哈ha
“魔术方块”的主题非常有趣,因为 一方面,它们自古以来就广为人知,另一方面,即使在今天,“魔方”的计算也是一项非常困难的计算任务。 回想一下,要构造一个“魔方” NxN,您需要输入数字1..N * N,以使其水平,垂直和对角线的总和等于相同的数字。 如果您简单地将所有选项的数目分类为4x4正方形,我们得到16! = 20,922,789,888,000期权。
考虑如何更有效地完成此操作。

首先,我们重复问题的条件。 您需要将数字排列成正方形,以免重复,并且轮廓,垂直线和对角线的总和等于相同的数字。
很容易证明这个总和始终是相同的,并且可以通过任何n的公式计算得出:
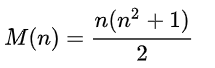
我们将考虑4x4正方形,因此总和= 34。
用X表示所有变量,我们的平方将如下所示:
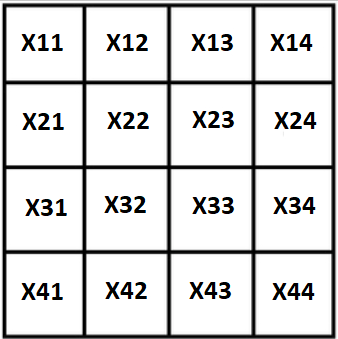
第一个也是显而易见的属性: 平方和是已知的,极端的脚步声可以通过剩余的3表示:
X14 = S - X11 - X12 - X13
X24 = S - X21 - X22 - X23
...
X41 = S - X11 - X21 - X31因此,一个4x4的正方形实际上变成了一个3x3的正方形,这使搜索选项的数量从16个减少了! 最多9! 5700万次。 知道了这一点,我们开始编写代码,看看对现代计算机进行如此详尽的搜索是多么复杂。
C ++-单线程版本
该程序的原理非常简单。 我们采用数字1..16的集合,并且对该集合进行for循环,它将为x11。 然后,我们采用第二组,除了数字x11外,由第一组组成,依此类推。
该程序的近似形式如下所示:
int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; ... int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue;
程序的全文可以在扰流板下面找到。
整个来源 #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
结果:总共找到
7040个 4x4“魔方”
选项 ,搜索时间为
102s 。

顺便说一句,检查正方形列表是否包含与Durer雕刻相同的正方形,这很有趣。 当然有,因为 程序显示
所有 4x4正方形:
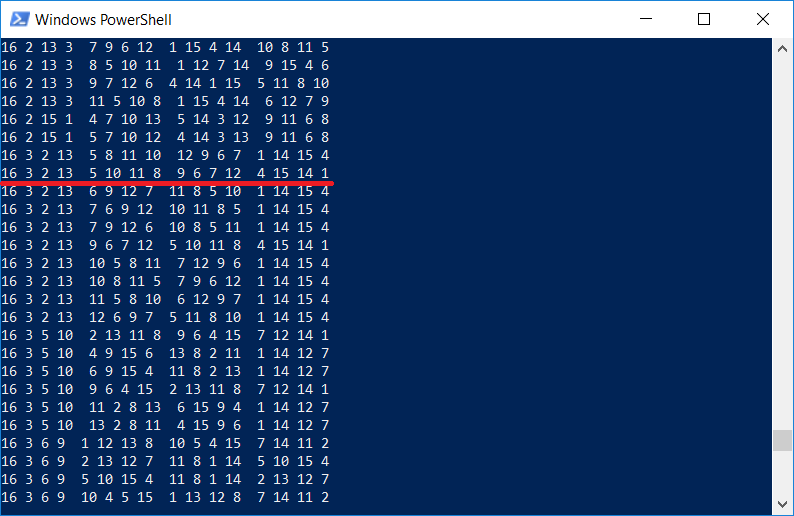
应当注意,Dürer出于某种原因在图像中插入了一个正方形,数字
1514也表示雕刻的年份。
如您所见,该程序可以工作(我们将任务标记为AlbrechtDürer在1514验证过;),但是对于配备Core i7处理器的计算机,执行时间并不短。 显然,该程序在单个线程中运行,建议使用所有其他内核。
C ++-多线程版本
使用流重写程序基本上很简单,尽管有点麻烦。 幸运的是,今天有一个几乎被遗忘的选项-使用对
OpenMP (开放式多处理)的支持。 该技术自1998年以来就存在,它允许处理器指令告诉编译器并行运行程序的哪些部分。 Visual Studio还支持OpenMP,因此要将程序变成多线程,只需在代码中添加一行即可:
int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { ... } printf("CNT: %d\n", squares);
指令#pragma omp parallel for表示可以并行执行下一个for循环,并且其他参数方块设置变量名,这对于并行线程是通用的(如果不这样做,增量将无法正常工作)。
结果很明显:执行时间从102s减少到
18s 。

整个来源 #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
这样好多了-因为 任务几乎完美并行化(每个分支中的计算彼此独立),时间少于等于处理器内核数量的次数。 但可惜
的是 ,虽然可以通过某些优化获得并获得百分之几的收益,但不可能从此代码中获得更多收益。 我们传递给重型火炮,在GPU上进行计算。
使用NVIDIA CUDA进行计算
如果您不详细介绍,则可以将在视频卡上执行的计算过程表示为几个并行的硬件块(块),每个硬件块执行多个过程(线程)。
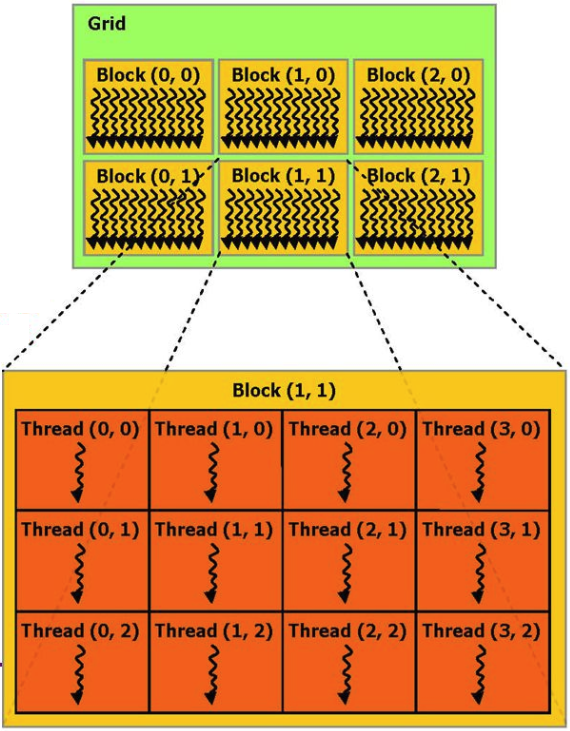
例如,我们可以举一个CUDA文档中添加两个向量的功能示例:
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
数组x和y对于所有块都是公用的,因此函数本身同时在多个处理器上同时执行。 这里的关键是并行性-视频卡处理器比常规CPU简单得多,但是其中有很多,并且它们专门针对数字数据的处理。
这就是我们所需要的。 我们有一个数字矩阵X11,X12,..,X44。 让我们开始16个块的过程,每个块将执行16个过程。 程序段号将与编号X11对应,过程号将与编号X12对应,并且代码本身将为所选X11和X12计算所有可能的平方。 这很简单,但有一个微妙之处-数据不仅需要计算,而且还需要从视频卡传回,为此,我们将存储在数组零元素中找到的平方数。
主要代码非常简单:
#define N 4 #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) int main(int argc,char *argv[]) { const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
我们使用cudaMalloc在视频卡上选择存储块,运行squares函数,指示2个参数16.16(块数和线程数)对应于迭代的数字1..16,然后通过cudaMemcpy复制数据。
squares函数本身本质上是重复上一部分的代码,所不同的是,找到的平方数的增量是使用atomicAdd完成的-这确保了变量在同时调用期间会正确更改。
结果不需要注释-执行时间为
2.7 s ,比初始单线程版本好30倍:

如评论中所建议,您可以使用视频卡的更多硬件块,因此尝试了256个块的选项。 更改代码非常简单:
__global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX; ... } squares<<<MAX*MAX, 1>>>(gpu_out);
这样又将时间减少了2倍,至
1.2s 。 此外,在每个块上,可以启动16个过程,这给出了
0.44s的最佳时间。
最终代码 #include <stdio.h> #include <ctime> #define N 4 #define MAX (N*N) #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) #define S 34 // Magic square: // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 __global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX, index3 = threadIdx.x; if (index1 + 1 > MAX || index2 + 1 > MAX || index3 + 1 > MAX) return; const int x11 = index1+1, x12 = index2+1, x13 = index3+1; if (x13 == x11 || x13 == x12) return; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) return; if (x14 == x11 || x14 == x12 || x14 == x13) return; for(int x21=1; x21<=MAX; x21++) { if (x21 == x11 || x21 == x12 || x21 == x13 || x21 == x14) continue; for(int x22=1; x22<=MAX; x22++) { if (x22 == x11 || x22 == x12 || x22 == x13 || x22 == x14 || x22 == x21) continue; for(int x23=1; x23<=MAX; x23++) { int x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x23 == x11 || x23 == x12 || x23 == x13 || x23 == x14 || x23 == x21 || x23 == x22) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; for(int x31=1; x31<=MAX; x31++) { if (x31 == x11 || x31 == x12 || x31 == x13 || x31 == x14 || x31 == x21 || x31 == x22 || x31 == x23 || x31 == x24) continue; for(int x32=1; x32<=MAX; x32++) { if (x32 == x11 || x32 == x12 || x32 == x13 || x32 == x14 || x32 == x21 || x32 == x22 || x32 == x23 || x32 == x24 || x32 == x31) continue; for(int x33=1; x33<=MAX; x33++) { int x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x33 == x11 || x33 == x12 || x33 == x13 || x33 == x14 || x33 == x21 || x33 == x22 || x33 == x23 || x33 == x24 || x33 == x31 || x33 == x32) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; const int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x44 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; // Square found: save in array (MAX numbers for each square) int p = atomicAdd(res_array, 1); if (p >= SQ_MAX) continue; int i = MAX*p + 1; res_array[i] = x11; res_array[i+1] = x12; res_array[i+2] = x13; res_array[i+3] = x14; res_array[i+4] = x21; res_array[i+5] = x22; res_array[i+6] = x23; res_array[i+7] = x24; res_array[i+8] = x31; res_array[i+9] = x32; res_array[i+10] = x33; res_array[i+11] = x34; res_array[i+12]= x41; res_array[i+13]= x42; res_array[i+14] = x43; res_array[i+15] = x44; // Warning: printf from kernel makes calculation 2-3x slower // printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); } } } } } } } int main(int argc,char *argv[]) { int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX*MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
最有可能的是,这远非理想,例如,您可以在GPU上运行更多的块,但这将使代码更加混乱且难以理解。 当然,计算并不是“免费的”-加载GPU后,Windows界面开始明显减速,计算机的功耗从65瓦增加到130瓦,几乎增加了2倍。
编辑 :正如
Bodigrim用户在评论中所建议的,一个4x4正方形具有另一个相等性:4个“内部”单元的总和等于“外部”单元的总和,也为S。

X22 + X23 + X32 + X33 = X11 + X41 + X14 + X44 = S通过通过其他变量表达一些变量并删除另外的1-2个嵌套循环,可以加快算法的速度;可以在下面的注释中找到代码的更新版本。结论
发现“魔方”的任务在技术上非常有趣,同时也很困难。即使在GPU上进行计算,对所有5x5平方的搜索也可能需要花费几个小时,寻找7x7和更高尺寸的幻方的优化仍然有待完成。在数学和算法上,还有几个未解决的问题:- « » N. 22 , 33 8 ( 1, ), 44 , 7040, . .
- , .
- . , NVIDIA Tesla , - , . , . , ;)
如果有兴趣的话,可以写一篇关于魔术方块本身的分析和属性的单独文章。PS:对于可能出现的问题,“为什么这是必要的”。在功耗方面,计算魔术平方不会比计算比特币更好或更糟,那为什么不呢?另外,它对于头脑来说是一种有趣的锻炼,并且在应用编程领域中是一项有趣的任务。