安然公司是2000年代美国商业界最著名的人物之一。 这不是因为他们的活动范围(电力和供应合同),而是由于欺诈而引起的共鸣。 在过去的15年中,公司收入迅速增长,并且从事其中的工作保证了不错的薪水。 但是,一切都以同样的短暂结束:在2000-2001年期间。 由于披露了带有申报收入的欺诈行为,其股价从90美元/股跌至几乎为零。 从那时起,“安然”一词已成为家喻户晓的字眼,并以类似的方式充当了公司的标签。
在审判过程中,有18人(包括本案中最大的被告:安德鲁·法斯托夫,杰夫·斯基林和肯尼思·莱)被定罪。
](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
同时,发布了公司员工之间的电子信件存档,即众所周知的Enron电子邮件数据集,以及有关该公司员工收入的内部信息。
本文将检查这些数据的来源,并基于该数据建立模型,以确定是否有人怀疑有欺诈行为。 听起来很有趣? 然后,欢迎来到哈布拉卡特。
数据集描述
安然数据集(数据集)是一组开放数据的组合,包含具有相应名称的在难忘的公司工作的人员的记录。
它可以区分3个部分:
- Payments_features-一个描述财务变动特征的组;
- stock_features-反映与股票相关的迹象的组;
- email_features-一个以汇总形式反映有关特定人的电子邮件信息的组。
当然,还有一个目标变量指示该人是否涉嫌欺诈( “ poi”标志)。
下载我们的数据并开始使用它们:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
之后,我们将data_dict设置为Pandas数据框,以更方便地处理数据:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
我们按照前面指出的类型对标志进行分组。 这应该有助于以后处理数据:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
财务数据
在此数据集中,有许多人都知道的NaN,它表示数据中通常存在的间隙。 换句话说,数据集的作者找不到与数据框中特定行关联的特定属性的任何信息。 结果,我们可以假设NaN为0,因为没有关于特定性状的信息。
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
资料验证
与原始数据集的原始PDF进行比较时,结果表明数据略有失真,因为并非对于付款 数据框中的所有行,total_payments字段都是此人的所有财务交易的总和。 您可以如下验证:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

我们发现BELFER ROBERT和BHATNAGAR SANJAY的付款金额不正确。
您可以通过将错误行中的数据左移或右移并重新计算所有付款的总和来解决此错误:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
库存数据
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
在这种情况下,也请执行验证检查:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

我们将类似地修复库存中的错误:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
电子邮件通讯
如果对于这些财务或股票,NaN等于0,并且这适合于每个组的最终结果,那么对于电子邮件,NaN更合理地替换为某些默认值。 为此,您可以使用Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
同时,我们将分别考虑每个类别的默认值(无论我们是否怀疑有人欺诈):
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
校正后的最终数据集:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
排放物
在此阶段的最后一步,我们将删除所有可能使训练失真的异常值。 同时,总是出现一个问题:我们可以从样本中删除多少数据,而作为训练模型仍不会丢失? 我遵循了有关Udacity的ML(机器学习)课程中一位讲师的建议-“删除10,然后再次检查排放。”
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
同时,我们不会删除异常记录和涉嫌欺诈的记录。 原因是只有18行包含此类数据,我们不能牺牲它们,因为这可能会导致缺少训练示例。 结果,我们仅删除了那些不涉嫌欺诈的人,但同时具有大量观察到排放的迹象:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
定稿
我们标准化我们的数据:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
让我们将目标变量定位到兼容视图:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

结果,有18名犯罪嫌疑人和121名未受到怀疑的人。
功能选择
选择任何重要模型之前,学习任何模型的最关键点之一可能是。
多重共线性测试
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
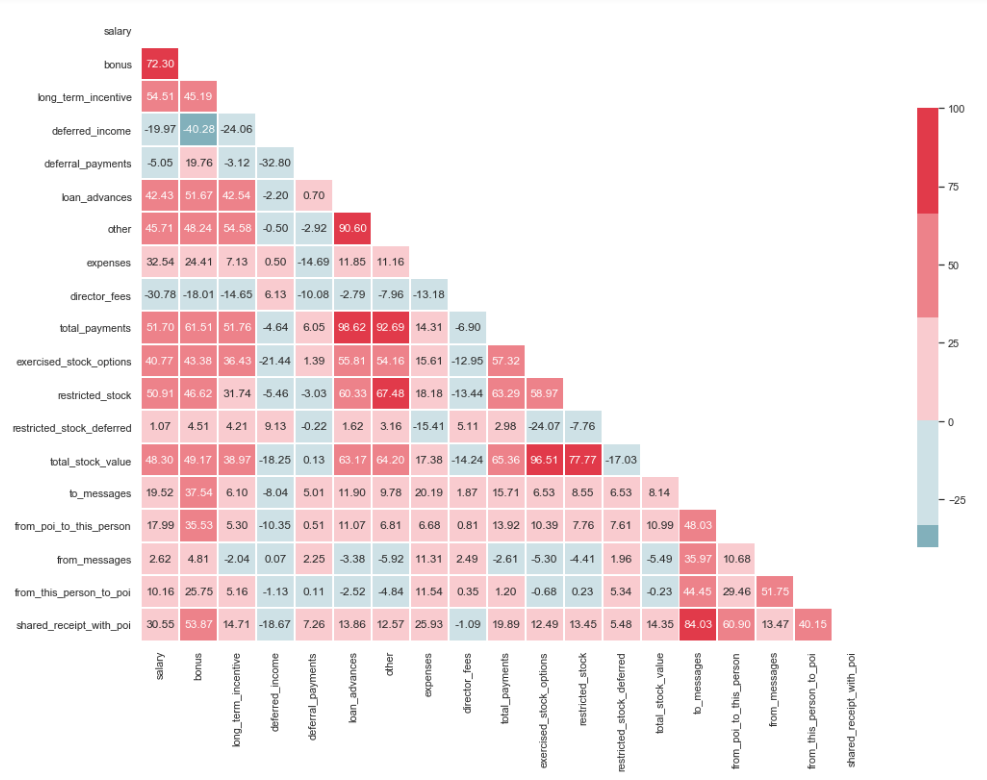
从图像中可以看到,“ loan_advanced”和“ total_payments”之间以及“ total_stock_value”和“ restricted_stock”之间具有明显的关系。 如前所述,“ total_payments”和“ total_stock_value”只是将特定组中所有指标相加的结果。 因此,可以将其删除:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
创造新特征
还有一种假设,即犯罪嫌疑人写给同伙的频率要比不参与此事的雇员更多。 因此,此类消息的比例应大于发给普通员工的消息的比例。 根据此语句,您可以创建新的标志,以反映与嫌疑犯相关的传入/传出百分比:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
筛选出不必要的标志
在与ML相关的人员的工具包中,有许多出色的工具可用于选择最重要的功能(SelectKBest,SelectPercentile,VarianceThreshold等)。 在这种情况下,将使用RFECV,因为它包括交叉验证,它使您可以计算最重要的功能并在样本的所有子集上进行检查:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
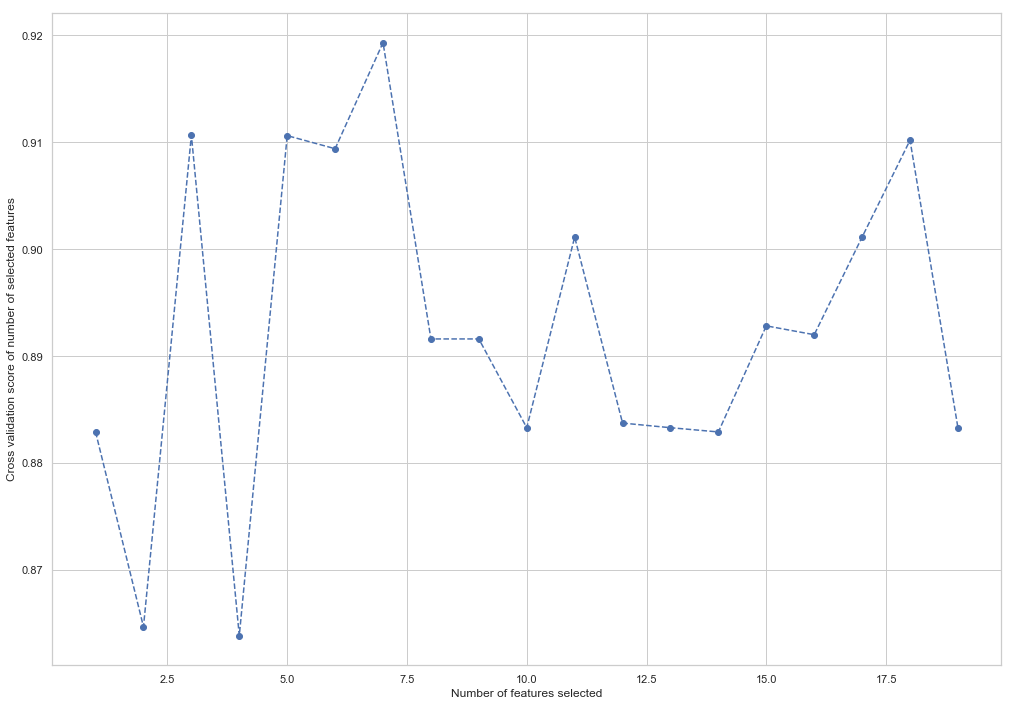
如您所见,RandomForestClassifier计算出18个属性中只有7个很重要。 使用其余部分会导致模型准确性下降。
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
未来将使用以下7个功能,以简化模型并降低重新培训的风险:
- 红利
- 递延收入
- 其他
- exercise_stock_options
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
更改训练和测试样本的结构以用于将来的模型训练:
X_train = X_train[columns] X_test = X_test[columns]
这是第一部分的结尾,该部分描述了将Enron数据集用作ML中的分类任务的示例。 基于Udacity的机器学习入门课程的材料。 还有一个python笔记本,反映了整个动作序列。
第二部分在这里