今天的对话主题是Python多年来在处理图像方面所学到的东西。 确实,除了1990年的ImageMagick和GraphicsMagick的老歌外,还有现代有效的库。 例如,枕头和生产力更高的枕头SIMD。 他们在莫斯科Python的活跃开发人员Alexander Karpinsky(
homm )比较了使用Python处理图像的不同库,提供了基准测试并谈到了始终足够的非显而易见的功能。 在本文中,报告的笔录将帮助您为应用程序选择一个库,并使其尽可能高效地工作。
关于演讲者: Alexander Karpinsky在
Uploadcare工作,从事即时图像快速修改的服务。 他参与了
Pillow的开发,
Pillow是使用Python处理图像的流行库,并且正在开发该库的自己的
Pillow-SIMD分支,该库使用现代处理器指令来实现最佳性能。
背景知识
Uploadcare的图像修改服务是一台服务器,它接收带有图像标识符的HTTP请求以及客户端需要执行的某些操作。 服务器必须完成操作并尽快做出响应。 客户端最常充当浏览器。
整个服务可以描述为图形库的包装。 整个项目的质量取决于图形库的质量,性能和可用性。 很容易猜到Uploadcare使用Pillow作为图形库。
图书馆
我们将简要回顾一下Python通常使用哪种图形库,以更好地理解以后将要讨论的内容。
抱枕
枕头 -PIL(Python影像库)的叉子。 这是一个非常老的项目,于1995年针对Python 1.2发布。 你可以想象他多大了! 在某个时候,Python Imaging Library被放弃了,它的开发停止了。 制作了Pillow的一个分支,用于在现代系统上安装和构建Python Imaging Library。 渐渐地,人们在Python Imaging Library中需要进行的更改数量增加了,Pillow 2.0出现了,它增加了对Python 3的支持。这可以看作是Pillow项目另一个独立生命的开始。
Pillow是Python的本机模块,一半代码是用C编写的,一半是用Python编写的。 支持最广泛的Python版本:2.7、3.3 +,PP,。
枕头SIMD
这是我在2016年5月推出的Pillow叉子。 SIMD代表单指令,多数据
-一种方法,其中处理器可以使用现代指令在每个周期执行更多的动作。
当项目开始过自己的生活时,
Pillow-SIMD并不是传统意义上的叉子。 这是Pillow的替代品,也就是说,您安装一个库而不是另一个库,不要在源代码中更改行,并获得更高的性能。
枕头SIMD可以与SSE4指令组装(默认)。 这是几乎所有现代x86处理器中都可以找到的一组指令。 枕头SIMD也可以与AVX2指令集一起组装。 这套说明从Haswell架构开始,即大约从2013年开始。
Opencv的
您可能听说过的另一个使用Python处理图像的库是
OpenCV (开放计算机视觉)。 自2000年以来一直在工作。 包含Python绑定。 这意味着绑定始终是相关的,库本身与绑定之间没有同步。
不幸的是,PyPy尚不支持该库,因为OpenCV基于numpy,并且numpy仅在PyPy下才开始工作,而在OpenCV中仍不支持PyPy。
VIPS
另一个值得关注的图书馆是VIPS。
VIPS的主要思想是您无需将整个图像加载到内存中即可使用该图像。 该库可以加载一些小片段,对其进行处理并保存。 因此,要处理千兆像素的图像,您不需要花费千兆字节的内存。
这是一个相当古老的图书馆-1993年,但是它已经超过了它的时间。 长期以来,人们对此知之甚少,但最近开始出现针对不同语言的VIPS活页夹,包括Go,Node.js和Ruby。
很长一段时间以来,我都想尝试一下这个库,但是由于非常愚蠢的原因,我没有成功。 我无法弄清楚如何安装VIPS,因为绑定非常复杂。 但是现在(2017年),vips本身的作者释放了pyvips绑定,不再存在任何问题。 现在,安装和使用VIPS非常容易。 支持:Python 2.7、3.3 +,RuPu,RuPuZ。
ImageMagick和GraphicsMagick
如果我们谈论使用图形,那么我们不禁要提及老人们
-ImageMagick和
GraphicsMagick库。 后者最初是ImageMagick的一个分支,具有更高的性能,但现在它们的性能似乎是相等的。 据我所知,它们之间没有其他根本区别。 因此,您可以使用任何更精确的偏好设置。
这些是我今天(1990年)提到的最古老的图书馆。 在这段时间里,有许多用于Python的活页夹,到目前为止,几乎所有活页夹都已经安全地死了。 在可以使用的那些中,有:
- Wand绑定,它基于ctypes,但也不再更新。
- pgmagick绑定使用Boost.Python,因此编译时间很长,在PyPy中不起作用。 但是,尽管如此,您仍然可以使用它,我想说它比Wand更可取。
性能表现
当我们谈论使用图像时,我们(至少对我而言)最感兴趣的是性能,因为否则我们可以用手用Python编写一些东西。
性能不是那么简单。 您不能只说一个图书馆比另一个图书馆快。 每个库都有一组函数,并且每个函数以不同的速度运行。
因此,仅说一个功能在特定库中的性能较高或较低是正确的。 或者,您有一个需要特定功能集的应用程序,并且为此功能专门制定了一个基准,并说这样的库对于您的应用程序来说工作得更快(更慢)。
检查结果很重要。
进行基准测试时,查看获得的结果非常重要。 即使乍看之下您编写了相同的代码,也并不意味着它是相同的。
最近,在比较Pillow和OpenCV性能的文章中,我遇到了以下代码:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
它似乎在那里,那里,BoxBlur和那里,那里,参数3,但实际上结果是不同的。 因为在Pillow(3)中,这是模糊半径,而在OpenCV中,ksize =(3,3)是仁的大小,即大致来说是直径。 在这种情况下,OpenCV的正确值为3 * 2 +1,即(7,7)。
怎么了
为什么在处理图形时通常会出现性能问题? 因为任何操作的复杂度都取决于几个参数,并且复杂度通常随每个参数线性增长。 并且,例如,如果存在这些因素中的三个,并且复杂度线性依赖于每个因素,那么将获得多维数据集中的复杂度。
示例: OpenCV中的高斯模糊。

左边的半径是3,右边的半径是30。您可以看到,速度差超过10倍。
当我面临将高斯模糊添加到我的应用程序的任务时,我不高兴地假设一次操作可以花费900毫秒。 应用程序中每分钟有数千个这样的操作,而在一个操作上花费这么多的时间是不切实际的。 因此,我研究了这个问题,并在Pillow中实现了高斯模糊,它在相对于半径的恒定时间内起作用。 也就是说,只有图像大小会影响高斯模糊的性能。
但是,这里的主要要点不是工作更快或更慢。
我想传达的是,在构建某种系统时,了解输出的复杂性取决于哪些参数非常重要。 然后,您可以限制这些参数或以其他方式来处理这种复杂性。
打开图像后,我们对图像进行的最常见操作可能是调整大小。
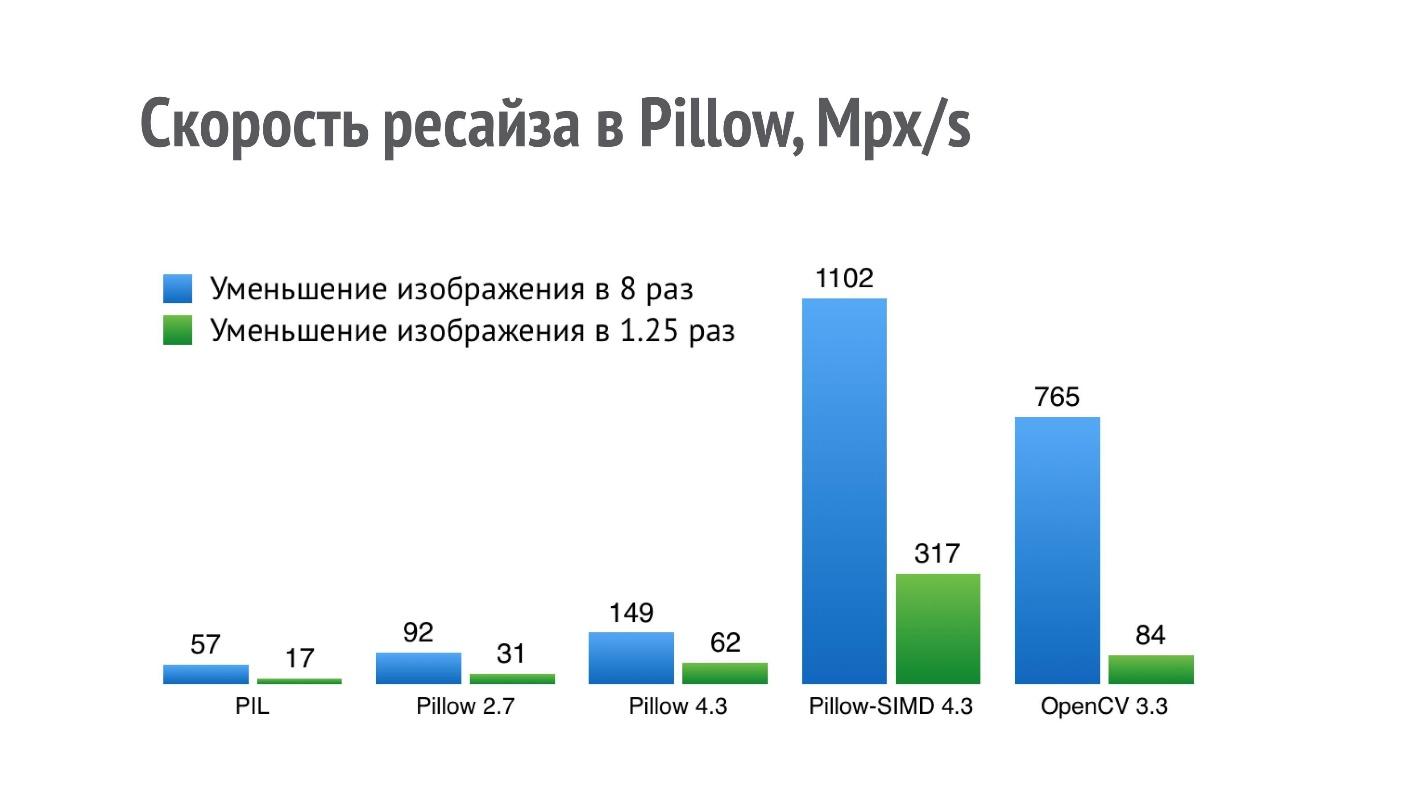
该图显示了将图像缩小8倍和1.25倍的操作时不同库的性能(越好越好)。
对于PIL,结果为17 Mpx / s意味着来自iPhone(12 Mpx)的照片可以在不到一秒钟的时间内减少1.25倍。 对于执行大量此类操作的严肃应用程序而言,这样的性能是不够的。
我开始优化调整大小的性能,在Pillow 2.7中设法实现了两倍的生产率提高,在Pillow 4.3中实现了三倍的提高(Pillow 5.3的版本目前是相关的,但是其中的调整大小性能是相同的)。
但是调整大小操作非常适合SIMD。 它处理单指令,多数据,因此,在当前版本的Pillow-SIMD中,与使用相同资源的原始Python Imaging Library相比,我设法
将调整大小速度提高了19倍 。
这明显高于OpenCV调整大小性能。 但是,这种比较并不完全正确,因为OpenCV使用的盒式过滤器调整大小的方法质量稍差一些,而在Pillow-SIMD中,使用卷积实现调整大小。
与常规枕头相比,这是在Pillow-SIMD中加速的那些操作的不完整列表。
- 调整大小:4至7倍。
- 模糊:2.8倍。
- 应用芯3×3或5×5:11次。
- 通过alpha通道进行乘法和除法:4和10倍。
- α组成:5倍。
我已经说过,不能说某个库比另一个库工作得更快,但是您可以组成一些您感兴趣的操作。 我选择了一组在我的应用程序中很有趣的操作,做了一个基准测试并得到了这样的结果。

事实证明,该装置上的Pillow-SIMD的工作速度比Pillow快2倍。 最后是Wand(记得这是ImageMagick)。
但是我对其他事情感兴趣-为什么OpenCV和VIPS的结果如此差劲,因为这些库也是出于性能考虑而设计的? 事实证明,对于OpenCV,使用pip安装的二进制OpenCV程序集是使用慢速JPEG编解码器进行组装的(该程序集的作者已得到通知,此问题已在2018年解决)。 它是使用libjpeg构建的,而大多数系统(至少是基于debian的系统)使用libjpeg-turbo,它的速度要快几倍。 如果您自己从源代码构建OpenCV,则性能会更好。
对于VIPS,情况有所不同。 我联系了VIPS的作者,向他展示了这个基准,我们进行了很长时间的交流,取得了丰硕的成果。 此后,VIPS的作者在VIPS本身中发现了几个执行不处于最佳路线的地方,并对其进行了纠正。
如果您从当前版本的源代码构建OpenCV,而从已经存在的master版本构建VIPS,那将对性能产生影响。
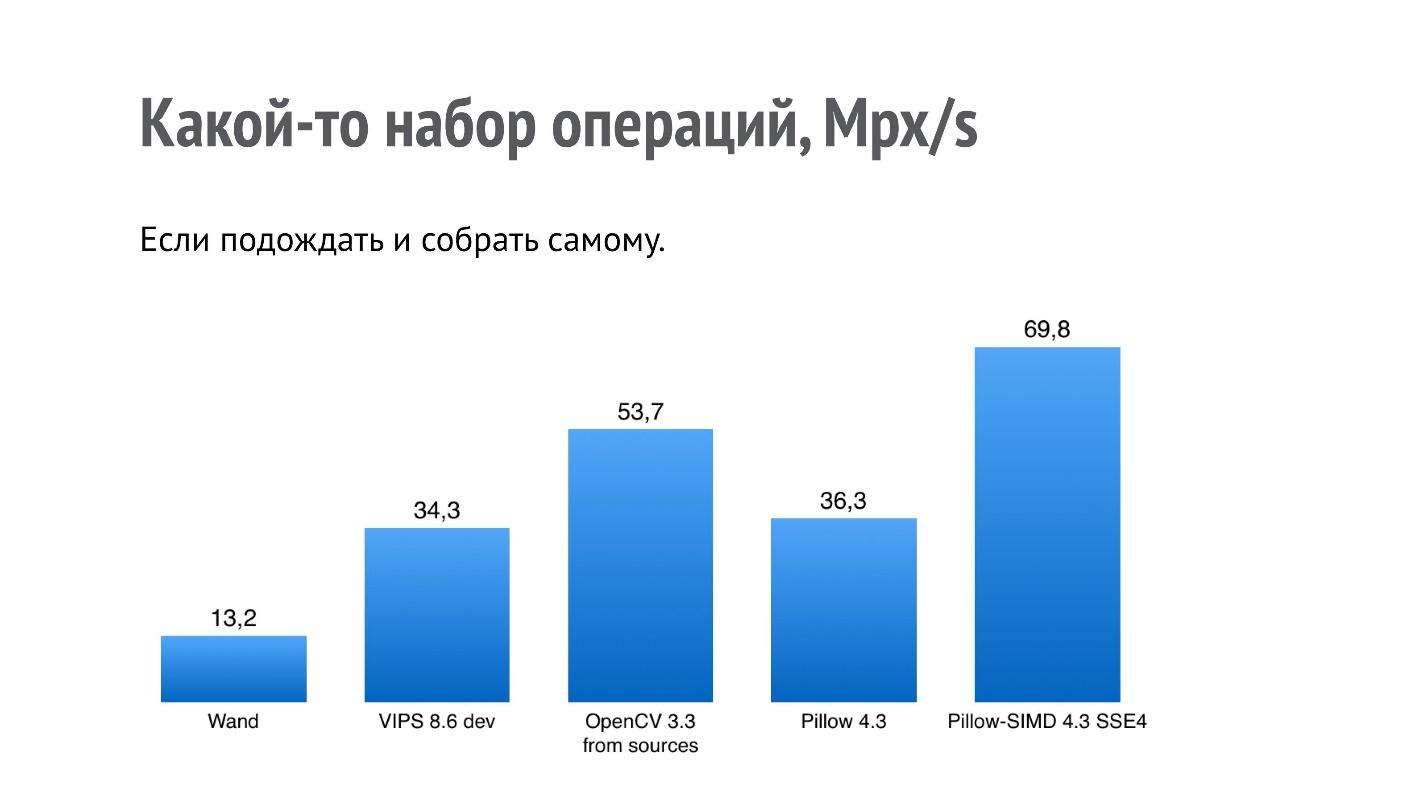
即使找到某种基准,也不是所有事情都可以在您的计算机上以这种速度正常工作的事实。
一套基准
我谈论的所有基准都可以在
结果页面上找到。 这是一个单独的小型项目,我在其中编写了开发Pillow-SIMD,运行它们并发布结果所需的基准。
GitHub有一个带有测试框架的
项目 ,每个人都可以提供自己的基准或修复现有基准。
并行工作
到目前为止,我一直在谈论纯性能,即在单个处理器内核上。 但是,我们所有人长期以来都可以使用具有更多核心的系统,因此,我想处置它们。 在这里我不得不说,事实上Pillow是所有不使用任务并行化的唯一库。 我将尝试解释为什么会这样。 其他所有以一种或另一种形式使用的库。
绩效指标
在性能方面,我们对2个参数感兴趣:
- 一次操作的实时性。 有一个操作(或一系列操作),您想知道在什么实时(挂钟)下执行该序列。 此参数在桌面上很重要,那里有一个用户在发出命令并等待结果。
- 整个系统的吞吐量 (工作流)。 当您有一组正在进行的操作或许多独立的操作时,在硬件上处理这些操作的速度对您很重要。 在有许多客户端的服务器上,该指标更为重要,您需要为所有客户端提供服务。 服务一个客户端所需的时间固然重要,但比总带宽要少。
基于这两个指标,我们考虑了并行操作的不同方式。
并行工作方法
1.
在应用程序级别 ,当您在应用程序级别决定在不同线程中处理操作时。 同时,一个操作的实际执行时间不会改变,因为像以前一样,一个内核参与了一个操作序列。 系统的吞吐量与内核数成正比增长,即非常好。
2.
在图形操作级别上 -大多数图形库中正是这样。 当图形库收到某种操作时,它会在其内部创建必要数量的线程,将一个操作拆分为几个较小的线程,然后执行它们。 同时,减少了实际执行时间-一种操作更快。 但是
吞吐量不会随核心数量
线性增长 。 有些操作不是并行的,一个引人注目的例子是PNG文件的解码-不能以任何方式并行化。 此外,创建线程,拆分任务还有开销,这些开销也不允许带宽线性增长。
3.
在处理器命令和数据级别 。 我们以特殊的方式准备数据,并使用特殊的命令来使处理器更快地处理它们。 这就是SIMD方法,实际上,它在Pillow-SIMD中使用。 实时运行时间在减少,吞吐量在增加-
这是
一个双赢的选择 。
如何结合并行工作
如果我们想以某种方式组合并行工作,那么SIMD可以很好地在操作内部进行并行化,而SIMD可以很好地在应用程序内部进行并行化。

但是应用程序内部和操作内部的并行化彼此不兼容。 如果您尝试这样做,则两种方法都将带来弊端。 该操作的实时性将与一个内核上的实时性相同,并且系统的吞吐量将增加,但相对于内核数而言不是线性的。
多线程
如果我们在谈论线程,我们所有人都是用Python编写的,并且知道它具有防止两个线程同时运行的GIL。 Python是严格的单线程语言。
当然,这是不正确的,因为GIL实际上阻止了两个线程在Python中执行,并且如果代码是用另一种语言编写的,并且在其运行期间未使用Python内部结构,则此代码可以释放GIL,从而释放解释器。用于其他任务。
许多图形库在其工作期间都会发布GIL,包括Pillow,OpenCV,pyvips,Wand。 只有一个pgmagick无法释放。 也就是说,您可以安全地创建线程来执行某些操作,这将与其余代码并行工作。
但是问题来了:
要创建多少个线程?如果我们为我们拥有的每个任务创建无限数量的线程,那么它们只会占用所有内存和整个处理器-我们将无法获得任何有效的工作。 我制定了一条特别规则。
规则N +1
对于生产性工作,您需要创建不超过N + 1个工作程序,其中N是机器上的内核或处理器线程数,而工作程序是处理中涉及的进程或线程。
最好使用过程,因为即使在同一个解释器中,也存在瓶颈和开销。
例如,在我们的应用程序中,使用了N + 1个实例“龙卷风”,两者之间的平衡由ngnix进行。 如果提到了Tornado,那么让我们谈谈异步操作。
异步运行
图形库实际有用的时间-图像处理-可以并且应该用于输入/输出(如果您在应用程序中拥有它们的话)。 异步框架在这里非常重要。
但是有一个问题-当我们调用某种处理时,它被同步调用。 即使此时库释放了GIL,事件循环仍然被阻止。
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
幸运的是,通过创建一个具有单个线程并开始图像处理的ThreadPoolExecutor可以很容易地解决此问题。 该调用已经异步发生。
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
本质上,这里创建了一个带有一个工作程序的队列,该队列执行图形操作,并且事件循环没有被阻塞,并且在另一个线程中安静地并行运行。
输入/输出
在图形操作的讨论中,我想谈谈的另一个主题是输入/输出。 事实是,我们很少使用图形库创建任何类型的图像。 通常,我们会以编码文件(JPEG,PNG,BMP,TIFF等)的形式打开来自用户的图像。
因此,用于构建良好应用程序的图形库应具有一些用于文件输入/输出的优点。
延迟加载
第一个这样的面包是延迟加载。 例如,如果在“枕头”中打开图像,则此刻不会发生图像解码。 返回的对象看起来像图像已经加载并且可以正常工作。 您可以查看其属性,并根据该图像的属性来决定是否准备好进一步使用它,例如用户是否已下载了数百万像素的图片以破坏服务。
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
如果决定下一步做什么,则使用显式或隐式调用进行加载,此图像将被解码。 此时已经分配了必要的内存量。
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
残影模式
使用用户生成的内容时需要的第二个包子是断图片模式。 我们从用户那里收到的文件经常与它们的编码格式包含一些不一致之处。
这些差异是由于各种原因而发生的。 有时是网络传输错误,有时只是某种扭曲的编解码器对图像进行了编码。 默认情况下,当Pillow看到不符合格式要求的图像时,只会抛出一个异常。
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
但是用户不要为自己的照片坏了而责怪,他仍然想要得到结果。 幸运的是,枕头有一个残破的图像模式。 我们更改一个设置,Pillow尝试最大程度地忽略图像中的所有解码错误。 因此,用户至少看到一些东西。
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

即使裁剪过的图片也总比没有好-只是有错误的页面。
汇总表
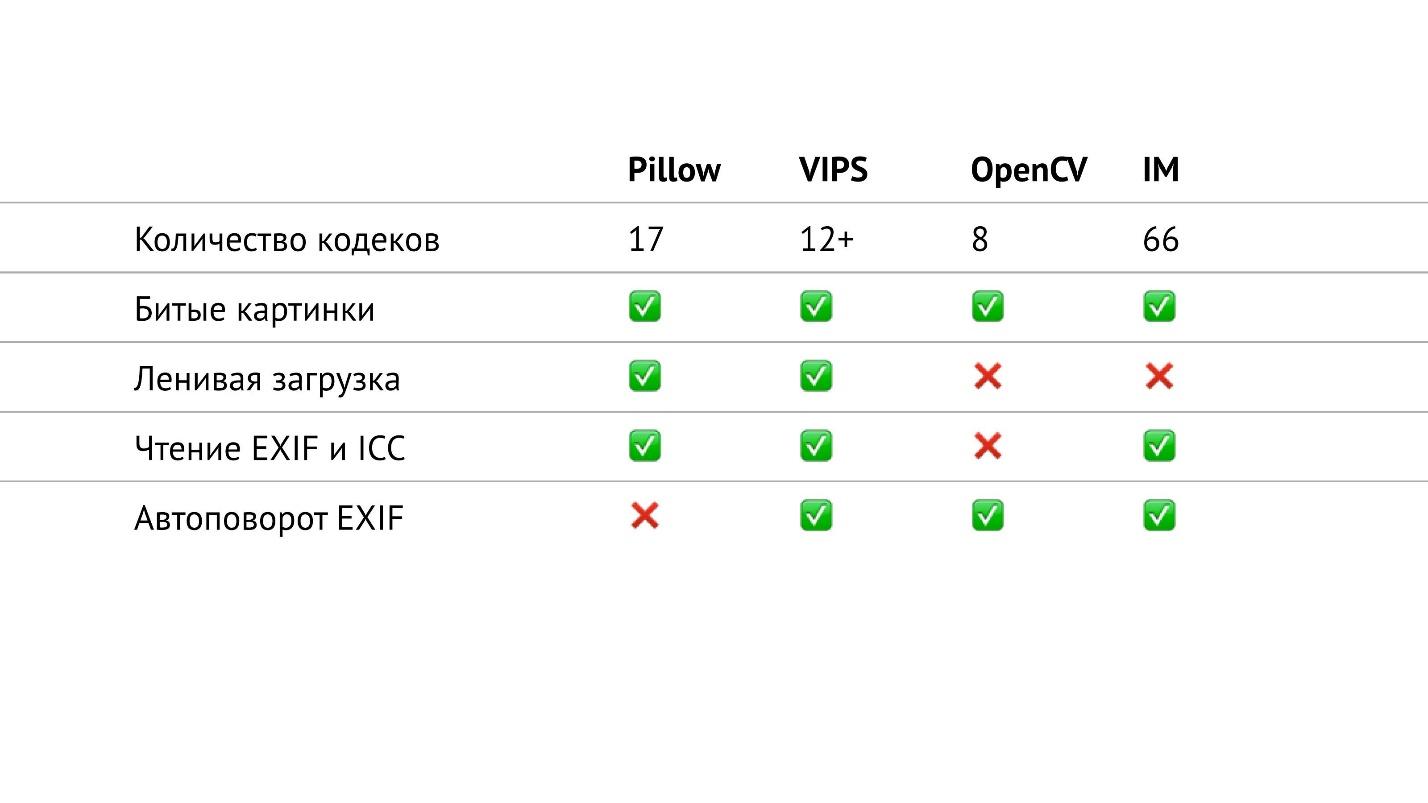
在上表中,我收集了我所谈论的库中与输入/输出相关的所有信息。 特别是,我计算了库中各种格式的编解码器的数量。 事实证明,在OpenCV中,它们最少,在ImageMagick中,最多。 似乎在ImageMagick中,您可以打开遇到的所有图像。 VIPS具有12个本机编解码器,但是VIPS可以使用ImageMagick作为中间产品。 我尚未测试它的工作方式,希望它是无缝的。
枕头有17个编解码器。 现在,这是唯一没有EXIF自动旋转的库。 但这现在是一个小问题,因为您可以自己阅读EXIF并根据它旋转图像。 这是一个小片段的问题,很容易用谷歌搜索,最多需要20行。
OpenCV的功能
如果仔细查看此表,您会发现在OpenCV中,输入/输出并不是一切都那么好。 它的编解码器数量最少,没有延迟加载,并且您无法读取EXIF和颜色配置文件。
但这还不是全部。 实际上,OpenCV具有更多功能。 当我们简单地打开图片时,
cv2.imread(filename)调用会根据EXIF(请参见表)旋转JPEG文件,但忽略PNG文件的alpha通道-这是相当奇怪的行为!
幸运的是,OpenCV具有一个标志:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) 。
如果指定IMREAD_UNCHANGED标志,则OpenCV会为PNG文件保留alpha通道,但会根据EXIF停止转换JPEG文件。 也就是说,同一标志影响两个完全不同的属性。 从表中可以看出,OpenCV不具有读取EXIF的功能,事实证明,在使用此标志的情况下,根本无法旋转JPEG。
如果您事先不知道图像的格式,又需要PNG的alpha通道和JPEG的自动旋转怎么办? 无所事事-OpenCV不能那样工作。
OpenCV出现此类问题的原因在于该库的名称。 它具有许多用于计算机视觉和图像分析的功能。 实际上,OpenCV旨在与经过验证的源一起使用。 例如,这是一台室外监控摄像机,每秒拍摄一次图像,并以相同的格式和相同的分辨率拍摄5年。 I / O问题中不需要可变性。
需要OpenCV功能的人实际上并不需要用户内容功能。
但是,如果您的应用程序仍需要使用功能来处理用户内容,同时又需要OpenCV的所有功能来进行处理和统计,该怎么办?

解决方案是合并库。 事实是,OpenCV是基于numpy构建的,并且Pillow具有将图像从Pillow导出到numpy数组的所有方法。 也就是说,我们导出numpy数组,并且OpenCV可以继续处理此映像,就像其本身一样。 这很容易做到:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
此外,当我们使用OpenCV(处理)进行魔术处理时,我们将调用另一个Pillow方法并将图像从OpenCV导入回Pillow格式。 因此,可以再次使用I / O。
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
因此,事实证明,我们使用来自Pillow的输入/输出,以及来自OpenCV的处理,也就是说,我们充分利用了这两个世界。
希望这可以帮助您构建加载的图形应用程序。
您可以学习其他Python开发秘诀,从宝贵的,有时是意想不到的经验中学习,最重要的是,您可以很快在Moscow Python Conf ++上讨论您的任务。 例如,在时间表中注意这些名称和主题。
- 唐纳德·怀特(Donald Whyte)的故事讲述了如何使用流行的库,技巧和狡猾使数学速度提高10倍,并且代码易于理解和支持。
- Andrei Popov打算收集大量数据并分析它们的威胁。
- Ephraim Matosyan在他的“再次使Python快速运行”报告中将告诉您如何提高处理来自总线的消息的守护程序的性能。
有关10月22日至23日将在此处讨论的内容的完整列表,请抽空参加。