9月22日,我们为高负载系统的开发人员举行了第一个非标准mitap 。 这非常酷,对报告有很多正面反馈,因此不仅决定上传报告,还决定为Habr解密。 今天,我们发表来自BIT.GAMES的DevOps的Ivan Bubnov的演讲。 他谈到了Consul发现服务在已经工作的高负载项目中的实现,以实现快速扩展和状态服务故障转移的可能性。 还有关于为后端应用程序和陷阱组织灵活的名称空间的信息。 现在对伊万说几句话。我在BIT.GAMES工作室管理生产基础架构,并在我们的“英雄联盟”项目-带有用于移动设备的异步pvp的幻想RPG项目中,讲述了Hashicorp领事实施的故事。 在Google Play,App Store,三星,亚马逊上可用。 DAU约100,000,在线10到1.3万。 我们使用Unity制作游戏,因此我们使用C#编写客户端,并使用我们自己的BHL脚本语言进行游戏逻辑。 我们用Golang编写服务器部分(从PHP切换到它)。 接下来是我们项目的原理图架构。
 实际上,有更多的服务,只有游戏逻辑的基础。
实际上,有更多的服务,只有游戏逻辑的基础。所以我们有。 在无状态服务中,这些是:
- nginx,我们用作前端和负载平衡器,并通过权重系数将客户端分配到我们的后端;
- 游戏-后端,Go编译的应用程序。 这是我们架构的中心轴,他们完成了大部分工作,并与所有其他后端服务进行通信。
在有状态服务中,我们提供的主要服务有:
- Redis,我们用来缓存热门信息(我们也使用它来组织游戏中的聊天并为玩家存储通知);
- Percona Server for Mysql是持久性信息的存储库(可能是任何体系结构中最大和最慢的)。 我们使用MySQL的分支,今天我们将在这里更详细地讨论它。
在设计过程中,我们(和其他所有人一样)希望项目能够成功并提供分片机制。 它由两个MAINDB数据库实体和分片本身组成。

MAINDB是一种目录-它存储有关存储有关玩家进度的特定分片数据的信息。 因此,完整的信息检索链如下所示:客户端访问前端,然后按权重将其重新分配给后端之一,后端转到MAINDB,定位玩家的碎片,然后直接从碎片本身中选择数据。
但是,当我们设计时,我们并不是一个大项目,因此我们决定仅名义上制作碎片。 它们都位于同一台物理服务器上,并且很可能在同一服务器内进行数据库分区。
对于备份,我们使用了经典的主从复制。 这不是一个很好的解决方案(稍后再说为什么),但是该架构的主要缺点是我们所有的后端都仅通过IP地址知道其他后端服务。 而且,如果在数据中心发生另一次荒谬的事故,“
抱歉,我们的工程师在维修另一台服务器时打了您服务器上的电缆,我们花了很长时间弄清楚为什么您的服务器无法保持联系 ”,我们需要
做出很大的努力。 首先,这是从IP备份服务器重建和预安装后端,以替代失败的后端。 其次,在事件发生后,有必要从储备库的备份中还原我们的主数据库,因为他处于不一致状态,并使用相同的复制使其处于协调状态。 然后,我们再次重新组装了后端并重新加载。 当然,所有这些都会导致停机。
曾经有一段时间,我们的技术总监(我非常感谢他)说:“伙计们,别再受苦了,我们需要改变一些东西,让我们寻找出路。” 首先,如果需要,我们希望实现一个简单,易于理解且最重要的-易于管理的数据库扩展和迁移过程。 此外,我们希望通过自动化故障转移来实现高可用性。
我们研究的中心轴已由Hashicorp担任领事。 首先,我们得到了建议,其次,我们对它的简单性,友好性和出色的技术堆栈感到非常着迷:带有健康检查,键值存储和我们想使用的最重要功能的发现服务解析为我们来自service.consul域的地址的DNS。
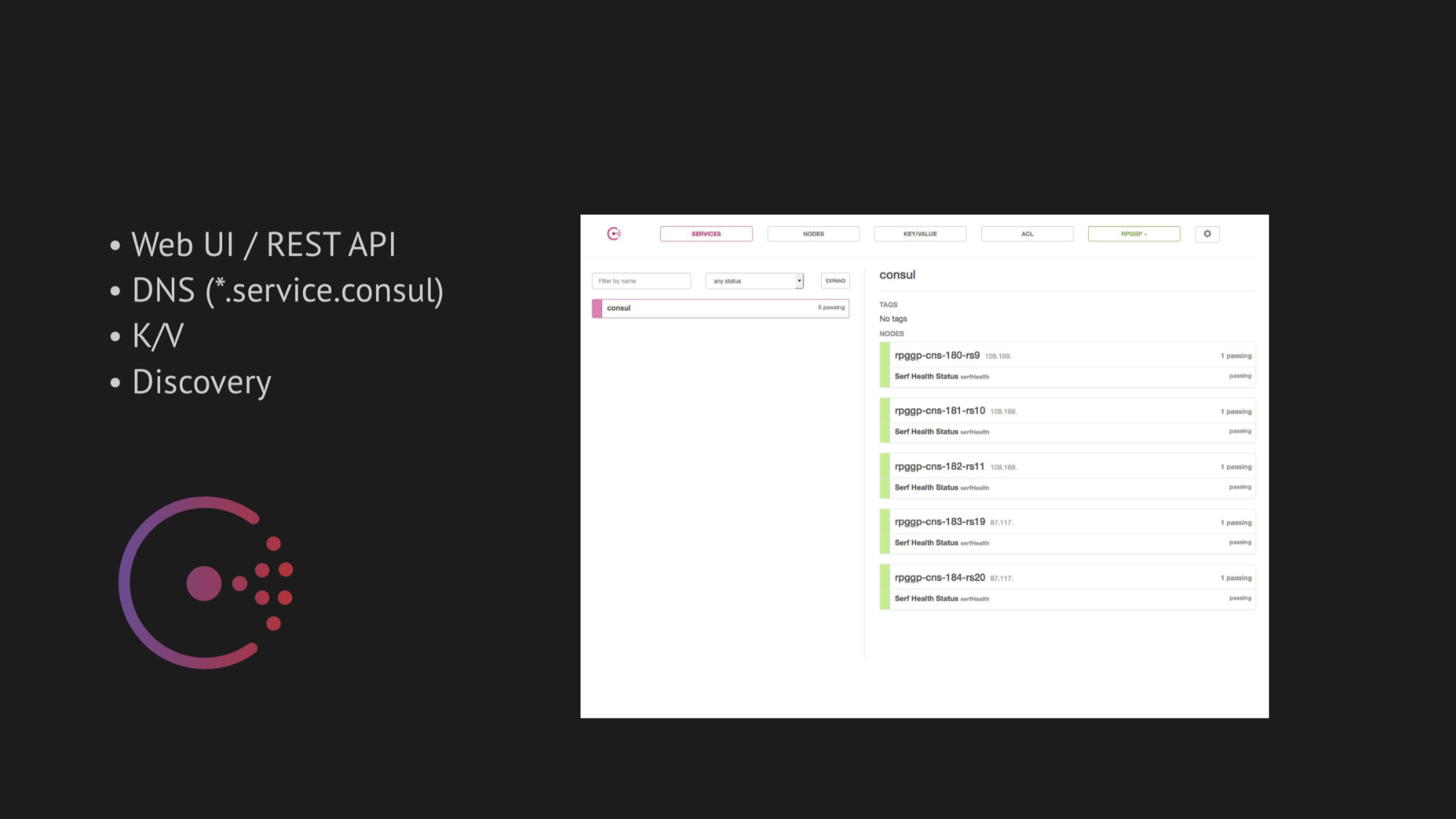
领事还提供了出色的Web UI和REST API来管理所有这些。
至于高可用性,我们选择了两个实用程序来进行自动故障转移:

对于适用于MySQL的MHA,我们将代理注入具有数据库的节点中,并监视它们的状态。 主服务器出现一定的超时,此后,停止从服务器以保持一致性,并且来自出现状态不一致的主服务器的备份主服务器未拾取数据。 然后,我们向这些代理添加了一个Web钩子,这些钩子在Consul自身中注册了备份主服务器的新IP,然后它进入了DNS的发行。
使用Redis前哨,一切都变得更加简单。 由于他本人承担了大部分工作,因此我们要做的就是在运行状况检查中考虑到Redis前哨应该仅在主节点上进行。
起初,一切工作都非常完美,就像时钟一样。 我们在测试台上没有任何问题。 但是值得进入一个已加载数据中心的自然数据传输环境中,记住一些OOM杀伤(这是内存不足,其中进程被系统核心杀死),并还原服务或影响服务可用性的更复杂的事物-我们如何立即立即面临严重的误报风险或根本没有保证的响应(如果您尝试扭曲某些支票以逃避误报的话)。

首先,一切都取决于编写正确的健康检查的难度。 看来任务很简单-检查服务是否在服务器和pingani端口上运行。 但是,如后续实践所示,在实施Consul时编写运行状况检查是一个极其复杂且耗时的过程。 因为无法预见会影响数据中心服务可用性的众多因素-仅在一定时间后才能检测到这些因素。
此外,数据中心不是您所淹没的静态结构,而是可以按预期工作。 但是,不幸的是(或幸运的是)我们只是在后来才发现了这一点,但就目前而言,我们受到鼓舞并充满信心,我们将在生产中实施所有产品。

关于扩展,我会简单地说:我们试图找到一辆成品自行车,但是它们都是针对特定架构设计的。 而且,就Jetpants而言,我们无法满足他对持久性信息存储体系结构施加的条件。
因此,我们考虑了自己的脚本绑定,并推迟了这个问题。 我们决定采取一致行动,并从实施领事开始。

Consul是一个分散的,分布式的集群,它基于八卦协议和Raft共识算法进行操作。
我们有五台服务器的独立等额服务器(五台以避免裂脑情况)。 对于每个节点,我们将Consul代理置于代理模式,并溢出所有运行状况检查(即,没有这样的情况,我们将一个运行状况检查上传到特定的服务器,而将其他运行状况检查上传到特定的服务器)。 编写了Healthcheck,以便它们仅在有服务的地方通过。
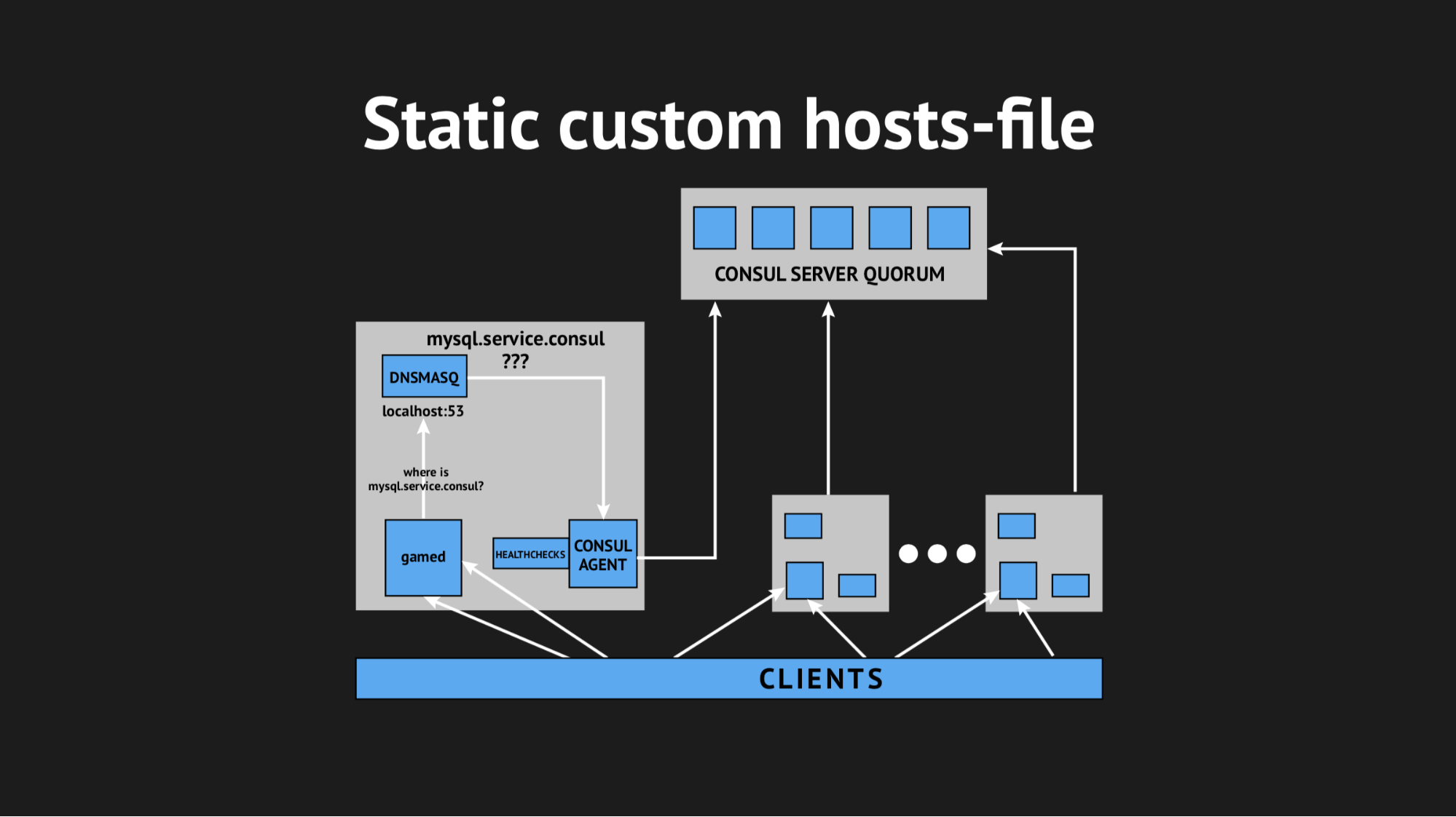
我们还使用了另一个实用程序,因此我们不必学习后端即可从非标准端口上的特定域解析地址。 我们使用了Dnsmasq-它提供了完全透明地解析所需集群节点上的地址的能力(可以说,在现实世界中,该地址不存在,但仅存在于集群中)。 我们准备了一个用于填充Ansible的自动脚本,将其全部上载到生产环境中,调整了名称空间,确保所有内容均已完成。 而且,他们不由自主地重新加载了后端,这些后端不是通过IP地址访问的,而是通过server.consul域中的这些名称访问的。
一切都是在第一时间开始的,我们的快乐无止境。 但是现在还太高兴了,因为一个小时之内,我们注意到在后端所位于的所有节点上,平均负载指标从0.7增加到1.0,这是一个相当大的指标。
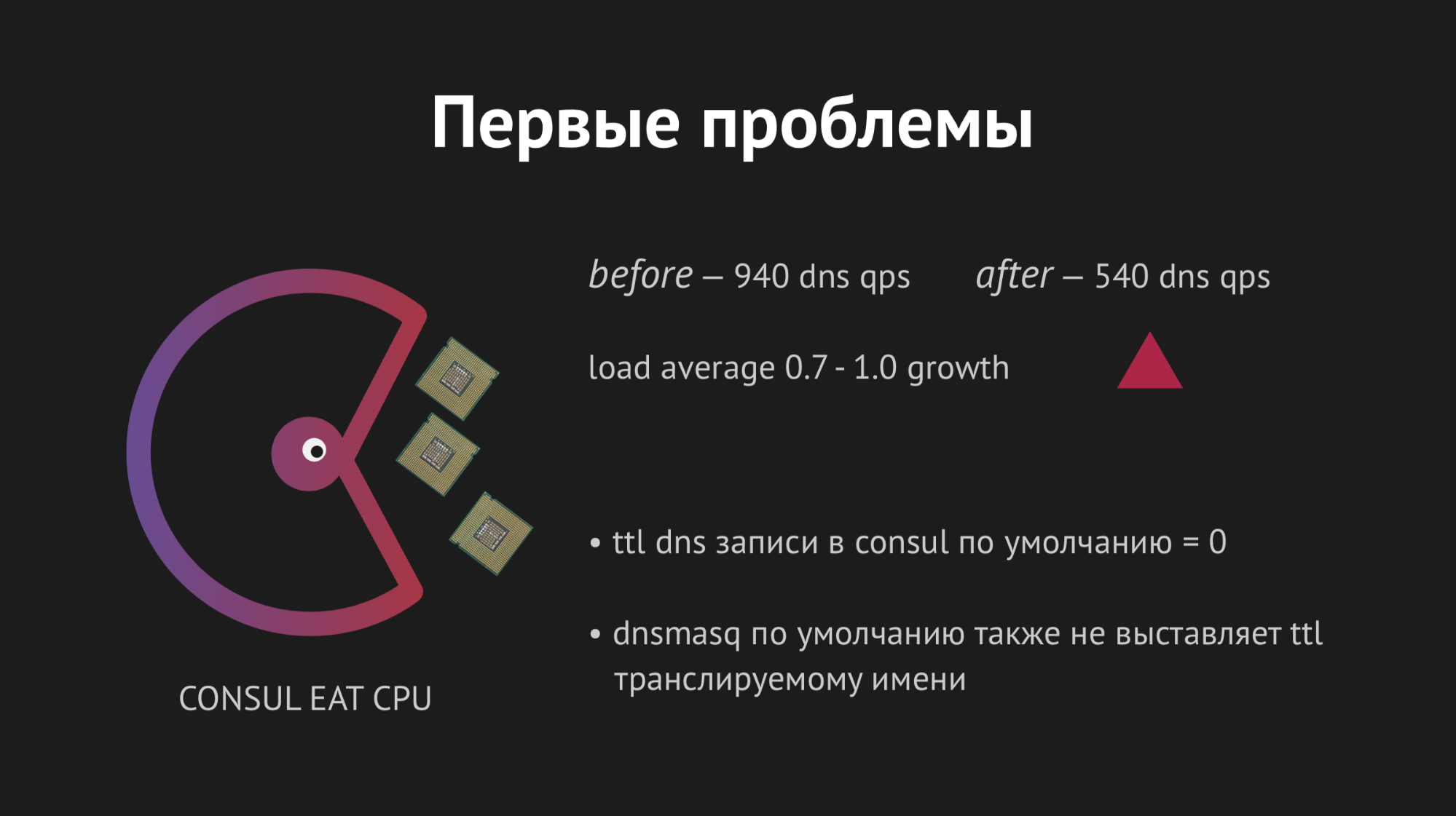
我爬上服务器以查看发生了什么,很明显,CPU正在吃Consul。 在这里,我们开始弄清楚了,开始使用strace(用于Unix系统的实用程序,可以让您跟踪正在运行的系统调用)进行萨满化处理,转储Dnsmasq统计信息以了解该节点上正在发生的情况,结果发现我们错过了一个非常重要的观点。 在进行集成计划时,我们错过了DNS记录的缓存,事实证明,我们的后端为Dnsmasq的每一次移动都拉了Dnsmasq,这又转向了Consul,所有这些每秒导致940个DNS查询。
出路似乎很明显-只要扭一下ttl,一切都会变得更好。 但是这里不可能是狂热的,因为我们想要实现这种结构以便获得动态的易于控制且快速变化的名称空间(因此,我们无法设置例如20分钟)。 我们将ttl扭曲到最大最佳值,设法将每秒查询率降低到540,但这并没有影响CPU消耗指标。
然后,我们决定使用自定义的hosts文件以棘手的方式走出去。
一切都很好,这就是Consul的出色模板系统,它基于集群的状态和模板脚本,可以生成任何类型的文件,任何您想要的配置。 另外,Dnsmasq具有addn-hosts配置参数,该参数允许您将非系统主机文件用作相同的其他主机文件。
我们所做的,再次在Ansible中准备了脚本,将其上传到生产环境中,开始看起来像这样:
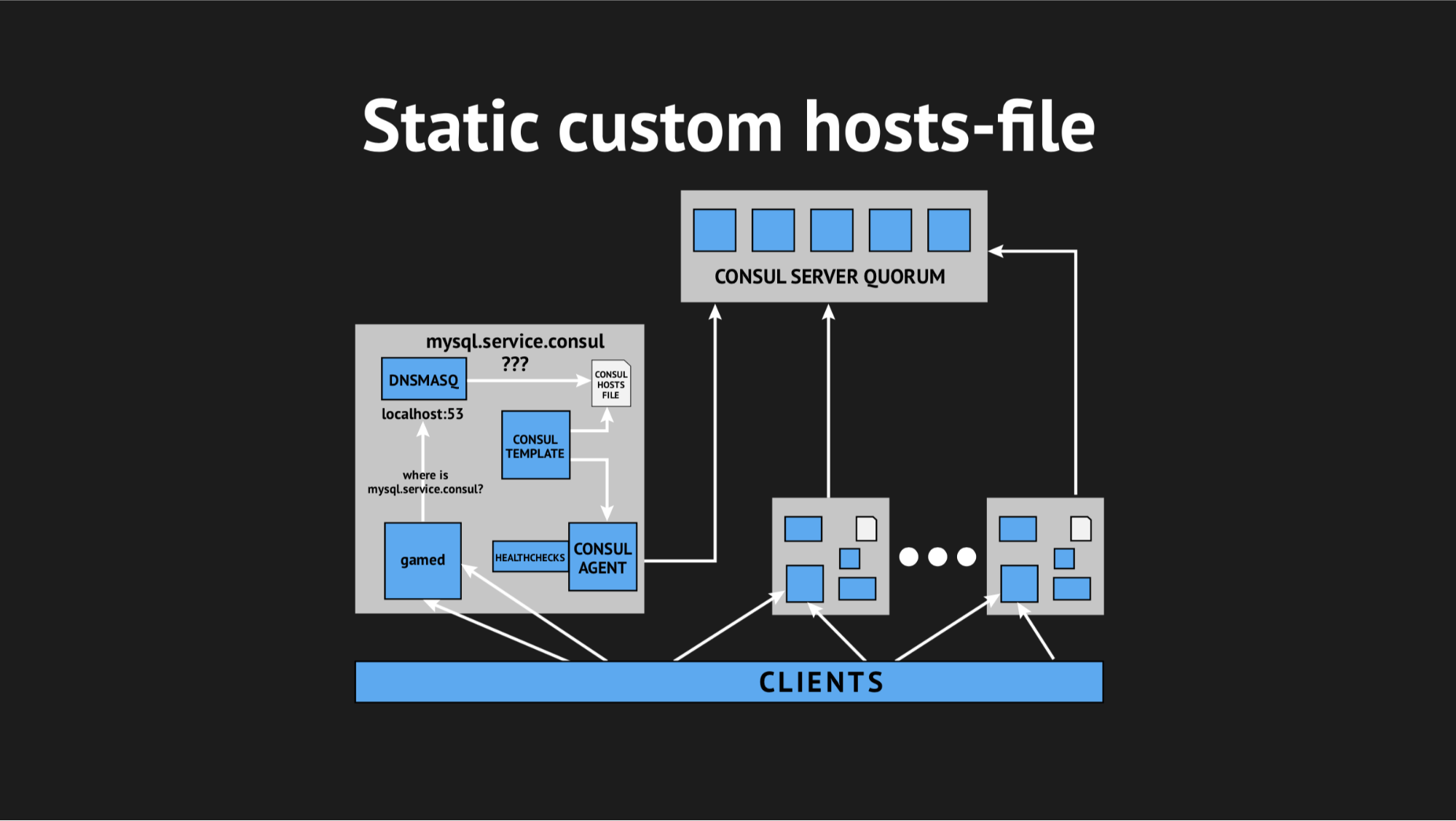
磁盘上有一个附加元素和一个静态文件,该文件可以很快重新生成。 现在,链条看起来非常简单:gamed转向Dnsmasq,然后(而不是拉Consula代理,而Consula代理会问服务器我们拥有该节点或那个节点的位置)只是查看了文件。 这解决了Consul占用CPU的问题。
现在一切似乎都像我们计划的那样-对我们的生产绝对透明,几乎不消耗资源。
那天我们遭受了极大的折磨,并充满了恐惧。 他们不怕白费力气,因为在晚上,来自监视的警报唤醒了我,并通知我我们发生了相当大的(尽管是短期的)错误。
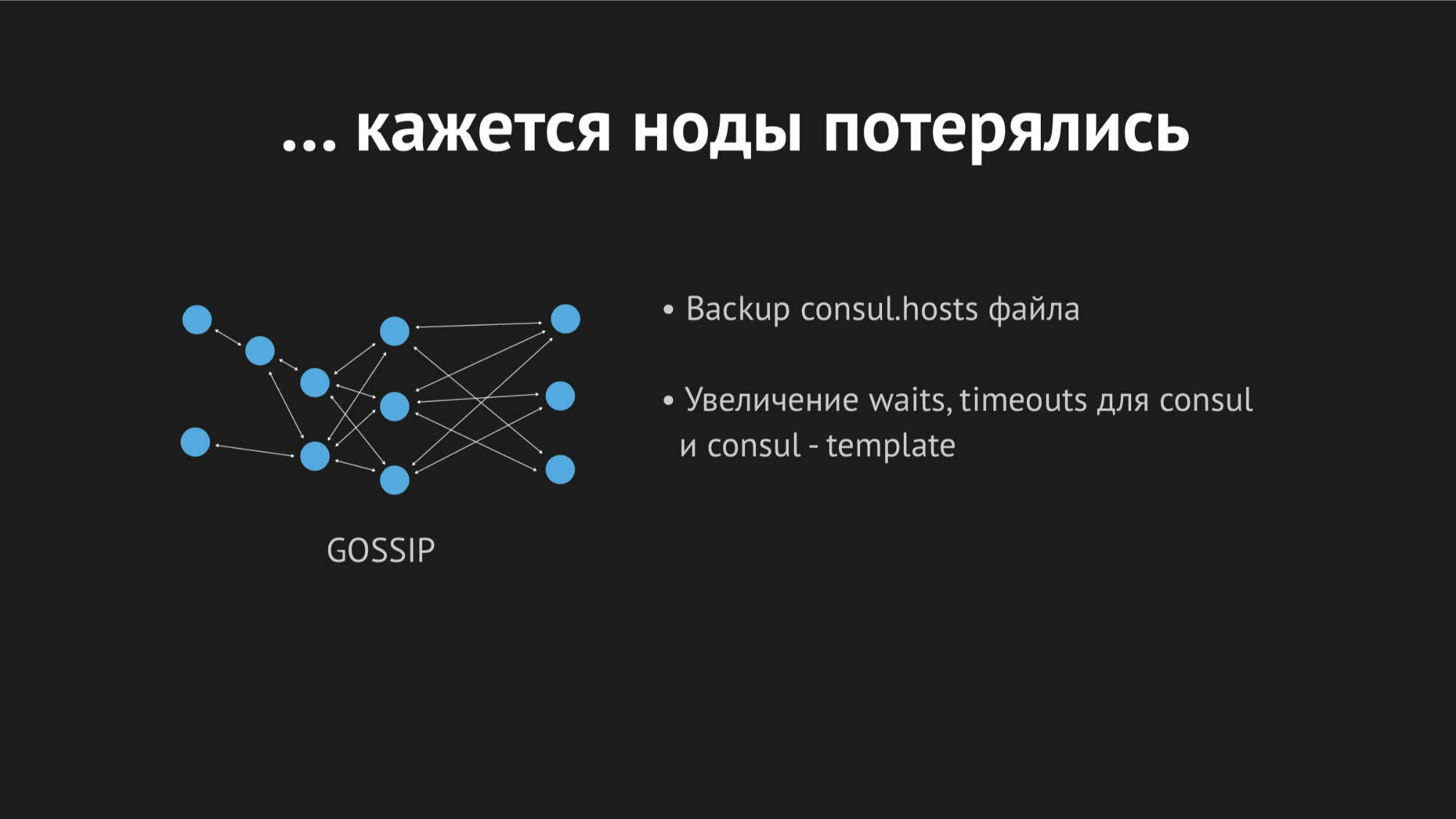
在早上处理日志时,我看到所有错误都是同一类型的未知主机。 目前尚不清楚Dnsmasq为什么不能使用文件中的一项或另一项服务-似乎根本不存在。 为了了解发生了什么,我添加了一个自定义指标来重新生成文件-现在我确切地知道了重新生成文件的时间。 另外,Consul模板本身具有出色的备份选项,即 您可以看到重新生成的文件的先前状态。
白天,该事件重复了好几次,并且很明显,在某个时间点(尽管它是偶发性的,本质上是非系统性的),将重新呈现没有任何特定服务的主机文件。 事实证明,在一个特定的数据中心(我不会做反广告)中,存在相当不稳定的网络-由于网络翻转,我们绝对无法预测地停止通过运行状况检查,甚至节点掉出集群。 它看起来像这样:
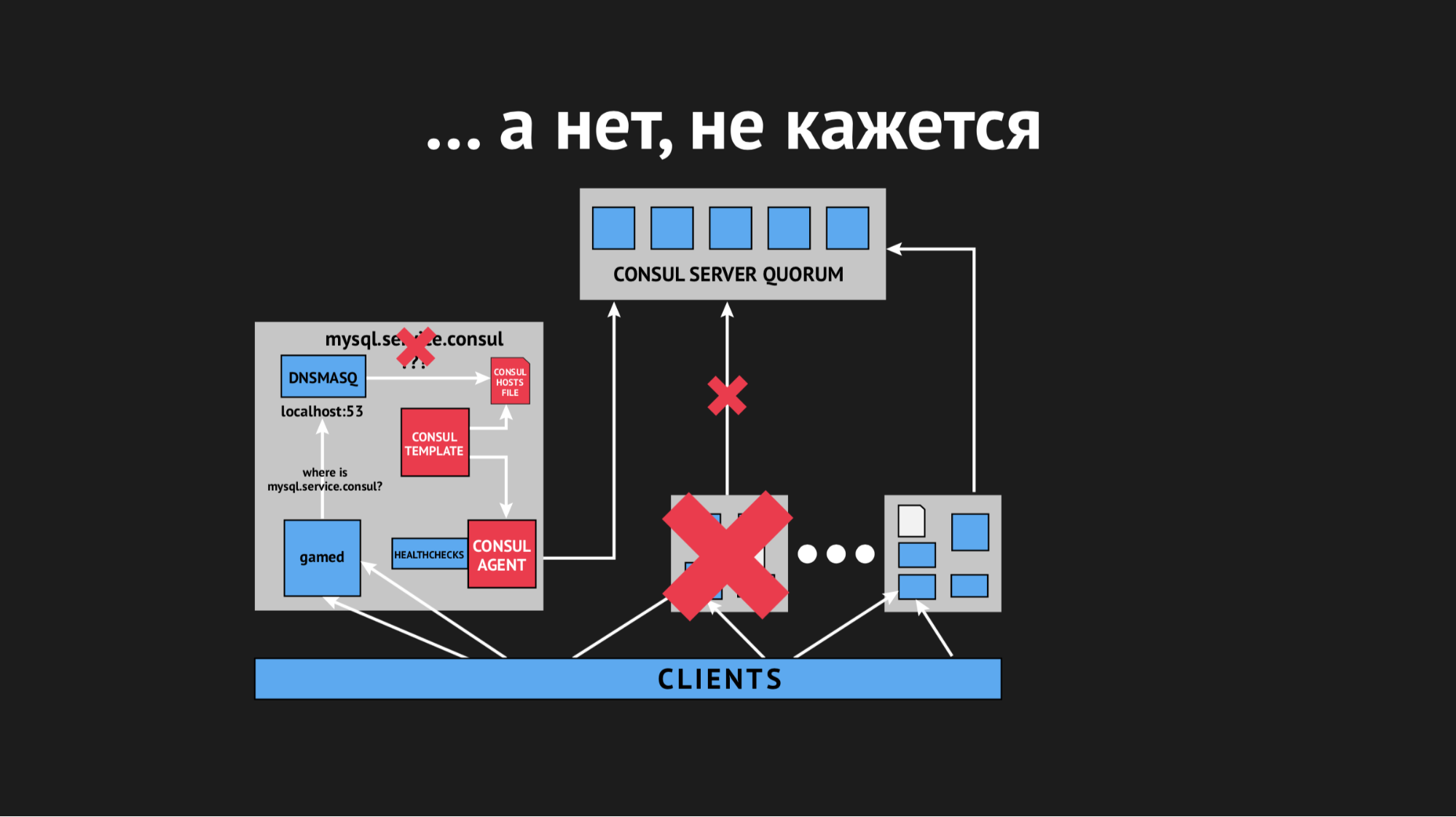
该节点脱离群集,立即通知Consul代理,并且Consul模板立即重新生成了主机文件,而无需我们需要的服务。 通常这是不可接受的,因为问题很荒谬:如果该服务几秒钟不可用,请设置超时和重新设置(它们没有连接一次,但是第二次连接了)。 但是,当服务只是从视图中消失而无法连接时,我们在卖方中激发了新的结构。
我们开始考虑该怎么做,并扭曲Consul中的timeout参数,然后在节点掉了多少之后确定它。 我们设法用一个很小的指示器解决了这个问题,节点停止掉线了,但这对运行状况检查没有帮助。
我们开始考虑为健康检查选择不同的参数,试图以某种方式了解何时以及如何发生这种情况。 但是由于所有的事情都是零星的和不可预测的,所以我们无法做到这一点。
然后,我们转到Consul模板,并决定对其进行超时,此后该模板对集群状态的变化做出反应。 再说一次,不可能狂热,因为当我们针对一个完全不同的域名时,我们可能会遇到结果不会比传统DNS更好的情况。
然后,我们的技术总监再次进行救援:“伙计们,让我们试着放弃所有这些交互性,我们拥有生产中的一切,我们没有时间进行研究,我们需要解决这个问题。 让我们利用简单易懂的东西。” 因此,我们想到了使用键值存储作为生成主机文件的源的概念。
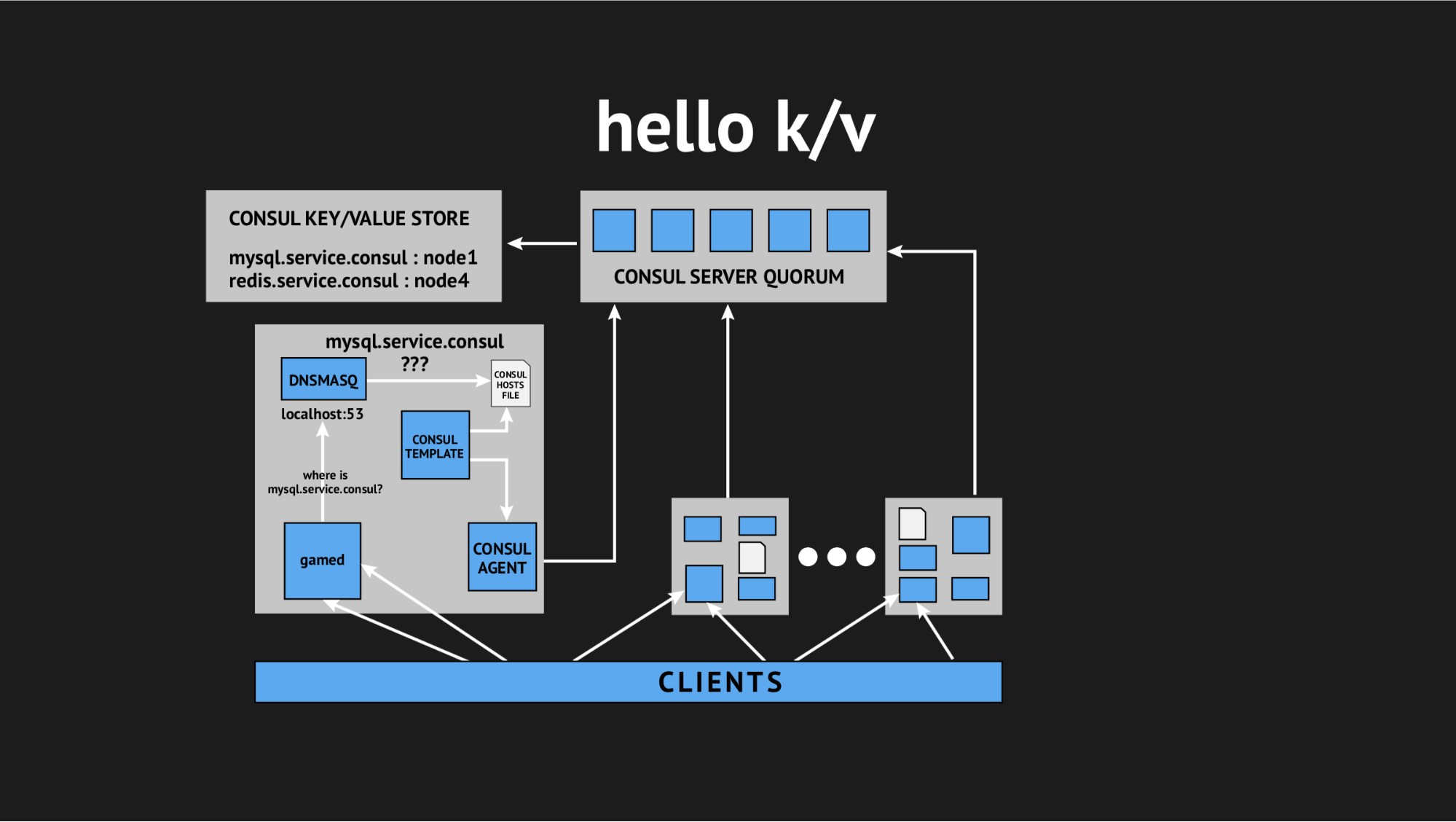
外观:我们拒绝所有动态运行状况检查,重写我们的模板脚本,以便它根据键值存储中记录的数据生成一个文件。 在键值存储中,我们以键名(这是我们需要的服务的名称)和键值(这是集群中节点的名称)的形式描述整个基础架构。 即 如果该节点位于群集中,则我们很容易获得其IP地址并将其写入主机文件。
我们测试了所有内容,并在生产中投入使用,在特定情况下,它变成了万灵药。 再次,我们整天都饱受折磨,但回到家后已经休息了,充满了热情,因为这些问题不再发生,并且在提交中已经一年没有重复了。 我个人由此得出结论,这是正确的决定(特别是对我们而言)。
这样啊 最终,我们得到了想要的东西,并为后端组织了一个动态名称空间。 此外,我们致力于确保高可用性。

但是事实是,非常害怕Consul集成,并且由于我们遇到的问题,我们认为并认为引入自动故障转移并不是一个很好的解决方案,因为我们再次冒着误报或失败。 此过程是不透明且不可控制的。
因此,我们走了一条简单(或复杂)的道路:我们决定让值班管理员凭良心进行故障转移,但又给了他另一个工具。 在只读模式下,我们已将主从复制替换为主从复制。 这消除了故障转移过程中的大量麻烦-当您获得向导时,您需要做的就是使用Web UI或API中的命令更改k / v存储中的值,然后再删除只读模式。备份主机。
事件结束后,主机将自动联系并进入协调状态,而无需执行任何不必要的操作。 我们停止使用此选项,并像以前一样使用它-对我们来说,它尽可能方便,最重要的是尽可能简单,清晰和可控制。
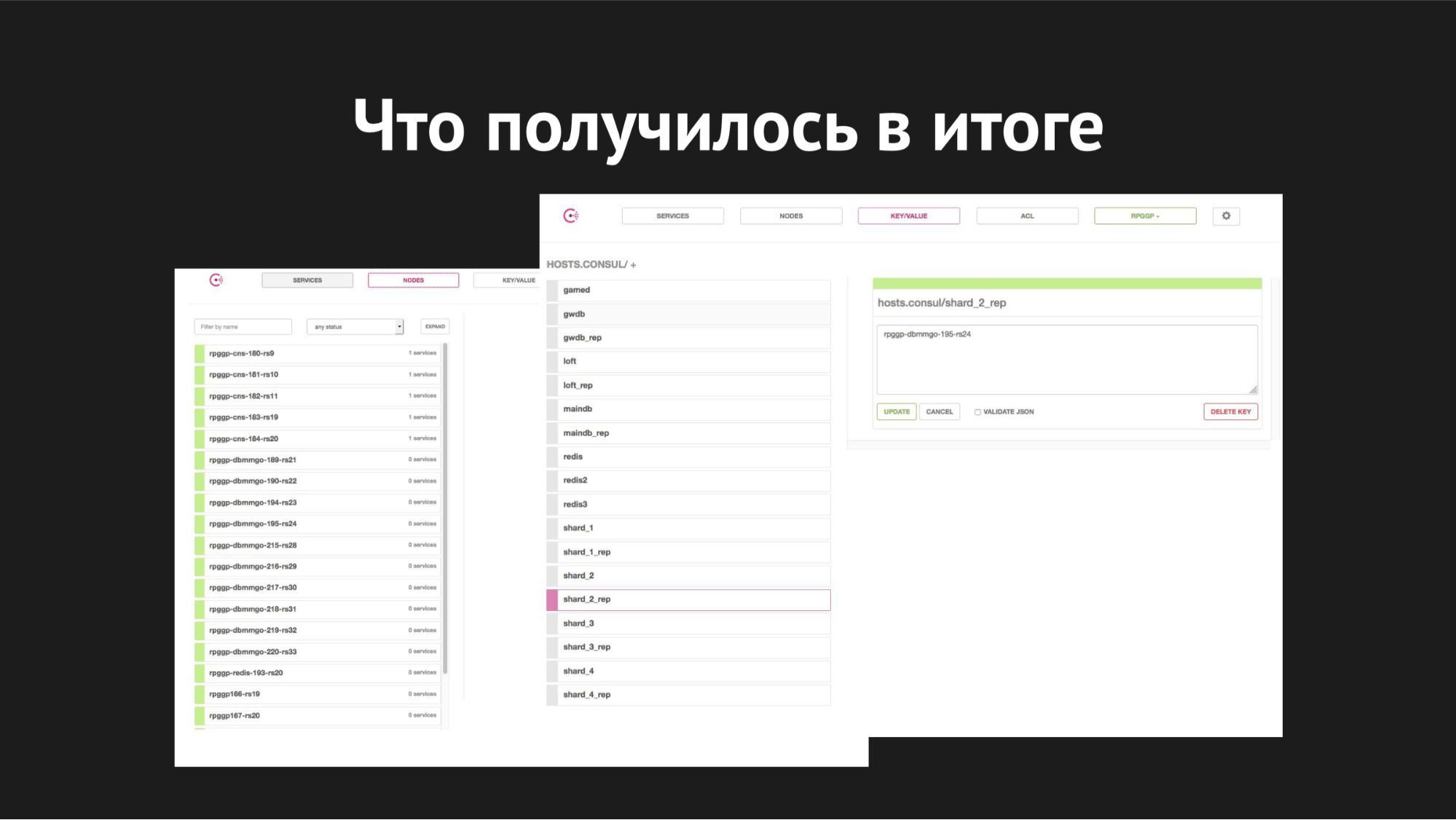 领事Web界面
领事Web界面右边是k / v存储,可见我们的服务,我们可以在游戏中使用它。 value是节点的名称。
至于扩展,我们开始在分片已经在一台服务器上拥挤,基础增长,变慢,播放器数量增加,交换时开始实施它,我们的任务是将所有分片分配到不同的单独服务器上。

外观:使用XtraBackup实用程序,我们在一对新服务器上还原了备份,之后,新的主服务器与旧的从服务器挂在了一起。 进入一致状态,我们将k / v-storage中的键值从旧主节点的节点名称更改为新主节点的节点名称。 然后(当我们认为一切正常,并且所有选择,更新,插入的游戏都交给了新的主服务器时),我们只需要终止复制并将令人垂涎的Drop数据库投入生产,因为我们都喜欢使用不必要的数据库。

这样我们就碎片化了。 迁移的整个过程从40分钟缩短到一个小时,并且没有造成任何停机时间,它对我们的后端是完全透明的,并且对玩家来说是完全透明的(除非他们移动后就变得更加轻松愉快)。

对于故障转移过程,此处的切换时间为20到40秒,加上值班系统管理员的反应时间。 那就是我们现在的样子。
最后,我想说的是-不幸的是,我们对绝对,全面的自动化的希望已经落入了负载数据中心中数据传输介质的苛刻现实,以及我们无法预见的随机因素。
其次,它再次告诉我们,系统管理员手中一个简单且经过验证的山雀要比云端以外的新型自反应式,自缩放式起重机好,甚至您都不知道它是在散落,还是真的开始扩大规模。
在生产中引入任何基础设施和自动化,都不会给服务它的员工造成不必要的麻烦; 它不应显着增加维护基础结构生产的成本-解决方案应简单,清晰,对客户透明,方便且可控制。
听众的提问
您如何用服务器编写k / v-脚本,还是只是打补丁?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . 即 , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks