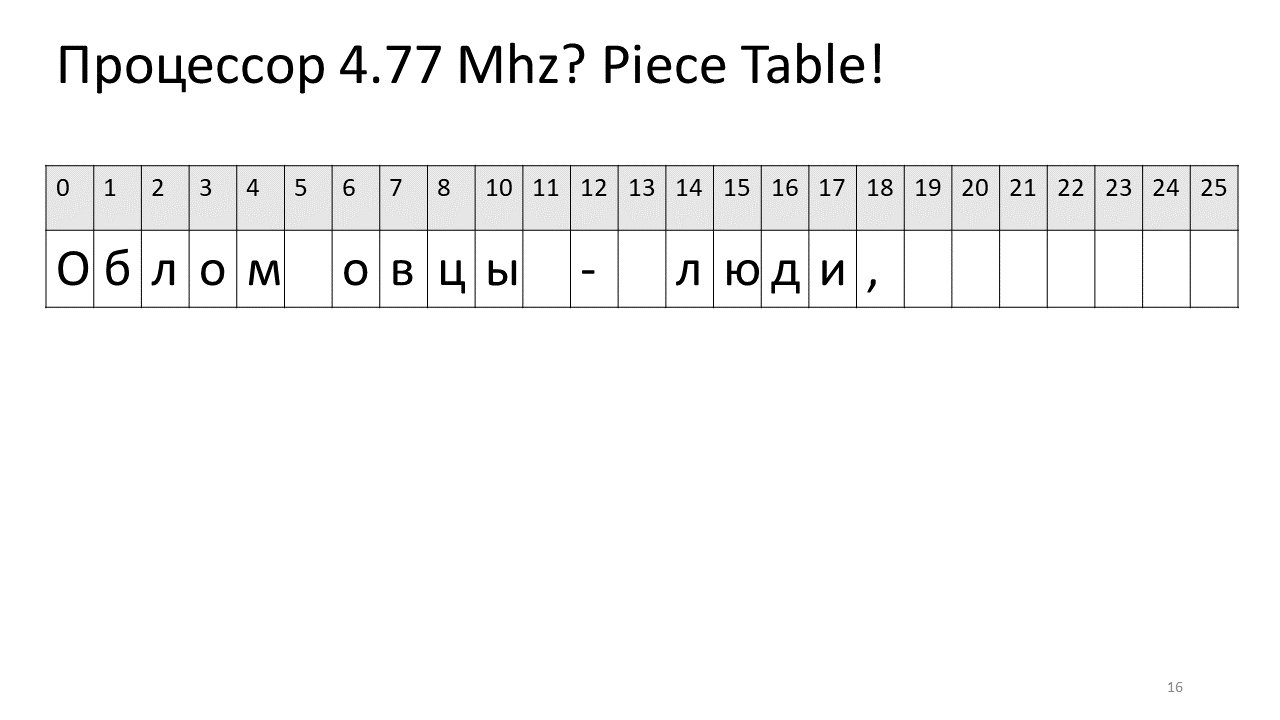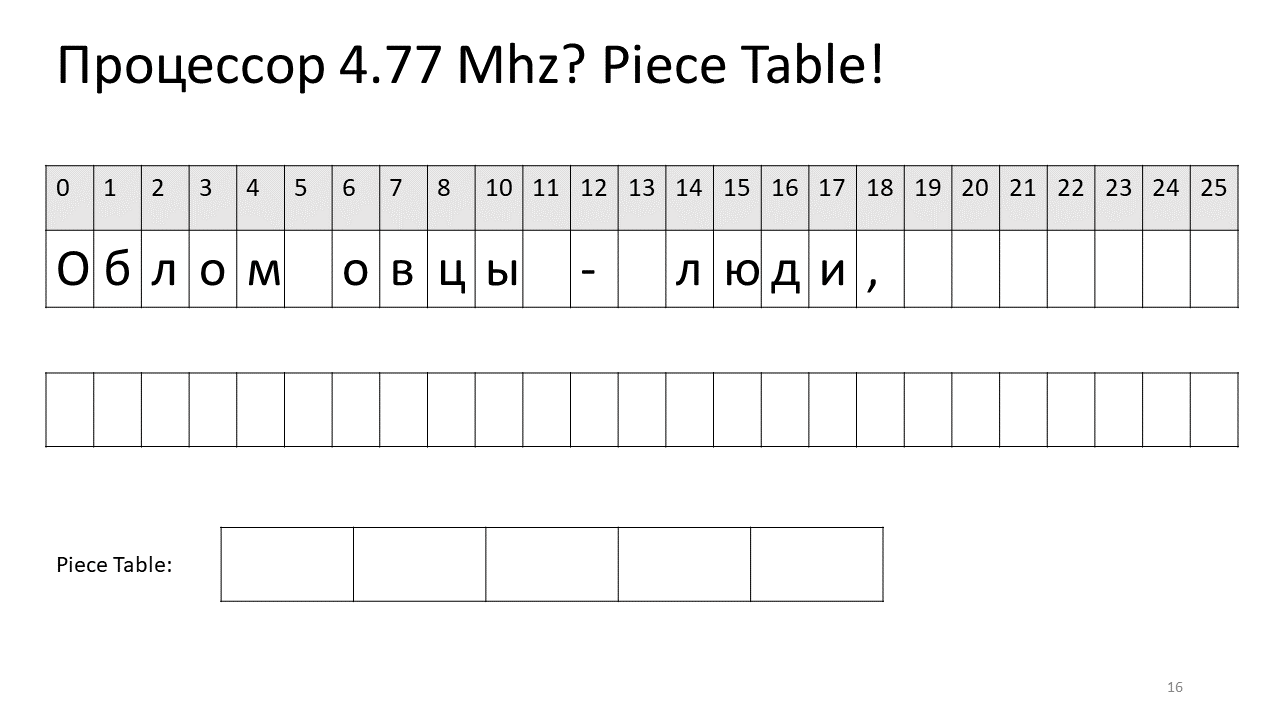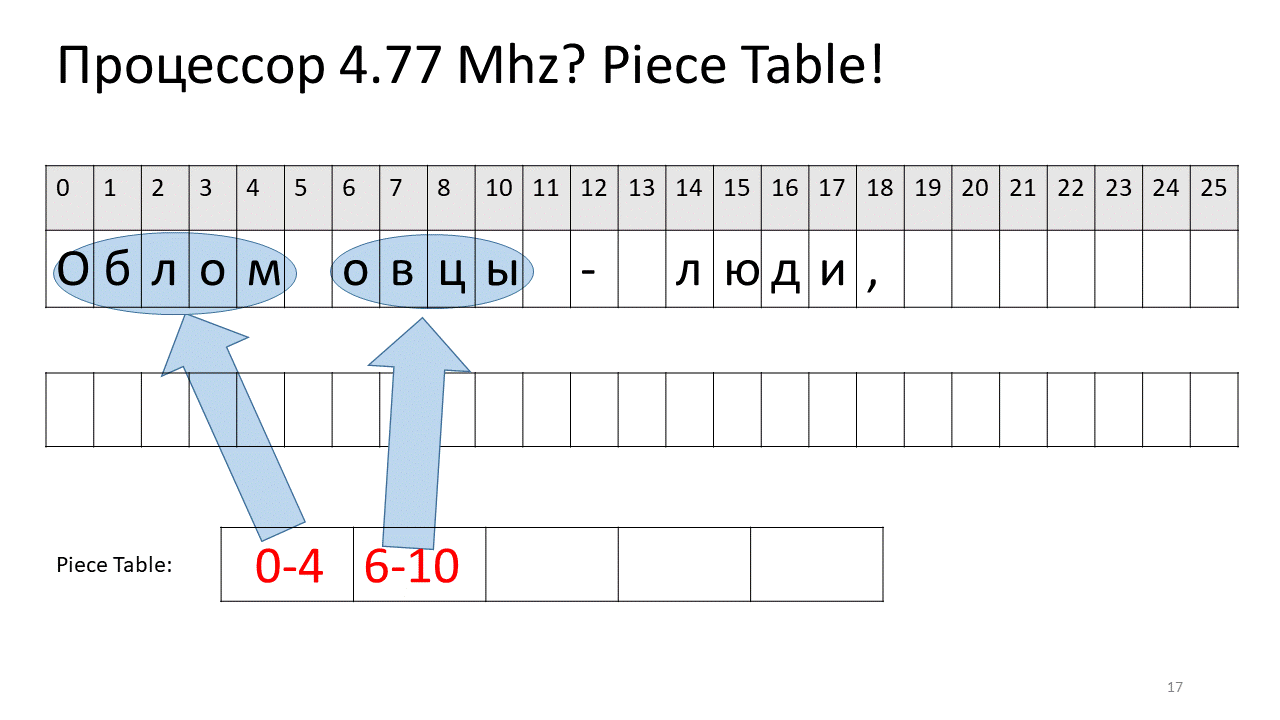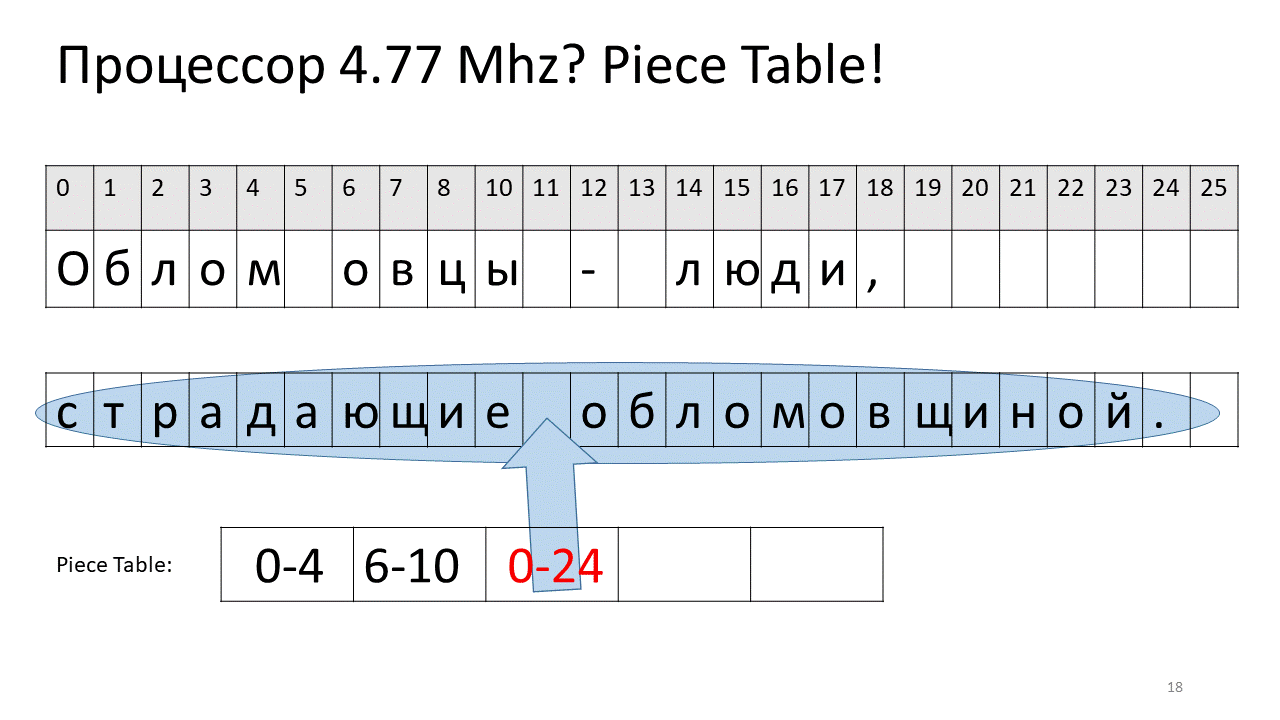
在这里,我们要删除偏移量5处的空间。为此,我们在切片表中添加了两个新片段:一个指示第一个片段(“ Bummer”),第二个指示编辑后的片段(“ sheep”)。 事实证明,它们之间的缝隙消失了,这两部分被粘合在一起,我们得到的新文本已经没有空格:“ Oblomovtsy”。 然后,我们在末尾添加新文本(“遭受Oblomovism的折磨”)。 使用额外的缓冲区,并将新的切片添加到计件表中,以指向此最新添加的文本。
如您所见,没有来回移动,所有文本都保留在原位。 坏消息是,越来越难以找到该符号,因为对所有这些片段进行分类非常困难。
总结一下。
Piece Table有什么好处:
不好的是:
让我们看看我们通常使用什么。
NetBeans,Eclipse和Emacs使用Gap Buffer-做得好! Vi不会打扰,仅使用行列表。 Word使用计件表(它们最近列出了它们的古老种类,您甚至可以在其中了解一些内容)。
原子更有趣。 直到最近,他们才开始使用JavaScript行列表。 然后他们决定用C ++重写所有内容,并堆积了一个相当复杂的结构,该结构似乎类似于Piece Table。 但是这些片段不是存储在列表中,而是存储在树中以及所谓的splay树中-这是一棵在插入其中时会自动调整的树,因此最近的插入操作更快。 他们做了一件非常复杂的事情。
Intellij IDEA使用什么?
不,不是间隙缓冲。 不,你也是错的,不是一张桌子。
是的,非常正确,您自己的自行车。
事实是,IDE对存储文本的要求与常规文本编辑器中的要求略有不同。 IDE需要支持各种棘手的事情,例如竞争力,即从编辑器并行访问文本。 例如,使许多不同的烘焙食品可以阅读并做某事。 (检查是一小段代码,以一种或另一种方式解析程序-例如,查找引发NullPointerException的位置)。 IDE还需要可编辑的文本版本支持。 在处理文档时,多个版本同时存储在内存中,以便这些漫长的过程继续分析旧版本。
问题所在
竞争力/版本控制
为了保持并行性,通常将文本操作包装在“同步”或“读/写锁”中。 不幸的是,这不能很好地扩展。 另一种方法是不可变文本,即不可变文本存储库。

这是一个将不可变文档作为支持数据结构的编辑器的外观。
数据结构如何工作?
而不是字符数组,我们将拥有一个类型为ImmutableText的新对象,该对象以树的形式存储文本,其中小的子字符串存储在工作表中。 当以一定的偏移量访问时,他尝试到达该树的最底端,并且已经向他询问了我们所指的符号。 并且当您插入文本时,他会创建一棵新树并将其保存在旧位置。

例如,我们有一个文本为“无热量”的文档。 它被实现为具有两张替换“ Demon”和“ high-calorie”的树。 当我们要在中间插入“ pretty”行时,将创建文档的新版本。 确切地说,创建了一个新的根,上面已经附加了三张纸:“ Demon”,“足够”和“高热量”。 此外,这些新表中的两个可能引用了我们文档的第一版。 对于我们插入“ pretty”行的图纸,将分配一个新的顶点。 在这里,第一个版本和第二个版本都可以同时使用,并且它们都是不可变的。 一切看起来都很好。
谁使用棘手的结构?

例如,在GNOME中,它们的一些标准小部件使用称为Rope的结构。 Xi-Editor是
Raf Levien的新任出色编辑,使用了Persistent Rope。 Intellij IDEA使用此不可变树。 实际上,所有这些名称的后面或多或少都是相同的数据结构,并以树状表示。 除了GtkTextBuffer使用可变绳索外,即具有可变顶点的树,以及Intellij IDEA和Xi-Editor-不可变。
在现代IDE中开发字符存储库时,要考虑的下一件事称为多猫。 此功能使您可以使用多个笔架一次在多个位置进行打印。

我们可以打印一些内容,同时在文档的多个位置插入我们打印的内容。 如果我们查看我们检查过的数据结构对多重插入符的反应,我们将看到一些有趣的东西。
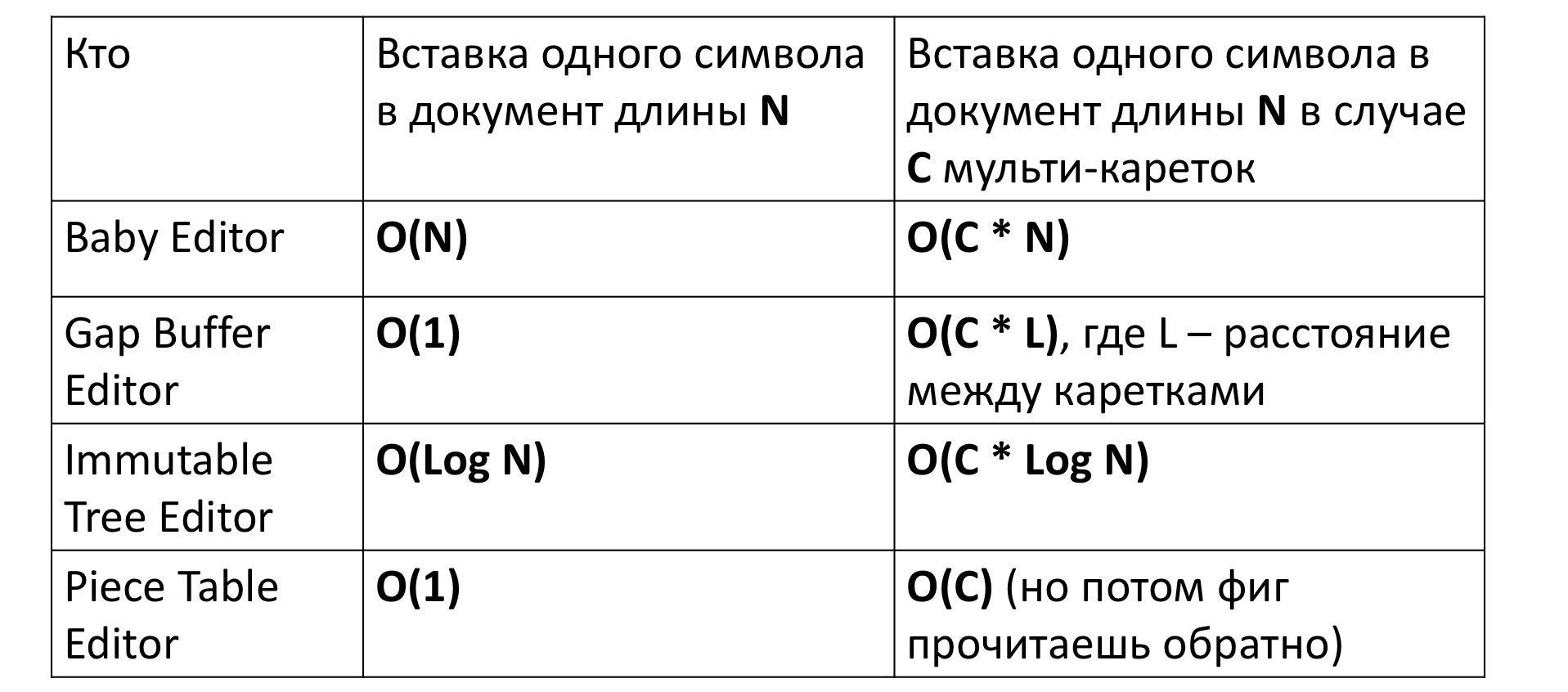
如果我们在第一个原始编辑器中插入一个字符,则自然会花费线性时间来回移动一堆字符。 这写为O(N)。 反过来,对于基于Gap Buffer的编辑器,需要恒定的时间,为此他被创造了出来。
对于不可变的树,时间在对数上取决于大小,因为您必须首先从树的顶部到其叶子-这是对数,然后对于路径上的所有顶点为新树创建新顶点-这又是对数。 计件表也需要一个常数。
但是,如果我们尝试测量将字符插入到具有多笔架的编辑器中的时间(即在多个位置同时插入)的时间,则一切都会有所变化。 乍一看,时间似乎成比例地增加了C,即插入符号的位置数。 这就是实际发生的情况,除了Gap Buffer。 在他的情况下,时间(而不是C倍)意外地增加了一些难以理解的C * L倍,其中L是滑架之间的平均距离。 为什么会这样呢?
想象一下,我们需要在文档的两个位置插入“,on”行。
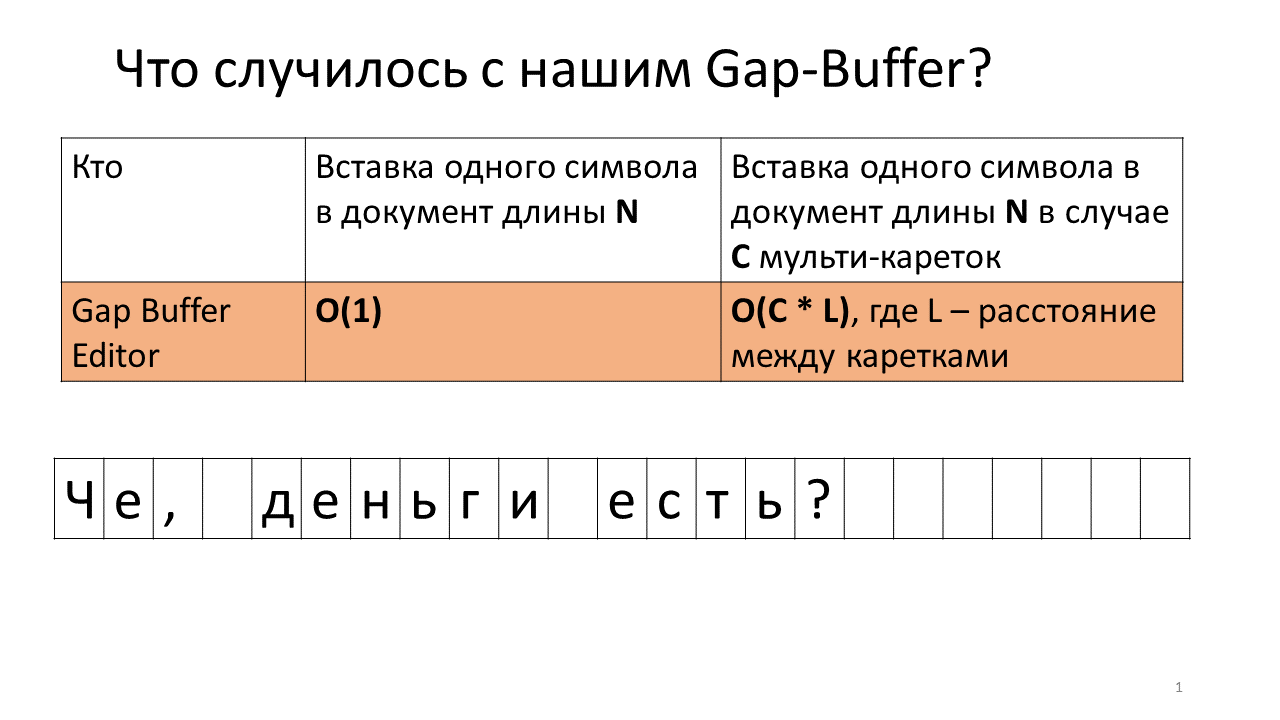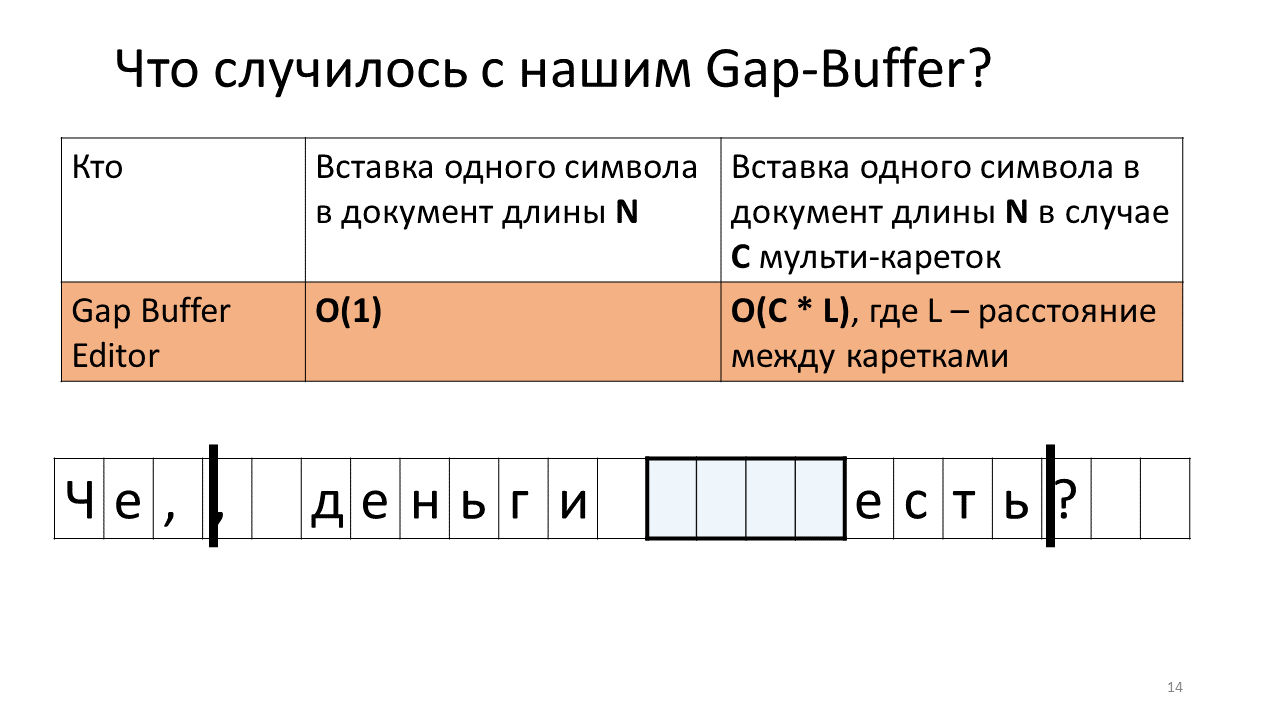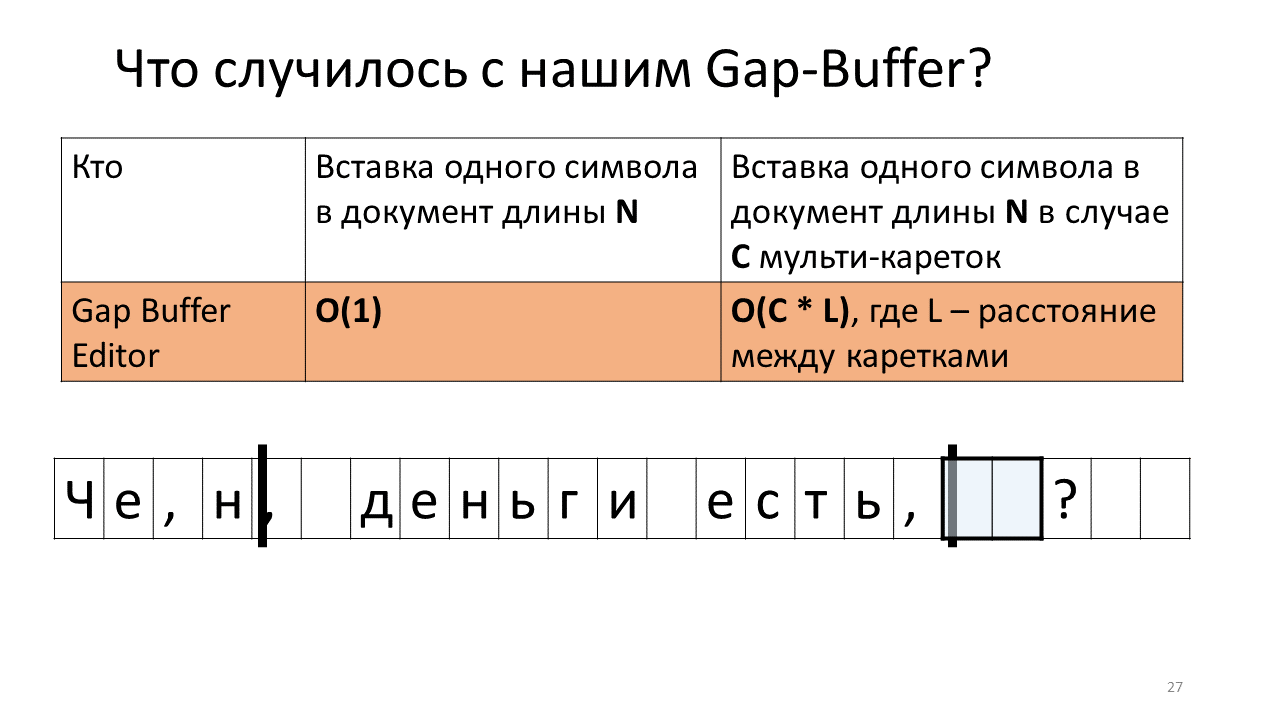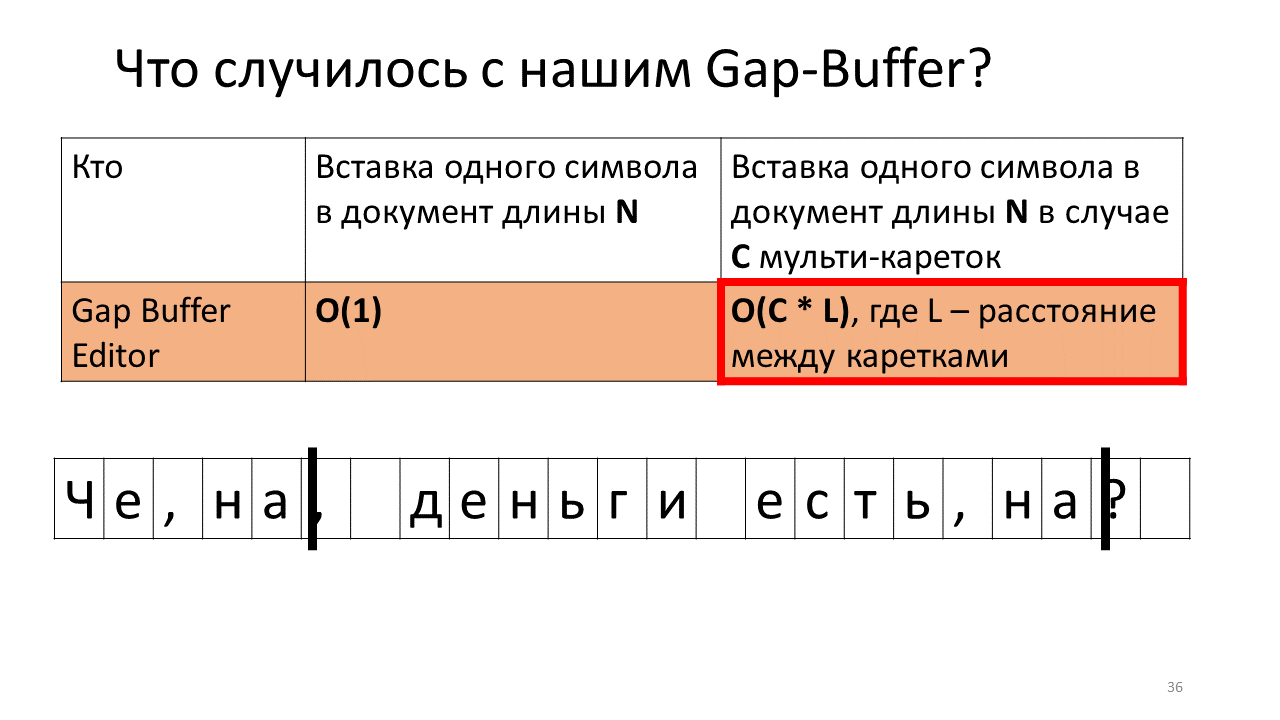
这就是此时在编辑器中发生的情况。
- 在编辑器中创建一个间隙缓冲区(图片中的一个蓝色小矩形);
- 我们开始两辆马车(黑色粗线)。
- 我们正在尝试打印;
- 在我们的Gap Buffer中插入一个逗号;
- 您现在应该将其插入第二个支架的位置;
- 为此,我们需要将间隙缓冲区移至下一个托架的位置。
- 将逗号打在第二位;
- 现在,您需要在第一个笔架的位置插入下一个字符;
- 而且我们必须将间隙缓冲区推回去;
- 插入字母“ n”;
- 然后,我们将受苦的缓冲区移到第二个滑架的位置。
- 我们在其中插入“ n”;
- 将缓冲区移回以插入下一个字符。
感觉一切都在哪里?
是的,事实证明,由于缓冲区的这种来回移动,我们的总时间增加了。 老实说,并不是因为它的增加而直接被吓到-在现代计算机上来回移动可悲的兆字节,千兆字节不是问题,但是有趣的是,这种数据结构在多猫的情况下工作原理截然不同。
行太多? LineSet!
常规文本编辑器还有什么其他问题? 最困难的问题是滚动,即在将笔架移至下一行时重新绘制编辑器。

当编辑器滚动时,我们需要了解从哪一行,从哪个符号开始在小窗口中绘制文本。 为此,我们需要快速了解哪条线对应于哪个偏移量。
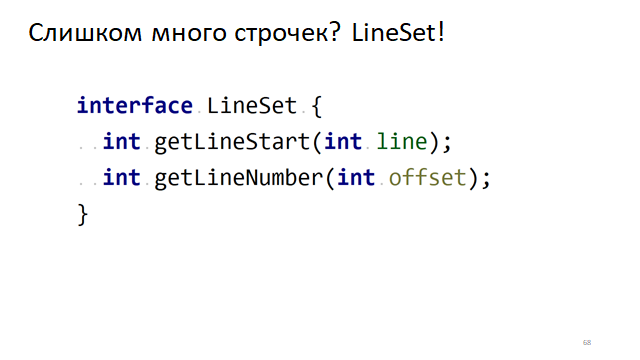
当我们需要通过行号了解其在文本中的偏移量时,有一个明显的接口。 反之亦然,通过在文本中的偏移量了解它在哪一行。 如何快速完成?
例如,像这样:
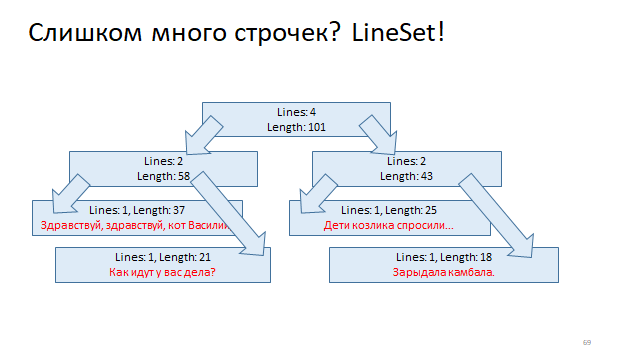
将这些线组织成一棵树,并通过移动线的起点和线的终点来标记该树的每个顶点。 然后,为了通过偏移量了解它所在的行,您只需要在此树中运行对数搜索并找到它。
另一种方法甚至更容易。
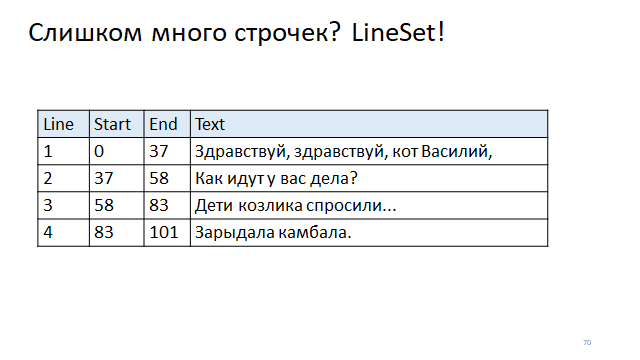
在表格中写出行首与行尾的偏移量。 然后,要找到行号开头和结尾的偏移量,您将需要访问索引。
有趣的是,在现实世界中,两种方法都被使用。

例如,Eclipse使用了这样一种木制结构,如您所见,它在对数时间内可用于读取和更新。 IDEA使用表结构,其读取是一个快速常数,它是表中的索引反转,但是重建相当慢,因为更改行的长度时需要重建整个表。
还是行太多? 折叠!
跨文本编辑器绊倒的还有什么不好? 例如,折叠。 这些是您可以“折叠”并显示其他内容的文本。

图片中绿色背景上的这些点在我们后面隐藏了许多符号,但是如果我们对查看它们不感兴趣(例如,对于最长的无聊Java文档或导入列表而言),我们会将其隐藏起来,将其折叠省略号。
在这里,您需要再次了解它何时结束以及何时需要显示的区域开始,以及如何快速更新它们? 这是如何组织的,我稍后再讲。
太长的线? 保鲜膜!

同样,没有软包装,现代编辑也无法生存。 图片显示开发人员在最小化后打开了JavaScript文件,并立即感到遗憾。 当我们尝试在编辑器中显示该巨大的JavaScript行时,它将不会适合任何屏幕。 因此,保鲜膜将其强行撕成几行,然后推入屏幕。
如何组织-稍后。
太美了

最后,我也想给文字编辑带来美感。 例如,突出显示一些单词。 在上图中,关键字以粗体蓝色突出显示,一些静态方法用斜体显示,一些注释也用不同的颜色显示。
那么,如何仍然存储和处理折页,软包装和高光呢?
事实证明,所有这些原则上都是一项任务。
太美了吗? 范围荧光笔!

为了支持所有这些功能,我们需要做的就是将某些文本属性粘贴到文本中的给定偏移处,例如颜色,字体或要折叠的文本。 而且,这些文本属性必须在此位置始终进行更新,以便它们能够经受各种插入和删除操作。
通常如何实施? 自然地,以树的形式。
问题:美丽太多? 间隔树!

例如,在这里我们有几个要突出显示的黄色高光。 我们将这些突出显示的间隔添加到搜索树中,即所谓的间隔树。 这是同一棵搜索树,但是有点棘手,因为我们需要存储间隔而不是数字。
而且,由于既有健康间隔又有小间隔,如何对它们进行排序,相互比较以及将它们放入树中是一项相当艰巨的任务。 尽管在计算机科学中非常广为人知。 然后以某种方式查看您的休闲方式。 因此,我们将所有间隔都放在一棵树中,然后中间的某处文本的每次更改都会导致该树的对数更改。 例如,插入一个字符应导致更新该字符右边的所有间隔。 为此,我们找到该符号的所有主要顶点,并指出所有其顶点必须向右移动一个符号。
还想要美丽吗? 连字!

还有这么可怕的一件事-连字,我也想支持。 这些是不同的美,例如符号“!=”以大字形“不相等”的形式绘制,依此类推。 幸运的是,这里我们依靠一种摆动机制来支持这些连字。 而且,根据我们的经验,他显然是以最简单的方式工作。 在字体内部,存储了所有这些对字符的列表,将它们组合在一起时会形成某种棘手的连字。 然后,在画线时,Swing会简单地遍历所有这些对,找到必要的对并相应地进行绘制。 如果字体中有许多连字,则显然,显示它会成比例地减慢速度。
刹车倾翻
最重要的是,现代复杂编辑器中遇到的另一个问题是提示的优化,即按键并显示结果。

如果您进入Intellij IDEA并查看按下按钮时会发生什么,那么可能会发生以下恐怖事件:
- 单击按钮时,例如,如果键入一些“ Enter”,则必须查看是否在完成弹出窗口中以关闭菜单以完成操作。
- 您需要查看文件是否在某些棘手的版本控制系统下,例如Perforce,该系统需要采取一些措施才能开始编辑。
- 检查文档中是否有任何无法打印的特殊区域,例如一些自动生成的文本。
- 如果文档被尚未结束的操作阻塞,则需要完成格式化,然后再继续。
- injected-, , , - .
- auto popup handler, , , .
- info , , . selection remove, selection , . selection , .
- typed handler, , .
- .
- undo, virtual space' write action.
- , .
万岁!不,这还不是全部。如果缓冲区已满,请删除字符。例如,在控制台中,调用侦听器,以便每个人都知道某些更改。滚动编辑器视图。叫其他一些愚蠢的听众。当他发现文档已更改并调用DocumentListener时,现在在编辑器中会发生什么?在Editor.documentChanged()中,将发生以下情况:- 更新错误条带;
- 重新计算装订线尺寸,重新绘制;
- 重新计算编辑器组件的大小,更改时发送事件;
- 计算改变的线及其坐标;
- 如果更改影响到他,则重新计算软包装;
- 调用repaint()。
此repaint()只是Swing指示屏幕上的区域应重绘的指示。当Swing消息队列处理Repaint事件时,将发生真正的重绘。也就是说,在半小时左右的某个时间里,将处理事件的队列出现,将在相应的组件上调用repaint方法,该方法将执行以下操作: 在这种情况下,将调用一堆不同的Paint方法来绘制世界上所有可能的东西。好吧,也许我们会优化所有这些?
在这种情况下,将调用一堆不同的Paint方法来绘制世界上所有可能的东西。好吧,也许我们会优化所有这些? 至少可以说,这非常复杂。因此,Intellij IDEA决定欺骗用户。
至少可以说,这非常复杂。因此,Intellij IDEA决定欺骗用户。 在所有这些令人恐惧的事情重新叙述并写下来之前,我们调用了一个小的方法,该方法可以在用户键入该字母的位置绘制该不幸的字母。就是这样!用户之所以高兴是因为他认为一切都已改变,但实际上-不!在引擎盖下,它只是刚刚开始,但是字母已经在它前面燃烧。因此,每个人都很高兴。此功能称为“零延迟键入”。
在所有这些令人恐惧的事情重新叙述并写下来之前,我们调用了一个小的方法,该方法可以在用户键入该字母的位置绘制该不幸的字母。就是这样!用户之所以高兴是因为他认为一切都已改变,但实际上-不!在引擎盖下,它只是刚刚开始,但是字母已经在它前面燃烧。因此,每个人都很高兴。此功能称为“零延迟键入”。协同编辑
现在有一种时髦的东西-所谓的协作编辑器。这是什么 这是当一个用户坐在印度,另一个用户在日本时,他们试图在同一Google文档上打印内容,并希望获得某种可预测的结果。有什么特别之处:这里的特点是大量用户可以同时执行此操作,并且信号可以在很长一段时间内从印度传到日本。因此,通常在协作编辑中,他们使用诸如免疫之类的新事物。他们提出了不同的建议,以确保一切正常进行。这些是一些标准。第一个标准是意图的保留,即“意图保留”。这意味着,如果有人在商标上留下印记,那么来自印度的商标迟早会来到日本,而日本人将确切地看到印度人的意图。第二个准则是收敛。这意味着来自印度和日本的符号迟早会转变为对日本和印度而言相同的事物。运营转型
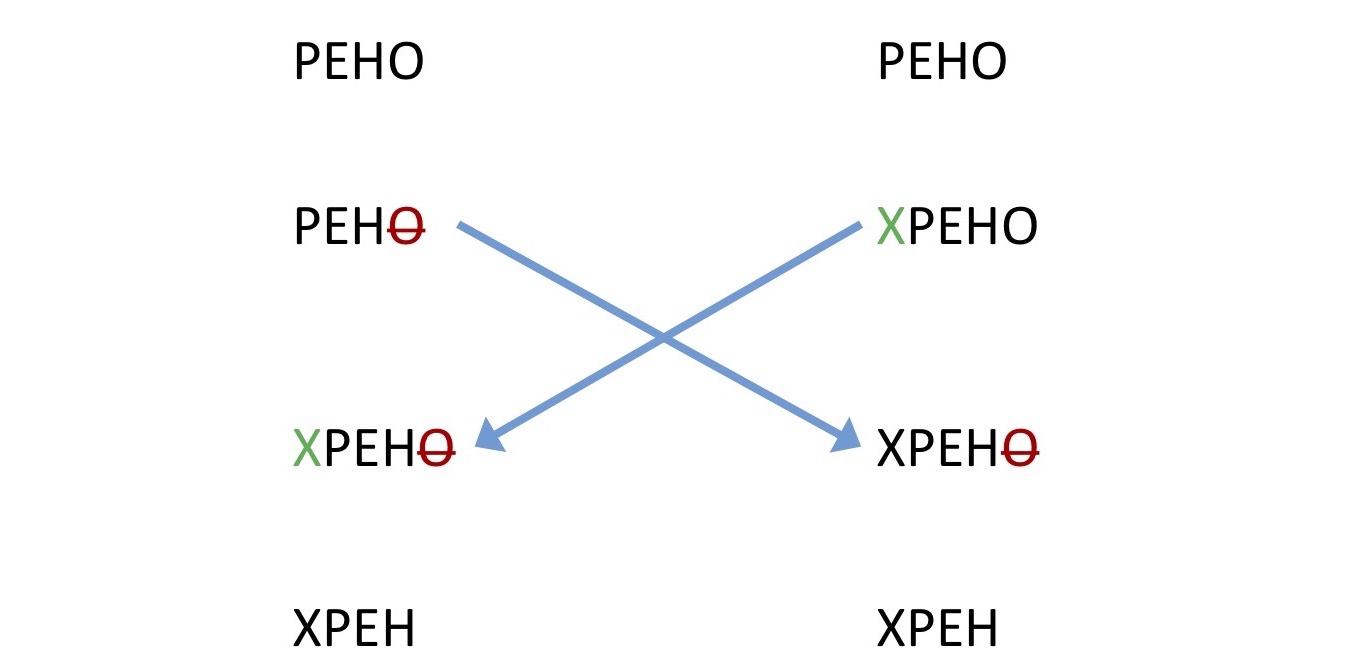 为支持该功能而发明的第一个算法称为“操作转换”。它就是这样。印度人和日本人坐在一起,输入内容:一个从结尾处删除字母,另一个从开头开始。操作转换框架将这些操作发送到所有其他地方。他必须了解如何遏制他的操作,以便至少获得明智的选择。例如,同时删除并显示该字母。他必须或多或少地在那儿工作,并保持一致。不幸的是,从我困惑的解释中可以看出,这是一件相当复杂的事情。当该框架的第一个实现开始出现时,惊奇的开发人员发现有一个通用的示例可以破坏所有内容。这个不幸的例子称为“ TP2拼图”。
为支持该功能而发明的第一个算法称为“操作转换”。它就是这样。印度人和日本人坐在一起,输入内容:一个从结尾处删除字母,另一个从开头开始。操作转换框架将这些操作发送到所有其他地方。他必须了解如何遏制他的操作,以便至少获得明智的选择。例如,同时删除并显示该字母。他必须或多或少地在那儿工作,并保持一致。不幸的是,从我困惑的解释中可以看出,这是一件相当复杂的事情。当该框架的第一个实现开始出现时,惊奇的开发人员发现有一个通用的示例可以破坏所有内容。这个不幸的例子称为“ TP2拼图”。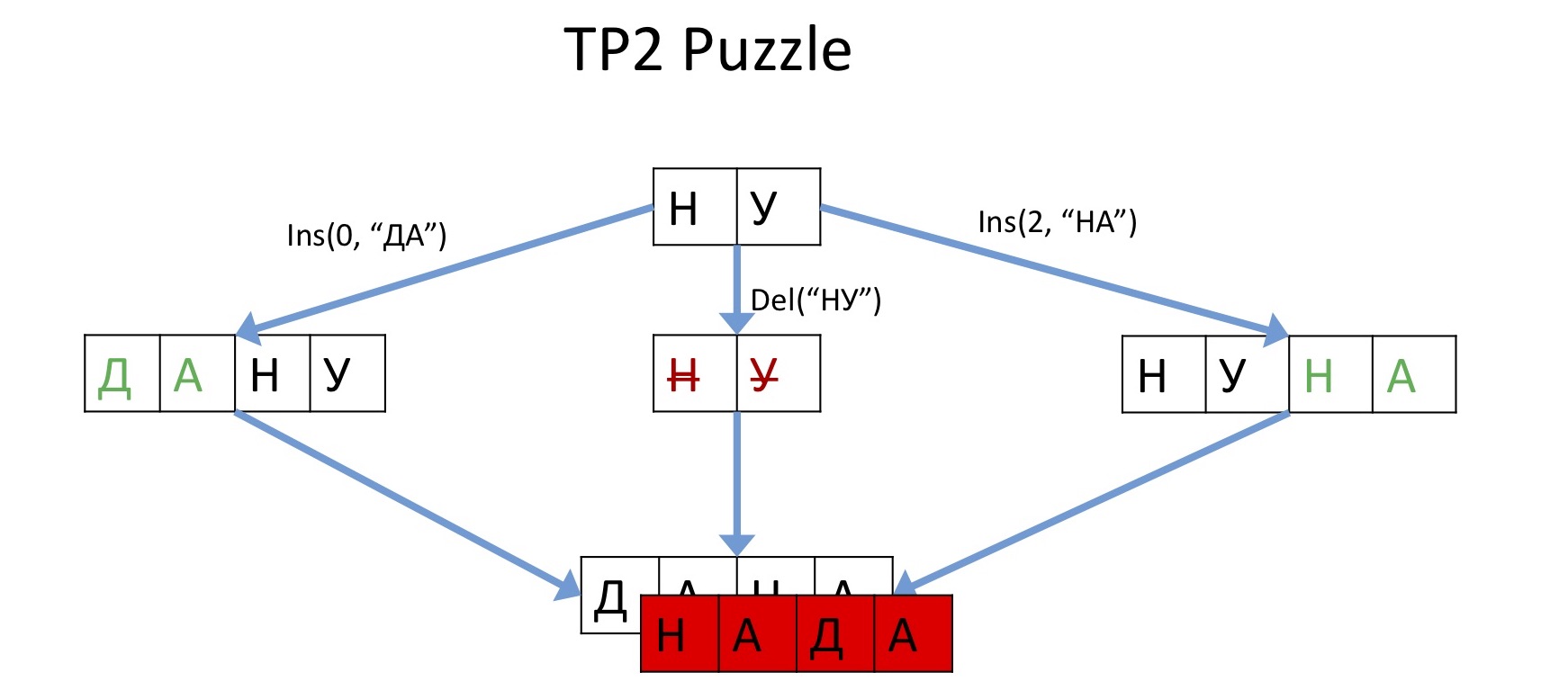 一个用户在行的开头绘制了一些字符,另一个用户删除了所有这些字符,而第三个则绘制到了结尾。在所有此Operation转换尝试合并到同一事物之后,从理论上讲,这行(“ DANA”)应该出现。但是,某些实现方式做到了这一点(“ NADA”)。因为不清楚在哪里插入它。在上面的图片中,您可以看到所有有关操作转换的科学都位于什么级别,如果由于这样的原始示例而一切都破了。但是尽管如此,还是有人可以做到这一点,例如Google Docs,Google Wave和一些分布式Etherpad编辑器。尽管有列出的问题,他们仍使用操作转换。
一个用户在行的开头绘制了一些字符,另一个用户删除了所有这些字符,而第三个则绘制到了结尾。在所有此Operation转换尝试合并到同一事物之后,从理论上讲,这行(“ DANA”)应该出现。但是,某些实现方式做到了这一点(“ NADA”)。因为不清楚在哪里插入它。在上面的图片中,您可以看到所有有关操作转换的科学都位于什么级别,如果由于这样的原始示例而一切都破了。但是尽管如此,还是有人可以做到这一点,例如Google Docs,Google Wave和一些分布式Etherpad编辑器。尽管有列出的问题,他们仍使用操作转换。无冲突的复制数据类型
这里的人们绞尽脑汁,决定:“让我们比OT更容易!” 需要处理和合并在一起的各种棘手的操作组合的数量正呈平方增长。因此,无需处理所有组合,我们只需将状态和操作一起发送给所有其他主机,这样就可以在保证100%保证的前提下将其合并为同一文本。这称为“ CRDT”(无冲突的复制数据类型)。 为此,您需要一个状态和一个函数,两个状态中的一个与操作一起构成一个新状态。此外,该函数应该是可交换的,联想的,幂等的和单调的。然后很明显,所有东西都可以简单地工作,并且是钢筋混凝土。由于功能上的这些严格限制,我们不再担心网络中的混乱(功能w是可交换的),优先级(关联)和数据包丢失(幂等和单调)。
为此,您需要一个状态和一个函数,两个状态中的一个与操作一起构成一个新状态。此外,该函数应该是可交换的,联想的,幂等的和单调的。然后很明显,所有东西都可以简单地工作,并且是钢筋混凝土。由于功能上的这些严格限制,我们不再担心网络中的混乱(功能w是可交换的),优先级(关联)和数据包丢失(幂等和单调)。 自然界中是否存在这样的功能,如何应用?
自然界中是否存在这样的功能,如何应用?是的
例如,对于所谓的G计数器,即计数器仅在增长。您可以为此计数器编写一个真正单调的函数,依此类推。因为如果我们在日本进行“ +1”操作,而在印度进行另一次“ +1”操作,则很明显如何从它们中建立一个新州-只需添加“ 2”即可。但是事实证明,您也可以以相同的方式创建一个任意计数器,该计数器可以递增和递减。为此,只需使用一个G计数器,该计数器会一直增长,然后对其应用所有增量操作。并将所有减量应用于另一个G计数器,该计数器将逐渐减小。要获得当前状态,您只需要减去它们的内容,就可以得到相同的单调性。可以扩展到任意集合。但是最重要的是在任意行上。是的,使用CRDT也可以编辑任意字符串。事实证明这很容易。无冲突的复制插入
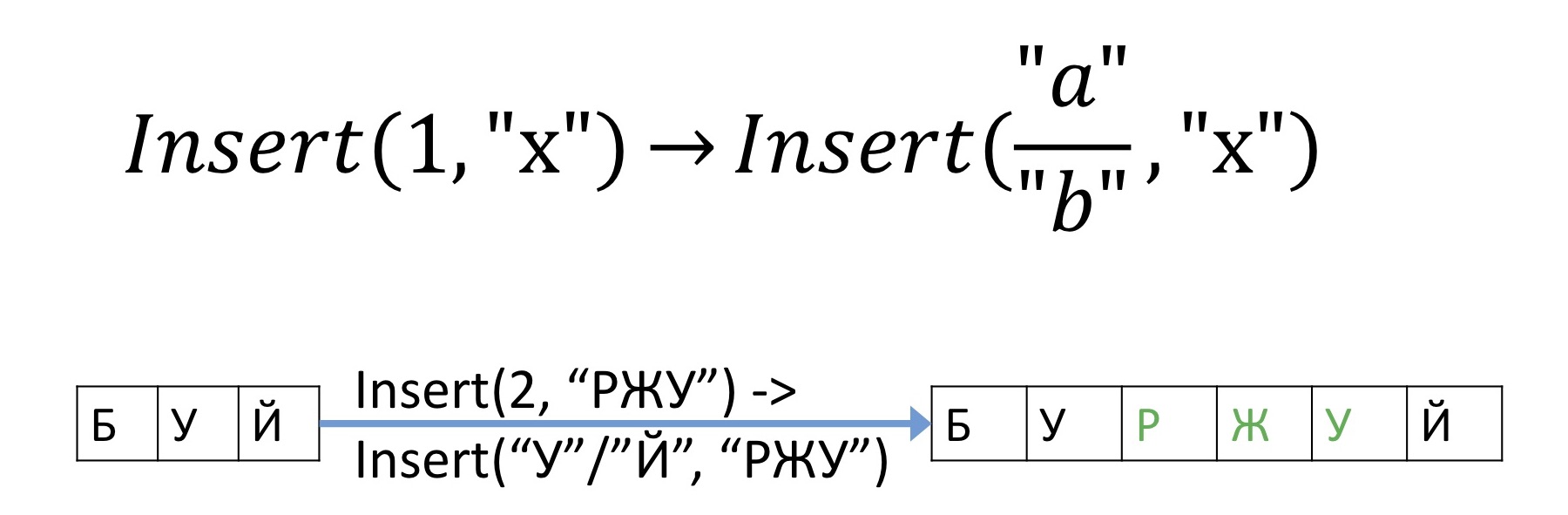 首先,我们将命名文档中的所有字符,以便即使进行任何编辑后也始终可以唯一标识它们。好吧,例如,我们将与每个字母一起存储一个唯一的数字。现在,我们不是向所有人发送信息,而是在某个偏移处插入符号,而是在要插入的符号之间进行讨论。然后很显然,没有任何差异,即使在任何其他操作之后,无论插入到哪里,我们都一定会知道该位置。例如,不是发送要在偏移2处插入“ RZhU”的操作,而是将发送在“ U”和“ Y”之间插入“ RZhU”的信息。
首先,我们将命名文档中的所有字符,以便即使进行任何编辑后也始终可以唯一标识它们。好吧,例如,我们将与每个字母一起存储一个唯一的数字。现在,我们不是向所有人发送信息,而是在某个偏移处插入符号,而是在要插入的符号之间进行讨论。然后很显然,没有任何差异,即使在任何其他操作之后,无论插入到哪里,我们都一定会知道该位置。例如,不是发送要在偏移2处插入“ RZhU”的操作,而是将发送在“ U”和“ Y”之间插入“ RZhU”的信息。无冲突的复制删除
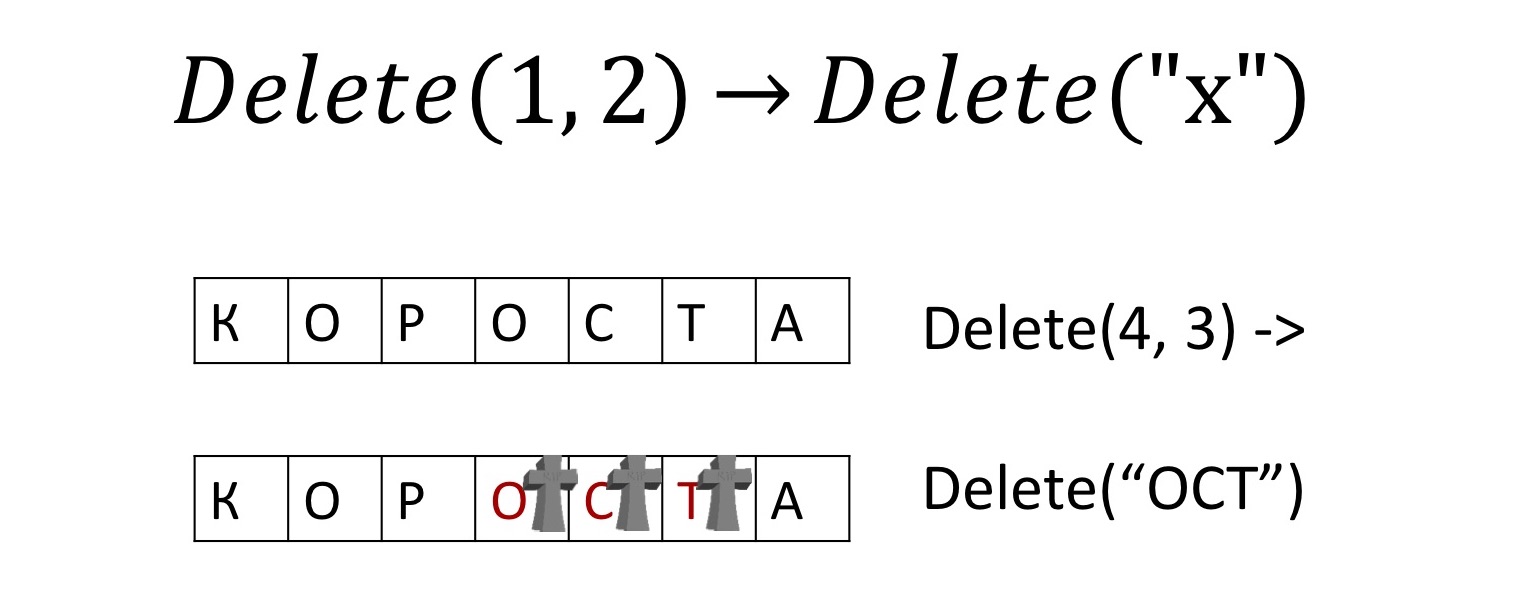 您还可以实现字符删除。由于我们已对所有字符进行了唯一重命名,因此我们只需要确切说出要删除的字符,而不是一些偏移量即可。但是,我们不会采用并实际删除这些字符,而是将其标记为已删除。为了让随后的并发插入或删除操作知道,如果它们影响到这些刚刚删除的字符,它们应该去哪里。事实证明,这整个新科学都是行得通的。
您还可以实现字符删除。由于我们已对所有字符进行了唯一重命名,因此我们只需要确切说出要删除的字符,而不是一些偏移量即可。但是,我们不会采用并实际删除这些字符,而是将其标记为已删除。为了让随后的并发插入或删除操作知道,如果它们影响到这些刚刚删除的字符,它们应该去哪里。事实证明,这整个新科学都是行得通的。无冲突的复制编辑
而且,实际上,CRDT甚至在某个地方实现,例如在Xi-Editor中,它将被插入其新型的秘密操作系统Fuchsia中。老实说,我不知道其他示例,但是它确实有效。拉链式
我也想谈谈在这个新的不可变世界中使用的东西,叫做“拉链”。在我们使结构不变之后,出现了一些与它们合作的细微差别。例如,在这里,我们有带有文本的不可变树。我们要更改它(如您所知,此处的“更改”是指“创建新版本”)。此外,我们希望在某个特定位置进行更改,并且要非常积极。在编辑器中,当我们不断在光标位置不断打印,粘贴和删除某些内容时,这是很常见的。为此,工作人员提出了一种称为“拉链”的结构。它的概念是所谓的光标或当前编辑位置,同时保持完全不变。这是操作方法。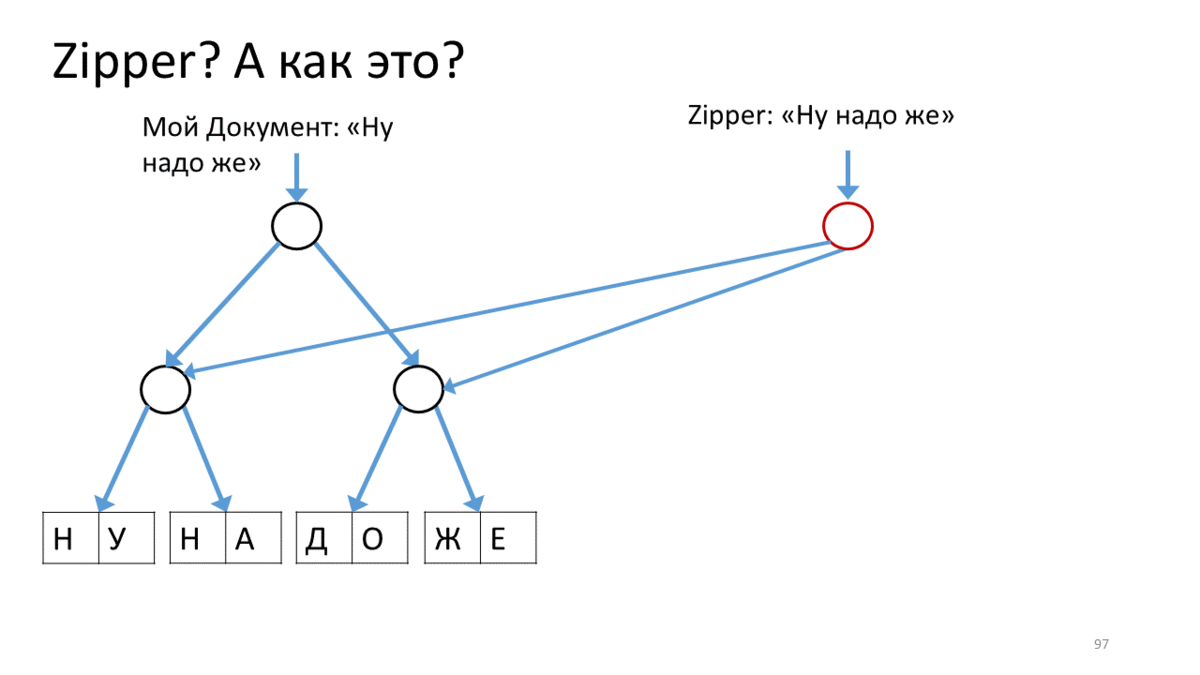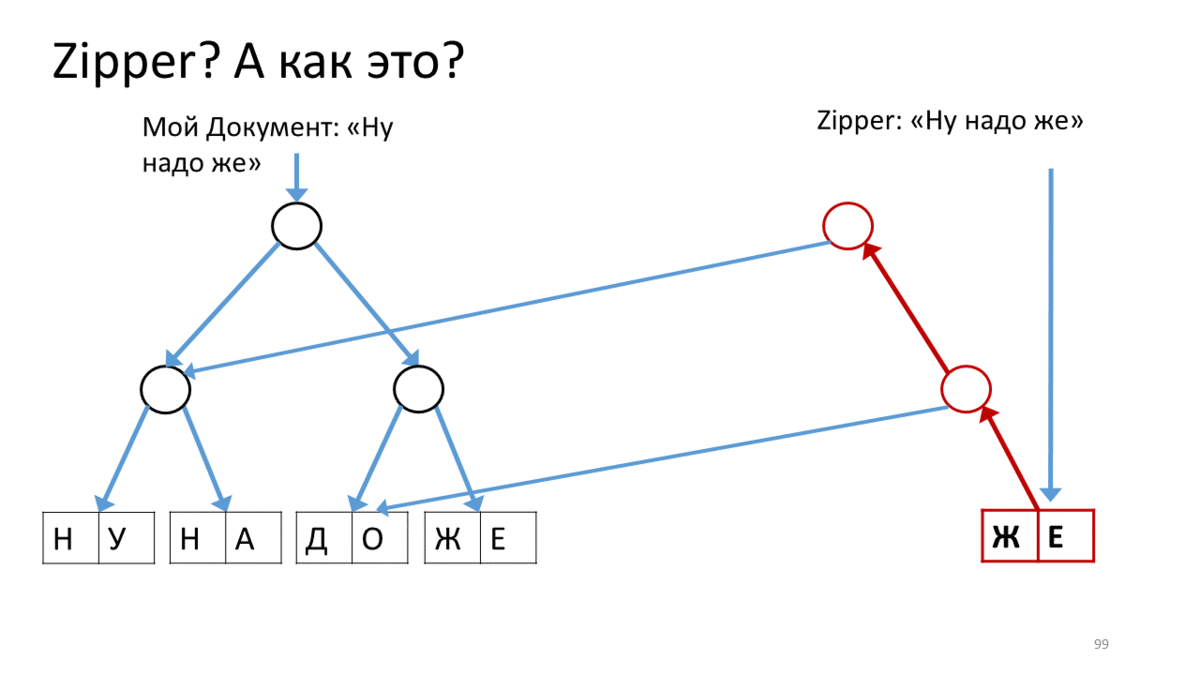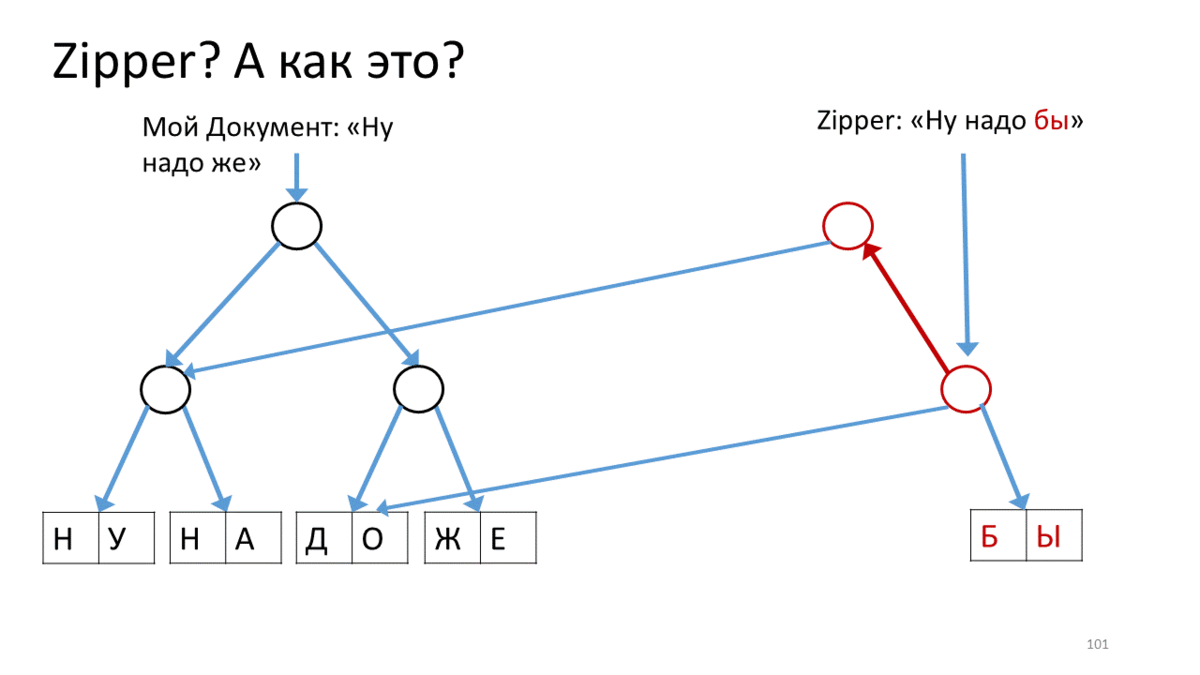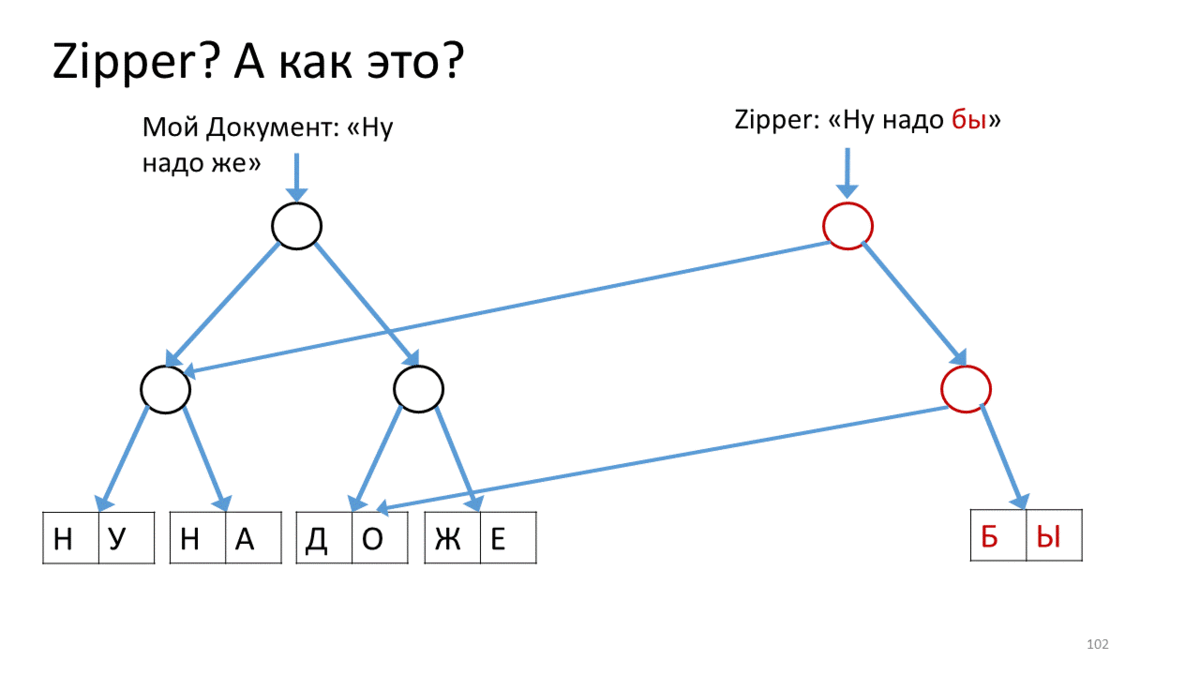 为我们的文档创建一个拉链,其中包含用于编辑的行(“好,您必须”)。我们在此Zipper上调用一个操作以沿直线移动到编辑位置。在我们的情况下,请从右上角向下移动。为此,我们创建一个与当前顶点相对应的新顶点(红色),并将链接从我们的树连接到子顶点。现在,要移动Zipper的光标,我们向下移动到右侧并创建一个新的顶点,而不是我们站立的那个顶点。同时,在顶部添加一个链接,以免忘记其来源(红色箭头)。这样就到达了编辑位置,我们创建了一个新的工作表来代替已编辑的文本(红色矩形)。现在我们回过头来,沿着红色的向上箭头,并用正确的指向子顶点的链接替换它们。当我们到达顶部时,我们将获得带有已编辑工作表的新树。注意,光标如何帮助我们编辑树的当前部分。我想向您传达什么结论?首先,很奇怪,在文本编辑器主题中,尽管有很多要求,但还是有很多有趣的事情。此外,同一主题中有时会出现新的,有时会出乎意料的发现。第三,有时它们太新了,以至于第一次都不起作用。但这很有趣,您可以保持温暖。
为我们的文档创建一个拉链,其中包含用于编辑的行(“好,您必须”)。我们在此Zipper上调用一个操作以沿直线移动到编辑位置。在我们的情况下,请从右上角向下移动。为此,我们创建一个与当前顶点相对应的新顶点(红色),并将链接从我们的树连接到子顶点。现在,要移动Zipper的光标,我们向下移动到右侧并创建一个新的顶点,而不是我们站立的那个顶点。同时,在顶部添加一个链接,以免忘记其来源(红色箭头)。这样就到达了编辑位置,我们创建了一个新的工作表来代替已编辑的文本(红色矩形)。现在我们回过头来,沿着红色的向上箭头,并用正确的指向子顶点的链接替换它们。当我们到达顶部时,我们将获得带有已编辑工作表的新树。注意,光标如何帮助我们编辑树的当前部分。我想向您传达什么结论?首先,很奇怪,在文本编辑器主题中,尽管有很多要求,但还是有很多有趣的事情。此外,同一主题中有时会出现新的,有时会出乎意料的发现。第三,有时它们太新了,以至于第一次都不起作用。但这很有趣,您可以保持温暖。谢谢啦
→ 存储库→ 邮件参考文献
Zipper data structureCRDT in Xi Editor,
Visual Studio Code editor Piece Table .
, -
.
是否需要更强大的报告,包括Java 11? 然后我们在Joker 2018等您。 今年的演讲者:Josh Long,John McClean,Marcus Hirth,Robert Scholte和其他同样出色的演讲者。 会议还剩17天。 网站上的门票 。